Linux上のSQLServerは、v.Nextに関するほとんどすべての見出しを盗みましたが、お気に入りのデータベースプラットフォームの次のバージョンには、他にも興味深い進歩がいくつかあります。 T-SQLの面では、グループ化された文字列の連結を実行する組み込みの方法がついにできました: STRING_AGG() 。
次のような単純なテーブル構造があるとします。
CREATE TABLE dbo.Objects
(
[object_id] int,
[object_name] nvarchar(261),
CONSTRAINT PK_Objects PRIMARY KEY([object_id])
);
CREATE TABLE dbo.Columns
(
[object_id] int NOT NULL
FOREIGN KEY REFERENCES dbo.Objects([object_id]),
column_name sysname,
CONSTRAINT PK_Columns PRIMARY KEY ([object_id],column_name)
);
パフォーマンステストでは、 sys.all_objectsを使用してこれを設定します およびsys.all_columns 。ただし、最初に簡単なデモンストレーションを行うために、次の行を追加しましょう。
INSERT dbo.Objects([object_id],[object_name])
VALUES(1,N'Employees'),(2,N'Orders');
INSERT dbo.Columns([object_id],column_name)
VALUES(1,N'EmployeeID'),(1,N'CurrentStatus'),
(2,N'OrderID'),(2,N'OrderDate'),(2,N'CustomerID'); フォーラムが何らかの兆候である場合、列名のコンマ区切りのリストとともに、各オブジェクトの行を返すことは非常に一般的な要件です。 (この方法でモデル化するエンティティタイプ(注文に関連付けられた製品名、製品の組み立てに関係する部品名、マネージャーに報告する部下など)に外挿します。)たとえば、上記のデータを使用すると、次のような出力が必要です:
object columns --------- ---------------------------- Employees EmployeeID,CurrentStatus Orders OrderID,OrderDate,CustomerID
SQL Serverの現在のバージョンでこれを実現する方法は、おそらく FOR XML PATHを使用することです。 、この以前の投稿でCLRの外部で最も効率的であることを示したように。この例では、次のようになります。
SELECT [object] = o.[object_name],
[columns] = STUFF(
(SELECT N',' + c.column_name
FROM dbo.Columns AS c
WHERE c.[object_id] = o.[object_id]
FOR XML PATH, TYPE
).value(N'.[1]',N'nvarchar(max)'),1,1,N'')
FROM dbo.Objects AS o; 予想通り、上記と同じ出力が得られます。 SQL Server v.Nextでは、これをより簡単に表現できるようになります。
SELECT [object] = o.[object_name],
[columns] = STRING_AGG(c.column_name, N',')
FROM dbo.Objects AS o
INNER JOIN dbo.Columns AS c
ON o.[object_id] = c.[object_id]
GROUP BY o.[object_name];
繰り返しますが、これはまったく同じ出力を生成します。そして、ネイティブ関数を使用してこれを行うことができ、高価な FOR XML PATHの両方を回避できました。 足場、および STUFF() 最初のコンマを削除するために使用される関数(これは自動的に行われます)。
注文はどうですか?
グループ化された連結に対する多くのクラッジソリューションの問題の1つは、コンマ区切りのリストの順序を任意で非決定的と見なす必要があることです。
XML PATHの場合 解決策として、以前の別の投稿で、 ORDER BYを追加することを示しました 些細で保証されています。したがって、この例では、列リストをSQL Serverに任せて並べ替える(またはしない)代わりに、列名のアルファベット順に並べ替えることができます。
SELECT [object] = [object_name],
[columns] = STUFF(
(SELECT N',' +c.column_name
FROM dbo.Columns AS c
WHERE c.[object_id] = o.[object_id]
ORDER BY c.column_name -- only change
FOR XML PATH, TYPE
).value(N'.[1]',N'nvarchar(max)'),1,1,N'')
FROM dbo.Objects AS o; 出力:
object columns --------- ---------------------------- Employees CurrentStatus,EmployeeID Order CustomerID,OrderDate,OrderID
CTP 1.1は、 WITHIN GROUPを追加します STRING_AGG()へ 、したがって、新しいアプローチを使用すると、次のように言うことができます:
SELECT [object] = o.[object_name],
[columns] = STRING_AGG(c.column_name, N',')
WITHIN GROUP (ORDER BY c.column_name) -- only change
FROM dbo.Objects AS o
INNER JOIN dbo.Columns AS c
ON o.[object_id] = c.[object_id]
GROUP BY o.[object_name];
これで同じ結果が得られます。通常のORDERBYと同じように注意してください 句を使用すると、 WITHIN GROUP()内に複数の順序付け列または式を追加できます。 。
わかりました、パフォーマンスはすでに完了しています!
