今週の初めに、 STRING_SPLIT()に関する最近の投稿のフォローアップを投稿しました。 SQL Server 2016では、投稿に残されたコメントや直接送信されたコメントに対処します。
-
STRING_SPLIT()SQL Server 2016の場合:フォローアップ#1
その投稿がほとんど書かれた後、ダグ・エルナーから最新の質問がありました:
これらの関数は、テーブル値のパラメーターとどのように比較されますか?
スタックオーバーフローでの@Nick_Craverとの最近のTwitter交換の後、TVPのテストはすでに私の将来のプロジェクトのリストに含まれていました。 STRING_SPLIT()に興奮していると彼は言った テーブル値パラメーターを介して最大7,000個の値を送信するパフォーマンスに不満があったため、パフォーマンスは良好でした。
私のテスト
これらのテストでは、PCIeストレージと32GBのRAMを備えた8コアのWindows10VMでSQLServer 2016 RC3(13.0.1400.361)を使用しました。
彼らが行っていることを模倣した単純なテーブルを作成しました(300万行以上の投稿テーブルから約10,000の値を選択)が、私のテストでは、列とインデックスがはるかに少なくなっています:
CREATE TABLE dbo.Posts_Regular ( PostID int PRIMARY KEY, HitCount int NOT NULL DEFAULT 0 ); INSERT dbo.Posts_Regular(PostID) SELECT TOP (3000000) ROW_NUMBER() OVER (ORDER BY s1.[object_id]) FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2;
また、インメモリバージョンも作成しました。これは、そこで別のアプローチが機能するかどうかに興味があったためです。
CREATE TABLE dbo.Posts_InMemory ( PostID int PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 4000000), HitCount int NOT NULL DEFAULT 0 ) WITH (MEMORY_OPTIMIZED = ON);
ここで、コンマ区切りの文字列(StringBuilderを使用して作成)またはTVP(DataTableから渡される)のいずれかとして10,000個の一意の値を渡すC#アプリを作成したいと思いました。重要なのは、リストの分割によって生成された要素、またはTVPの明示的な値のいずれかとの一致に基づいて、選択した行を取得または更新することです。そのため、コードは文字列またはDataTableに300番目ごとの値を追加するように記述されています(C#コードは以下の付録にあります)。元の投稿で作成した関数を使用して、 varchar(max)を処理するように変更しました 、次にTVPを受け入れる2つの関数を追加しました–そのうちの1つはメモリ最適化されています。表の種類は次のとおりです(関数は以下の付録にあります):
