
前回の記事では、SQLServerのインデックス要件とパフォーマンスに関する考慮事項について説明しました。データベースのパフォーマンスに関しては、パフォーマンスの調整は間違いなく最も重要で複雑な機能の1つです。これは、SQLクエリの最適化、インデックスの調整、システムリソースの調整など、さまざまな分野で構成されています。データをすばやく取得するには、これらすべてを正しく実行する必要があります。
SQL Serverインデックスに関しては、パフォーマンス調整の取り組みとデータベース全体のパフォーマンスの両方に大きな影響を与える可能性があるため、考慮すべき重要な領域がいくつかあります。以下は、それぞれの詳細と、それらが果たす重要な役割です。
SQLServerインデックスのベストプラクティス
1。データベース設計がSQLServerインデックスにどのように影響するかを理解する
インデックス作成の要件は、オンライントランザクション処理(OLTP)データベースとオンライン分析処理(OLAP)データベースで異なります。
OLTPデータベースでは、ユーザーは頻繁に読み取り/書き込み操作を実行し、新しいデータを挿入し、既存のデータを変更します。これらは、データ操作言語クエリ(挿入、更新、削除)と、データの取得および変更のためのSelectステートメントを使用します。 OLTPデータベースの場合、テーブルの[選択済み]列にインデックスを作成するのが最適です。複数のインデックスはパフォーマンスに悪影響を及ぼし、システムリソースにストレスを与える可能性があります。代わりに、インデックス作成の要件を満たすことができる最小数のインデックスを作成することをお勧めします。一方、OLAPデータベースでは、主にSelectステートメントを使用して、さらに分析する目的でデータを取得します。この場合、インデックスごとに複数のキー列を持つインデックスをさらに追加できます。列ストアインデックスを活用して、データウェアハウスクエリでのデータ取得を高速化することもできます
2。ワークロード要件のインデックスを作成する
データベースに新しいテーブルを作成するときは、単にインデックスを盲目的に追加しないでください。開発者は、1つのクラスター化インデックスといくつかの非クラスター化インデックスを、それらのインデックスを使用するクエリを探すことなく配置することがあります。クエリオプティマイザの要件を満たさないインデックスが存在する可能性があります。したがって、ワークロードとSQLクエリ(ストアドプロシージャ、関数、ビュー、およびアドホッククエリ)を適切に分析する必要があります。 SQLプロファイラー、拡張イベント、動的管理ビューを使用してワークロードをキャプチャし、インデックスを作成してリソースを大量に消費するクエリを最適化できます。
3。最も頻繁に使用されるクエリのインデックスを作成する
システムで最も頻繁に使用されるクエリのワークロードをグループ化することが重要です。これらのクエリに最適なインデックスを作成することで、システムへの負担を最小限に抑えることができます。
4。 SQLServerインデックスキー列のベストプラクティスを適用する
1つのテーブルに複数の列を含めることができるため、インデックスキー列に関するいくつかの考慮事項を次に示します。
- text、image、ntext、varchar(max)、nvarchar(max)、およびvarbinary(max)の列は、インデックスキー列では使用できません。
- インデックスキー列で整数データ型を使用することをお勧めします。必要なスペースが少なく、効率的に動作します。このため、通常は整数データ型で主キー列を作成する必要があります。
- XMLデータ型はXMLインデックスでのみ使用できます。
- 一意の値を持つ列の主キーを作成することを検討する必要があります。テーブルに一意の値の列がない場合は、整数データ型のID列を定義できます。主キーは、行分布のクラスター化インデックスも作成します。
- Unique値とNotNULL値を持つ列を有用なインデックスキー候補と見なすことができます。
