プロキシレイヤーは、データベース層の可用性を高めるのに非常に役立ちます。データベースの障害やレプリケーショントポロジの変更を処理するために、アプリケーション側のコードの量を減らすことができます。このブログ投稿では、PostgreSQL上で動作するようにHAProxyを設定する方法について説明します。
まず最初に-HAProxyはデータベースをネットワーク層プロキシとして機能します。基礎となる、時には複雑なトポロジーについての理解はありません。 HAProxyが行うのは、定義されたバックエンドにラウンドロビン方式でパケットを送信することだけです。パケットを検査せず、アプリケーションがPostgreSQLと通信するプロトコルを理解しません。その結果、HAProxyが単一のポートに読み取り/書き込み分割を実装する方法はありません。クエリの解析が必要になります。アプリケーションが書き込みから読み取りを分割し、それらを異なるIPまたはポートに送信できる限り、2つのバックエンドを使用してR/W分割を実装できます。それがどのように行われるかを見てみましょう。
HAProxy構成
以下に、HAProxyで構成された2つのPostgreSQLバックエンドの例を示します。
listen haproxy_10.0.0.101_3307_rw
bind *:3307
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string master\ is\ running
balance leastconn
option tcp-check
option allbackups
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server 10.0.0.101 10.0.0.101:5432 check
server 10.0.0.102 10.0.0.102:5432 check
server 10.0.0.103 10.0.0.103:5432 check
listen haproxy_10.0.0.101_3308_ro
bind *:3308
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string is\ running.
