レプリケーションは、高可用性を維持する上で重要な役割を果たします。サーバーに障害が発生する可能性があり、オペレーティングシステムまたはデータベースソフトウェアのアップグレードが必要になる場合があります。これは、すべてのデータベース間でデータの一貫性を維持しながら、サーバーの役割を再シャッフルし、レプリケーションリンクを移動することを意味します。トポロジの変更が必要になり、それらを実行するにはさまざまな方法があります。
スタンバイサーバーのプロモート
間違いなく、これは実行する必要がある最も一般的な操作です。複数の理由があります。たとえば、許容できない方法でワークロードに影響を与えるプライマリサーバーのデータベースメンテナンスなどです。一部のハードウェア操作により、計画的なダウンタイムが発生する可能性があります。アプリケーションにアクセスできなくなるプライマリサーバーのクラッシュ。これらはすべて、計画されているかどうかに関係なく、フェイルオーバーを実行する理由です。いずれの場合も、スタンバイサーバーの1つを昇格させて、新しいプライマリサーバーにする必要があります。
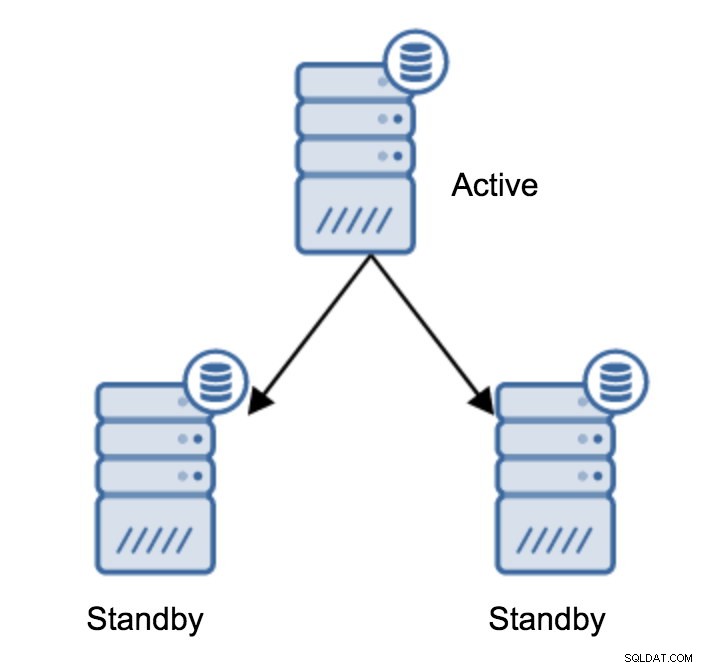
スタンバイサーバーを昇格させるには、以下を実行する必要があります:
example@sqldat.com:~$ /usr/lib/postgresql/10/bin/pg_ctl promote -D /var/lib/postgresql/10/main/
waiting for server to promote.... done
server promotedこのコマンドを実行するのは簡単ですが、最初に、データの損失を回避するようにしてください。 「プライマリサーバーがダウンしている」シナリオについて話している場合、選択肢が多すぎない可能性があります。計画的なメンテナンスであれば、準備することができます。プライマリサーバーのトラフィックを停止してから、スタンバイサーバーがすべてのデータを受信して適用したことを確認する必要があります。これは、スタンバイサーバーで、次のクエリを使用して実行できます。
postgres=# select pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn();
pg_last_wal_receive_lsn | pg_last_wal_replay_lsn
-------------------------+------------------------
1/AA2D2B08 | 1/AA2D2B08
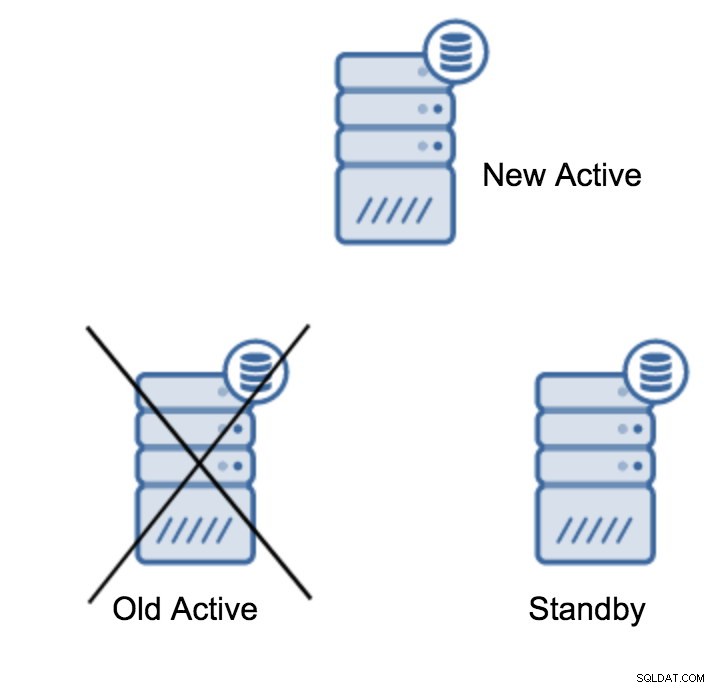
(1 row)すべてがうまくいったら、古いプライマリサーバーを停止してスタンバイサーバーを昇格させることができます。