- Where句の述語に基づいてインデックスを作成する必要があります。たとえば、Where句で使用される列、SQL結合、たとえば、order by、groupby述語などを検討できます。
- 残りのクエリの行数を減らす方法でテーブルを結合する必要があります。これは、クエリオプティマイザが最小限のシステムリソースで実行プランを準備するのに役立ちます。
- インデックスキーに複数の列を使用する場合は、インデックスキーでのそれらの位置を考慮することも重要です。
- インデックスに含まれる列の使用も検討する必要があります。
5。 SQLServerのインデックス列のデータ分布を分析する
SQLServerのインデックスキー列のデータ分布を調べる必要があります。一意でない値を持つ列は、データの取得に遅延を引き起こし、トランザクションが長時間実行される可能性があります。統計のヒストグラムを使用してデータ分布を分析できます。
6。データの並べ替え順序を使用する
クエリとインデックスのデータ並べ替え要件も考慮する必要があります。既定では、SQLServerはデータをインデックスの昇順で並べ替えます。インデックスを昇順で作成し、クエリでOrderBy句を使用してデータを降順で並べ替えるとします。
たとえば、次のクエリの実際の実行プランを見てください。
SELECT [SalesOrderID],>
[UnitPrice]
FROM [AdventureWorks].[Sales].[SalesOrderDetail]
ORDER BY UnitPrice DESC,
SalesOrderID ASC;
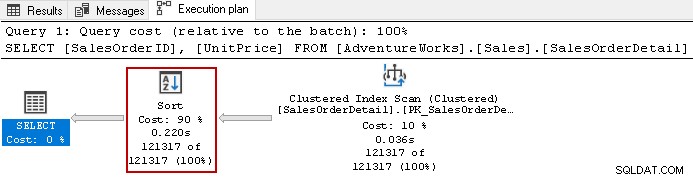
このクエリでは、全体で90%のコストがかかる、コストのかかる並べ替え演算子を使用します。 [UnitPrice]と[SalesOrderID]に非クラスター化インデックスを作成することにしました。インデックスの両方の列にデフォルトの並べ替え順序を使用します。
CREATE NONCLUSTERED INDEX IX_SalesOrderDetail_Unitprice
ON [AdventureWorks].[Sales].[SalesOrderDetail]
(UnitPrice ASC, SalesOrderID ASC);
Selectステートメントを再実行しましたが、クエリオプティマイザは引き続きsort演算子を使用します。非クラスター化インデックスを使用できますが、データを並べ替えて結果を準備します。
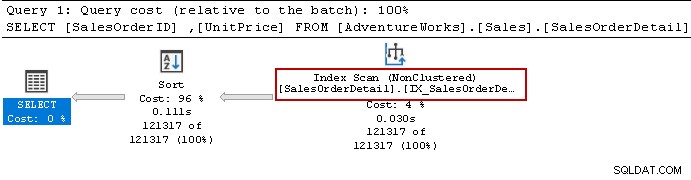
次のクエリを使用してインデックスを再作成しましょう。今回は、インデックス定義の[Unitprice]の降順でデータを並べ替えます。
DROP INDEX IX_SalesOrderDetail_Unitprice ON [AdventureWorks].[Sales].[SalesOrderDetail];
Go CREATE NONCLUSTERED INDEX IX_SalesOrderDetail_Unitprice ON [AdventureWorks].[Sales].[SalesOrderDetail](UnitPrice DESC, SalesOrderID ASC);
Go
インデックスはクエリ要件を満たしているため、ソート演算子は必要ありません。
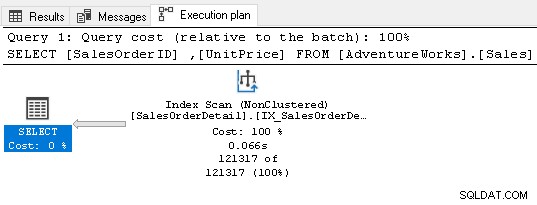
7。 SQLServerインデックスに外部キーを使用する
外部キー列にインデックスを作成する必要があります。クエリのパフォーマンスを向上させるために、外部キーにクラスター化インデックスを作成することをお勧めします。
8。 SQLServerのインデックスストレージに関する考慮事項に注意してください
インデックスストレージも考慮すべき有用な側面です。 SQL Serverは、テーブルの同じファイルグループにすべてのインデックスを作成します。インデックス用に別のファイルグループを検討し、別のディスク上の物理ファイルを分離することができます。これにより、IOのパフォーマンスとスループットが向上します。