CREATE TYPE dbo.PostIDs_Regular AS TABLE(PostID int PRIMARY KEY); GO CREATE TYPE dbo.PostIDs_InMemory AS TABLE ( PostID int NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 1000000) ) WITH (MEMORY_OPTIMIZED = ON); GO
また、8Kを超える文字列と8Kを超える要素を処理するためにNumbersテーブルを大きくする必要がありました(1MM行にしました)。次に、7つのストアドプロシージャを作成しました。そのうちの5つは varchar(max)を使用します。 そして、ベーステーブルを更新するために関数出力と結合し、次に2つでTVPを受け入れ、それに対して直接結合します。 C#コードは、これら7つのプロシージャのそれぞれを呼び出し、選択または更新する10,000件の投稿のリストを1,000回使用します。これらの手順は、以下の付録にもあります。要約すると、テストされているメソッドは次のとおりです。
- ネイティブ(
STRING_SPLIT()) - XML
- CLR
- 数値表
- JSON(明示的な
int出力) - テーブル値パラメーター
- メモリ最適化されたテーブル値パラメータ
DataReaderを使用して10,000個の値を1,000回取得することをテストしますが、DataReaderを反復処理しないでください。テストに時間がかかるだけであり、データベースの方法に関係なく、C#アプリケーションの作業量は同じになります。セットを制作しました。また、 ExecuteNonQuery()を使用して、10,000行をそれぞれ1,000回更新するテストも行います。 。また、Postsテーブルの通常バージョンとメモリ最適化バージョンの両方に対してテストします。これらは、同義語を使用して、関数やプロシージャを変更することなく非常に簡単に切り替えることができます。
CREATE SYNONYM dbo.Posts FOR dbo.Posts_Regular; -- to test memory-optimized version: DROP SYNONYM dbo.Posts; CREATE SYNONYM dbo.Posts FOR dbo.Posts_InMemory; -- to test the disk-based version again: DROP SYNONYM dbo.Posts; CREATE SYNONYM dbo.Posts FOR dbo.Posts_Regular;
アプリケーションを開始し、組み合わせごとに数回実行して、コンパイル、キャッシュ、およびその他の要因が最初に実行されたバッチに対して不公平でないことを確認してから、ロギングテーブルからの結果を分析しました(sysもスポットチェックしました)。 dm_exec_procedure_statsを使用して、アプリケーションベースのオーバーヘッドが大きくないことを確認します。
結果–ディスクベースのテーブル
データの視覚化に苦労することもあります。これらの指標を1つのグラフで表現する方法を考え出そうとしましたが、データポイントが多すぎて、目立つものを目立たせることができなかったと思います。
