単一障害点(SPOF)は、組織がデータベース環境の存在を地理的に別の場所に分散することに取り組んでいる一般的な理由です。これは、ディザスタリカバリとビジネス継続性の戦略計画の一部です。
ディザスタリカバリ(DR)計画は、自然災害、事故(人為的ミスなど)、またはインシデント(犯罪行為など)などの予期しない問題への準備をカバーする技術手順を具体化します。
過去10年間、データベース環境を地理的に複数の場所に分散することは非常に一般的な設定でした。パブリッククラウドはこれに対処するための多くの方法を提供するためです。課題は、データベース環境のセットアップにあります。データベースを管理したり、データを別の地理的場所に移動したり、高レベルの可観測性を備えたセキュリティを適用したりしようとすると、課題が発生します。
このブログでは、MySQLレプリケーションを使用してこれを行う方法を紹介します。 MySQLクラスターの現在の地域から離れた別の国にある別のデータベースノードにデータをコピーする方法について説明します。この例では、ターゲット地域は私たち東部に基づいていますが、オンプレミスはフィリピンにあるアジアにあります。
ジオロケーションデータベースクラスターが必要なのはなぜですか?
このタイプの問題は、事業継続計画の際に予測する必要があります。定義された内容に基づいて分析および実装されている必要があります。 MySQLデータベースのビジネス継続性には、高い稼働時間が含まれている必要があります。一部の環境では、ベンチマークを実行し、脆弱性、脆弱性の回復力、データベースインフラストラクチャを含むテクノロジアーキテクチャのスケーラブル性を明らかにするために、弱点を含む厳格なテストの高い基準を設定しています。ビジネス、特に大量のトランザクションを処理するビジネスでは、大災害が発生した場合でも、アプリケーションで本番データベースを常に利用できるようにすることが不可欠です。そうしないと、ダウンタイムが発生し、多額の費用がかかる可能性があります。
