先週、新しいSTRING_AGG()を使用して、パフォーマンスを簡単に比較しました。 従来のFOR XML PATHに対して機能します 私が長年使ってきたアプローチ。未定義/任意の順序と明示的な順序の両方、およびSTRING_AGG()をテストしました どちらの場合もトップになりました:
- SQL Server v.Next:STRING_AGG()パフォーマンス、パート1
これらのテストでは、いくつかのことを省略しました(すべてを意図的にではありません):
- Mikael ErikssonとGrzegorzŁypはどちらも、私が絶対的に最も効率的な
FOR XML PATHを使用していないことを指摘しました。 構築します(そして明確にするために、私は決して持っていません)。 - Linuxではテストを実行しませんでした。 Windowsのみ。それらが大きく異なるとは思いませんが、Grzegorzは非常に異なる期間を見たので、これはさらに調査する価値があります。
- また、出力が有限の非LOB文字列である場合にのみテストしました。これは、最も一般的な使用例であると思います(通常、テーブル内のすべての行を1つのコンマ区切りに連結することはないと思います)。文字列ですが、これが以前の投稿でユースケースを尋ねた理由です)。
- 順序付けテストでは、役立つ可能性のあるインデックスを作成しませんでした(または、すべてのデータが単一のテーブルから取得されたものを試してみました)。
この投稿では、これらの項目のいくつかを扱いますが、すべてではありません。
XMLパスの場合
私は以下を使用していました:
... FOR XML PATH, TYPE).value(N'.[1]', ...
Mikaelからのこのコメントの後、代わりにこのわずかに異なる構成を使用するようにコードを更新しました:
... FOR XML PATH(''), TYPE).value(N'text()[1]', ... LinuxとWindows
当初、私はWindowsでテストを実行することしか気にしませんでした:
Microsoft SQL Server vNext (CTP1.1) - 14.0.100.187 (X64) Dec 10 2016 02:51:11 Copyright (C) 2016 Microsoft Corporation. All rights reserved. Developer Edition (64-bit) on Windows Server 2016 Datacenter 6.3(Build 14393: ) (Hypervisor)
しかし、Grzegorzは、彼(そしておそらく他の多くの人)はCTP1.1のLinuxフレーバーにしかアクセスできなかったと公正に指摘しました。そこで、Linuxをテストマトリックスに追加しました:
Microsoft SQL Server vNext (CTP1.1) - 14.0.100.187 (X64) Dec 10 2016 02:51:11 Copyright (C) 2016 Microsoft Corporation. All rights reserved. on Linux (Ubuntu 16.04.1 LTS)
いくつかの興味深いが完全に接線方向の観察:
-
@@VERSIONこのビルドではエディションは表示されませんが、SERVERPROPERTY('Edition')期待されるDeveloper Edition (64-bit)を返します 。 - バイナリにエンコードされたビルド時間に基づくと、WindowsバージョンとLinuxバージョンは、同じソースから同時にコンパイルされているように見えます。または、これは1つのクレイジーな偶然の一致でした。
順序付けられていないテスト
最初に、任意の順序の出力をテストしました(連結された値の順序が明示的に定義されていない場合)。 Grzegorzに続いて、WideWorldImporters(Standard)を使用しましたが、Sales.Orders間の結合を実行しました およびSales.OrderLines 。ここでの架空の要件は、すべての注文のリストと、各注文とともに、各StockItemIDのコンマ区切りのリストを出力することです。 。
StockItemID以降 は整数です。定義されたvarcharを使用できます 、つまり、MAXが必要になることを心配する前に、文字列を8000文字にすることができます。 intは最大長11(符号なしの場合は実際には10)にコンマを加えたものにすることができるため、これは、最悪のシナリオでは、注文が約8,000 / 12(666)の在庫アイテムをサポートする必要があることを意味します(たとえば、すべてのStockItemID値が11桁)。この場合、最長のIDは3桁であるため、データが追加されるまで、MAXを正当化するために、実際には1回の注文で8,000 / 4(2,000)個の一意の在庫アイテムが必要になります。私たちの場合、在庫アイテムは全部で227個しかないので、MAXは必要ありませんが、注意が必要です。シナリオでこのような大きな文字列が可能である場合は、varchar(max)を使用する必要があります デフォルトの代わりに(STRING_AGG() nvarchar(max)を返します 、ただし、 input でない限り、8,000バイトに切り捨てられます MAXタイプです。
最初のクエリ(サンプル出力を表示し、1回の実行の期間を監視するため):
SET STATISTICS TIME ON;
GO
SELECT o.OrderID, StockItemIDs = STRING_AGG(ol.StockItemID, ',')
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
SELECT o.OrderID,
StockItemIDs = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Sample output:
OrderID StockItemIDs
======= ============
1 67
2 50,10
3 114
4 206,130,50
5 128,121,155
Important SET STATISTICS TIME metrics (SQL Server Execution Times):
Windows:
STRING_AGG: CPU time = 217 ms, elapsed time = 405 ms.