新しいタブ/ウィンドウでこれらのいずれかをクリックして拡大できますが、小さなウィンドウがある場合でも、色を使用して勝者を明確にしようとしました(勝者はすべての場合で同じでした)。 明確にするために、「平均期間」とは、アプリケーションが1,000回の操作のループを完了するのにかかった平均時間を意味します。
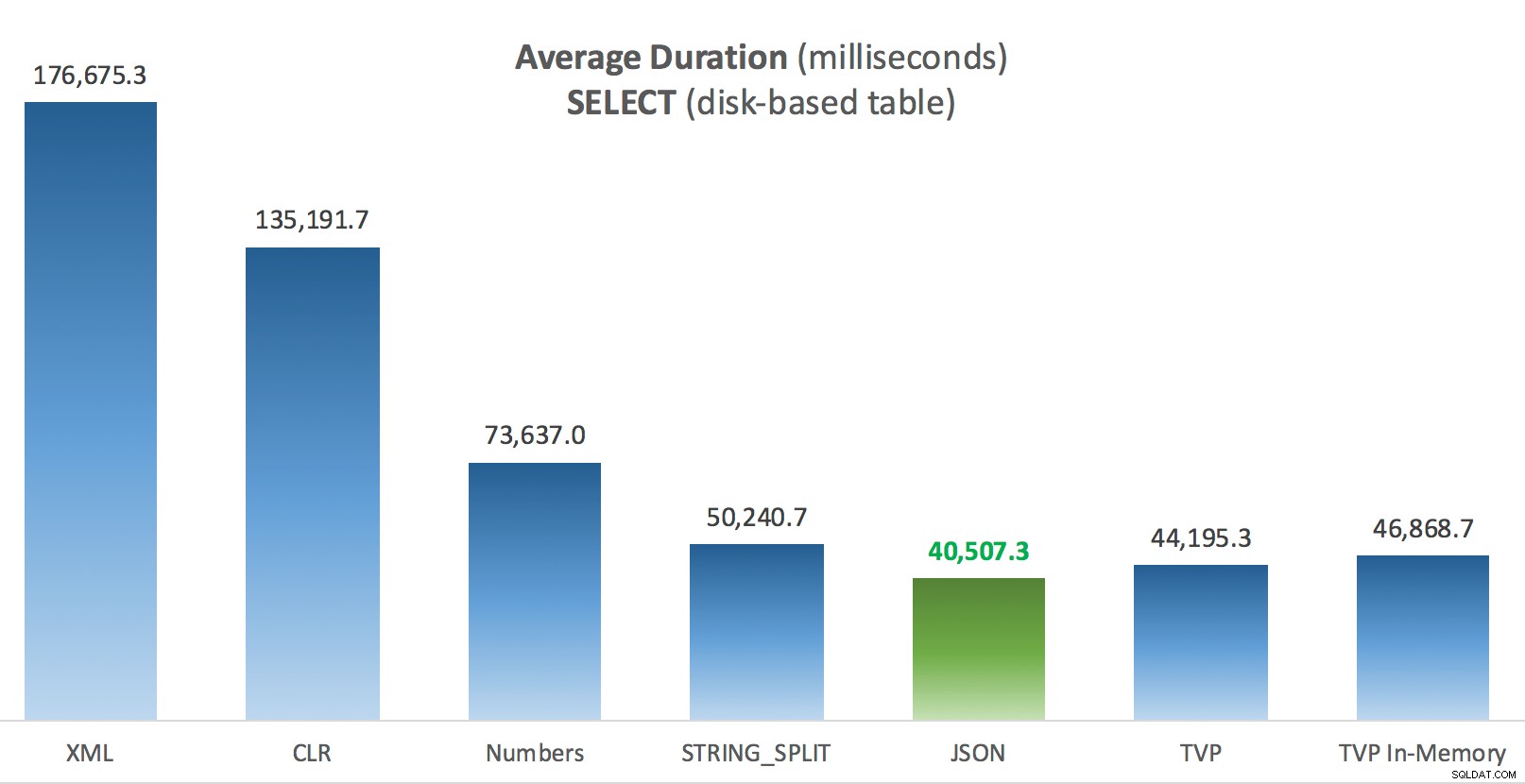 ディスクベースの投稿テーブルに対するSELECTの平均継続時間(ミリ秒)
ディスクベースの投稿テーブルに対するSELECTの平均継続時間(ミリ秒)
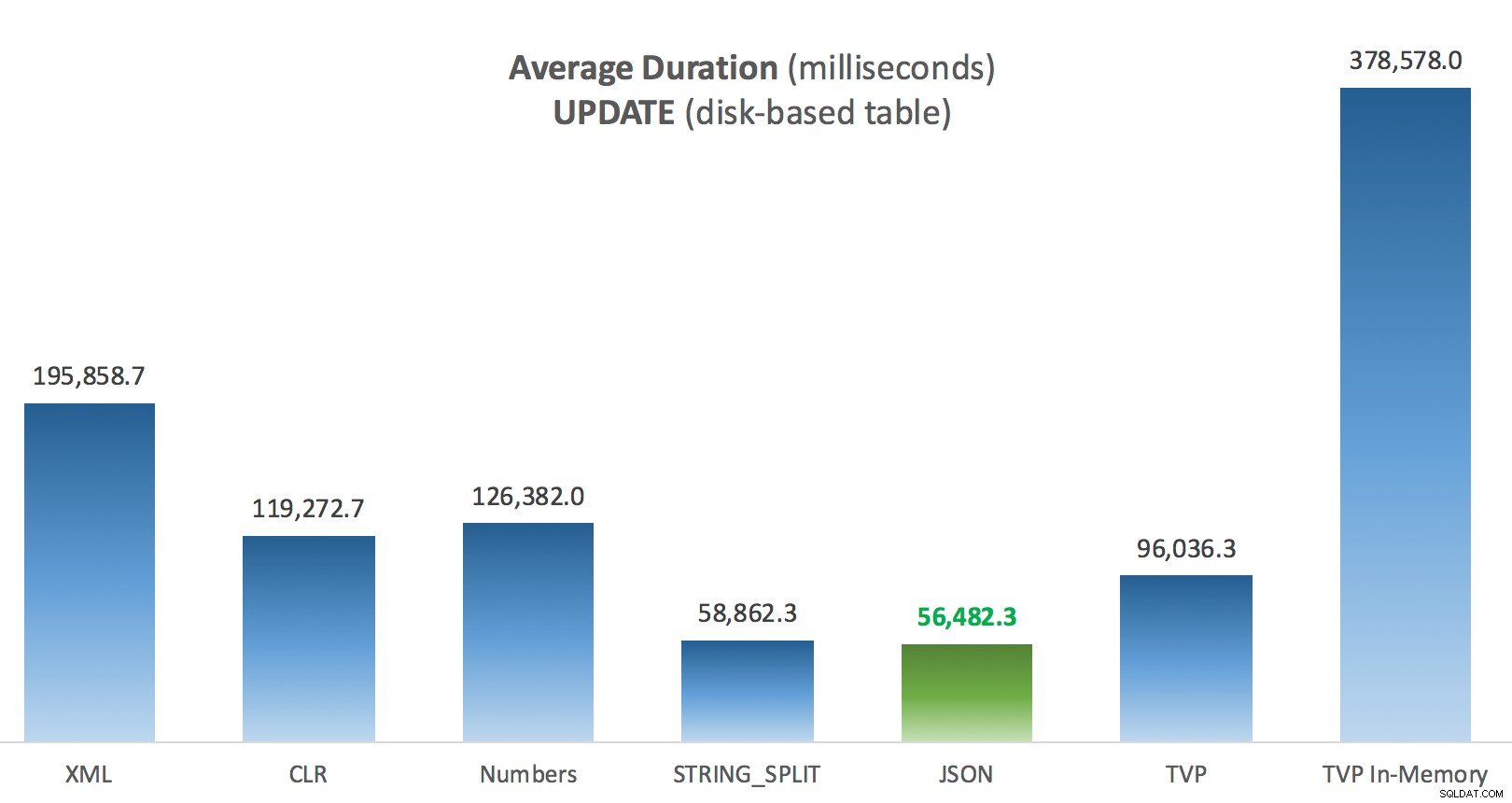 ディスクベースの投稿テーブルに対するUPDATEの平均継続時間(ミリ秒)
ディスクベースの投稿テーブルに対するUPDATEの平均継続時間(ミリ秒)
ここで最も興味深いのは、私にとって、 UPDATEを支援するときにメモリ最適化TVPがどれほどうまく機能しなかったかということです。 。現在、DMLが関与している場合、並列スキャンはあまりにも積極的にブロックされていることがわかります。 Microsoftはこれを機能のギャップとして認識しており、すぐに対処することを望んでいます。現在、 SELECTで並列スキャンが可能であることに注意してください ただし、現在DMLではブロックされています。 (SQL Server 2014では、これらの特定の並列スキャン操作はどの操作でも使用できないため、解決されません。)それが修正された場合、またはTVPが小さいか、並列処理がとにかく有益でない場合は、次のように表示されます。そのメモリ最適化TVPのパフォーマンスは向上します(このパターンは、比較的大きなTVPのこの特定のユースケースではうまく機能しません)。
この特定のケースでは、 SELECTの計画は次のとおりです。 (並列化を強制できます)および UPDATE (できませんでした):
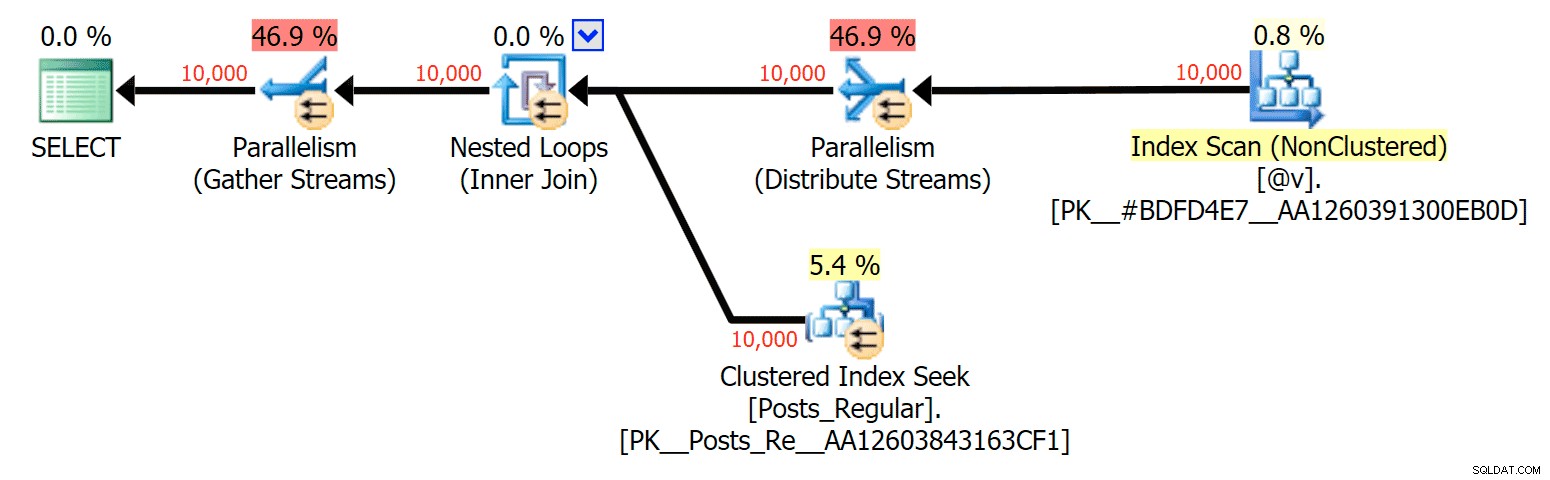 ディスクベースのテーブルをメモリ内TVPに結合するSELECTプランの並列処理
ディスクベースのテーブルをメモリ内TVPに結合するSELECTプランの並列処理
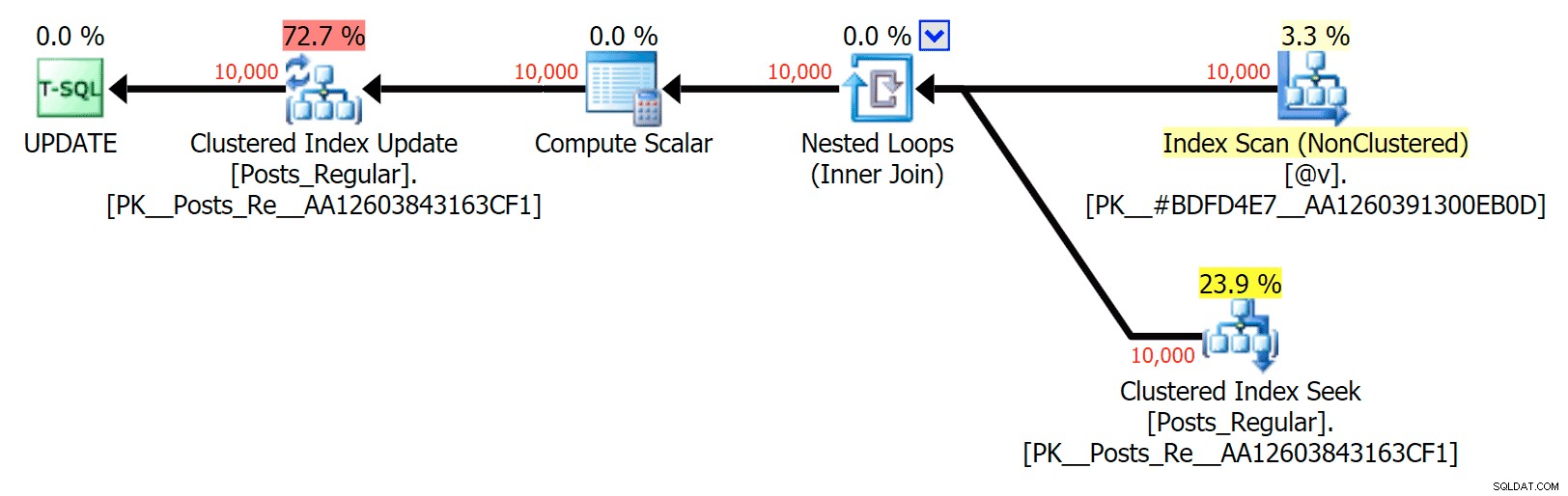 ディスクベースのテーブルをメモリ内に結合するUPDATEプランに並列処理はありませんTVP
ディスクベースのテーブルをメモリ内に結合するUPDATEプランに並列処理はありませんTVP
結果–メモリ最適化テーブル
ここでもう少し一貫性があります。右側の4つの方法は比較的均一ですが、左側の3つの方法は対照的に非常に望ましくないように見えます。また、ディスクベースのテーブルと比較して絶対スケールにも特に注意してください。ほとんどの場合、同じ方法を使用し、並列処理がなくても、メモリ最適化テーブルに対する操作がはるかに高速になり、全体的なCPU使用率が低下します。
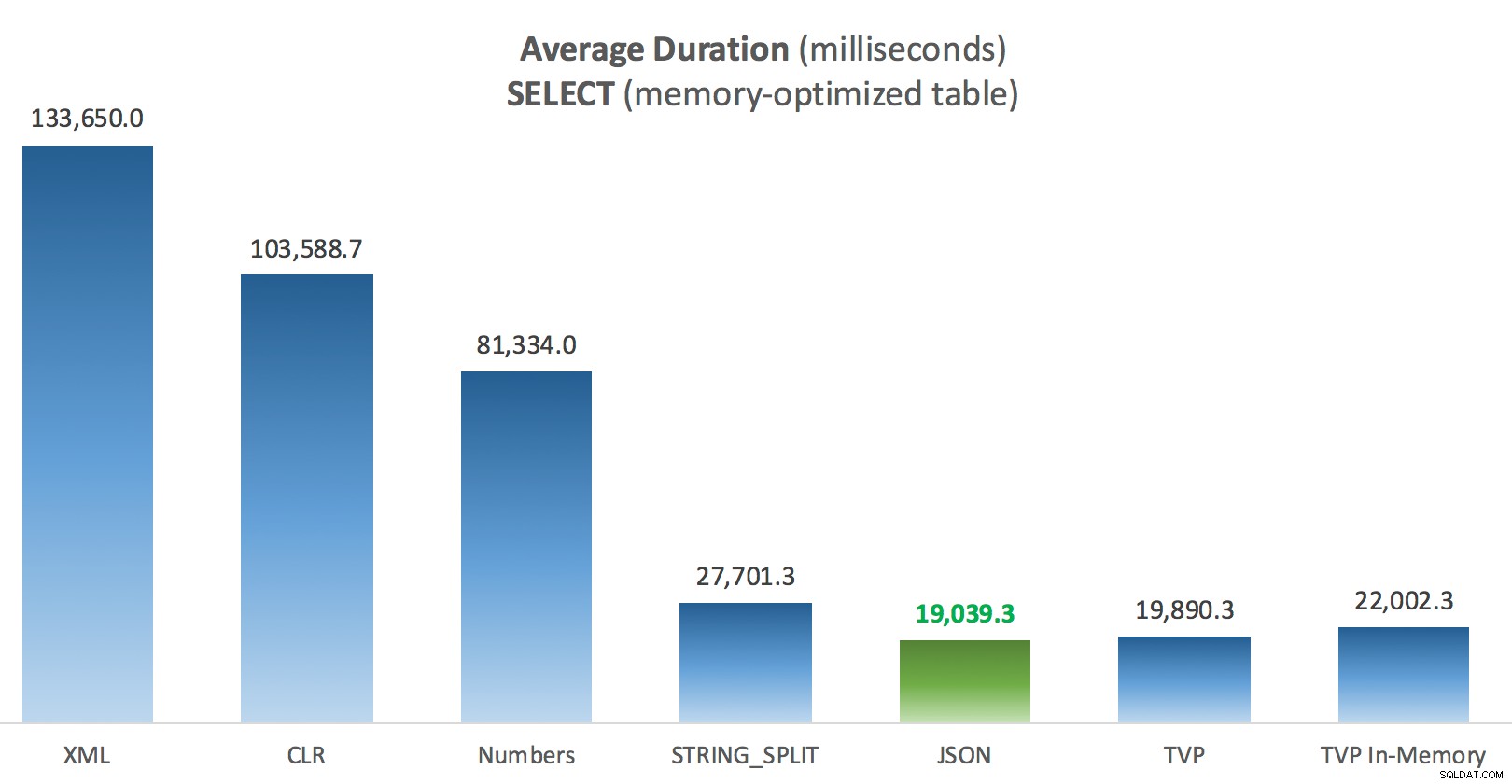 メモリ最適化投稿テーブルに対するSELECTの平均継続時間(ミリ秒)
メモリ最適化投稿テーブルに対するSELECTの平均継続時間(ミリ秒)