これらの特定されたシナリオにより、組織はインフラストラクチャをさまざまなクラウドプロバイダーに拡張し、ノードをさまざまな地理的場所に配置して、稼働時間を長くし(99.99999999999で可能であれば)、RPOを低くし、SPOFをなくします。
本番データベースが災害に耐えられるようにするには、ディザスタリカバリ(DR)サイトを構成する必要があります。本番サイトとDRサイトは、地理的に離れた2つのデータセンターの一部である必要があります。つまり、本番データベースで発生するデータ変更がトランザクションログを介してスタンバイデータベースに即座に同期されるように、本番データベースごとにDRサイトでスタンバイデータベースを構成する必要があります。一部のセットアップでは、DRノードを使用して読み取りを処理し、アプリケーションとデータレイヤー間の負荷分散を提供します。
このブログでは、必要なセットアップは単純ですが、今日では非常に一般的な実装です。このブログに必要なアーキテクチャの設定については、以下を参照してください。
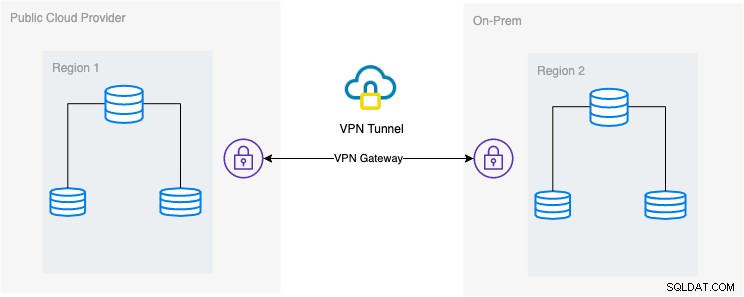
このブログでは、パブリックとしてGoogle Cloud Platform(GCP)を選択していますクラウドプロバイダーであり、ローカルネットワークをオンプレミスデータベース環境として使用しています。
このタイプの設計を使用する場合、非常に安全な方法で通信するには、環境とプラットフォームの両方が常に必要である必要があります。 VPNを使用するか、AWSDirectConnectなどの代替手段を使用します。これらのパブリッククラウドは現在、使用できるマネージドVPNサービスを提供しています。ただし、このブログでは高度なハードウェアやサービスを必要としないため、このセットアップではOpenVPNを使用します。
