PostgreSQLデータベースにレプリケーションを使用すると、高可用性とフォールトトレラントな環境を実現するだけでなく、スタンバイノード間のトラフィックのバランスをとることでシステムのパフォーマンスを向上させることができます。 2部構成のブログのこの最初の部分では、PostgreSQLレプリケーションに関連するいくつかの概念を見ていきます。
PostgreSQLのレプリケーションメソッド
PostgreSQLでデータを複製するにはさまざまな方法がありますが、ここでは、ストリーミングレプリケーションと論理レプリケーションの2つの主要な方法に焦点を当てます。
最も一般的なPostgreSQLレプリケーションであるPostgreSQLストリーミングレプリケーションは、変更をバイト単位でレプリケートし、別のサーバーにデータベースの同一のコピーを作成する物理レプリケーションです。ログ配送方式に基づいています。 WALレコードは、あるデータベースサーバーから別のデータベースサーバーに直接移動されて適用されます。一種の継続的なPITRと言えます。
このWAL転送は、WALレコードを一度に1ファイル(WALセグメント)転送する方法(ファイルベースのログ配布)と、WALレコードを転送する方法(WALファイルはで構成されます)の2つの異なる方法で実行されます。 WALファイルがいっぱいになるのを待たずに、プライマリサーバーとスタンバイサーバーの1つ以上の間でオンザフライ(レコードベースのログ配布)を実行します。
実際には、スタンバイサーバーで実行されているWALレシーバーと呼ばれるプロセスは、TCP/IP接続を使用してプライマリサーバーに接続します。プライマリサーバーには、WAL送信者という名前の別のプロセスが存在し、WALレジストリをスタンバイサーバーに送信する役割を果たします。
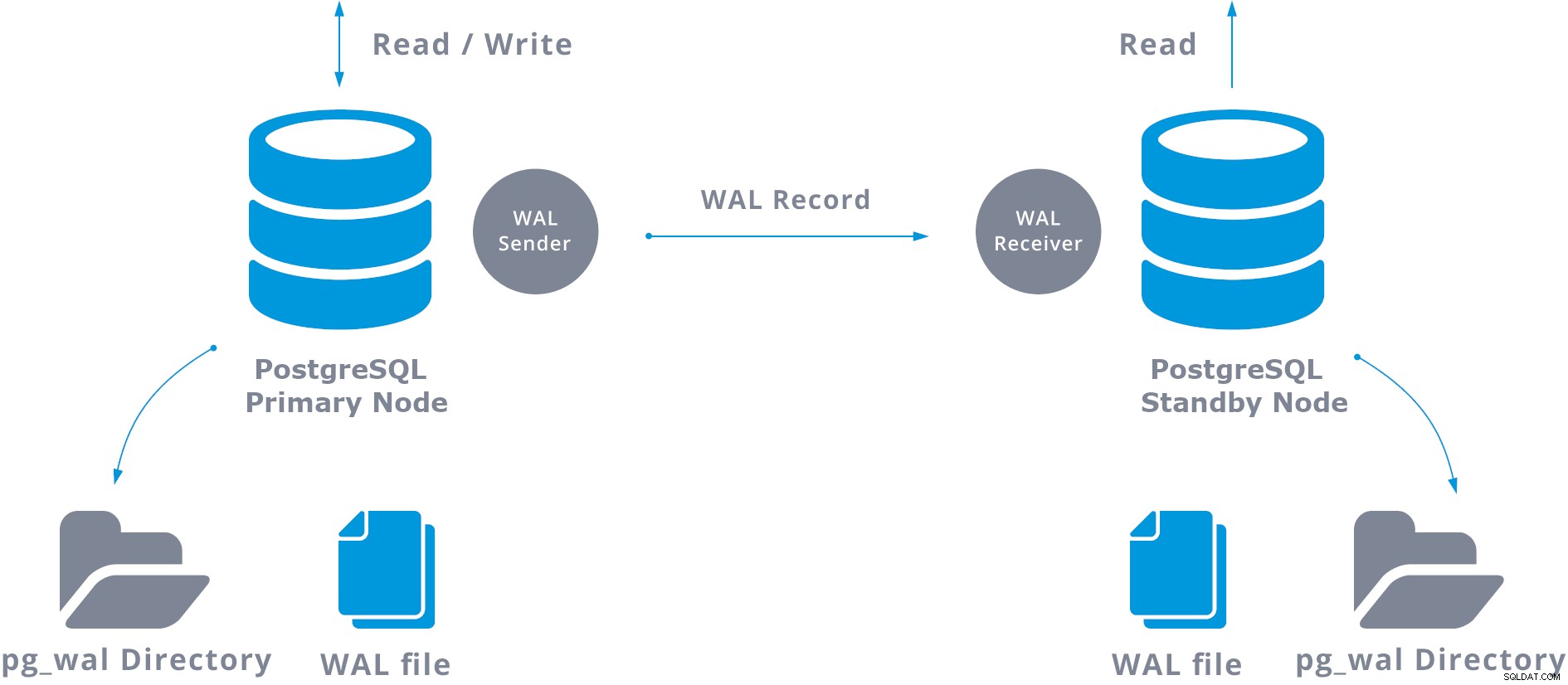
ストリーミングレプリケーションを構成する場合、WALアーカイブを有効にするオプションがあります。これは必須ではありませんが、メインサーバーがスタンバイサーバーにまだ適用されていない古いWALファイルをリサイクルすることを回避する必要があるため、堅牢なレプリケーションセットアップにとって非常に重要です。これが発生した場合は、レプリカを最初から再作成する必要があります。