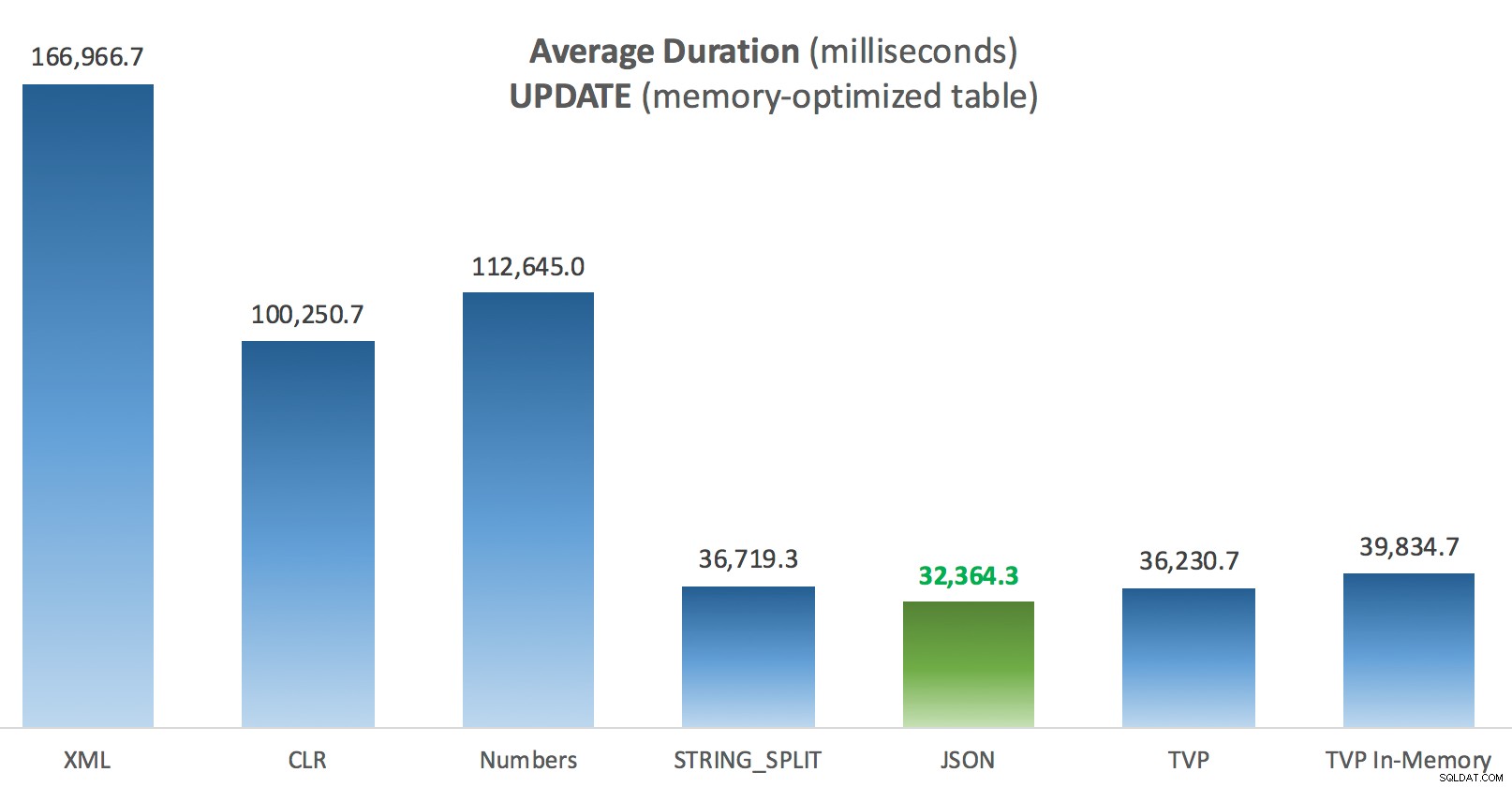 メモリ最適化投稿テーブルに対するUPDATEの平均継続時間(ミリ秒)
メモリ最適化投稿テーブルに対するUPDATEの平均継続時間(ミリ秒)
結論
この特定のテストでは、特定のデータサイズ、分布、パラメーターの数を使用し、特定のハードウェアでは、JSONが一貫して勝者でした(わずかにそうですが)。ただし、以前の投稿の他のテストのいくつかについては、他のアプローチの方がうまくいきました。実行していることと実行している場所がさまざまな手法の相対的な効率に劇的な影響を与える可能性がある方法のほんの一例です。この短いシリーズでテストしたものと、その手法の概要を以下に示します。その場合に使用し、2番目または3番目の選択肢として使用します(たとえば、企業ポリシーのため、またはAzure SQL Databaseを使用しているためにCLRを実装できない場合、またはJSONまたはSELECTINTOを再テストしなかったことに注意してください。 TVPを使用したスクリプト–これらのテストは、CSV形式の既存のデータがすでにあることを前提として設定されており、いずれにせよ最初に分割する必要があります。 一般的に、それを回避できる場合は、最初にセットをコンマ区切りの文字列にスムージングしないでください、IMHO。
| 目標 | 最初の選択肢 | 2番目の選択肢(および適切な場合は3番目) |
|---|---|---|
| 単純な変数の割り当て | STRING_SPLIT() | CLR if <2016 XML if no CLR and <2016 |
| SELECT INTO | CLR | CLRがない場合のXML |
| SELECT INTO(スプールなし) | CLR | CLRがない場合の数値テーブル |
| SELECT INTO(スプールなし+ MAXDOP 1) | STRING_SPLIT() | CLR if <2016 Numbers table if no CLR and <2016 |
| SELECTが大きなリストに参加(ディスクベース) | JSON(int) | TVP if <2016 |
| SELECTが大きなリストに参加(メモリ最適化) | JSON(int) | TVP if <2016 |
| 大きなリストに参加するUPDATE(ディスクベース) | JSON(int) | TVP if <2016 |
| 大きなリストに参加するUPDATE(メモリ最適化) | JSON(int) | TVP if <2016 |
ダグの特定の質問:JSON、 STRING_SPLIT() 、およびTVPは、これらのテスト全体で平均してかなり類似して実行されました。SQLServer 2016を使用していない場合は、TVPが当然の選択であるほど十分に近いです。異なるユースケースがある場合、これらの結果は異なる場合があります。 すばらしい 。