クアッドコア2.6GHzプロセッサ、8 GBのメモリ、およびSQL Server CTP1.1(14.0.100.187)を使用して、新しいデータベースを作成し、これらのテーブルを再作成し、 sys.all_objects> およびsys.all_columns 。少なくとも1つの列を持つオブジェクトのみを含めるようにしました:
INSERT dbo.Objects([object_id], [object_name]) -- 656 rows
SELECT [object_id], QUOTENAME(s.name) + N'.' + QUOTENAME(o.name)
FROM sys.all_objects AS o
INNER JOIN sys.schemas AS s
ON o.[schema_id] = s.[schema_id]
WHERE EXISTS
(
SELECT 1 FROM sys.all_columns
WHERE [object_id] = o.[object_id]
);
INSERT dbo.Columns([object_id], column_name) -- 8,085 rows
SELECT [object_id], name
FROM sys.all_columns AS c
WHERE EXISTS
(
SELECT 1 FROM dbo.Objects
WHERE [object_id] = c.[object_id]
); 私のシステムでは、これにより656個のオブジェクトと8,085個の列が生成されました(システムによって生成される数はわずかに異なる場合があります)。
計画
まず、プランエクスプローラーを使用して、2つの順序付けされていないクエリのプランと[テーブルI/O]タブを比較してみましょう。全体的なランタイムメトリックは次のとおりです。
 XML PATH(上)とSTRING_AGG()(下)のランタイムメトリック
