PostgreSQLは、多くの優れた機能を備えた世界で最も先進的なオープンソースデータベースの1つです。その1つが、PostgreSQL 9.0で導入されたストリーミングレプリケーション(物理レプリケーション)です。これは、宛先サーバーに転送されてそこで適用されるXLOGレコードに基づいています。ただし、これはクラスターベースであり、単一のデータベースまたは単一のオブジェクト(選択的レプリケーション)レプリケーションを実行することはできません。 PostgreSQL 9.6までコアレベルの機能がなかったため、長年にわたり、選択的または部分的なレプリケーションをSlony、Bucardo、BDRなどの外部ツールに依存してきました。ただし、PostgreSQL 10は、データベース/オブジェクトレベルのレプリケーションを実行できる論理レプリケーションと呼ばれる機能を考案しました。
論理レプリケーションは、通常は主キーであるレプリケーションIDに基づいてオブジェクトの変更をレプリケートします。これは、レプリケーションがブロックとバイトごとのレプリケーションに基づいている物理レプリケーションとは異なります。論理レプリケーションは、宛先サーバー側で正確なバイナリコピーを必要とせず、物理レプリケーションとは異なり、宛先サーバーに書き込むことができます。この機能は、pglogicalモジュールに由来します。
このブログ投稿では、次のことについて説明します。
- 仕組み-アーキテクチャ
- 機能
- ユースケース-役立つ場合
- 制限
- それを達成する方法
仕組み-論理レプリケーションアーキテクチャ
論理レプリケーションは、パブリッシュおよびサブスクライブの概念(パブリケーションとサブスクリプション)を実装します。以下は、それがどのように機能するかについてのより高いレベルのアーキテクチャ図です。
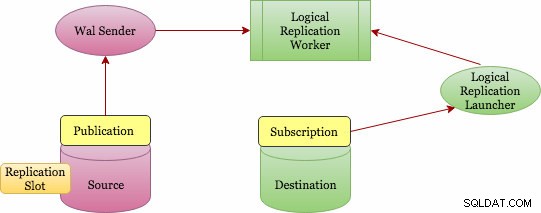
基本的な論理レプリケーションアーキテクチャ
パブリケーションはマスターサーバーで定義でき、パブリケーションが定義されているノードは「パブリッシャー」と呼ばれます。パブリケーションは、単一のテーブルまたはテーブルのグループからの一連の変更です。これはデータベースレベルであり、各パブリケーションは1つのデータベースに存在します。 1つのパブリケーションに複数のテーブルを追加したり、複数のパブリケーションにテーブルを追加したりできます。スーパーユーザー権限を必要とする「ALLTABLES」オプションを選択する場合を除いて、オブジェクトをパブリケーションに明示的に追加する必要があります。
複製するオブジェクト(INSERT、UPDATE、およびDELETE)の変更を制限できます。デフォルトでは、すべての操作タイプが複製されます。パブリケーションに追加するオブジェクトのレプリケーションIDを構成する必要があります。これは、UPDATEおよびDELETE操作を複製するためです。レプリケーションIDは、主キーまたは一意のインデックスにすることができます。テーブルに主キーまたは一意のインデックスがない場合は、すべての列をキーとして使用するレプリカID「フル」に設定できます(行全体がキーになります)。
CREATEPUBLICATIONを使用してパブリケーションを作成できます。いくつかの実用的なコマンドは、「それを達成する方法」セクションで説明されています。
サブスクリプションは宛先サーバーで定義でき、サブスクリプションが定義されているノードは「サブスクライバー」と呼ばれます。ソースデータベースへの接続は、サブスクリプションで定義されます。サブスクライバーノードは、他のスタンドアロンのpostgresデータベースと同じであり、さらにサブスクリプションを作成するためのパブリケーションとして使用することもできます。
サブスクリプションはCREATESUBSCRIPTIONを使用して追加され、ALTER SUBSCRIPTIONコマンドを使用していつでも停止/再開でき、DROPSUBSCRIPTIONを使用して削除できます。
サブスクリプションが作成されると、論理レプリケーションはデータのスナップショットをパブリッシャーデータベースにコピーします。それが完了すると、デルタの変更を待機し、変更が発生するとすぐにサブスクリプションノードに送信します。
ただし、変更はどのように収集されますか?誰がそれらをターゲットに送りますか?そして、誰がそれらをターゲットに適用しますか?論理レプリケーションも、物理レプリケーションと同じアーキテクチャに基づいています。これは、「walsender」および「apply」プロセスによって実装されます。 WALデコードに基づいているので、誰がデコードを開始しますか? walsenderプロセスは、WALの論理デコードを開始し、標準の論理デコードプラグイン(pgoutput)をロードします。プラグインは、WALから読み取った変更を論理レプリケーションプロトコルに変換し、パブリケーション仕様に従ってデータをフィルタリングします。次に、データはストリーミングレプリケーションプロトコルを使用して適用ワーカーに継続的に転送されます。適用ワーカーは、データをローカルテーブルにマッピングし、受信した個々の変更を正しいトランザクション順序で適用します。
セットアップ中に、これらすべての手順をログファイルに記録します。メッセージは、投稿の後半の「達成方法」セクションで確認できます。
論理レプリケーションの機能
- 論理レプリケーションは、レプリケーションIDに基づいてデータオブジェクトをレプリケートします(通常は
- 主キーまたは一意のインデックス)。
- 宛先サーバーは書き込みに使用できます。さまざまなインデックスとセキュリティ定義を持つことができます。
- 論理レプリケーションはクロスバージョンをサポートしています。ストリーミングレプリケーションとは異なり、論理レプリケーションはPostgreSQLの異なるバージョン間で設定できます(ただし、> 9.4)
- 論理レプリケーションはイベントベースのフィルタリングを行います
- 比較すると、論理レプリケーションはストリーミングレプリケーションよりもライトアンプリフィケーションが少なくなります
- 出版物には複数のサブスクリプションを含めることができます
- 論理レプリケーションは、小さなセット(パーティション化されたテーブルも含む)をレプリケートすることでストレージの柔軟性を提供します
- トリガーベースのソリューションと比較した最小のサーバー負荷