MySQL / Percona / MariaDBデータベース環境の場合、データベースのバックアップコピーを作成し、ターゲットノードに送信してデプロイまたはインスタンス化するのが最善かつ効率的な方法です。このアプローチを使用するには、mysqldump、mydumper、rsyncを使用するか、Percona XtraBackup/Mariabackupを使用してデータをターゲットノードにストリーミングするさまざまな方法があります。
mysqldumpの使用
mysqldumpは、データベース全体の論理バックアップを作成します。または、ダンプするデータベース、テーブル、または特定のレコードのリストを選択的に選択することもできます。
$ mysqldump --single-transaction --all-databases --triggers --routines --events --master-data | mysql -h <target-host-db-node -u<user> -p<password> -vvv --show-warningsこの単純なコマンドを使用すると、MySQLステートメントをターゲットデータベースノード(たとえば、Google Compute Engineのターゲットデータベースノード)に対して直接実行します。これは、データが小さい場合や帯域幅が速い場合に効率的です。それ以外の場合は、データベースをファイルにパックしてから、ターゲットノードに送信することもできます。
$ mysqldump --single-transaction --all-databases --triggers --routines --events --master-data | gzip > mydata.db
$ scp mydata.db <target-host>:/some/path次に、ターゲットデータベースノードに対してmysqldumpを実行します。
zcat mydata.db | mysqlmysqldumpを使用して論理バックアップを使用する場合の欠点は、速度が遅く、ディスク領域を消費することです。また、単一のスレッドを使用するため、これを並行して実行することはできません。オプションで、特にデータが大きすぎる場合にmydumperを使用できます。 mydumperは並行して実行できますが、mysqldumpと比較して柔軟性がありません。
xtrabackupの使用
xtrabackupは、ストリームまたはバイナリをターゲットノードに送信できる物理バックアップです。これは非常に効率的であり、ネットワークを介してバックアップをストリーミングする場合、特にターゲットノードが異なる地域または異なる地域にある場合に主に使用されます。 ClusterControlは、アクションの前にアクセスと権限が設定されている限り、新しいスレーブがどこにあるかに関係なく、新しいスレーブをプロビジョニングまたはインスタンス化するときにxtrabackupを使用します。
xtrabackupを使用して手動で実行している場合は、コマンドをそのまま実行できます。
##ターゲットノード
$ socat -u tcp-listen:9999,reuseaddr stdout 2>/tmp/netcat.log | xbstream -x -C /var/lib/mysql##ソースノード
$ innobackupex --defaults-file=/etc/my.cnf --stream=xbstream --socket=/var/lib/mysql/mysql.sock --host=localhost --tmpdir=/tmp /tmp | socat -u stdio TCP:192.168.10.70:9999これら2つのコマンドを詳しく説明するには、最初のコマンドを実行するか、ターゲットノードで最初に実行する必要があります。 