これがこれの教訓につながります ストーリー:私や他の人は、機能やアプローチを中心に非常に具体的なパフォーマンステストを実行し、どのアプローチが最も速いかについて何らかの結論に達する可能性があります。しかし、非常に多くの変数があるので、「このアプローチは常に」と言う自信はありません。 このシナリオでは、ほとんどの要因を制御するために非常に懸命に努力しました。4つのケースすべてでJSONが勝ちましたが、これらのさまざまな要因が実行時間にどのように影響したかを確認できます(一部のアプローチでは大幅に影響しました)。独自のテストを作成することは常に価値があります。私がそのようなことをどのように行うかを説明するのに役立ったことを願っています。
付録A:コンソールアプリケーションコード
どうか、このコードについては気にしないでください。これは文字通り、C#でアセンブルされた真のリストとDataTablesを使用してこれらのストアドプロシージャを1,000回実行し、各ループがテーブルにかかった時間をログに記録する非常に簡単な方法としてまとめられました(アプリケーション関連のオーバーヘッドを処理に含めるようにしてください)大きな文字列またはコレクションのいずれか)。エラー処理を追加したり、別の方法でループしたり(たとえば、単一の作業単位を再利用する代わりに、ループ内にリストを作成したり)などができます。
using System;
using System.Text;
using System.Configuration;
using System.Data;
using System.Data.SqlClient;
namespace SplitTesting
{
class Program
{
static void Main(string[] args)
{
string operation = "Update";
if (args[0].ToString() == "-Select") { operation = "Select"; }
var csv = new StringBuilder();
DataTable elements = new DataTable();
elements.Columns.Add("value", typeof(int));
for (int i = 1; i <= 10000; i++)
{
csv.Append((i*300).ToString());
if (i < 10000) { csv.Append(","); }
elements.Rows.Add(i*300);
}
string[] methods = { "Native", "CLR", "XML", "Numbers", "JSON", "TVP", "TVP_InMemory" };
using (SqlConnection con = new SqlConnection())
{
con.ConnectionString = ConfigurationManager.ConnectionStrings["primary"].ToString();
con.Open();
SqlParameter p;
foreach (string method in methods)
{
SqlCommand cmd = new SqlCommand("dbo." + operation + "Posts_" + method, con);
cmd.CommandType = CommandType.StoredProcedure;
if (method == "TVP" || method == "TVP_InMemory")