PostgreSQL論理レプリケーションは、レプリケーションID(通常は主キー)に基づいて、データオブジェクトとその変更をレプリケートする方法です。これは、1つ以上のサブスクライバーがパブリッシャーノード上の1つ以上のパブリケーションをサブスクライブするパブリッシュアンドサブスクライブモードに基づいています。
パブリケーションは、テーブルまたはテーブルのグループから生成された一連の変更です。パブリケーションが定義されているノードは、パブリッシャーと呼ばれます。サブスクリプションは、論理レプリケーションのダウンストリーム側です。サブスクリプションが定義されているノードはサブスクライバーと呼ばれ、サブスクライブする別のデータベースおよび一連のパブリケーション(1つ以上)への接続を定義します。購読者は、購読している出版物からデータを取得します。
論理レプリケーションは、物理ストリーミングレプリケーションと同様のアーキテクチャで構築されています。これは、「walsender」および「apply」プロセスによって実装されます。 walsenderプロセスは、WALの論理デコードを開始し、標準の論理デコードプラグインをロードします。プラグインは、WALから読み取った変更を論理レプリケーションプロトコルに変換し、パブリケーション仕様に従ってデータをフィルタリングします。次に、データはストリーミングレプリケーションプロトコルを使用して適用ワーカーに継続的に転送されます。適用ワーカーは、データをローカルテーブルにマッピングし、受信した個々の変更を正しいトランザクション順序で適用します。
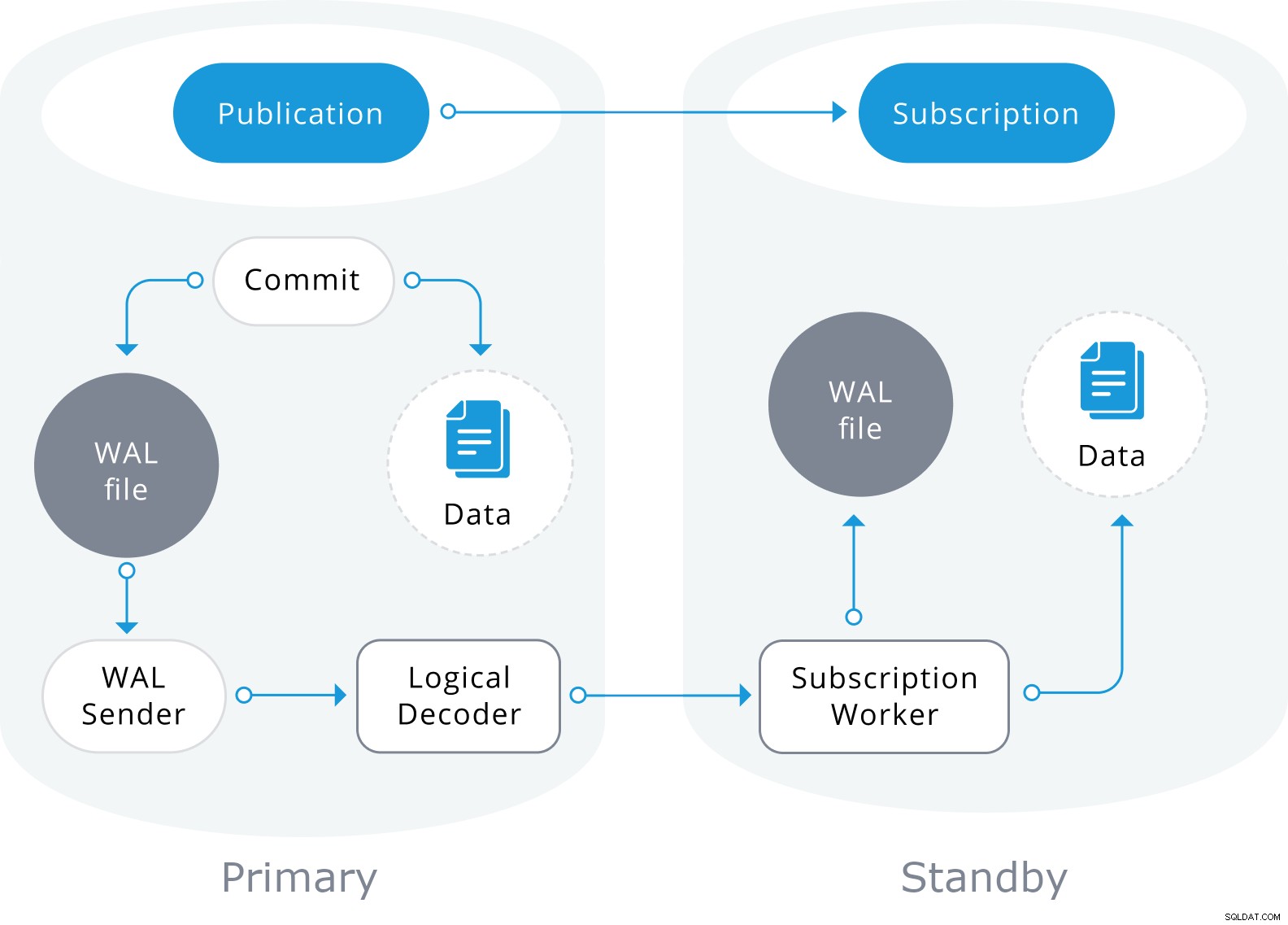
論理レプリケーションは、パブリッシャーデータベース上のデータのスナップショットを取得することから始まります。それをサブスクライバーにコピーします。既存のサブスクライブされたテーブルの初期データは、スナップショットが作成され、特別な種類の適用プロセスの並列インスタンスにコピーされます。このプロセスにより、独自の一時レプリケーションスロットが作成され、既存のデータがコピーされます。既存のデータがコピーされると、ワーカーは同期モードに入ります。これにより、標準の論理レプリケーションを使用して最初のデータコピー中に発生した変更をストリーミングすることにより、テーブルがメインの適用プロセスと同期された状態になります。同期が完了すると、テーブルのレプリケーションの制御がメインの適用プロセスに戻され、レプリケーションは通常どおり続行されます。パブリッシャーでの変更は、リアルタイムで発生したときにサブスクライバーに送信されます。