- パブリッシャー間での並列ストリーミングを可能にします
- 論理レプリケーションは移行とアップグレードに使用できます
- データ変換はセットアップ中に実行できます。
ユースケース-論理レプリケーションはいつ役に立ちますか?
論理レプリケーションをいつ使用するかを知ることは非常に重要です。そうしないと、ユースケースが一致しない場合に多くのメリットが得られません。したがって、論理レプリケーションを使用する場合のユースケースは次のとおりです。
- 分析目的で複数のデータベースを単一のデータベースに統合する場合。
- 要件がPostgreSQLの異なるメジャーバージョン間でデータを複製することである場合。
- 単一のデータベースまたはデータベースのサブセットの増分変更を他のデータベースに送信する場合。
- 複製されたデータへのアクセスをさまざまなユーザーグループに与える場合。
- データベースのサブセットを複数のデータベース間で共有する場合。
論理レプリケーションの制限
論理レプリケーションには、コミュニティが克服するために継続的に取り組んでいるいくつかの制限があります。
- テーブルは、パブリケーションとサブスクリプションの間で同じ完全修飾名を持っている必要があります。
- テーブルには主キーまたは一意キーが必要です
- 相互(双方向)レプリケーションはサポートされていません
- スキーマ/DDLを複製しません
- シーケンスを複製しません
- TRUNCATEを複製しません
- 大きなオブジェクトを複製しません
- サブスクリプションには、より多くの列または列の異なる順序を含めることができますが、タイプと列名は、パブリケーションとサブスクリプションの間で一致する必要があります。
- すべてのテーブルを追加するためのスーパーユーザー権限
- 同じホストにストリーミングすることはできません(サブスクリプションはロックされます)。
論理レプリケーションを実現する方法
基本的な論理レプリケーションを実現するための手順は次のとおりです。より複雑なシナリオについては後で話し合うことができます。
-
パブリケーションとサブスクリプション用に2つの異なるインスタンスを初期化し、開始します。
C1MQV0FZDTY3:bin bajishaik$ export PATH=$PWD:$PATH C1MQV0FZDTY3:bin bajishaik$ which psql /Users/bajishaik/pg_software/10.2/bin/psql C1MQV0FZDTY3:bin bajishaik$ ./initdb -D /tmp/publication_db C1MQV0FZDTY3:bin bajishaik$ ./initdb -D /tmp/subscription_db -
インスタンスを開始する前に変更するパラメーター(パブリケーションインスタンスとサブスクリプションインスタンスの両方)。
C1MQV0FZDTY3:bin bajishaik$ tail -3 /tmp/publication_db/postgresql.conf listen_addresses='*' port = 5555 wal_level= logical C1MQV0FZDTY3:bin bajishaik$ pg_ctl -D /tmp/publication_db/ start waiting for server to start....2018-03-21 16:03:30.394 IST [24344] LOG: listening on IPv4 address "0.0.0.0", port 5555 2018-03-21 16:03:30.395 IST [24344] LOG: listening on IPv6 address "::", port 5555 2018-03-21 16:03:30.544 IST [24344] LOG: listening on Unix socket "/tmp/.s.PGSQL.5555" 2018-03-21 16:03:30.662 IST [24345] LOG: database system was shut down at 2018-03-21 16:03:27 IST 2018-03-21 16:03:30.677 IST [24344] LOG: database system is ready to accept connections done server started C1MQV0FZDTY3:bin bajishaik$ tail -3 /tmp/subscription_db/postgresql.conf listen_addresses='*' port=5556 wal_level=logical C1MQV0FZDTY3:bin bajishaik$ pg_ctl -D /tmp/subscription_db/ start waiting for server to start....2018-03-21 16:05:28.408 IST [24387] LOG: listening on IPv4 address "0.0.0.0", port 5556 2018-03-21 16:05:28.408 IST [24387] LOG: listening on IPv6 address "::", port 5556 2018-03-21 16:05:28.410 IST [24387] LOG: listening on Unix socket "/tmp/.s.PGSQL.5556" 2018-03-21 16:05:28.460 IST [24388] LOG: database system was shut down at 2018-03-21 15:59:32 IST 2018-03-21 16:05:28.512 IST [24387] LOG: database system is ready to accept connections done server started基本設定では、他のパラメータをデフォルトにすることができます。
-
pg_hba.confファイルを変更してレプリケーションを許可します。これらの値は環境によって異なることに注意してください。ただし、これは単なる基本的な例です(パブリケーションインスタンスとサブスクリプションインスタンスの両方)。