XML PATH(上)とSTRING_AGG()(下)のランタイムメトリック
FOR XML PATHからのグラフィカルプランとテーブルI/O クエリ:
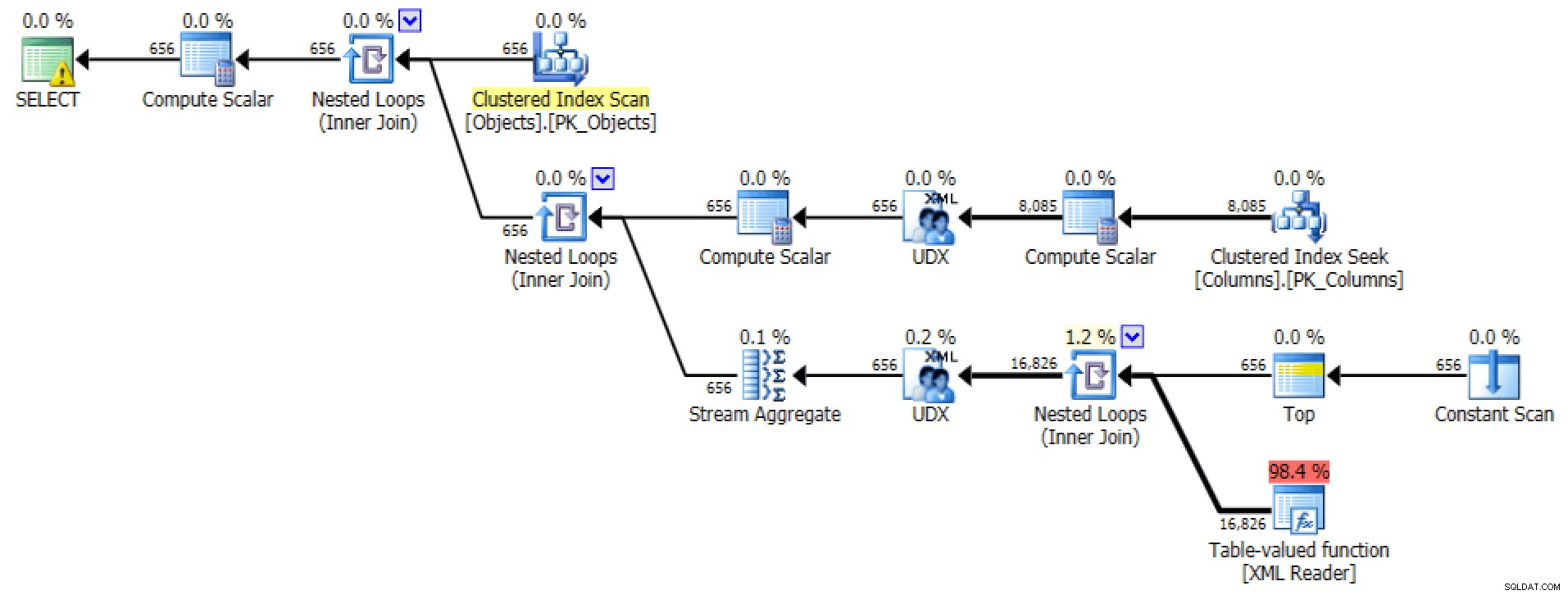
 プランとテーブルI / O XML PATHの場合、順序なし
プランとテーブルI / O XML PATHの場合、順序なし
そしてSTRING_AGGから バージョン:
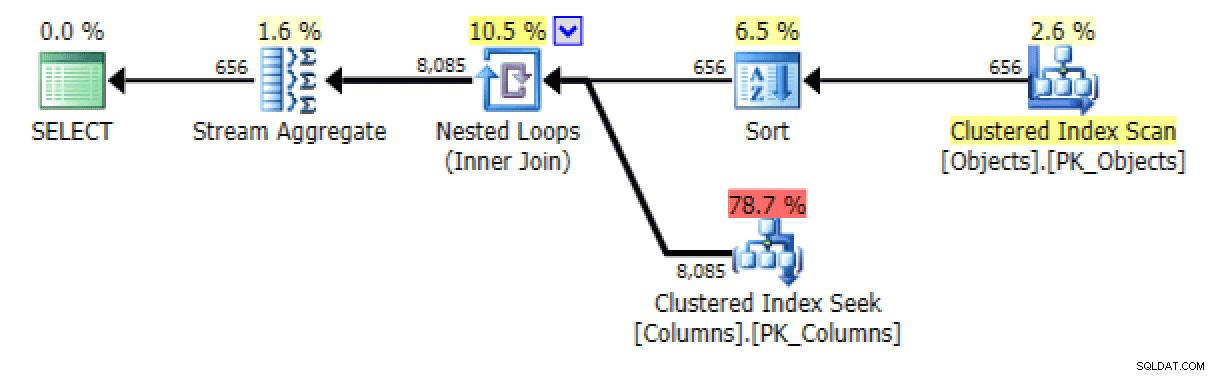
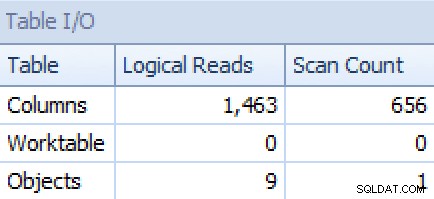 プランとテーブルI / O STRING_AGGの場合、順序付けなし
プランとテーブルI / O STRING_AGGの場合、順序付けなし
後者の場合、クラスター化されたインデックスシークは私には少し厄介なようです。これは、めったに使用されない FORCESCANをテストするための良いケースのように思われました。 ヒント(いいえ、これは FOR XML PATHの助けにはなりません。 クエリ):
SELECT [object] = o.[object_name],
[columns] = STRING_AGG(c.column_name, N',')
FROM dbo.Objects AS o
INNER JOIN dbo.Columns AS c WITH (FORCESCAN) -- added hint
ON o.[object_id] = c.[object_id]
GROUP BY o.[object_name]; これで、プランとテーブルI/Oタブがロットになります。 少なくとも一見したところ、より良い:
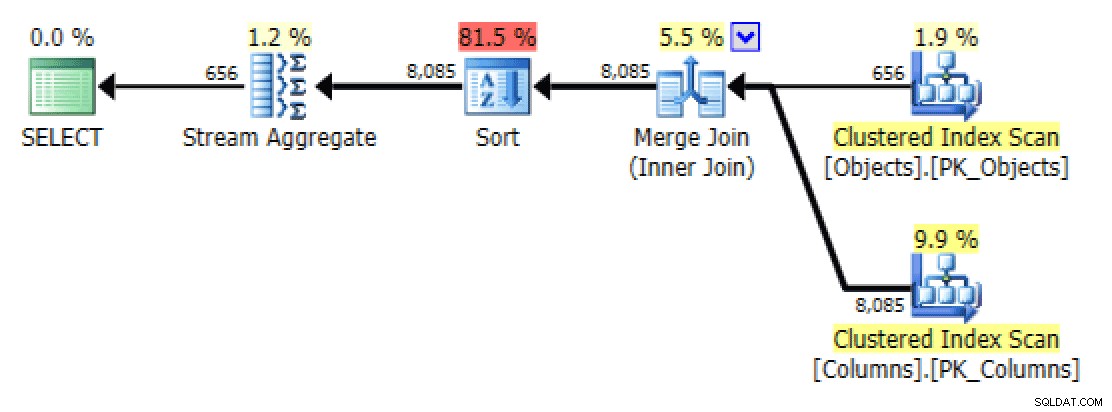
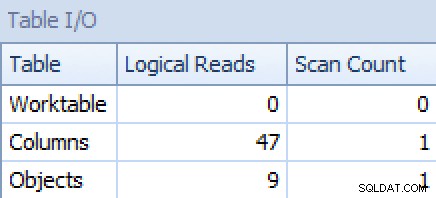 プランとテーブルI / O STRING_AGG()の場合、順序付けなし、FORCESCANを使用