FOR XML PATH: CPU time = 1954 ms, elapsed time = 2097 ms.
Linux:
STRING_AGG: CPU time = 627 ms, elapsed time = 472 ms.
FOR XML PATH: CPU time = 2188 ms, elapsed time = 2223 ms.
*/
解析およびコンパイル時のデータは常に正確にゼロであるか、無関係であるために十分に近いため、無視しました。各実行の実行時間にはわずかな違いがありましたが、それほど多くはありませんでした。上記のコメントは、実行時の一般的なデルタを反映しています(STRING_AGG そこでは並列処理を少し利用しているように見えましたが、Linuxでのみ、FOR XML PATH どちらのプラットフォームにもありませんでした)。どちらのマシンにも、単一のソケット、クアッドコアCPUが割り当てられ、8 GBのメモリがあり、すぐに使用できる構成であり、その他のアクティビティはありませんでした。
次に、大規模なテストを行いたいと思いました(1つのセッションで同じクエリを500回実行するだけです)。上記のクエリのように、すべての出力を500回返したくありませんでした。これは、SSMSを圧倒してしまうためです。そして、とにかく実際のクエリシナリオを表していないことを願っています。そこで、出力を変数に割り当て、各バッチの全体の時間を測定しました。
SELECT sysdatetime();
GO
DECLARE @i int, @x varchar(8000);
SELECT @i = o.OrderID, @x = STRING_AGG(ol.StockItemID, ',')
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int, @x varchar(8000);
SELECT @i = o.OrderID,
@x = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime(); 私はこれらのテストを3回実行しましたが、その違いは非常に大きく、ほぼ1桁でした。 3つのテストの平均期間は次のとおりです。