C1MQV0FZDTY3:bin bajishaik$ tail -1 /tmp/publication_db/pg_hba.conf host all repuser 0.0.0.0/0 md5 C1MQV0FZDTY3:bin bajishaik$ tail -1 /tmp/subscription_db/pg_hba.conf host all repuser 0.0.0.0/0 md5 C1MQV0FZDTY3:bin bajishaik$ psql -p 5555 -U bajishaik -c "select pg_reload_conf()" Timing is on. Pager usage is off. 2018-03-21 16:08:19.271 IST [24344] LOG: received SIGHUP, reloading configuration files pg_reload_conf ---------------- t (1 row) Time: 16.103 ms C1MQV0FZDTY3:bin bajishaik$ psql -p 5556 -U bajishaik -c "select pg_reload_conf()" Timing is on. Pager usage is off. 2018-03-21 16:08:29.929 IST [24387] LOG: received SIGHUP, reloading configuration files pg_reload_conf ---------------- t (1 row) Time: 53.542 ms C1MQV0FZDTY3:bin bajishaik$ -
いくつかのテストテーブルを作成して、Publicationインスタンスにデータを複製して挿入します。
postgres=# create database source_rep; CREATE DATABASE Time: 662.342 ms postgres=# \c source_rep You are now connected to database "source_rep" as user "bajishaik". source_rep=# create table test_rep(id int primary key, name varchar); CREATE TABLE Time: 63.706 ms source_rep=# create table test_rep_other(id int primary key, name varchar); CREATE TABLE Time: 65.187 ms source_rep=# insert into test_rep values(generate_series(1,100),'data'||generate_series(1,100)); INSERT 0 100 Time: 2.679 ms source_rep=# insert into test_rep_other values(generate_series(1,100),'data'||generate_series(1,100)); INSERT 0 100 Time: 1.848 ms source_rep=# select count(1) from test_rep; count ------- 100 (1 row) Time: 0.513 ms source_rep=# select count(1) from test_rep_other ; count ------- 100 (1 row) Time: 0.488 ms source_rep=# -
論理レプリケーションは構造を複製しないため、サブスクリプションインスタンスにテーブルの構造を作成します。
postgres=# create database target_rep; CREATE DATABASE Time: 514.308 ms postgres=# \c target_rep You are now connected to database "target_rep" as user "bajishaik". target_rep=# create table test_rep_other(id int primary key, name varchar); CREATE TABLE Time: 9.684 ms target_rep=# create table test_rep(id int primary key, name varchar); CREATE TABLE Time: 5.374 ms target_rep=# -
Publicationインスタンス(ポート5555)でパブリケーションを作成します。
source_rep=# CREATE PUBLICATION mypub FOR TABLE test_rep, test_rep_other; CREATE PUBLICATION Time: 3.840 ms source_rep=# -
手順6で作成したパブリケーションへのサブスクリプションインスタンス(ポート5556)でサブスクリプションを作成します。
target_rep=# CREATE SUBSCRIPTION mysub CONNECTION 'dbname=source_rep host=localhost user=bajishaik port=5555' PUBLICATION mypub; NOTICE: created replication slot "mysub" on publisher CREATE SUBSCRIPTION Time: 81.729 msログから:
2018-03-21 16:16:42.200 IST [24617] LOG: logical decoding found consistent point at 0/1616D80 2018-03-21 16:16:42.200 IST [24617] DETAIL: There are no running transactions. target_rep=# 2018-03-21 16:16:42.207 IST [24618] LOG: logical replication apply worker for subscription "mysub" has started 2018-03-21 16:16:42.217 IST [24619] LOG: starting logical decoding for slot "mysub" 2018-03-21 16:16:42.217 IST [24619] DETAIL: streaming transactions committing after 0/1616DB8, reading WAL from 0/1616D80 2018-03-21 16:16:42.217 IST [24619] LOG: logical decoding found consistent point at 0/1616D80 2018-03-21 16:16:42.217 IST [24619] DETAIL: There are no running transactions. 2018-03-21 16:16:42.219 IST [24620] LOG: logical replication table synchronization worker for subscription "mysub", table "test_rep" has started 2018-03-21 16:16:42.231 IST [24622] LOG: logical replication table synchronization worker for subscription "mysub", table "test_rep_other" has started 2018-03-21 16:16:42.260 IST [24621] LOG: logical decoding found consistent point at 0/1616DB8 2018-03-21 16:16:42.260 IST [24621] DETAIL: There are no running transactions. 2018-03-21 16:16:42.267 IST [24623] LOG: logical decoding found consistent point at 0/1616DF0 2018-03-21 16:16:42.267 IST [24623] DETAIL: There are no running transactions. 2018-03-21 16:16:42.304 IST [24621] LOG: starting logical decoding for slot "mysub_16403_sync_16393" 2018-03-21 16:16:42.304 IST [24621] DETAIL: streaming transactions committing after 0/1616DF0, reading WAL from 0/1616DB8 2018-03-21 16:16:42.304 IST [24621] LOG: logical decoding found consistent point at 0/1616DB8 2018-03-21 16:16:42.304 IST [24621] DETAIL: There are no running transactions. 2018-03-21 16:16:42.306 IST [24620] LOG: logical replication table synchronization worker for subscription "mysub", table "test_rep" has finished 2018-03-21 16:16:42.308 IST [24622] LOG: logical replication table synchronization worker for subscription "mysub", table "test_rep_other" has finishedNOTICEメッセージでわかるように、レプリケーションスロットが作成され、最初のスナップショットまたはデルタの変更がターゲットデータベースに転送されるまでWALのクリーンアップが実行されないようになっています。次に、WAL送信者が変更のデコードを開始し、pubとsubの両方が開始されると、論理レプリケーションの適用が機能しました。次に、テーブルの同期を開始します。
-
サブスクリプションインスタンスのデータを確認します。
target_rep=# select count(1) from test_rep; count ------- 100 (1 row) Time: 0.927 ms target_rep=# select count(1) from test_rep_other ; count ------- 100 (1 row) Time: 0.767 ms target_rep=#ご覧のとおり、データは最初のスナップショットを通じて複製されています。
-
デルタの変更を確認します。
C1MQV0FZDTY3:bin bajishaik$ psql -d postgres -p 5555 -d source_rep -c "insert into test_rep values(generate_series(101,200), 'data'||generate_series(101,200))" INSERT 0 100 Time: 3.869 ms C1MQV0FZDTY3:bin bajishaik$ psql -d postgres -p 5555 -d source_rep -c "insert into test_rep_other values(generate_series(101,200), 'data'||generate_series(101,200))" INSERT 0 100 Time: 3.211 ms C1MQV0FZDTY3:bin bajishaik$ psql -d postgres -p 5556 -d target_rep -c "select count(1) from test_rep" count ------- 200 (1 row) Time: 1.742 ms C1MQV0FZDTY3:bin bajishaik$ psql -d postgres -p 5556 -d target_rep -c "select count(1) from test_rep_other" count ------- 200 (1 row) Time: 1.480 ms C1MQV0FZDTY3:bin bajishaik$
これらは、論理レプリケーションの基本的なセットアップの手順です。