プランとテーブルI / O STRING_AGG()の場合、順序付けなし、FORCESCANを使用
クエリの順序付けされたバージョンは、ほぼ同じ計画を生成します。 FOR XML PATHの場合 バージョン、並べ替えが追加されます:
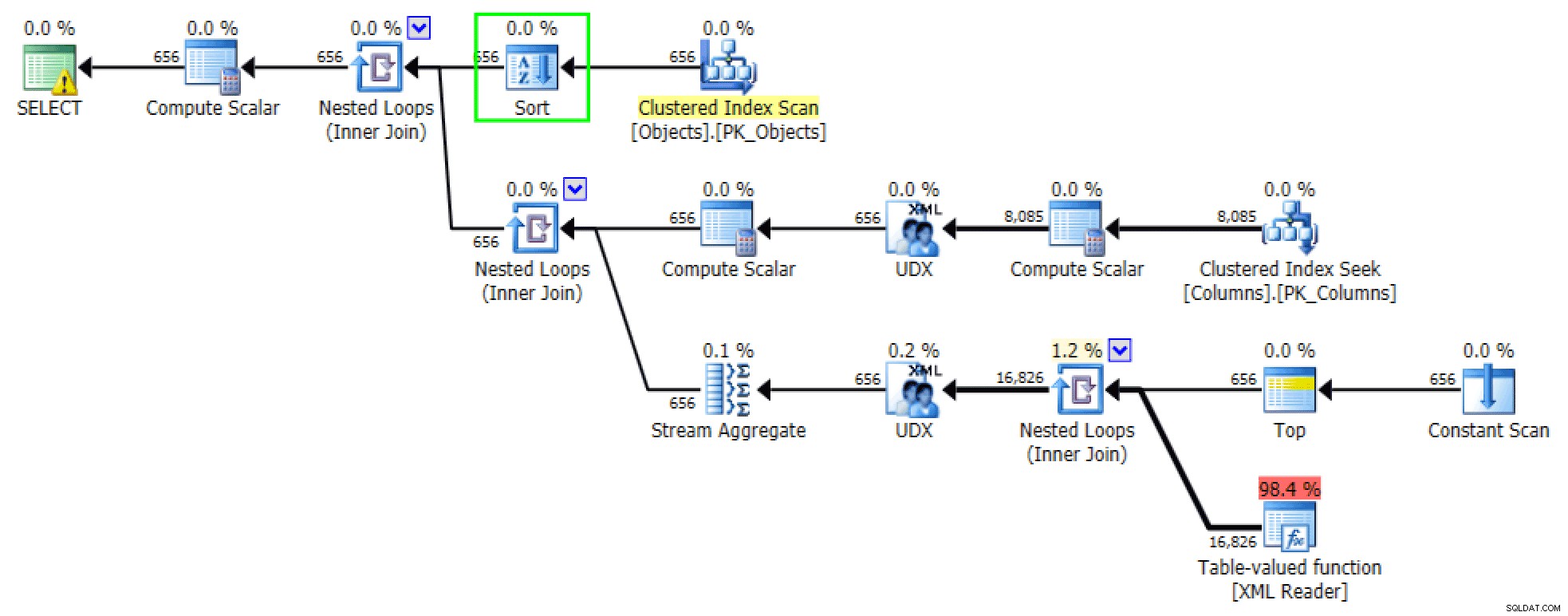 FORXMLPATHバージョンに並べ替えを追加
FORXMLPATHバージョンに並べ替えを追加
STRING_AGG()の場合 、この場合、 FORCESCAN がなくても、スキャンが選択されます。 ヒントであり、追加の並べ替え操作は必要ありません。したがって、プランは FORCESCANと同じように見えます。 バージョン。
大規模
計画と1回限りの実行時メトリックを見ると、 STRING_AGG()かどうかについてのアイデアが得られる可能性があります。 既存のFORXML PATHよりもパフォーマンスが優れています 解決策ですが、テストが大きいほど理にかなっている場合があります。グループ化された連結を5,000回実行するとどうなりますか?
SELECT SYSDATETIME(); GO DECLARE @x nvarchar(max); SELECT @x = STRING_AGG(c.column_name, N',') FROM dbo.Objects AS o INNER JOIN dbo.Columns AS c ON o.[object_id] = c.[object_id] GROUP BY o.[object_name]; GO 5000 SELECT [string_agg, unordered] = SYSDATETIME(); GO DECLARE @x nvarchar(max); SELECT @x = STRING_AGG(c.column_name, N',') FROM dbo.Objects AS o INNER JOIN dbo.Columns AS c WITH (FORCESCAN) ON o.