balance leastconn
option tcp-check
option allbackups
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server 10.0.0.101 10.0.0.101:5432 check
server 10.0.0.102 10.0.0.102:5432 check
server 10.0.0.103 10.0.0.103:5432 checkご覧のとおり、書き込みにはポート3307を使用し、読み取りには3308を使用します。このセットアップには、3つのサーバーがあります。1つはアクティブレプリカ、2つはスタンバイレプリカです。重要なのは、tcp-checkを使用してノードの状態を追跡することです。 HAProxyはポート9201に接続し、文字列が返されることを期待しています。バックエンドの正常なメンバーは期待されるコンテンツを返し、文字列を返さないメンバーは利用不可としてマークされます。
Xinetdのセットアップ
HAProxyがポート9201をチェックするとき、何かがそれをリッスンする必要があります。 xinetdを使用してそこでリッスンし、いくつかのスクリプトを実行できます。このようなサービスの構成例は次のようになります。
# default: on
# description: postgreschk
service postgreschk
{
flags = REUSE
socket_type = stream
port = 9201
wait = no
user = root
server = /usr/local/sbin/postgreschk
log_on_failure += USERID
disable = no
#only_from = 0.0.0.0/0
only_from = 0.0.0.0/0
per_source = UNLIMITED
}次の行を追加する必要があります:
postgreschk 9201/tcp/ etc/servicesに。
Xinetdはpostgreschkスクリプトを開始します。このスクリプトには、次のような内容が含まれています。
#!/bin/bash