{
cmd.Parameters.Add("@PostList", SqlDbType.Structured).Value = elements;
}
else
{
cmd.Parameters.Add("@PostList", SqlDbType.VarChar, -1).Value = csv.ToString();
}
var timer = System.Diagnostics.Stopwatch.StartNew();
for (int x = 1; x <= 1000; x++)
{
if (operation == "Update") { cmd.ExecuteNonQuery(); }
else { SqlDataReader rdr = cmd.ExecuteReader(); rdr.Close(); }
}
timer.Stop();
long this_time = timer.ElapsedMilliseconds;
// log time - the logging procedure adds clock time and
// records memory/disk-based (determined via synonym)
SqlCommand log = new SqlCommand("dbo.LogBatchTime", con);
log.CommandType = CommandType.StoredProcedure;
log.Parameters.Add("@Operation", SqlDbType.VarChar, 32).Value = operation;
log.Parameters.Add("@Method", SqlDbType.VarChar, 32).Value = method;
log.Parameters.Add("@Timing", SqlDbType.Int).Value = this_time;
log.ExecuteNonQuery();
Console.WriteLine(method + " : " + this_time.ToString());
}
}
}
}
} 使用例:
SplitTesting.exe -SelectSplitTesting.exe -Update
付録B:関数、手順、およびログテーブル
varchar(max)をサポートするために編集された関数は次のとおりです。 (CLR関数はすでに nvarchar(max)を受け入れています そして、私はまだそれを変更しようとはしませんでした):
CREATE FUNCTION dbo.SplitStrings_Native( @List varchar(max), @Delimiter char(1))
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN (SELECT [value] FROM STRING_SPLIT(@List, @Delimiter));
GO
CREATE FUNCTION dbo.SplitStrings_XML( @List varchar(max), @Delimiter char(1))