target nodeコマンドは、ポート9999でリッスンし、ポート9999から受信したすべてのストリームをターゲットノードに書き込みます。これはコマンドsocatとxbstreamに依存しているため、これらのパッケージがインストールされていることを確認する必要があります。
ソースノードで、バックグラウンドでxtrabackupを呼び出し、xbstreamを使用してネットワーク経由で送信されるデータをストリーミングするinnobackupexperlスクリプトを実行します。 socatコマンドは、ポート9999を開き、そのデータを目的のホスト(この例では192.168.10.70)に送信します。それでも、このコマンドを使用するときは、socatとxbstreamがインストールされていることを確認してください。 socatを使用する別の方法はncですが、socatは、複数のクライアントがポートでリッスンできるようなシリアル化など、ncと比較してより高度な機能を提供します。
ClusterControlは、スレーブを再構築するとき、または新しいスレーブを構築するときにこのコマンドを使用します。高速で、ソースデータの正確なコピーがターゲットノードにコピーされることが保証されます。新しいデータベースを別の地理的場所にプロビジョニングする場合、このアプローチを使用すると、効率が向上し、ジョブを完了する速度が向上します。ただし、ネットワークを介してストリーミングするときに論理バックアップまたはバイナリバックアップを使用する場合は、長所と短所があります。この方法を使用することは、新しいジオロケーションデータベースクラスターを別の地域にセットアップし、データベース環境の正確なコピーを作成するときに非常に一般的なアプローチです。
