
SQL Serverインデックスは、データをより迅速に取得し、重要なリソースに影響を与えるボトルネックを減らすために使用されます。データベーステーブルのインデックスは、パフォーマンスの最適化手法として機能します。疑問に思うかもしれませんが、インデックスはクエリのパフォーマンスをどのように向上させるのでしょうか。良いインデックスと悪いインデックスなどはありますか? 50列のテーブルがあるとすると、各列にインデックスを作成することをお勧めしますか?複数のインデックスを作成する場合、SQLクエリの実行速度が向上しますか?
すべてのすばらしい質問ですが、詳しく説明する前に、そもそもなぜインデックスが必要になるのかを知ることが不可欠です。
何千冊もの本が集まっている市立図書館を訪れたと想像してみてください。特定の本を探していますが、どのようにして見つけますか?各本を各ラックで調べた場合、それを見つけるのに数日かかる可能性があります。テーブルに格納されている数百万の行からレコードを検索する場合も、データベースに同じことが当てはまります。
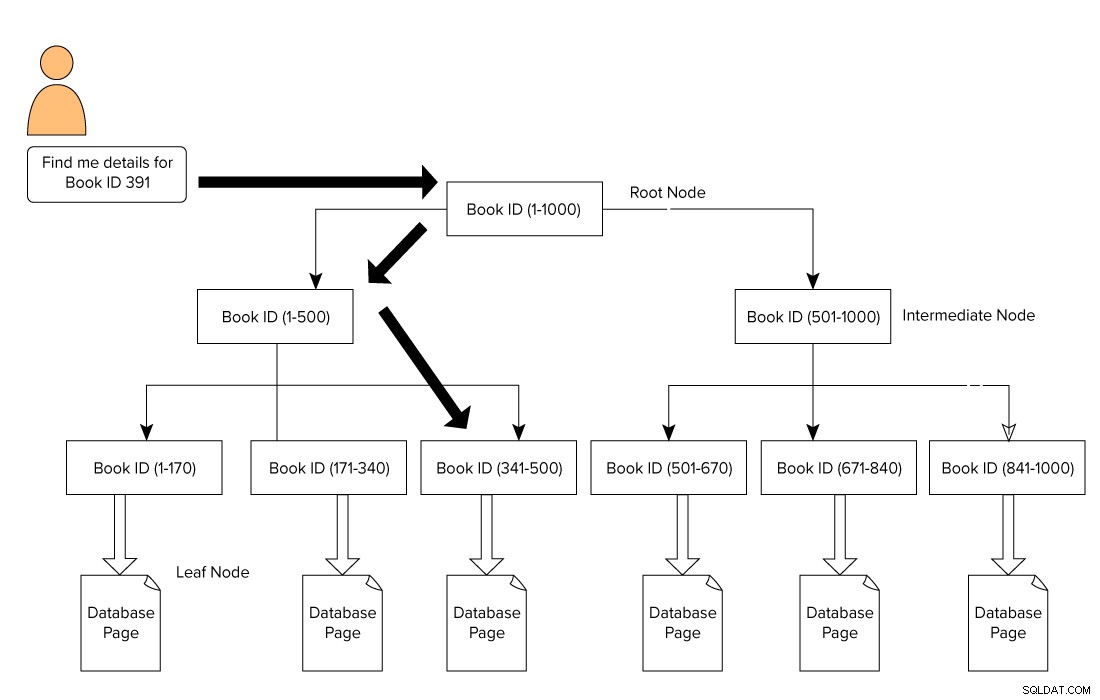
SQL Serverインデックスは、上部のルートノードと下部のリーフノードで構成されるBツリー形式で形成されます。図書館の本の例では、ユーザーがクエリを発行してID 391の本を検索します。この場合、クエリエンジンはルートノードからトラバースを開始し、リーフノードに移動します。
ルートノード–>中間ノード–>リーフノード。
クエリエンジンは、中間レベルで参照ページを探します。この例では、最初の中間ノードは1〜500のブックIDで構成され、2番目の中間ノードは501〜1000で構成されています。
中間ノードに基づいて、クエリエンジンはBツリーをトラバースして、対応する中間ノードとリーフノードを探します。このリーフノードは、実際のデータで構成することも、インデックスタイプに基づいて実際のデータページを指すこともできます。次の画像では、SQLServerインデックスを使用してデータを検索するためにインデックスをトラバースする方法を示しています。この場合、SQL Serverは各ページを調べて読み、特定のブックIDコンテンツを探す必要はありません。
SQLServerのパフォーマンスに対するインデックスの影響
