データベースへのトラフィックの管理は、トラフィックの量が増え、データベースが実際には複数のサーバーに分散されるため、ますます困難になる可能性があります。 PostgreSQLクライアントは通常、単一のエンドポイントと通信します。プライマリノードに障害が発生すると、データベースクライアントは同じIPを再試行し続けます。セカンダリノードにフェイルオーバーした場合は、アプリケーションを新しいエンドポイントで更新する必要があります。これは、アプリケーションとデータベースインスタンスの間にロードバランサーを配置する場所です。アプリケーションを使用可能な/正常なデータベースノードに転送し、必要に応じてフェイルオーバーできます。もう1つの利点は、レプリカを効果的に使用して読み取りパフォーマンスを向上させることです。レプリカ間で読み取りのバランスをとる読み取り専用ポートを作成することができます。このブログでは、HAProxyについて説明します。それが何であるか、どのように機能するか、そしてPostgreSQLにどのようにデプロイするかを見ていきます。
HAProxyとは何ですか?
HAProxyは、TCPおよびHTTPベースのアプリケーションの高可用性、負荷分散、およびプロキシを実装するために使用できるオープンソースプロキシです。
ロードバランサーとして、HAProxyは1つの発信元から1つ以上の宛先にトラフィックを分散し、このタスクの特定のルールやプロトコルを定義できます。いずれかの宛先が応答を停止すると、オフラインとしてマークされ、トラフィックは残りの利用可能な宛先に送信されます。
HAProxyを手動でインストールして設定する方法
LinuxにHAProxyをインストールするには、次のコマンドを使用できます。
Ubuntu / Debian OSの場合:
$ apt-get install haproxy -yCentOS / RedHat OSの場合:
$ yum install haproxy -y次に、HAProxy構成を管理するために、次の構成ファイルを編集する必要があります。
$ /etc/haproxy/haproxy.cfgHAProxyの設定は複雑ではありませんが、何をしているのかを知る必要があります。 HAProxyの動作方法に応じて、設定するパラメータがいくつかあります。詳細については、HAProxy構成に関するドキュメントに従うことができます。