効率、可観測性、速度
このアプローチに精通していないほとんどの人が残した質問は、常に「方法、内容、場所」の問題をカバーしています。このセクションでは、処理する作業を減らしてジオロケーションデータベースを効率的にセットアップする方法と、失敗する理由の可観測性について説明します。 ClusterControlの使用は非常に効率的です。私が持っているこの現在のセットアップでは、最初に実装された次の環境:
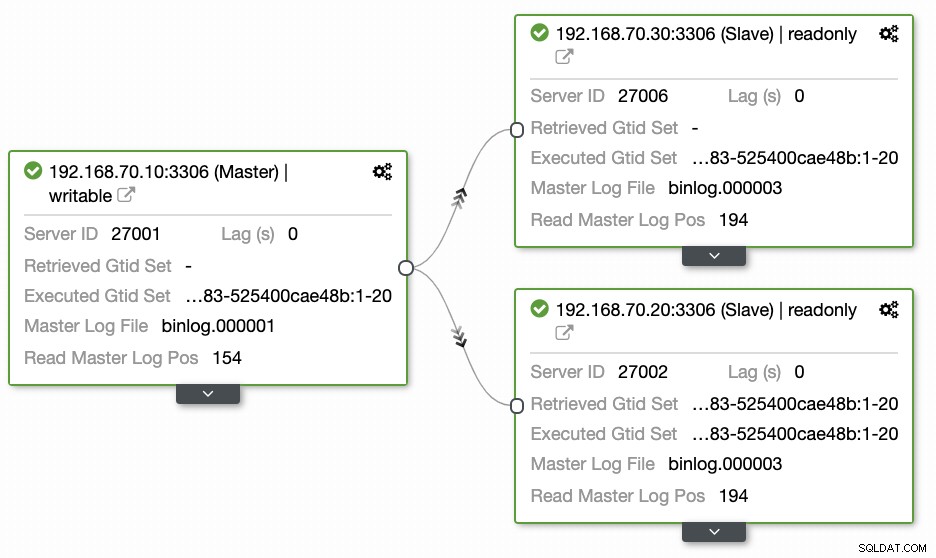
ジオロケーションデータベースクラスターのセットアップを開始し、クラスターを拡張してクラスターのスナップショットコピーを作成するには、新しいスレーブを追加できます。前述のように、ClusterControlはxtrabackup(MariaDB 10.2以降のmariabackup)を使用して、クラスター内に新しいノードをデプロイします。 GCP計算ノードをターゲットノードとして登録する前に、ClusterControlに登録したシステムユーザーと同じ適切なシステムユーザーを最初に設定する必要があります。これは、/ etc / cmon.d / cmon_X.cnfで確認できます。ここで、Xはcluster_idです。たとえば、以下を参照してください:
# grep 'ssh_user' /etc/cmon.d/cmon_27.cnf
ssh_user=maximusmaximus(この例では)はGCPコンピューティングノードに存在する必要があります。 GCPノードのユーザーには、sudoまたはsuperadmin権限が必要です。また、パスワードなしのSSHアクセスでセットアップする必要があります。システムユーザーとそれに必要な権限について詳しくは、ドキュメントをお読みください。
以下にサーバーのリストの例を示しましょう(GCPコンソールから:Compute Engineダッシュボード):