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN (SELECT [value] = y.i.value('(./text())[1]', 'varchar(max)')
FROM (SELECT x = CONVERT(XML, '<i>' + REPLACE(@List, @Delimiter, '</i><i>')
+ '</i>').query('.')) AS a CROSS APPLY x.nodes('i') AS y(i));
GO
CREATE FUNCTION dbo.SplitStrings_Numbers( @List varchar(max), @Delimiter char(1))
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN (SELECT [value] = SUBSTRING(@List, Number,
CHARINDEX(@Delimiter, @List + @Delimiter, Number) - Number)
FROM dbo.Numbers WHERE Number <= CONVERT(INT, LEN(@List))
AND SUBSTRING(@Delimiter + @List, Number, LEN(@Delimiter)) = @Delimiter
);
GO
CREATE FUNCTION dbo.SplitStrings_JSON( @List varchar(max), @Delimiter char(1))
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN (SELECT [value] FROM OPENJSON(CHAR(91) + @List + CHAR(93)) WITH (value int '$'));
GO そして、ストアドプロシージャは次のようになりました:
CREATE PROCEDURE dbo.UpdatePosts_Native @PostList varchar(max) AS BEGIN UPDATE p SET HitCount += 1 FROM dbo.Posts AS p INNER JOIN dbo.SplitStrings_Native(@PostList, ',') AS s ON p.PostID = s.[value]; END GO CREATE PROCEDURE dbo.SelectPosts_Native @PostList varchar(max) AS BEGIN SELECT p.PostID, p.HitCount FROM dbo.Posts AS p INNER JOIN dbo.SplitStrings_Native(@PostList, ',') AS s ON p.PostID = s.