PostgreSQLのレプリケーションモード
PostgreSQLでのレプリケーションは同期または非同期にすることができます。
書き込みトランザクションの各コミットは、コミットがプライマリサーバーとスタンバイサーバーの両方のディスクの先行書き込みログに書き込まれたことの確認まで待機します。この方法は、データ損失の可能性を最小限に抑えます。データ損失が発生するためには、プライマリとスタンバイの両方が同時に失敗する必要があります。
この方法の欠点は、すべての同期方法で同じです。この方法では、各書き込みトランザクションの応答時間が長くなります。これは、トランザクションがコミットされたというすべての確認まで待つ必要があるためです。幸い、読み取り専用トランザクションはこれによる影響を受けませんが、書き込みトランザクションのみ。
PostgreSQLレプリケーションの高可用性
高可用性は、使用するテクノロジーに関係なく、多くのシステムの要件であり、さまざまなツールを使用してこれを実現するためのさまざまなアプローチがあります。
ロードバランサーは、アプリケーションからのトラフィックを管理してデータベースアーキテクチャを最大限に活用するために使用できるツールです。データベースの負荷を分散するのに役立つだけでなく、アプリケーションが使用可能な/正常なノードにリダイレクトされ、異なる役割を持つポートを指定するのにも役立ちます。
HAProxyは、1つの発信元から1つ以上の宛先にトラフィックを分散し、このタスクの特定のルールやプロトコルを定義できるロードバランサーです。いずれかの宛先が応答を停止すると、オフラインとしてマークされ、トラフィックは残りの使用可能な宛先に送信されます。ロードバランサノードが1つしかない場合は、単一障害点が生成されるため、これを回避するには、少なくとも2つのHAProxyノードをデプロイし、それらの間にキープアライブを設定する必要があります。