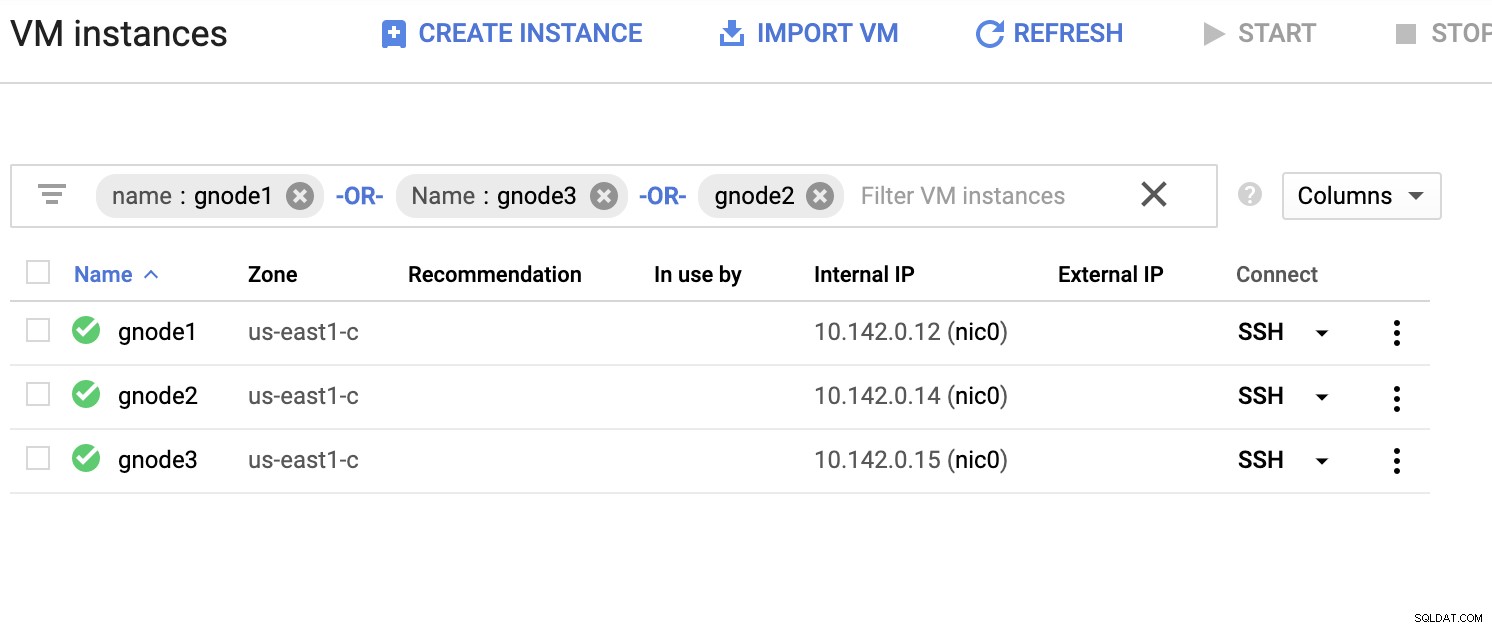
上のスクリーンショットでは、ターゲット地域は米国東部に基づいています領域。前述のように、私のローカルネットワークは、OpenVPNを使用してGCPを通過する安全なレイヤー上にセットアップされています(その逆も同様です)。そのため、GCPからローカルネットワークへの通信もVPNトンネルを介してカプセル化されます。
以下のスクリーンショットは、これを行う方法を示しています。以下の画像を参照してください:
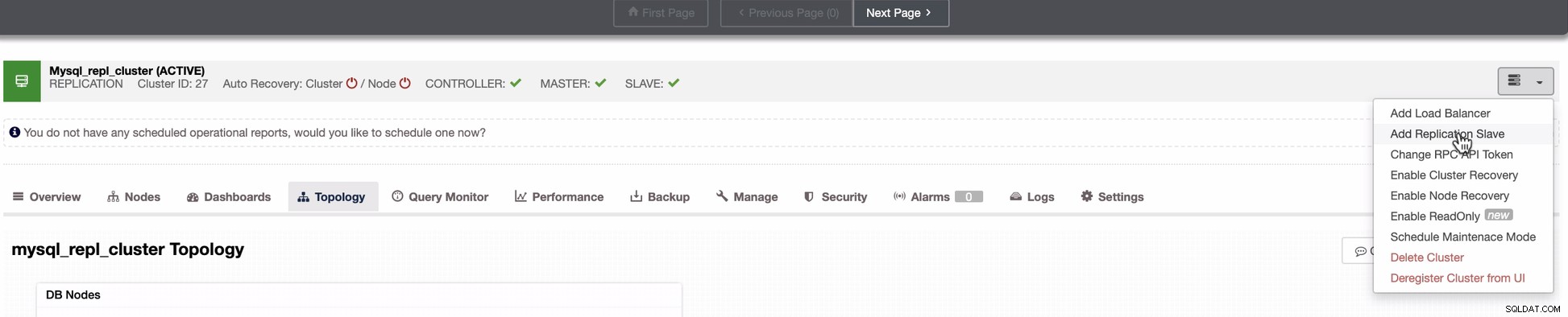
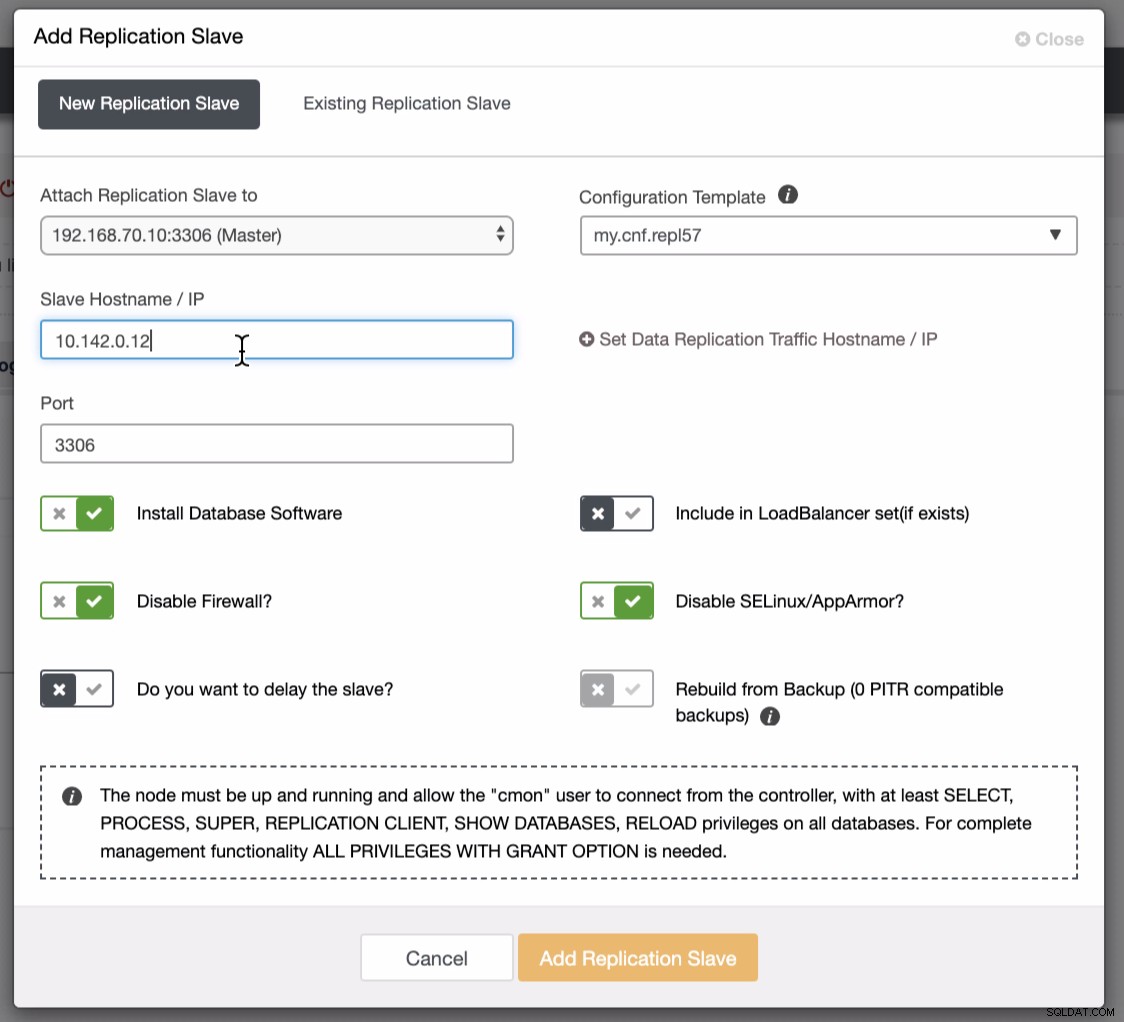
2番目のスクリーンショットに示されているように、ノード10.142.0.12をターゲットにしています。そのソースマスターは192.168.70.10です。 ClusterControlは、実行する必要のあるファイアウォール、セキュリティモジュール、パッケージ、構成、およびセットアップを決定するのに十分なほど賢いです。以下のジョブアクティビティログの例を参照してください:
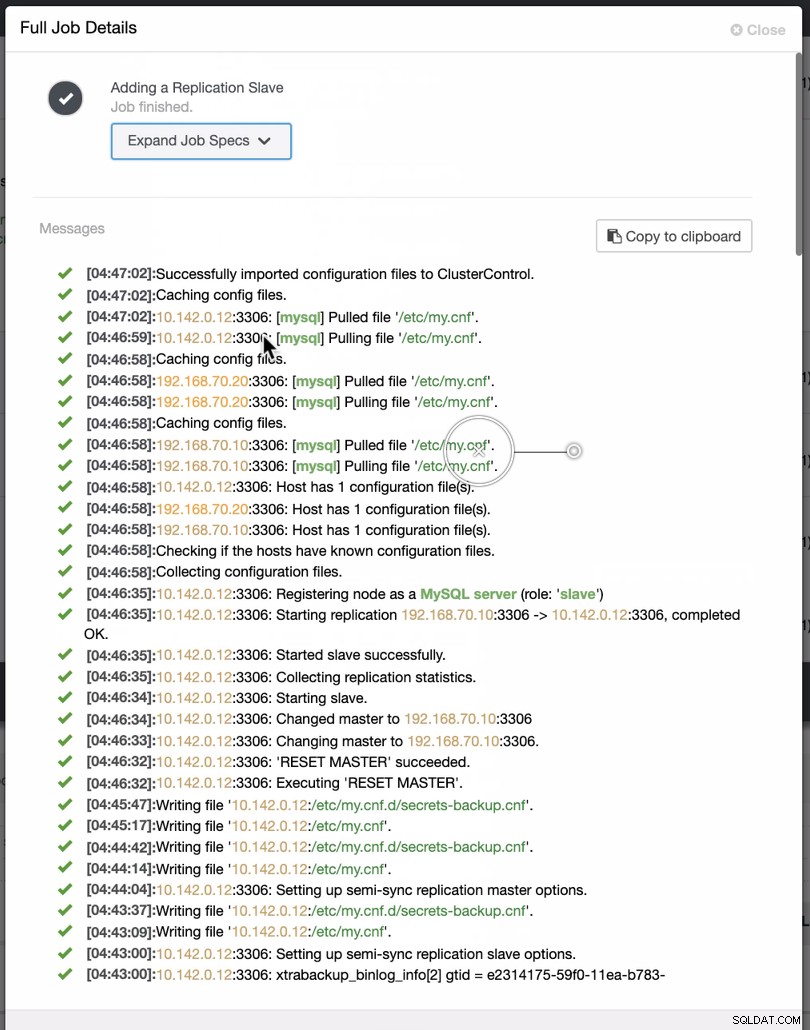
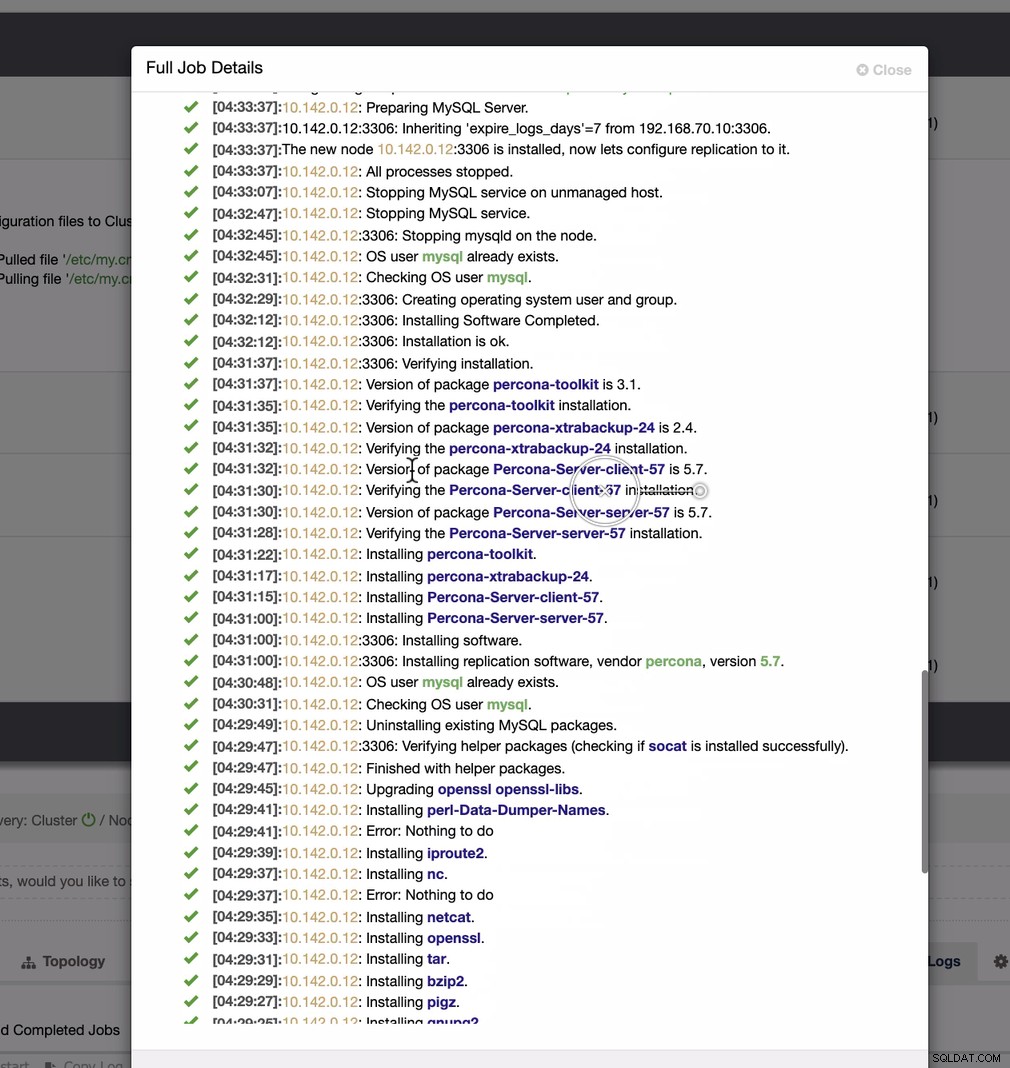
とても簡単な作業ですね。
GCPMySQLクラスターを完成させる
ローカルネットワークの場合と同じように、バランストポロジを実現するには、GCPクラスターにさらに2つのノードを追加する必要があります。 2番目と3番目のノードについては、マスターがGCPノードを指している必要があることを確認してください。この例では、マスターは10.142.0.12です。これを行う方法については、以下をご覧ください