[object_id] = c.[object_id] GROUP BY o.[object_name]; GO 5000 SELECT [string_agg, unordered, forcescan] = SYSDATETIME(); GO DECLARE @x nvarchar(max); SELECT @x = STUFF((SELECT N',' +c.column_name FROM dbo.Columns AS c WHERE c.[object_id] = o.[object_id] FOR XML PATH, TYPE).value(N'.[1]',N'nvarchar(max)'),1,1,N'') FROM dbo.Objects AS o; GO 5000 SELECT [for xml path, unordered] = SYSDATETIME(); GO DECLARE @x nvarchar(max); SELECT @x = STRING_AGG(c.column_name, N',') WITHIN GROUP (ORDER BY c.column_name) FROM dbo.Objects AS o INNER JOIN dbo.Columns AS c ON o.[object_id] = c.[object_id] GROUP BY o.[object_name]; GO 5000 SELECT [string_agg, ordered] = SYSDATETIME(); GO DECLARE @x nvarchar(max); SELECT @x = STUFF((SELECT N',' +c.column_name FROM dbo.Columns AS c WHERE c.[object_id] = o.[object_id] ORDER BY c.column_name FOR XML PATH, TYPE).value(N'.[1]',N'nvarchar(max)'),1,1,N'') FROM dbo.Objects AS o ORDER BY o.[object_name]; GO 5000 SELECT [for xml path, ordered] = SYSDATETIME();
このスクリプトを5回実行した後、期間の数値を平均しました。結果は次のとおりです。
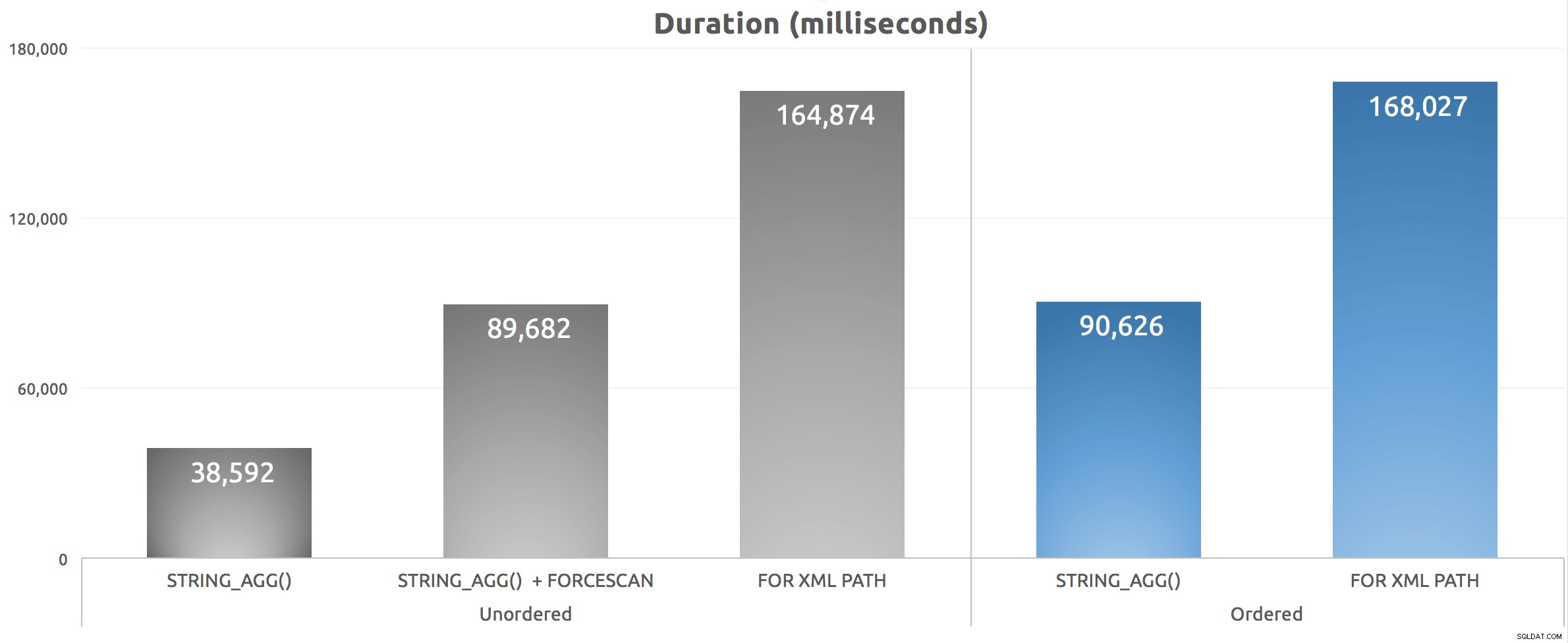 さまざまなグループ化された連結アプローチの期間(ミリ秒)
さまざまなグループ化された連結アプローチの期間(ミリ秒)
FORCESCAN ヒントは実際に事態を悪化させました。コストをクラスター化されたインデックスシークからシフトしましたが、推定コストが比較的同等であると見なしたとしても、実際にはソートははるかに悪化しました。さらに重要なのは、 STRING_AGG()であることがわかります。 連結された文字列を特定の方法で並べ替える必要があるかどうかに関係なく、パフォーマンス上の利点があります。 STRING_SPLIT()と同様 、3月に振り返ったところ、この関数は「v1」よりもかなり前にスケーリングされていることに非常に感銘を受けました。
おそらく将来の投稿のために、さらにテストを計画しています:
- すべてのデータが単一のテーブルからのものであり、順序付けをサポートするインデックスがある場合とない場合
- Linuxでの同様のパフォーマンステスト
それまでの間、グループ化された連結の特定のユースケースがある場合は、以下で共有してください(または、abertrand @ sentryone.comに電子メールを送信してください)。私は自分のテストが可能な限り現実の世界であることを確認することに常にオープンです。