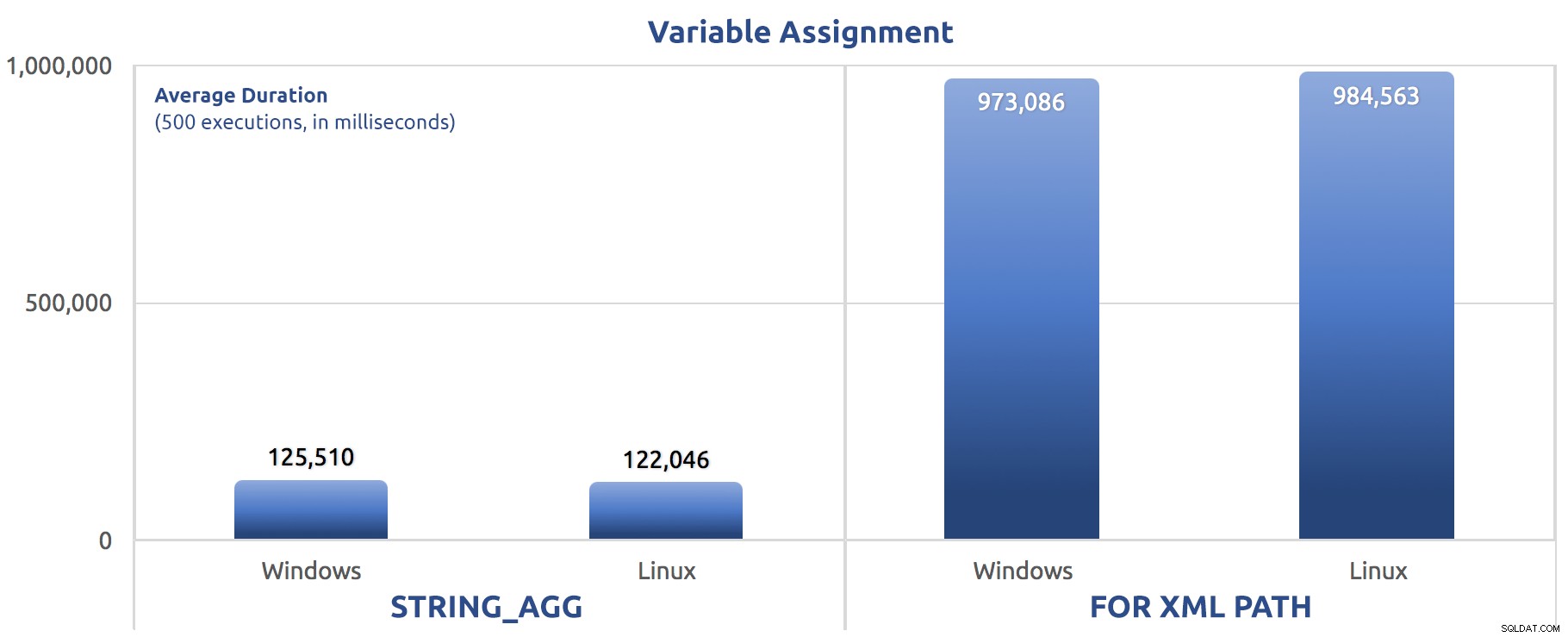 変数割り当てを500回実行した場合の平均期間(ミリ秒)
変数割り当てを500回実行した場合の平均期間(ミリ秒)
この方法で他のさまざまなこともテストしました。主に、Grzegorzが実行しているテストの種類(LOB部分なし)をカバーしていることを確認するためです。
- 出力の長さだけを選択する
- (任意の行の)出力の最大長を取得する
- すべての出力を新しいテーブルに選択する
出力の長さだけを選択する
このコードは、各注文を実行し、すべてのStockItemID値を連結して、長さだけを返します。
SET STATISTICS TIME ON;
GO
SELECT LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
SELECT LEN(STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 142 ms, elapsed time = 351 ms.
FOR XML PATH: CPU time = 1984 ms, elapsed time = 2120 ms.
Linux:
STRING_AGG: CPU time = 310 ms, elapsed time = 191 ms.
FOR XML PATH: CPU time = 2149 ms, elapsed time = 2167 ms.
*/ バッチバージョンの場合も、多くの結果セットをSSMSに返そうとするのではなく、変数の割り当てを使用しました。変数の割り当ては最終的に任意の行になりますが、任意の行が最初に選択されていないため、これでもフルスキャンが必要です。
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = LEN(STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime(); 500回の実行のパフォーマンスメトリック:
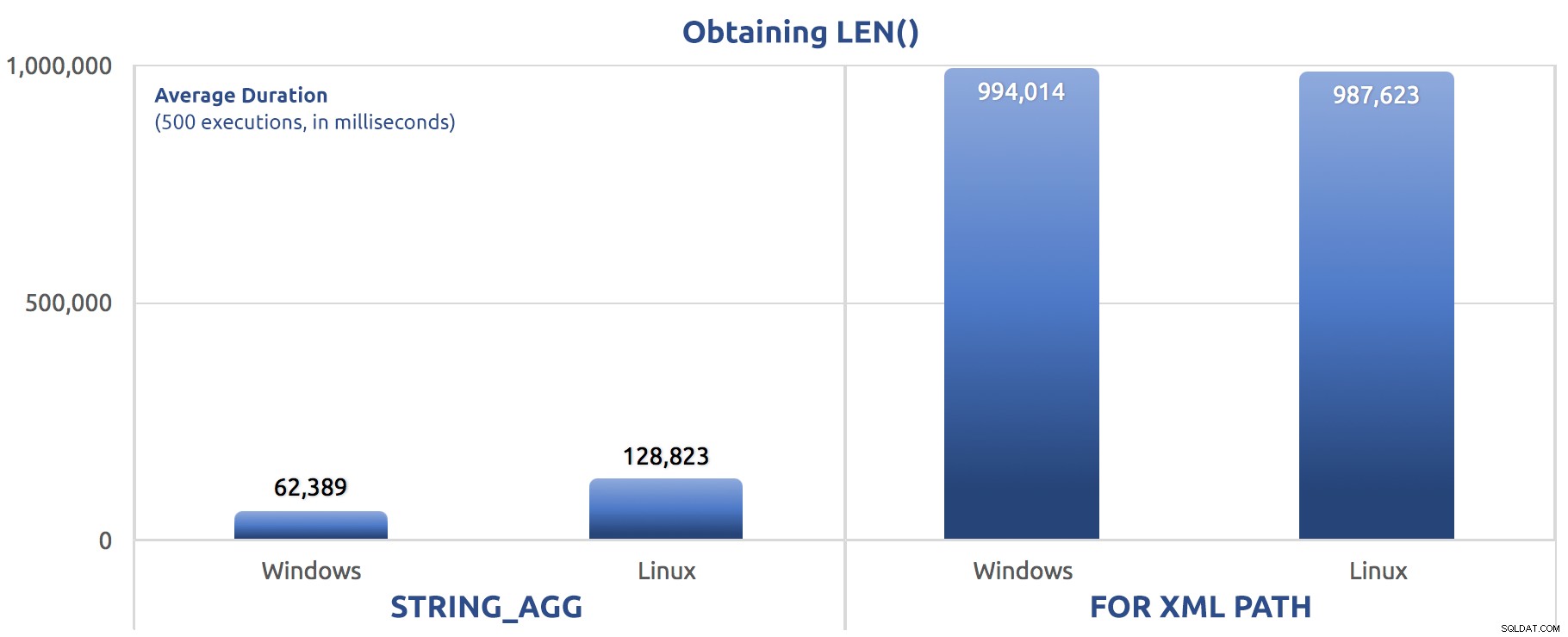 LEN()を変数に割り当てる500回の実行
LEN()を変数に割り当てる500回の実行