Keepalivedは、サーバーのアクティブ/パッシブグループ内で仮想IPを構成できるようにするサービスです。この仮想IPはアクティブサーバーに割り当てられます。このサーバーに障害が発生した場合、IPは自動的に「セカンダリ」パッシブサーバーに移行され、システムに対して透過的な方法で同じIPを引き続き使用できるようになります。
PostgreSQLレプリケーションのパフォーマンスの向上
どのシステムでも、パフォーマンスは常に重要です。可能な限り最高の応答時間を確保するには、利用可能なリソースを十分に活用する必要があります。これを行うには、さまざまな方法があります。データベースへのすべての接続はリソースを消費するため、PostgreSQLデータベースのパフォーマンスを向上させる方法の1つは、アプリケーションとデータベースサーバーの間に適切な接続プールを設定することです。
接続プールは、接続のプールを作成して再利用する方法であり、データベースへの新しい接続を常に開くことを回避します。これにより、アプリケーションのパフォーマンスが大幅に向上します。 PgBouncerは、PostgreSQL用に設計された人気のある接続プールです。
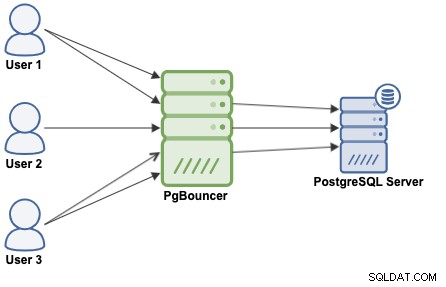
PgBouncerはPostgreSQLサーバーとして機能するため、データベースにアクセスするだけで済みます。 PgBouncer情報(IPアドレス/ホスト名とポート)を使用すると、PgBouncerはPostgreSQLサーバーへの接続を作成するか、存在する場合は再利用します。
PgBouncerは接続を受信すると、構成ファイルで指定された方法に応じて認証を実行します。 PgBouncerは、PostgreSQLサーバーがサポートするすべての認証メカニズムをサポートします。この後、PgBouncerは、同じユーザー名とデータベースの組み合わせで、キャッシュされた接続をチェックします。キャッシュされた接続が見つかった場合は、クライアントに接続を返します。見つからなかった場合は、新しい接続を作成します。 PgBouncerの構成とアクティブな接続の数によっては、新しい接続が作成されるか、中止されるまでキューに入れられる可能性があります。
これらすべての概念について、このブログの後半では、それらを組み合わせてPostgreSQLで優れたレプリケーション環境を構築する方法を説明します。