マイクロサービスのような最新のアプリは通常、多くのデータベース接続を必要とし、それらの接続を非常に迅速に使用および解放します。 PostgreSQLがほぼ25年前に開発されたとき、その開発者は新しいリクエストにスレッドを使用せず、代わりにリクエストごとに新しいプロセスを作成することを決定しました。その決定はおそらく当時は理にかなっていたでしょうが、今日では多くのつながりが深刻な問題になる可能性があります。この問題の解決策の1つは、接続プールです。このブログ投稿では、PgBouncer接続プールとそれをClusterControl1.8.2で利用する方法について説明します。
この質問に対する簡単な答えは、アプリのパフォーマンスを向上させると同時に、PostgreSQLサーバーの負荷を軽減するためのシンプルで効果的なソリューションです。これについてもう少し詳しく見ていきましょう。
接続プールは、クライアントが再利用できるオープンデータベース接続のキャッシュとして定義できます。つまり、新しい接続ごとの要求を減らすことで、データベースの負荷を軽減します。これらの新しい接続は、基本的に、接続が確立されるたびにポストマスタープロセスによって生成されます。これは、通常、接続ごとに約2〜3MBのメモリを消費します。
接続プールがないと、ポストマスターが大量のメモリを提供する必要があるため、接続数が多すぎると問題が発生します。 PostgreSQLでは、接続プールはPgBouncerによって管理されます。
PgBouncerとは
PgBouncerは、軽量でシングルバイナリのオープンソースであり、PostgreSQLでおそらく最も人気のある接続プールです。 PgBouncerは、データベースとクライアントの間に位置し、PostgreSQLプロトコルと通信してPostgreSQLサーバーをコピーするという、まさに1つのことを実行する単純なユーティリティです。執筆時点では、PgBouncerの最新バージョンは1.15.0です。
それが提供する最高の機能のいくつかと、おそらくPostgreSQLの世界で非常に人気がある理由を見てみましょう:
-
軽量-単一のプロセスのみ、クライアントからのすべての要求とサーバーからの応答は、追加なしでPgBouncerを通過します処理
-
簡単なセットアップ–クライアント側のコードを変更する必要はなく、セットアップするのに最も簡単なPostgreSQL接続プーラーの1つです
-
スケーラビリティとパフォーマンス–多数のクライアントに対応できると同時に、トランザクションを大幅に増加させますPostgreSQLサーバーがサポートできる1秒あたり
ClusterControlを使用してPgBouncerをセットアップする手順
ClusterControlを使用してPgBouncerをインストールし、構成するには、いくつかの手順があります。このセクションでは、PostgreSQLクラスターがすでにデプロイされていることを条件に手順を実行します。クラスタをまだお持ちでない場合は、このブログ投稿のガイドに従うことができます。
WebUIから>PostgreSQLクラスターを選択>管理>ロードバランサー>PgBouncerタブを選択すると、次のスクリーンショットが表示されます。ここで、PgBouncerをデプロイするかインポートするかを選択できます。この例では、デプロイを選択します。:
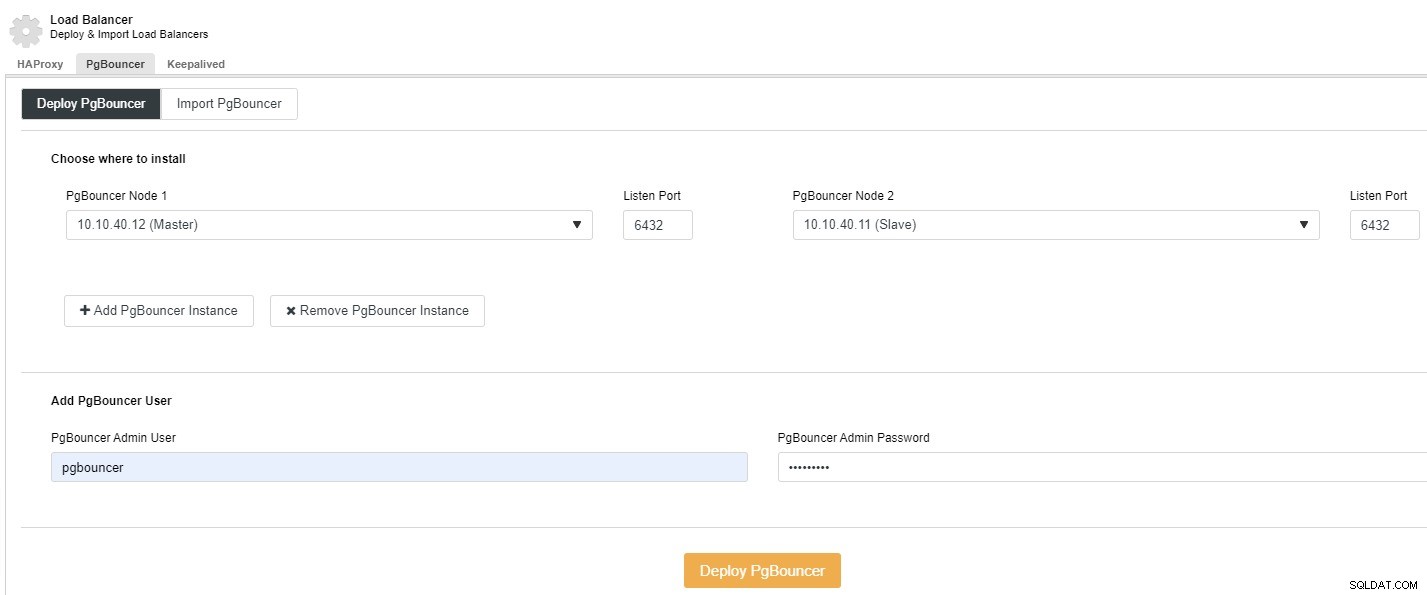
ドロップダウンからノードを選択し、ポートを指定して、'を追加できます。 PgBouncer Admin User」とパスワードを入力し、「DeployPgBouncer」をクリックします。ジョブの実行が開始され、この画面にステータスが表示され始めます。[アクティビティ]タブで監視することもできます。
PgBouncerノードが正常にデプロイされたら、次のステップは接続プールを作成することです。クラスタ>ノード>からPgBouncerノードを選択すると、次のスクリーンショットが表示されます。
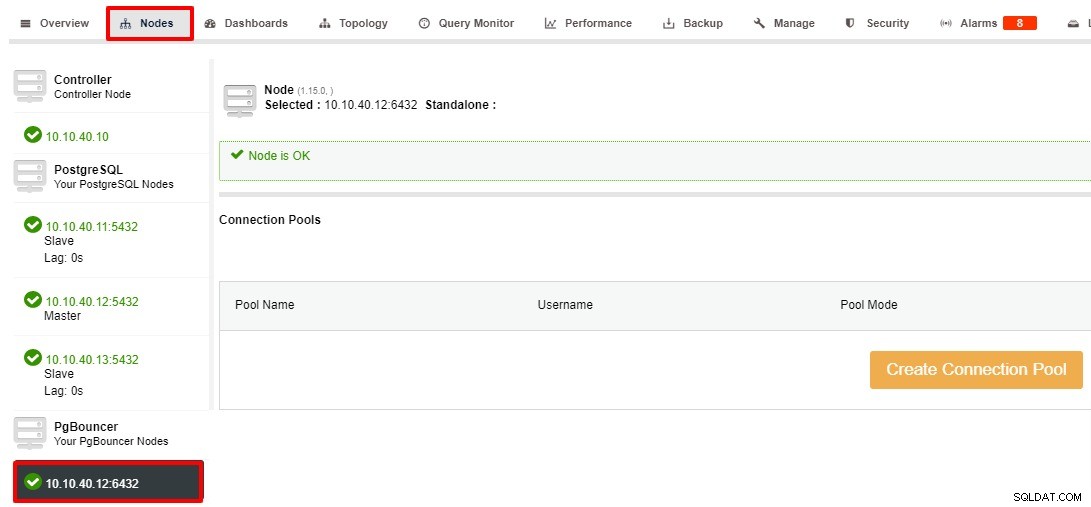