前のライブラリの例では、潜在的なインデックスのパフォーマンスへの影響を調べました。インデックスがある場合とない場合のクエリのパフォーマンスを見てみましょう。
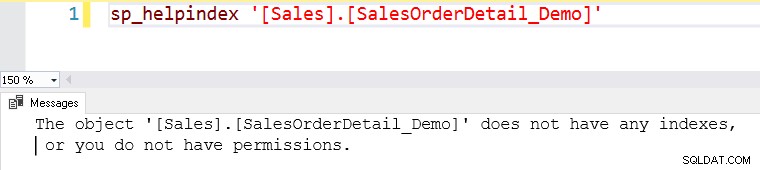
[SalesOrderDetail_Demo]テーブルの[SalesOrderID]56958のデータが必要だとします。
SELECT *
FROM[AdventureWorks]。[Sales]。[SalesOrderDetail_Demo]
where SalesOrderID =56958
このテーブルにはインデックスがありません。インデックスのないテーブルは、SQLServerではヒープテーブルと呼ばれます。
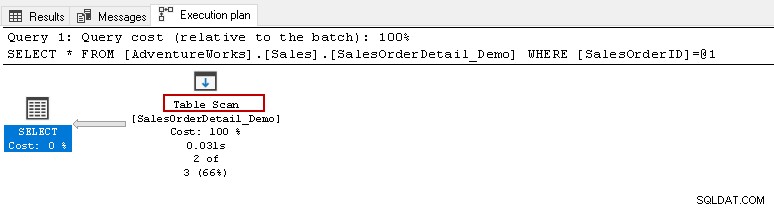
ここから、上記のselectステートメントを実行して、実際の実行プランを表示します。このテーブルには121317レコードが含まれています。テーブルスキャンを実行します。つまり、テーブル内のすべての行を読み取って、特定の[SalesOrderID]を見つけます。
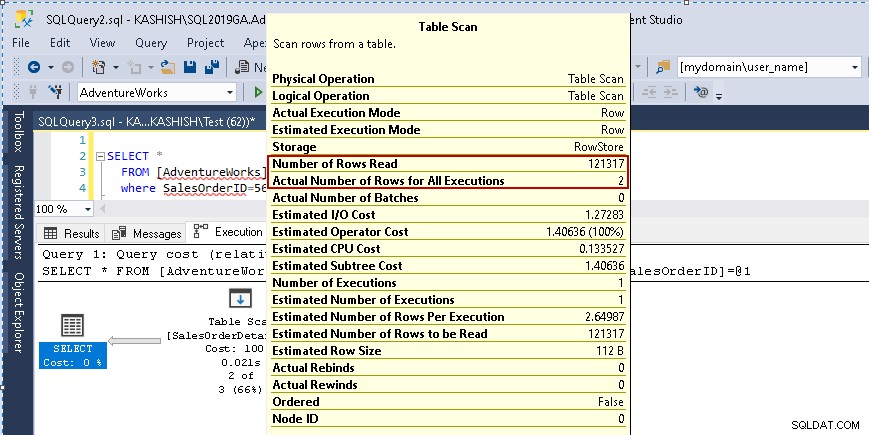
テーブルスキャンアイコンにカーソルを合わせると、実際の結果セットに2行が含まれていることが示されますが、この目的のために、そのテーブルのすべての行が読み取られます。
- 読み取られた行数:121317
- 実行の実際の行数:2
ここで、数百万または数十億の行を持つテーブルについて考えてみます。テーブル内のすべてのレコードをトラバースして、いくつかの行をフィルタリングすることはお勧めできません。大規模なオンライントランザクション処理(OLTP)データベースシステムでは、サーバーリソース(CPU、IO、メモリ)を効果的に使用しないため、ユーザーはパフォーマンスの問題に直面する可能性があります。
次に、インデックスを持つテーブルを使用して上記のselectステートメントを実行してみましょう。このテーブルには、[ProductID]列と[rowguid]列に主キーのクラスター化インデックスと2つの非クラスター化インデックスがあります。 SQLServerのさまざまな種類のインデックスについては後で説明します。
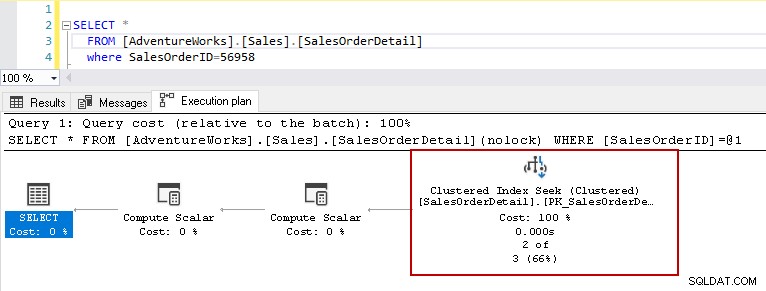