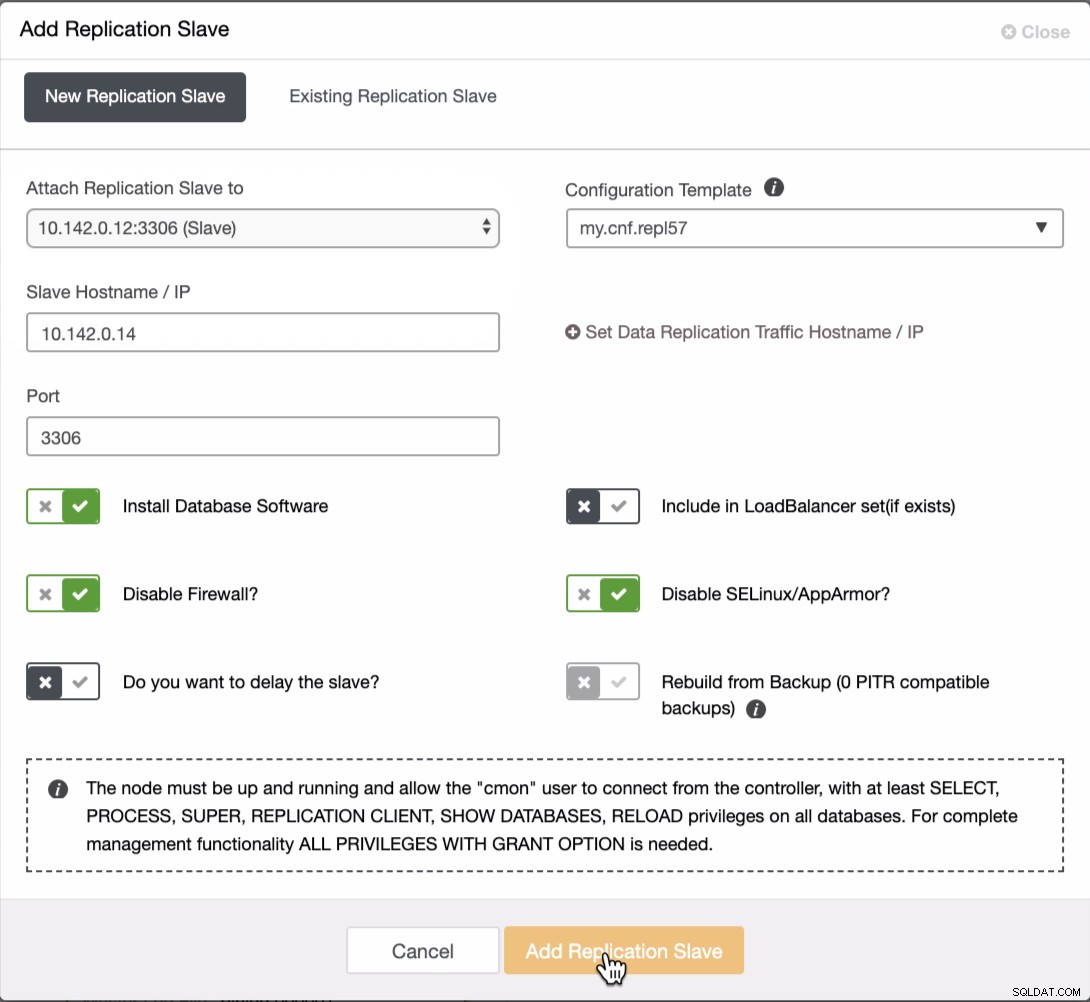
上のスクリーンショットにあるように、10.142.0.12(スレーブ)を選択しました)これは、クラスターに追加した最初のノードです。完全な結果は次のようになります
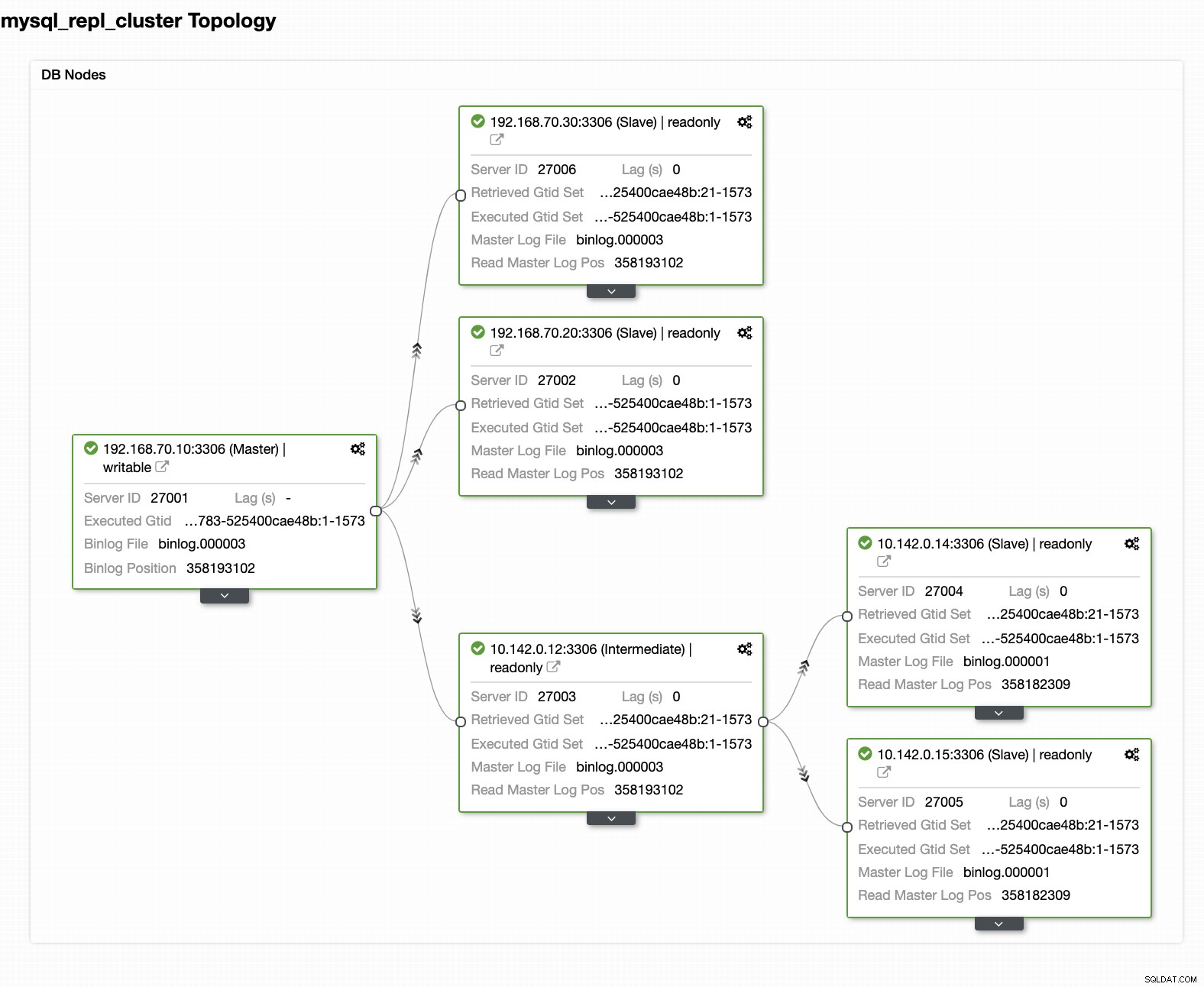
最後のスクリーンショットから、この種のトポロジは理想的な設定ではない可能性があります。ほとんどの場合、DRクラスターがスタンバイクラスターとして機能し、オンプレミスがプライマリアクティブクラスターとして機能するマルチマスターセットアップである必要があります。これを行うには、ClusterControlでは非常に簡単です。この目標を達成するには、次のスクリーンショットを参照してください。
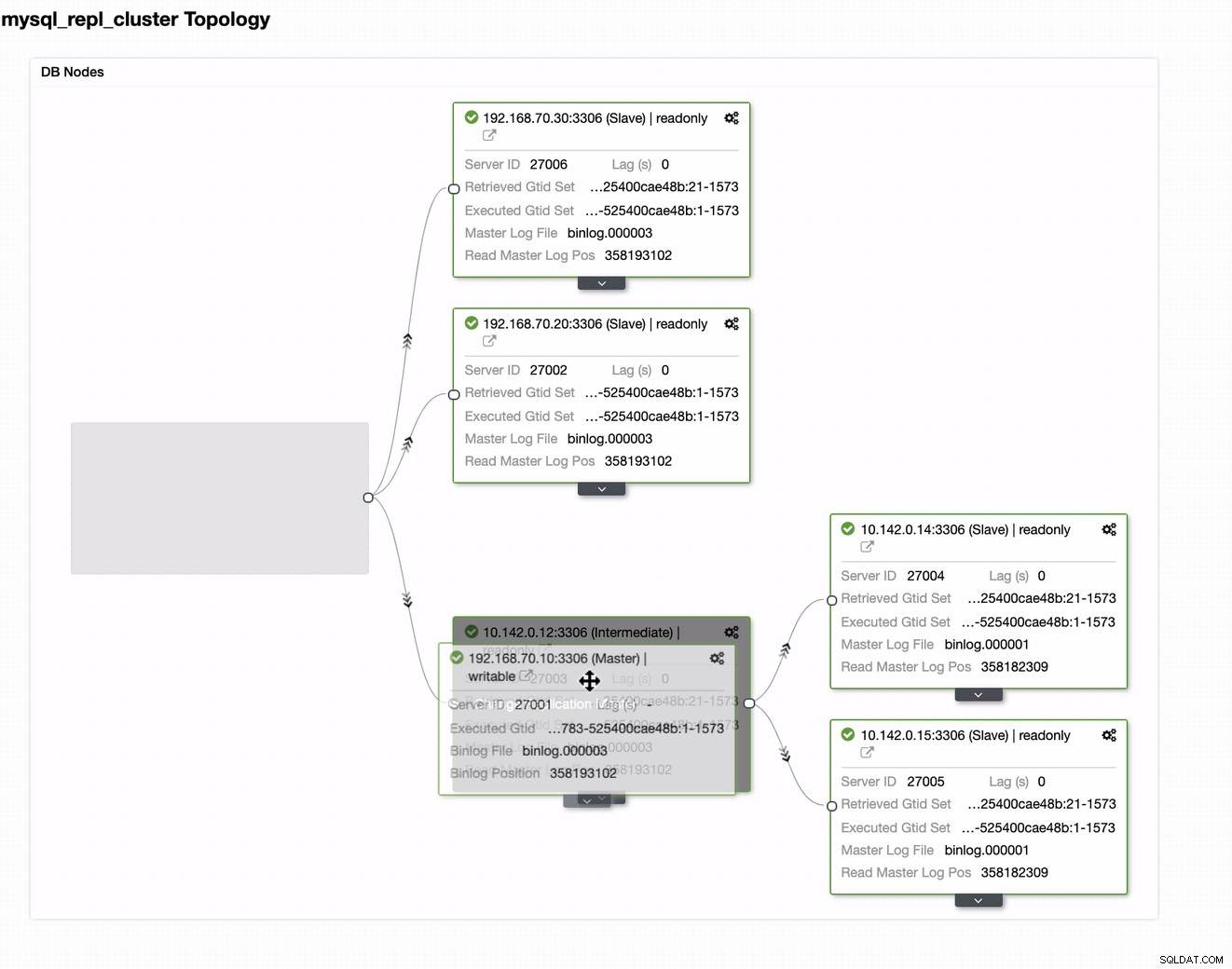
現在のマスターを、必要なターゲットマスターにドラッグするだけです。オンプレミスが危険にさらされた場合に備えて、プライマリスタンバイライターとして設定します。この例では、ターゲットホスト10.142.0.12(GCP計算ノード)をドラッグします。最終結果を以下に示します。
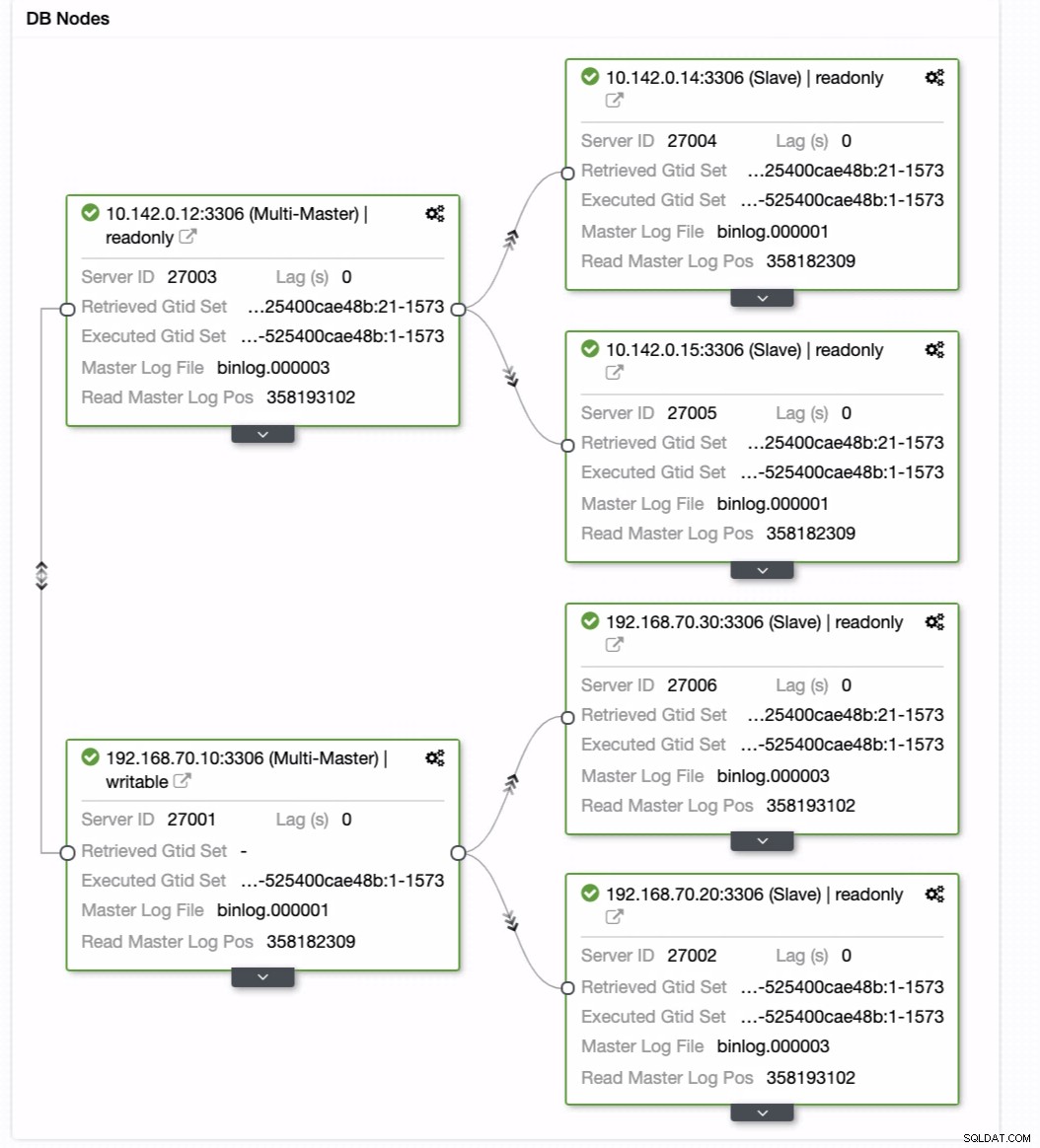
これで、目的の結果が得られます。 MySQLレプリケーションを使用してGeo-LocationDatabaseクラスターを簡単かつ迅速に生成します。
この設定の主なポイントは、セキュリティ、冗長性、および復元力です。また、新しいクラスターを別の地理的地域に展開することがどれほど実現可能で効率的かについても説明します。 ClusterControlはこれを提供できますが、バックアップから効率的に作成し、ClusterControlで新しい別のクラスターを生成できるため、これをより早く改善できると期待しています。しばらくお待ちください。