ここでも、FOR XML PATHが表示されます。 WindowsとLinuxの両方で、はるかに低速です。
出力の最大長の選択
前のテストとは少し異なりますが、これは最大を取得するだけです。 連結された出力の長さ:
SET STATISTICS TIME ON;
GO
SELECT MAX(s) FROM (SELECT s = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID) AS x;
GO
SELECT MAX(s) FROM (SELECT s = LEN(STUFF(
(SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),
1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID) AS x;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 188 ms, elapsed time = 48 ms.
FOR XML PATH: CPU time = 1891 ms, elapsed time = 907 ms.
Linux:
STRING_AGG: CPU time = 270 ms, elapsed time = 83 ms.
FOR XML PATH: CPU time = 2725 ms, elapsed time = 1205 ms.
*/ そして大規模に、その出力を変数に再度割り当てるだけです:
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = MAX(s) FROM (SELECT s = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID) AS x;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = MAX(s) FROM (SELECT s = LEN(STUFF
(
(SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),
1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID) AS x;
GO 500
SELECT sysdatetime(); 3回の実行で平均した500回の実行のパフォーマンス結果:
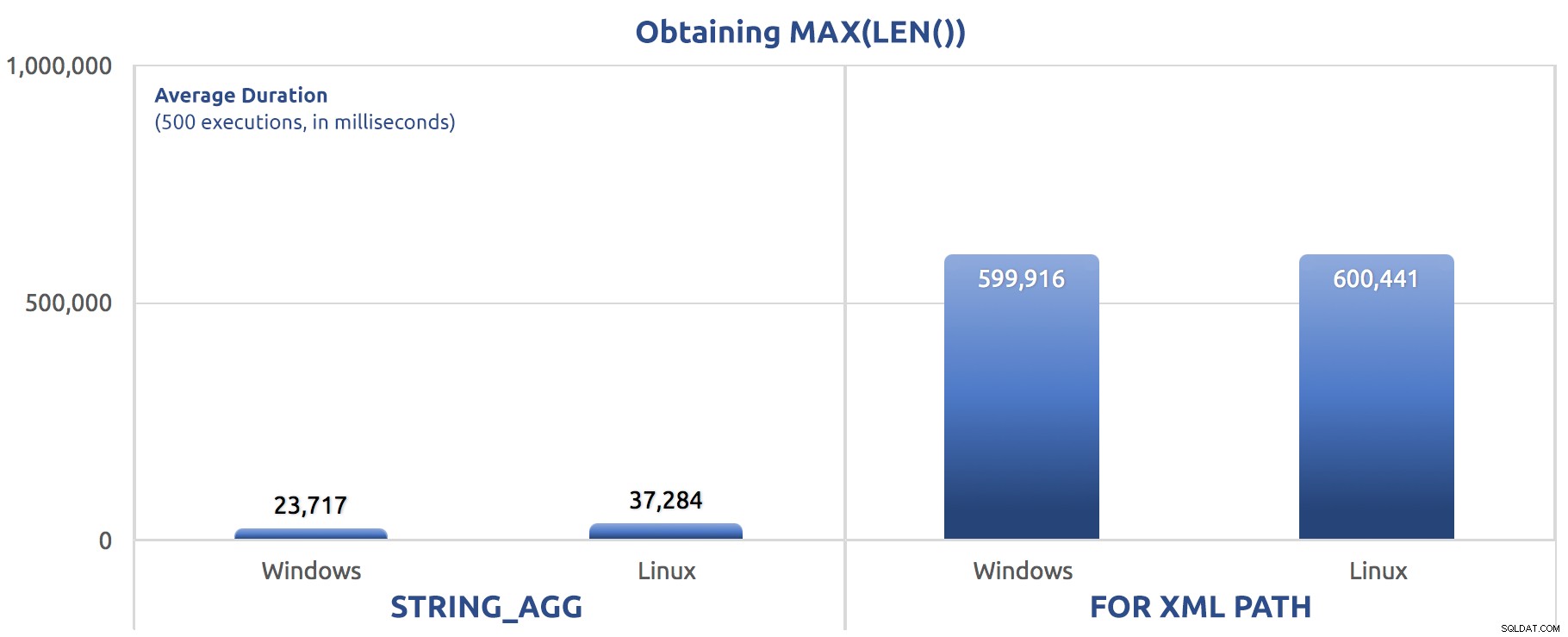 MAX(LEN())を変数に割り当てる500回の実行
MAX(LEN())を変数に割り当てる500回の実行
これらのテスト全体でパターンに気付くかもしれません– FOR XML PATH 以前の投稿で提案されたパフォーマンスの改善があっても、常に犬です。
SELECT INTO
連結の方法が書き込みに影響を与えたかどうかを確認したかったのです。 他のいくつかのシナリオの場合のように、データをディスクに戻します:
SET NOCOUNT ON;
GO
SET STATISTICS TIME ON;
GO
DROP TABLE IF EXISTS dbo.HoldingTank_AGG;
SELECT o.OrderID, x = STRING_AGG(ol.StockItemID, ',')
INTO dbo.HoldingTank_AGG
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
DROP TABLE IF EXISTS dbo.HoldingTank_XML;
SELECT o.OrderID, x = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
INTO dbo.HoldingTank_XML
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 218 ms, elapsed time = 90 ms.
FOR XML PATH: CPU time = 4202 ms, elapsed time = 1520 ms.
Linux:
STRING_AGG: CPU time = 277 ms, elapsed time = 108 ms.
FOR XML PATH: CPU time = 4308 ms, elapsed time = 1583 ms.
