こんにちは、
SQL Serverデータベースでのインデックスの使用は、パフォーマンス、速度、およびメモリの節約が最も必要な環境で発生します。
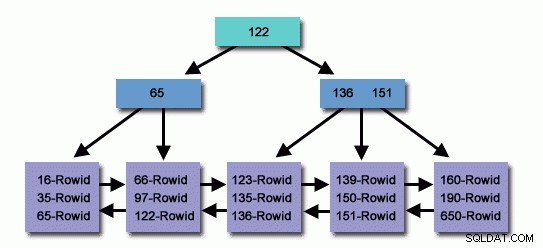
数百万または数十億のレコードがあるテーブルでは、インデックスを使用して、読み取るレコードを減らし、検索を減らして関連するレコードを見つけることができます。
正確に作成されたインデックス、データベース内の数百万のレコードを非常に短時間で検索して、発信者の利便性のレコードを取得すると同時に、ターゲットレコードに到達することでレコードの読み取りを減らし、オペレーティングシステムのリソースを有効に活用します。
テーブルに対するほとんどの読み取り専用クエリのインデックスを作成する必要があります。削除、更新操作が読み取り専用クエリ以上のものである場合は、そのテーブルにインデックスを作成しないでください。
次のスクリプトを使用して、SQLServerの欠落しているインデックスの推奨事項を確認できます。欠落しているインデックスを作成することはできますが、これらのインデックスを監視する必要があります。役に立たない場合は、削除する必要があります。
SELECT MID.[statement] AS ObjectName
,MID.equality_columns AS EqualityColumns
,MID.inequality_columns AS InequalityColms
,MID.included_columns AS IncludedColumns
,MIGS.last_user_seek AS LastUserSeek
,MIGS.avg_total_user_cost
* MIGS.avg_user_impact
* (MIGS.user_seeks + MIGS.user_scans) AS Impact
,N'CREATE NONCLUSTERED INDEX <TYPE_Index_Name> ' +
N'ON ' + MID.[statement] +
N' (' + MID.equality_columns
+ ISNULL(', ' + MID.inequality_columns, N'') +
N') ' + ISNULL(N'INCLUDE (' + MID.included_columns + N');', ';')
AS CreateStatement
FROM sys.dm_db_missing_index_group_stats AS MIGS
INNER JOIN sys.dm_db_missing_index_groups AS MIG
ON MIGS.group_handle = MIG.index_group_handle
INNER JOIN sys.dm_db_missing_index_details AS MID
ON MIG.index_handle = MID.index_handle
WHERE database_id = DB_ID()
AND MIGS.last_user_seek >= DATEDIFF(month, GetDate(), -1)
ORDER BY Impact DESC;