ここで、同じ述部を使用してselectステートメントを再実行すると、実行プランにパフォーマンスの問題が表示されます。クエリオプティマイザは、クラスター化インデックススキャンの代わりにクラスター化インデックスシークを使用することを決定します。
クラスタ化インデックスシークの詳細では、クエリオプティマイザが出力で指定した行を正確に読み取ったことを示しています。
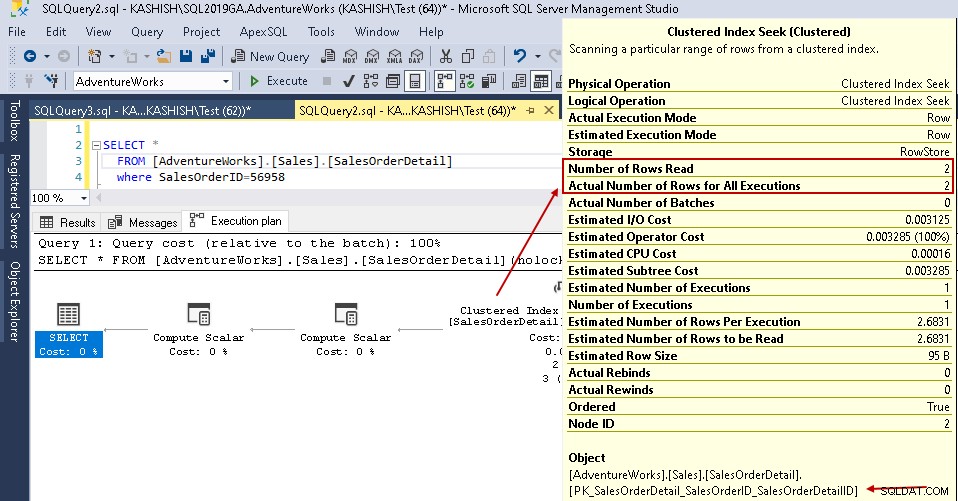
比較分析を提供するために、SQLServerインデックスがある場合とない場合の実行プランを比較してみましょう。詳細については、SQLServer2016の記事にあるSQLShackのクエリ実行プランを比較する方法を参照してください。
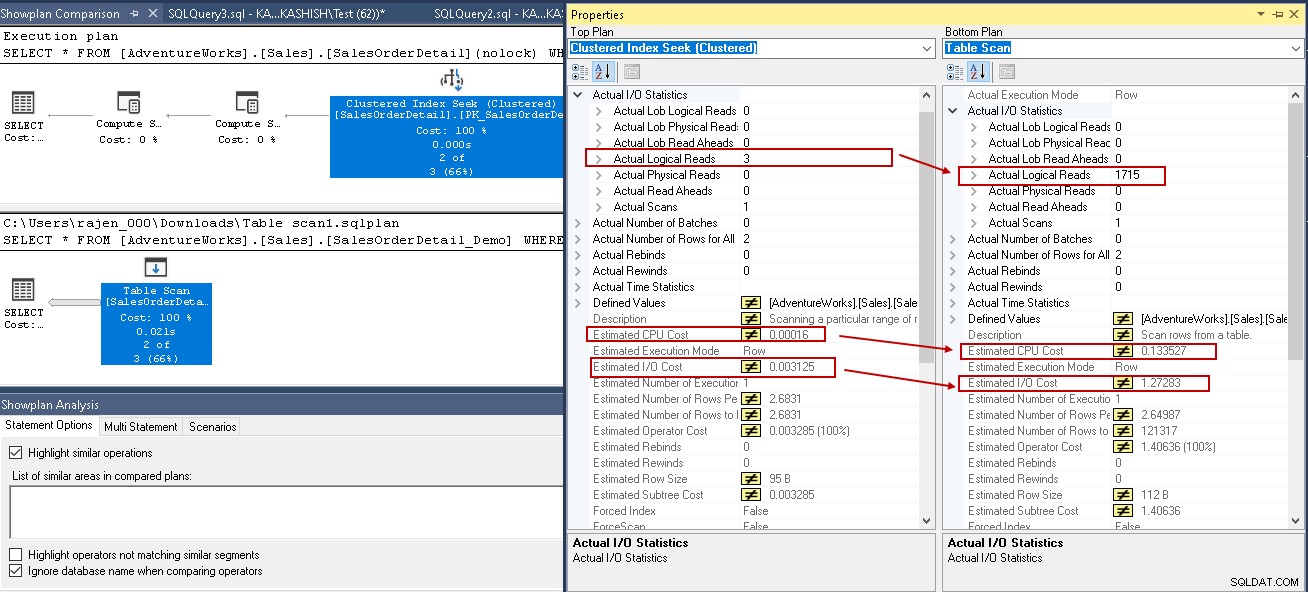
この例では、クラスター化されたインデックスシークとテーブルスキャンで強調表示された値を確認します。
- 論理読み取り:SQL Serverデータベースエンジンがバッファキャッシュからページを読み取り、論理読み取りを引き起こします。以下では、インデックスを作成すると、論理読み取りが1715から3に減少することがわかります。
- 推定CPUコストも0.133527から0.00016に低下します
- 推定IOコストは1.27283から0.003125に低下します
次の画像は、テーブルスキャンとインデックスシークの違いを示しています。
SQL Serverの良い(便利な)インデックスと悪いインデックス
名前が示すように、優れたインデックスはクエリのパフォーマンスを向上させ、リソースの使用率を最小限に抑えます。インデックスはSQLServerのクエリのパフォーマンスを低下させる可能性がありますか?特定の列にインデックスを作成することもありますが、それが使用されることはありません。列にインデックスがあり、その列に対して多くの挿入と更新を実行するとします。更新ごとに、対応するインデックスの更新も必要です。ワークロードに書き込みアクティビティが多く、列に多くのインデックスがある場合、クエリの全体的なパフォーマンスが低下します。未使用のインデックスは、selectステートメントのパフォーマンスも低下させる可能性があります。クエリオプティマイザは、統計を使用して実行プランを作成します。すべてのインデックスとそのデータサンプリングを読み取り、それに基づいて、最適化されたクエリ実行プランを構築します。動的管理ビューsys.dm_db_index_usage_statsを使用してインデックスの使用状況を追跡し、ユーザースキャン、ユーザーシーク、ユーザールックアップなどのリソースを監視できます。