*/
この場合、おそらくSELECT INTO 少し並列処理を利用できましたが、それでもFOR XML PATHが表示されます。 STRING_AGGよりも1桁長いランタイムでの苦労 。
バッチバージョンでは、SETSTATISTICSコマンドがSELECT sysdatetime();に置き換えられました。 同じGO 500を追加しました 前のテストと同様に、2つの主要なバッチの後。これがどのようにパンアウトしたかです(これも、以前に聞いたことがあるかどうか教えてください):
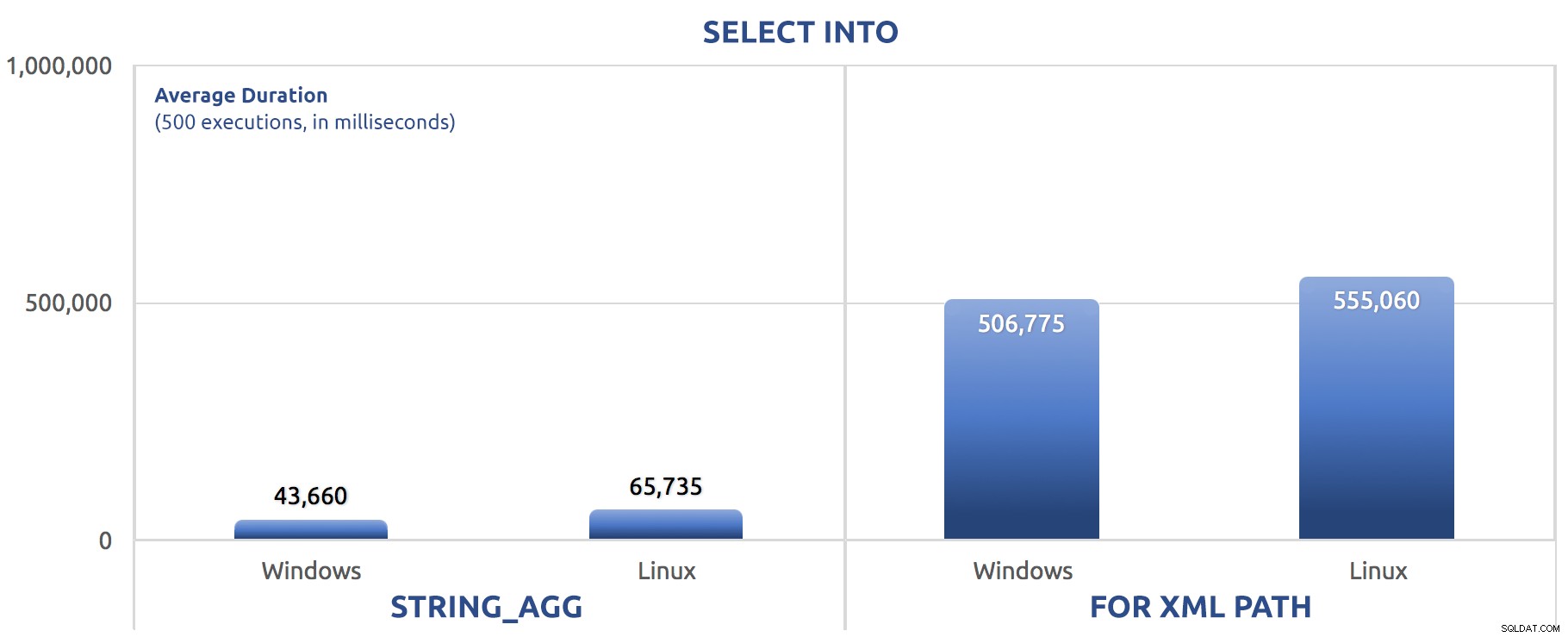 500回のSELECTINTOの実行
500回のSELECTINTOの実行
注文したテスト
順序付けられた構文を使用して同じテストを実行しました。例:
... STRING_AGG(ol.StockItemID, ',')
WITHIN GROUP (ORDER BY ol.StockItemID) ...
... WHERE ol.OrderID = o.OrderID
ORDER BY ol.StockItemID
FOR XML PATH('') ... これは何にもほとんど影響を与えませんでした。4つのテストリグの同じセットは、全体的にほぼ同じメトリックとパターンを示しました。
連結された出力が非LOBの場合、または連結で文字列を並べ替える必要がある場合(サポートインデックスの有無にかかわらず)、これが異なるかどうかを確認したいと思います。
結論
非LOB文字列の場合 、STRING_AGG FOR XML PATHよりもパフォーマンスが大幅に向上します 、WindowsとLinuxの両方で。 varchar(max)の要件を回避するために注意してください またはnvarchar(max) 、Grzegorzが実行したテストに似たものは使用しませんでした。つまり、列のすべての値をテーブル全体で1つの文字列に連結するだけでした。次の投稿では、連結された文字列の出力が8,000バイトを超える可能性があるため、LOBタイプと変換を使用する必要があるユースケースを見ていきます。