同様に、テーブルパーティショニングを使用して、複数のディスクおよびファイルグループ間でデータを分離できます。これらのテーブルパーティションのパーティションインデックスを設計して、同時データアクセスを向上させることができます。
もう1つのオプションは、インデックスの作成または再構築中にFILLFACTORを定義することです。 FILLFACTORは、リーフノードのデータページの空き領域を定義します。これは、さらにデータを挿入する場合に役立ちます。データが静的で頻繁に変更されない場合は、FILLFACTORの値が高いと見なすことができます。一方、頻繁に変更されるデータの場合は、新しいデータを挿入するための十分なスペースを残すことができます。
9。不足しているインデックスを見つける
クエリ実行プランで不足しているSQLServerインデックスに関する情報を取得する場合があります。動的管理ビューを実行して、これらの欠落している索引を見つけることもできます。これらのインデックスをやみくもに作成しないでください。これは単なるクエリオプティマイザの提案ですが、既存のインデックスやワークロード要件は考慮されていません。インデックス定義に複数の列が含まれている場合もあるため、実装する前にこれらの提案を確認してください。
10。非クラスター化インデックスの前に、常にクラスター化インデックスを作成します
一般的なガイドラインとして、非クラスター化インデックスを作成する前に、クラスター化インデックスを作成する必要があります。テーブルにインデックスがない場合、非クラスター化インデックスは行識別子で構成されます。クラスター化インデックスを作成したら、SQL Serverは、これらの非クラスター化インデックスを再構築して、行識別子の代わりにクラスター化インデックスキーを指すことができるようにする必要があります。
11。インデックスのメンテナンスを監視し、統計を更新します
以下は、SQLServerインデックスに関して監視するいくつかのメンテナンス領域です。
- インデックスの断片化を削除 :特にトランザクションの多いテーブルについては、内部および外部の断片化を定期的に確認する必要があります。ワークロードに適切なインデックスがある場合でも、クエリの応答が遅くなる可能性があります。大きく断片化されたインデックスは、追加のIOを必要とするため、パフォーマンスを低下させる可能性があります。フラグメンテーション値に基づいて、インデックスの再編成または再構築を実行できます。通常、断片化が30%を超える場合はインデックスを再構築し、断片化が30%未満の場合はインデックスを再編成する必要があります。
- 未使用のインデックスを削除する: クエリオプティマイザはクエリごとにインデックスを考慮する必要があるため、データベース内の未使用(アイドル)インデックスを常に確認する必要があります。未使用のインデックスもストレージを消費し、メンテナンスのオーバーヘッドを増加させます。
- 統計の更新: データベース構成内で自動更新統計を設定した場合でも、統計を定期的に更新する必要があります。インデックス統計が更新されていない場合、クエリオプティマイザは不適切な実行プランを準備する可能性があります。エージェントジョブをスケジュールして、営業時間後にフルスキャンでSQLServer統計を更新できます。
このトピックの詳細については、SQLインデックスのメンテナンスを参照してください。
SQLServerインデックスのベストプラクティスの適用
最適なSQLServerインデックスを設計する簡単な方法は必ずしもありませんが、この投稿で指定されている推奨事項を適用すると、各データベースタイプとそのワークロードで発生するさまざまなインデックス要件をナビゲートするのに役立ちます。これらのベストプラクティスは、インデックスを最適化してデータベースのパフォーマンスを向上させ、その過程でよりスムーズなパフォーマンス調整プロセスを確保するのに役立ちます。