Rabbitのキューはメモリ内にあるため、データベースに実装するよりもはるかに高速です。 (優れた)専用メッセージキューは、スロットリング/フロー制御などの重要なキュー関連機能、およびカップルに名前を付けるためのさまざまなルーティングアルゴリズムを選択する機能も提供する必要があります(ウサギはこれらなどを提供します)。プロジェクトのサイズによっては、メッセージパッシングコンポーネントをデータベースとは別にして、一方のコンポーネントに大きな負荷がかかった場合でも、もう一方のコンポーネントの操作を妨げる必要がないようにすることもできます。
あなたが言及した問題について:
-
データベースをビジーでパフォーマンスの低い状態に保つポーリング :Rabbitmqを使用すると、プロデューサーはプッシュできます ポーリングよりもはるかにパフォーマンスの高いコンシューマーへの更新。データは必要なときに消費者に送信されるだけなので、無駄なチェックは不要です。
-
テーブルのロック->再びパフォーマンスが低い: ロックするテーブルはありません:P
-
数百万行のタスク->繰り返しますが、ポーリングのパフォーマンスは低くなります: 上記のように、RabbitmqはRAMに常駐し、フロー制御を提供するため、より高速に動作します。必要に応じて、RAMが不足した場合に、ディスクを使用してメッセージを一時的に保存することもできます。 2.0以降、RabbitのRAM使用量は大幅に改善されました。クラスタリングオプションも利用できます。
AMQPに関して言えば、本当にすばらしい機能は「交換」であり、他の交換にルーティングする機能です。これにより、柔軟性が向上し、スケーリング時に非常に便利なさまざまな複雑なルーティングタイポロジーを作成できます。良い例については、以下を参照してください:
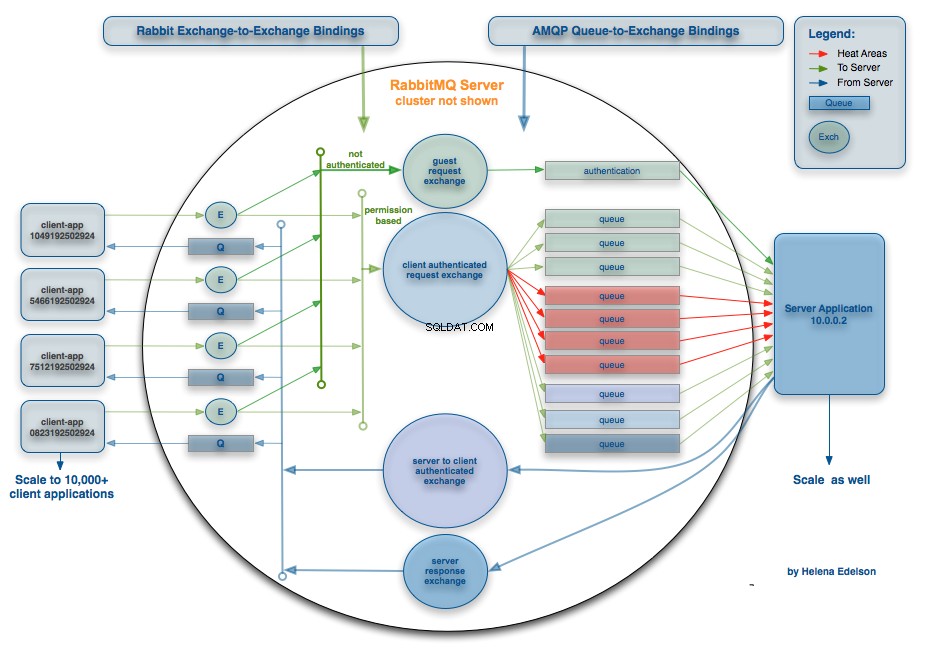
(出典:springsource.com)
および:http://blog.springsource.org/2011/04/01/routing-topologies-for-performance-and-scalability-with-rabbitmq/
最後に、Redisに関しては、はい、メッセージブローカーとして使用でき、うまく機能します。ただし、rabbitmqは、フル機能のエンタープライズレベルの専用メッセージキューとしてゼロから構築されたため、Redisよりも多くのメッセージキュー機能を備えています。一方、Redisは、主にメモリ内のKey-Valueストアとして作成されました(ただし、現在よりもはるかに多くの機能を備えています。スイスアーミーナイフとも呼ばれます)。それでも、小規模なプロジェクトでRedisを使用して良好な結果を達成している多くの人を読んだり聞いたりしましたが、大規模なアプリケーションではあまり聞いていません。
長いポーリングのチャット実装で使用されているRedisの例を次に示します。http://eflorenzano.com/blog/2011/02/16/technology-behind-convore/