SQLServerのインデックスの種類と考慮事項
SQL Serverには、クラスター化インデックスと非クラスター化インデックスの2つの主要なインデックスがあります。クラスタ化されたインデックスは、実際のデータをインデックスのリーフノードに格納します。クラスタ化されたインデックスキーに基づいて、データページ内のデータを物理的に並べ替えます。 SQL Serverでは、テーブルごとに1つのクラスター化インデックスを使用できます。複数の列を結合して、クラスター化インデックスキーを作成できます。非クラスター化インデックスは論理インデックスであり、クラスター化インデックスキーを指すインデックスキー列があります。
SQL Serverには、XMLインデックス、列ストアインデックス、空間インデックス、フルテキストインデックス、ハッシュインデックスなど、他のインデックスを含めることができます。
SQL Serverでインデックスを作成する前に、次の点を考慮する必要があります。
- ワークロード
- インデックスが必要な列
- テーブルサイズ
- 列データの昇順または降順
- 列の順序
- インデックスタイプ
- フィルファクター、パッドインデックス、TempDBの並べ替え順序
SQL Serverインデックスの利点、影響、および推奨事項
データベース内のインデックスは両刃の剣である可能性があります。便利なSQLServerインデックスは、他のクエリに影響を与えることなく、クエリとシステムのパフォーマンスを向上させます。一方、準備や考慮なしにインデックスを作成すると、パフォーマンスが低下し、データの取得が遅くなり、CPU、IO、メモリなどのより重要なリソースを消費する可能性があります。インデックスは、データベースのメンテナンスタスクも増やします。これらの要素を念頭に置いて、本番環境と同等のワークロードを使用して本番前の環境で適切なインデックスをテストし、パフォーマンスを分析して、本番データベースに実装するのが最適かどうかを判断するのが常に最善です。考慮すべき推奨事項は他にもたくさんあります。詳細については、インデックスのベストプラクティストップ11をご覧ください。