#
# This script checks if a PostgreSQL server is healthy running on localhost. It will
# return:
# "HTTP/1.x 200 OK\r" (if postgres is running smoothly)
# - OR -
# "HTTP/1.x 500 Internal Server Error\r" (else)
#
# The purpose of this script is make haproxy capable of monitoring PostgreSQL properly
#
export PGHOST='10.0.0.101'
export PGUSER='someuser'
export PGPASSWORD='somepassword'
export PGPORT='5432'
export PGDATABASE='postgres'
export PGCONNECT_TIMEOUT=10
FORCE_FAIL="/dev/shm/proxyoff"
SLAVE_CHECK="SELECT pg_is_in_recovery()"
WRITABLE_CHECK="SHOW transaction_read_only"
return_ok()
{
echo -e "HTTP/1.1 200 OK\r\n"
echo -e "Content-Type: text/html\r\n"
if [ "$1x" == "masterx" ]; then
echo -e "Content-Length: 56\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL master is running.</body></html>\r\n"
elif [ "$1x" == "slavex" ]; then
echo -e "Content-Length: 55\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL slave is running.</body></html>\r\n"
else
echo -e "Content-Length: 49\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL is running.</body></html>\r\n"
fi
echo -e "\r\n"
unset PGUSER
unset PGPASSWORD
exit 0
}
return_fail()
{
echo -e "HTTP/1.1 503 Service Unavailable\r\n"
echo -e "Content-Type: text/html\r\n"
echo -e "Content-Length: 48\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL is *down*.</body></html>\r\n"
echo -e "\r\n"
unset PGUSER
unset PGPASSWORD
exit 1
}
if [ -f "$FORCE_FAIL" ]; then
return_fail;
fi
# check if in recovery mode (that means it is a 'slave')
SLAVE=$(psql -qt -c "$SLAVE_CHECK" 2>/dev/null)
if [ $? -ne 0 ]; then
return_fail;
elif echo $SLAVE | egrep -i "(t|true|on|1)" 2>/dev/null >/dev/null; then
return_ok "slave"
fi
# check if writable (then we consider it as a 'master')
READONLY=$(psql -qt -c "$WRITABLE_CHECK" 2>/dev/null)
if [ $? -ne 0 ]; then
return_fail;
elif echo $READONLY | egrep -i "(f|false|off|0)" 2>/dev/null >/dev/null; then
return_ok "master"
fi
return_ok "none";スクリプトのロジックは次のようになります。ノードの状態を検出するために使用される2つのクエリがあります。
SLAVE_CHECK="SELECT pg_is_in_recovery()"