[接続プールの作成]をクリックすると、接続画面が表示されますボタン。設定に応じて、すべての情報を入力して値を更新できます。この例では、「プールモード」、「プールサイズ」、「最大データベース接続」のデフォルト値を使用します。
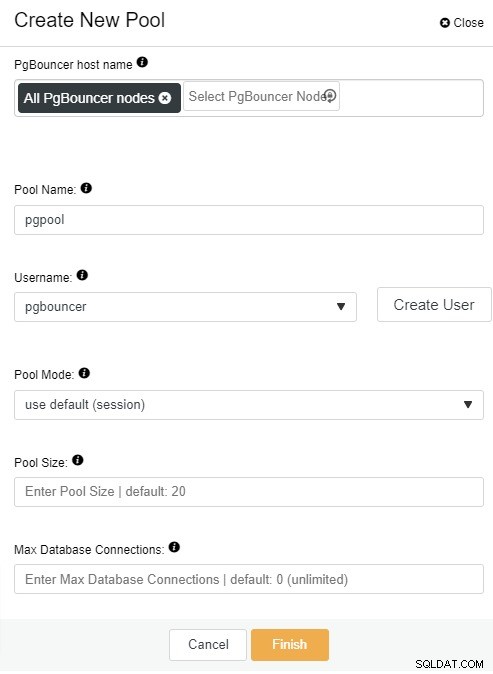
ここで、次の情報を追加する必要があります:
-
PgBouncerホスト名:接続プールを作成するノードホストを選択します。
-
プール名:プール名とデータベース名は同じである必要があります。
-
ユーザー名:PostgreSQLマスターノードからユーザーを選択するか、新しいユーザーを作成します。
-
プールモード:セッション(デフォルト)、トランザクション、またはステートメントのプーリング。
-
セッション(デフォルト):クライアントが切断された後、サーバーはプールに解放されます
-
トランザクション:トランザクションが終了すると、サーバーはプールに解放されます
-
ステートメント:クエリが終了すると、サーバーはプールに解放されます。このモードでは、複数のステートメントにまたがるトランザクションは許可されません
-
-
プールサイズ:このデータベースのプールの最大サイズ。デフォルト値は20です。
-
データベース接続の最大数:データベース全体の最大数を構成します。デフォルト値は0で、無制限を意味します。
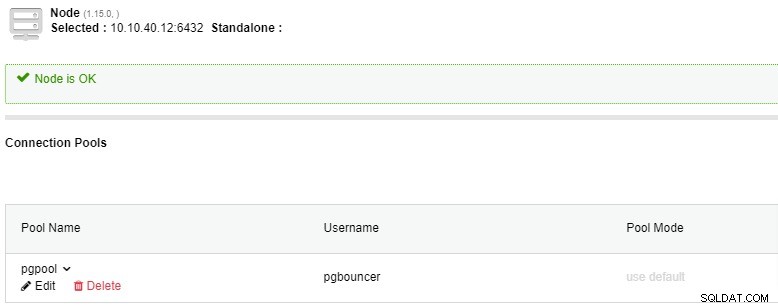
下のスクリーンショットのように[完了]ボタンをクリックすると接続プールが表示され、PgBouncerと接続プールの両方の準備が整います:
接続プールとPgBouncerの使用は、高可用性に関してアプリケーションのパフォーマンスを向上させるための手順の一部です。 ClusterControlを使用すると、PgBouncerをデプロイできるだけでなく、接続プールを簡単かつ迅速に作成できます。
さらに改善するために、PgBouncerに加えてHAProxyをデプロイすることもお勧めします。 HAProxy機能はClusterControlで利用可能であり、執筆時点では、使用しているバージョンは1.8.23です。