[value]; END GO -- repeat for the 4 other varchar(max)-based methods CREATE PROCEDURE dbo.UpdatePosts_TVP @PostList dbo.PostIDs_Regular READONLY -- switch _Regular to _InMemory AS BEGIN SET NOCOUNT ON; UPDATE p SET HitCount += 1 FROM dbo.Posts AS p INNER JOIN @PostList AS s ON p.PostID = s.PostID; END GO CREATE PROCEDURE dbo.SelectPosts_TVP @PostList dbo.PostIDs_Regular READONLY -- switch _Regular to _InMemory AS BEGIN SET NOCOUNT ON; SELECT p.PostID, p.HitCount FROM dbo.Posts AS p INNER JOIN @PostList AS s ON p.PostID = s.PostID; END GO -- repeat for in-memory
そして最後に、ロギングテーブルと手順:
CREATE TABLE dbo.SplitLog
(
LogID int IDENTITY(1,1) PRIMARY KEY,
ClockTime datetime NOT NULL DEFAULT GETDATE(),
OperatingTable nvarchar(513) NOT NULL, -- Posts_InMemory or Posts_Regular
Operation varchar(32) NOT NULL DEFAULT 'Update', -- or select
Method varchar(32) NOT NULL DEFAULT 'Native', -- or TVP, JSON, etc.
Timing int NOT NULL DEFAULT 0
);
GO
CREATE PROCEDURE dbo.LogBatchTime
@Operation varchar(32),
@Method varchar(32),
@Timing int
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.SplitLog(OperatingTable, Operation, Method, Timing)
SELECT base_object_name, @Operation, @Method, @Timing
FROM sys.synonyms WHERE name = N'Posts';
END
GO
-- and the query to generate the graphs:
;WITH x AS
(
SELECT OperatingTable,Operation,Method,Timing,
Recency = ROW_NUMBER() OVER
(PARTITION BY OperatingTable,Operation,Method
ORDER BY ClockTime DESC)
FROM dbo.SplitLog
)
SELECT OperatingTable,Operation,Method,AverageDuration = AVG(1.0*Timing)
FROM x WHERE Recency <= 3
GROUP BY OperatingTable,Operation,Method;