今日のホワイトペーパーをダウンロードするClusterControlを使用したPostgreSQLの管理と自動化PostgreSQLの導入、監視、管理、スケーリングを行うために知っておくべきことについて学ぶホワイトペーパーをダウンロードするスタンバイサーバーを新しいプライマリサーバーから再スレーブする
複数のスタンバイサーバーがプライマリサーバーから離れている場合があります。結局のところ、スタンバイサーバーは読み取り専用トラフィックをオフロードするのに役立ちます。スタンバイサーバーを新しいプライマリサーバーに昇格させた後、古いプライマリサーバーにまだ接続されている(または接続しようとしている)残りのスタンバイサーバーに対して何かを行う必要があります。残念ながら、recovery.confを変更して、新しいプライマリサーバーに接続することはできません。それらを接続するには、最初にそれらを再構築する必要があります。ここで試すことができる方法は、標準ベースバックアップまたはpg_rewindの2つです。
基本バックアップの作成方法については詳しく説明しません。これについては、以前のブログ投稿で取り上げました。これは、バックアップの作成とPostgreSQLでの復元に焦点を当てたものです。 ClusterControlを使用している場合は、それを使用してベースバックアップを作成することもできます。
一方、pg_rewindについていくつかの言葉を考えてみましょう。両方の方法の主な違いは、ベースバックアップがデータセットの完全コピーを作成することです。小さなデータセットについて話している場合は問題ありませんが、サイズが数百ギガバイト(またはそれ以上)のデータセットの場合、すぐに問題になる可能性があります。最終的には、スタンバイサーバーを迅速に稼働させ、アクティブサーバーの負荷を軽減し、必要に応じてフェイルオーバーする別のスタンバイを用意する必要があります。 Pg_rewindの動作は異なります。変更されたブロックのみをコピーします。すべてをコピーする代わりに、変更のみをコピーするため、プロセスが大幅に高速化されます。新しいマスターのIPが10.0.0.103であると仮定します。これは、pg_rewindを実行する方法です。ターゲットサーバーを停止する必要があることに注意してください。PostgreSQLはそこで実行できません。
example@sqldat.com:~$ /usr/lib/postgresql/10/bin/pg_rewind --source-server="user=myuser dbname=postgres host=10.0.0.103" --target-pgdata=/var/lib/postgresql/10/main --dry-run
servers diverged at WAL location 1/AA4F1160 on timeline 3
rewinding from last common checkpoint at 1/AA4F10F0 on timeline 3