WRITABLE_CHECK="SHOW transaction_read_only"最初に、PostgreSQLが回復中であるかどうかを確認します。アクティブサーバーの場合は「false」、スタンバイサーバーの場合は「true」になります。 2つ目は、PostgreSQLが読み取り専用モードであるかどうかを確認します。アクティブサーバーは「オフ」を返し、スタンバイサーバーは「オン」を返します。結果に基づいて、スクリプトは正しいパラメーター(検出されたものに応じて、「master」または「slave」)を使用してreturn_ok()関数を呼び出します。クエリが失敗した場合、「return_fail」関数が実行されます。
Return_ok関数は、渡された引数に基づいて文字列を返します。ホストがアクティブサーバーの場合、スクリプトは「PostgreSQLマスターが実行中です」を返します。スタンバイの場合、返される文字列は「PostgreSQLスレーブが実行中です」になります。状態が明確でない場合は、「PostgreSQLは実行中です」と返されます。ここでループが終了します。 HAProxyは、xinetdに接続して状態をチェックします。後者はスクリプトを開始し、HAProxyが解析する文字列を返します。
覚えているかもしれませんが、HAProxyは次の文字列を想定しています:
tcp-check expect string master\ is\ running書き込みバックエンドおよび
tcp-check expect string is\ running.読み取り専用バックエンドの場合。これにより、アクティブサーバーが書き込みバックエンドで使用可能な唯一のホストになり、読み取りバックエンドではアクティブサーバーとスタンバイサーバーの両方を使用できます。
ClusterControlのPostgreSQLとHAProxy
上記の設定は複雑ではありませんが、設定には時間がかかります。 ClusterControlを使用して、これらすべてを設定できます。
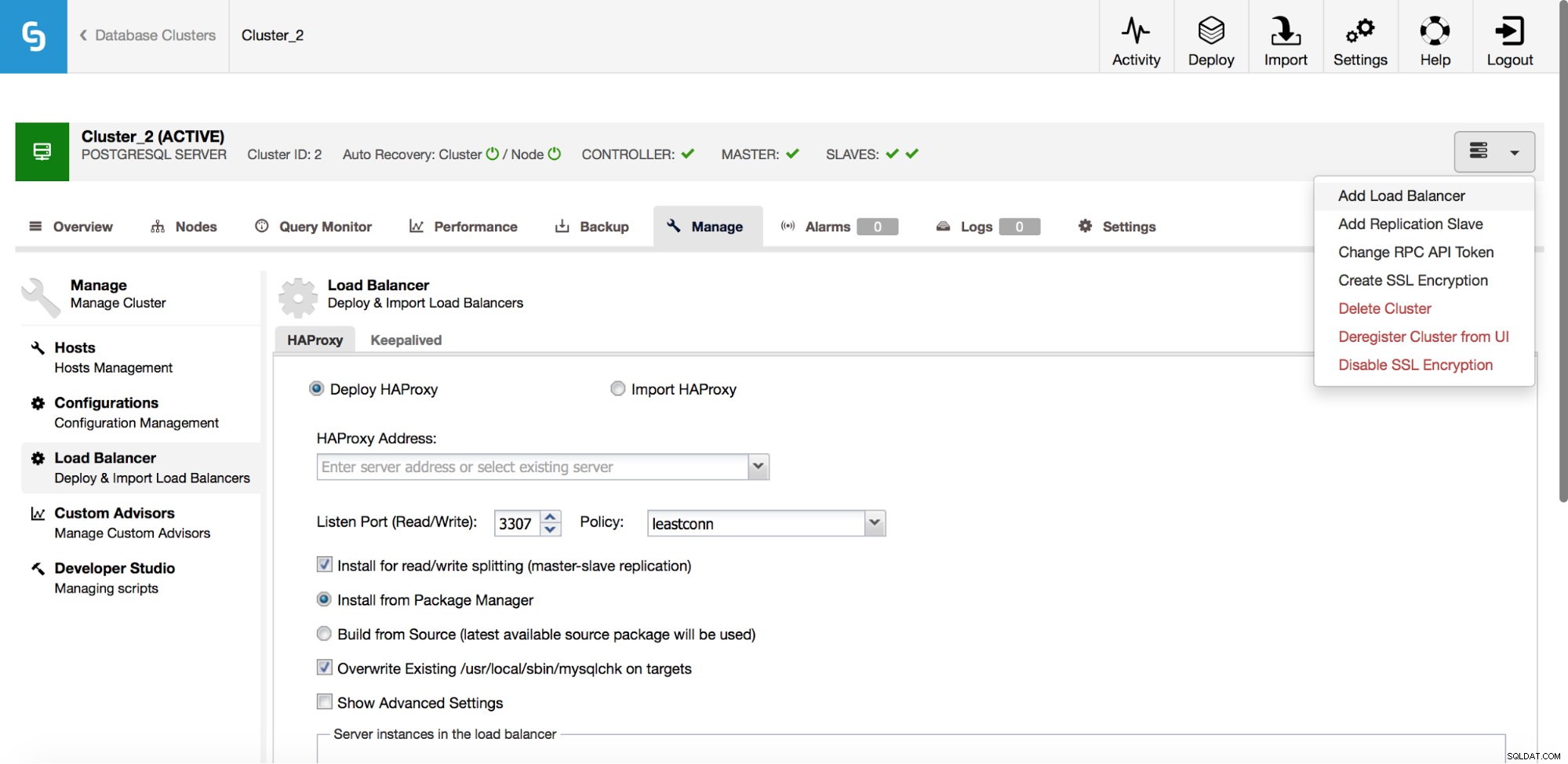
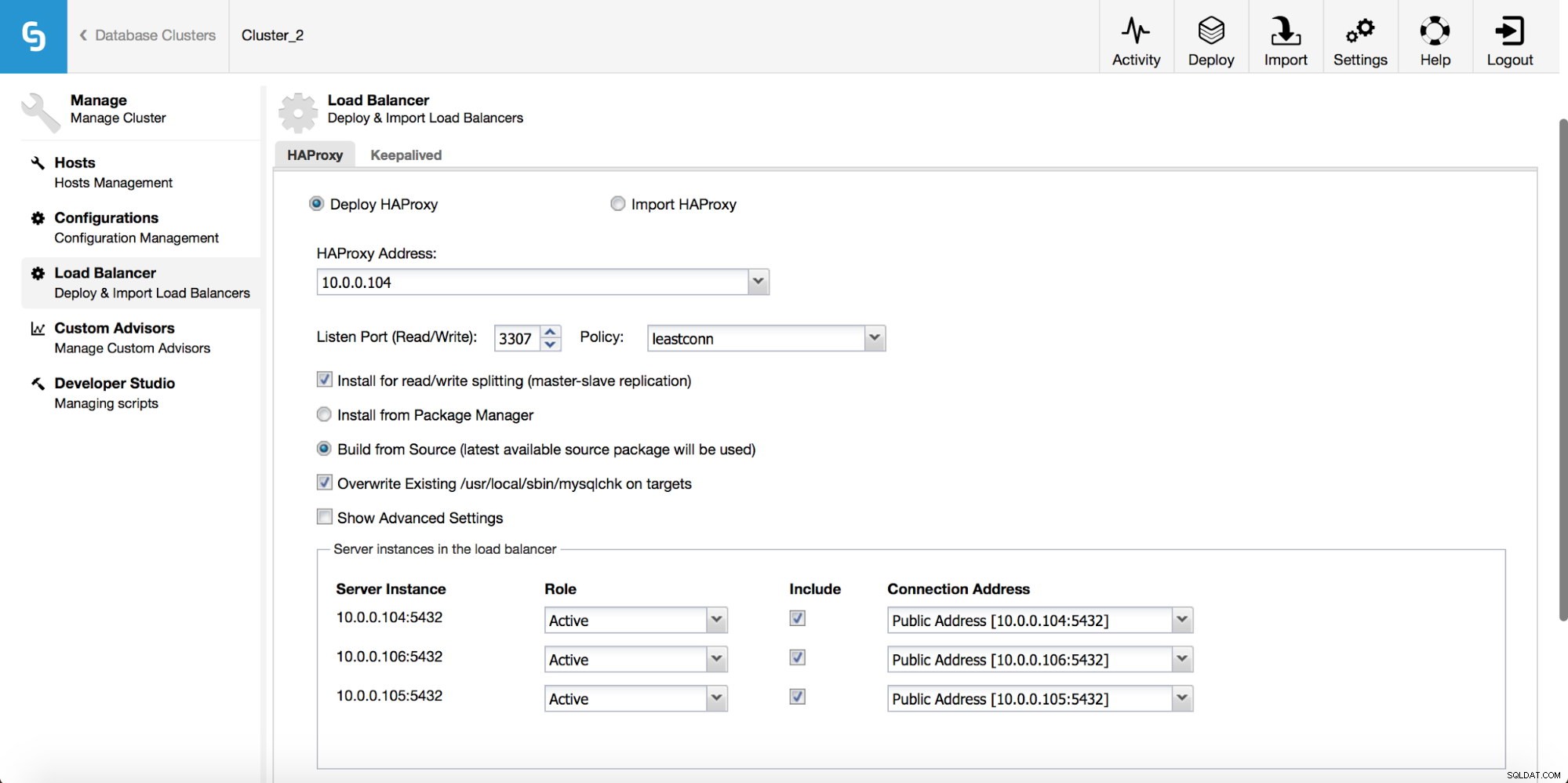
クラスタージョブのドロップダウンメニューには、ロードバランサーを追加するオプションがあります。次に、HAProxyをデプロイするオプションが表示されます。インストールする場所を入力し、いくつかの決定を行う必要があります。ホストで構成したリポジトリまたはソースコードからコンパイルされた最新バージョンからです。また、クラスター内のどのノードをHAProxyに追加するかを構成する必要があります。
HAProxyインスタンスがデプロイされると、[ノード]タブでいくつかの統計にアクセスできます。
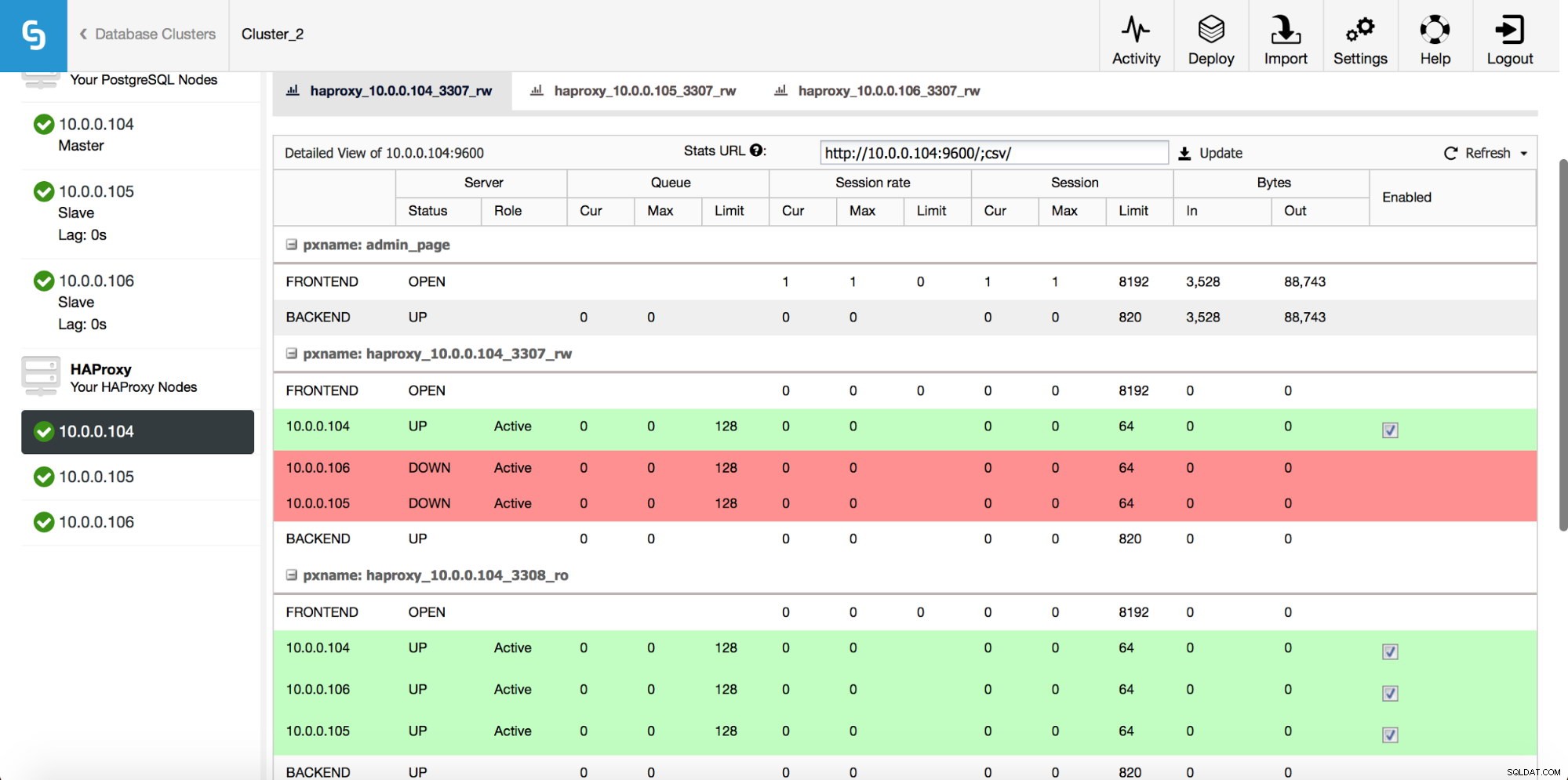
ご覧のとおり、R / Wバックエンドの場合、1つのホスト(アクティブサーバー)のみがアップとしてマークされます。読み取り専用バックエンドの場合、すべてのノードが稼働しています。
今日のホワイトペーパーをダウンロードするClusterControlを使用したPostgreSQLの管理と自動化PostgreSQLの導入、監視、管理、スケーリングを行うために知っておくべきことについて学ぶホワイトペーパーをダウンロードするキープアライブ
HAProxyは、アプリケーションとデータベースインスタンスの間に位置するため、中心的な役割を果たします。残念ながら、単一障害点になる可能性もあります。障害が発生した場合、データベースへのルートはありません。このような状況を回避するために、複数のHAProxyインスタンスをデプロイできます。しかし、問題は、どのプロキシホストに接続するかをどのように決定するかです。 ClusterControlからHAProxyをデプロイした場合は、別の「ロードバランサーの追加」ジョブを実行するのと同じくらい簡単です。今回はKeepalivedをデプロイします。
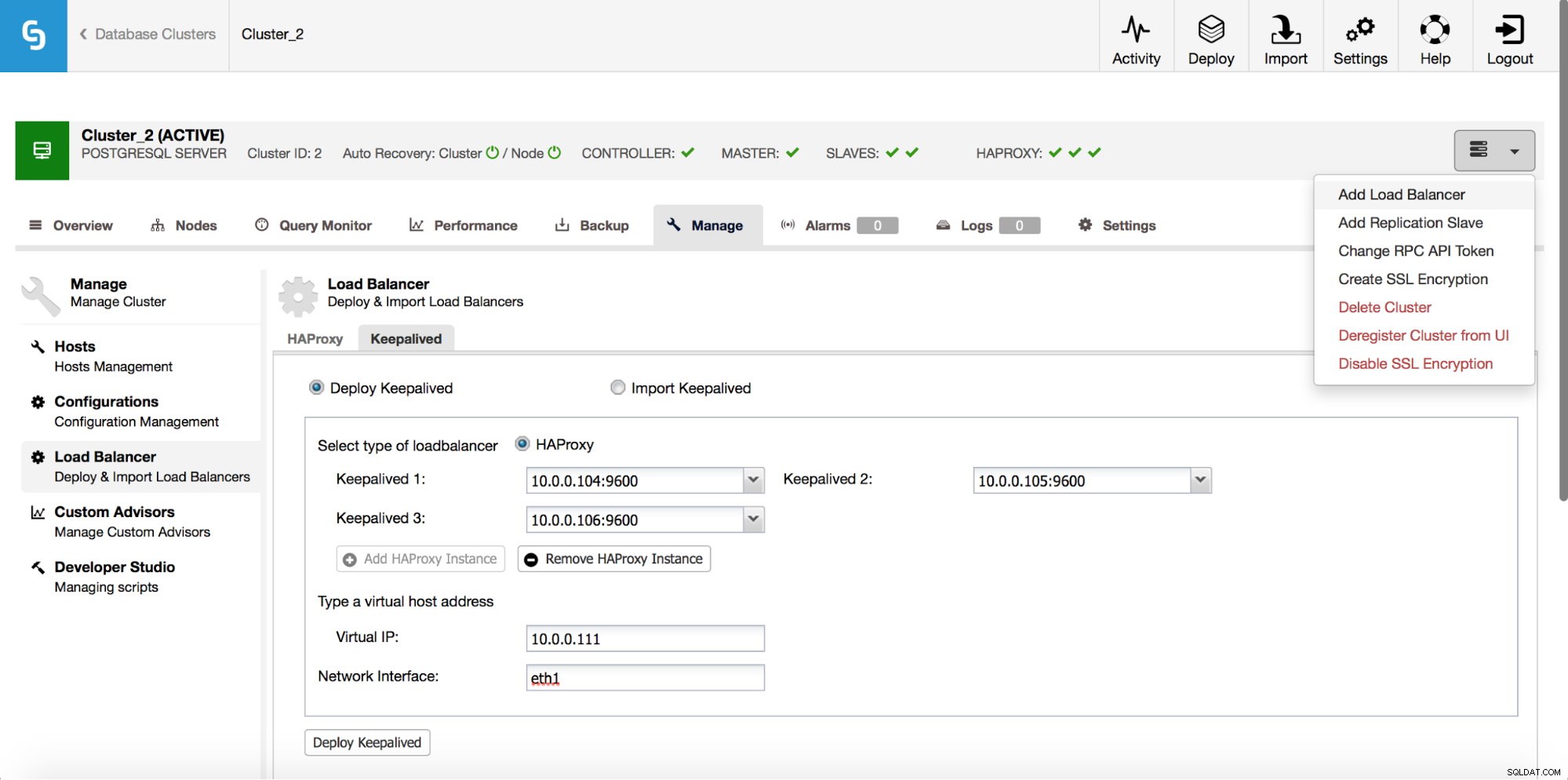
上のスクリーンショットでわかるように、最大3つのHAProxyホストを選択でき、Keepalivedがそれらの上にデプロイされ、それらの状態を監視します。そのうちの1つに仮想IP(VIP)が割り当てられます。アプリケーションは、このVIPを使用してデータベースに接続する必要があります。 「アクティブな」HAProxyが使用できなくなると、VIPは別のホストに移動されます。
これまで見てきたように、PostgreSQL用の完全な高可用性スタックをデプロイするのは非常に簡単です。試してみて、フィードバックがあればお知らせください。