Done!これにより、ドライランが実行されます 、プロセスをテストしますが、変更は加えません。すべてが正常であれば、今度は「--dry-run」パラメータを使用せずに、もう一度実行するだけです。完了したら、残りの最後の手順は、新しいマスターを指すrecovery.confファイルを作成することです。次のようになります:
standby_mode = 'on'
primary_conninfo = 'application_name=pgsql_node_0 host=10.0.0.103 port=5432 user=replication_user password=replication_password'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover.trigger'これで、スタンバイサーバーを起動する準備が整い、新しいアクティブサーバーから複製されます。
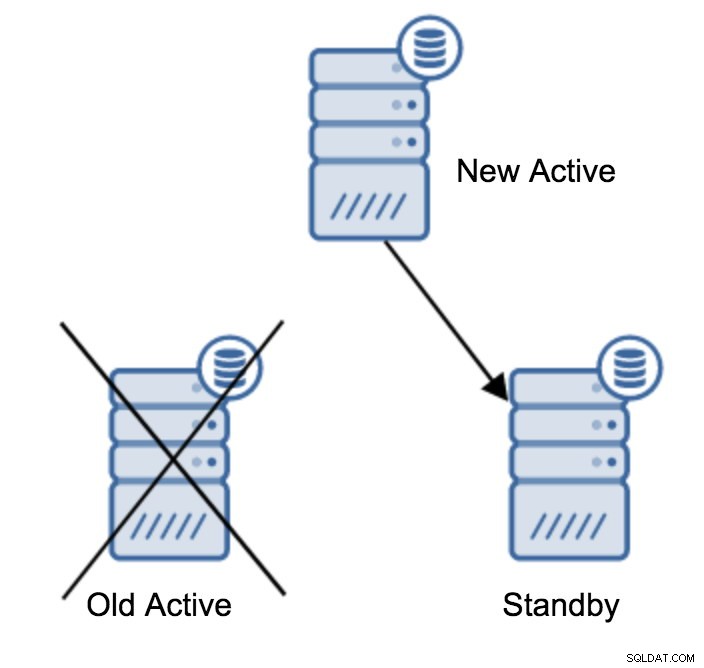
連鎖レプリケーション
チェーンレプリケーションを構築する理由は多数ありますが、通常はプライマリサーバーの負荷を軽減するために行われます。 WALをスタンバイサーバーに提供すると、オーバーヘッドが増加します。スタンバイが1つか2つあればそれほど問題にはなりませんが、多数のスタンバイサーバーについて話している場合は、これが問題になる可能性があります。たとえば、次のようにトポロジを作成することで、アクティブから直接複製するスタンバイサーバーの数を最小限に抑えることができます。
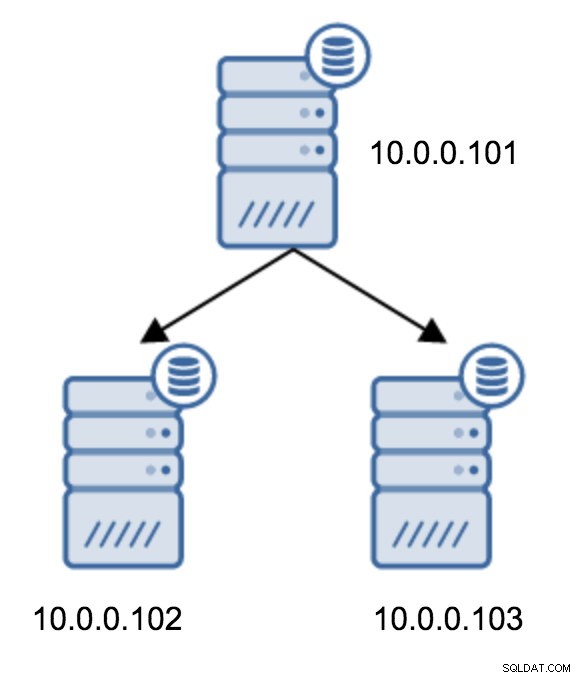
2台のスタンバイサーバーのトポロジからチェーンレプリケーションへの移行は非常に簡単です。
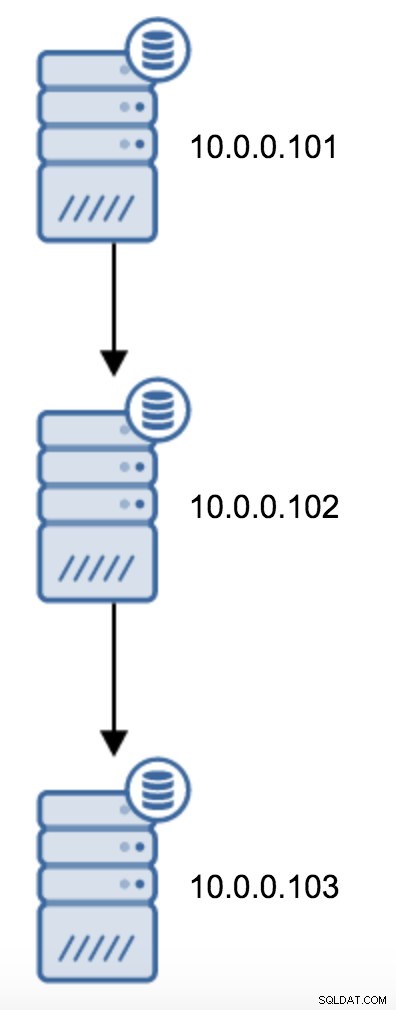
10.0.0.103でrecovery.confを変更し、それを10.0.0.102に向けてから、PostgreSQLを再起動する必要があります。
standby_mode = 'on'
primary_conninfo = 'application_name=pgsql_node_0 host=10.0.0.102 port=5432 user=replication_user password=replication_password'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover.trigger'再起動後、10.0.0.103はWALアップデートの適用を開始する必要があります。
これらは、トポロジー変更のいくつかの一般的なケースです。議論されなかったが、それでも重要なトピックの1つは、これらの変更がアプリケーションに与える影響です。これについては別の投稿で説明し、これらのトポロジの変更をアプリケーションに対して透過的にする方法についても説明します。