基本的な構成例を見てみましょう。次のデータベーストポロジがあるとします。
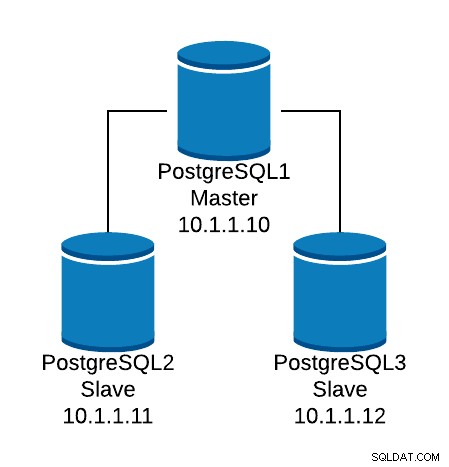 データベーストポロジの例
データベーストポロジの例 3つのノード間の読み取りトラフィックのバランスをとるためにHAProxyリスナーを作成したいと思います。
listen haproxy_read
bind *:5434
balance roundrobin
server postgres1 10.1.1.10:5432 check
server postgres2 10.1.1.11:5432 check
server postgres3 10.1.1.12:5432 check前に述べたように、ここで構成するパラメーターはいくつかあり、この構成は実行する内容によって異なります。例:
listen haproxy_read
bind *:5434
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string is\ running
balance leastconn
option tcp-check
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server postgres1 10.1.1.10:5432 check
server postgres2 10.1.1.11:5432 check
server postgres3 10.1.1.12:5432 checkClusterControlでのHAProxyの動作
PostgreSQLの場合、HAProxyは、デフォルトで2つの異なるポート(1つは読み取り/書き込み、もう1つは読み取り専用)を使用してClusterControlによって構成されます。
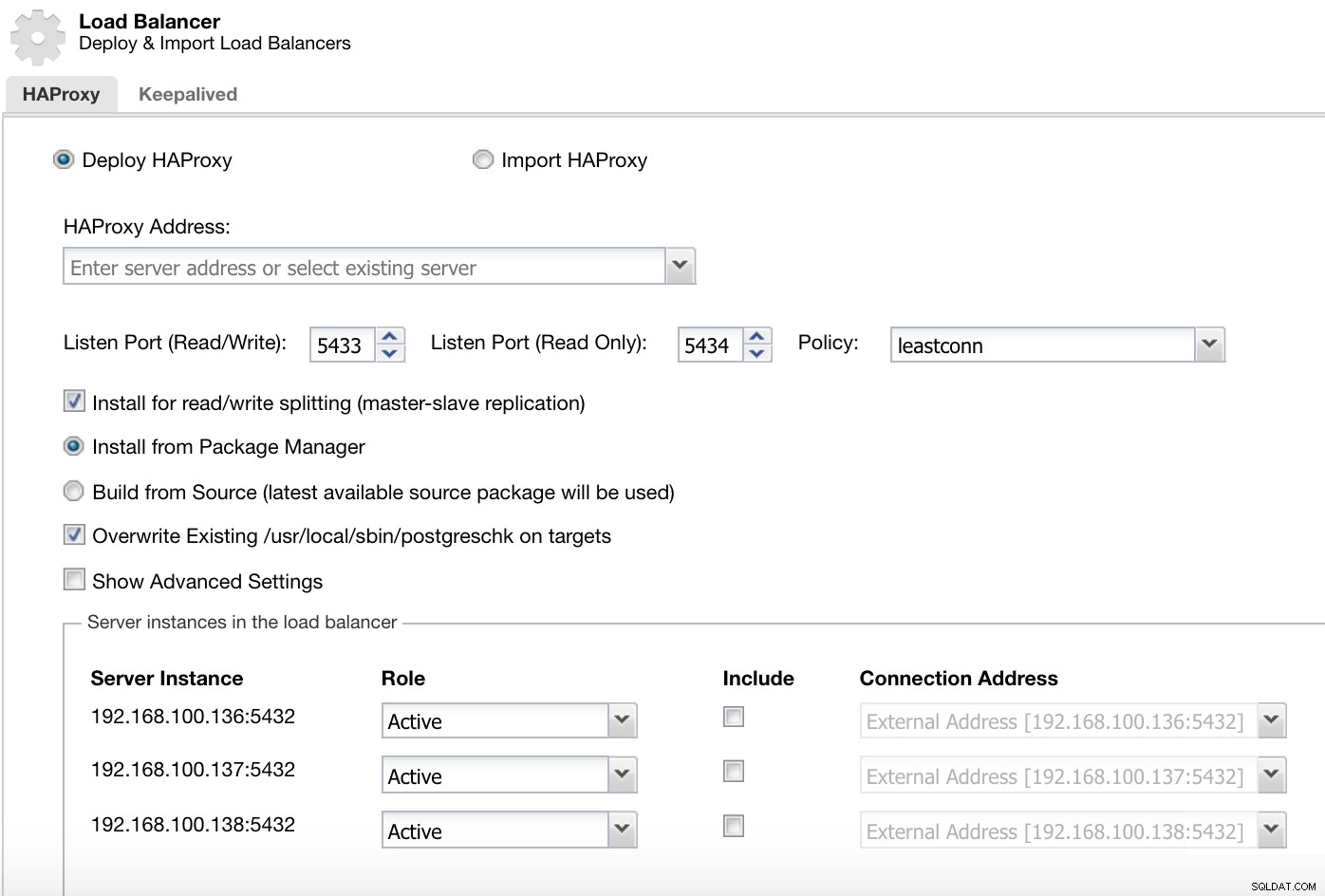 ClusterControlロードバランサーのデプロイ情報1
ClusterControlロードバランサーのデプロイ情報1 読み取り/書き込みポートでは、マスターサーバーがオンラインで、残りのノードがオフラインであり、読み取り専用ポートでは、マスターとスレーブの両方がオンラインです。
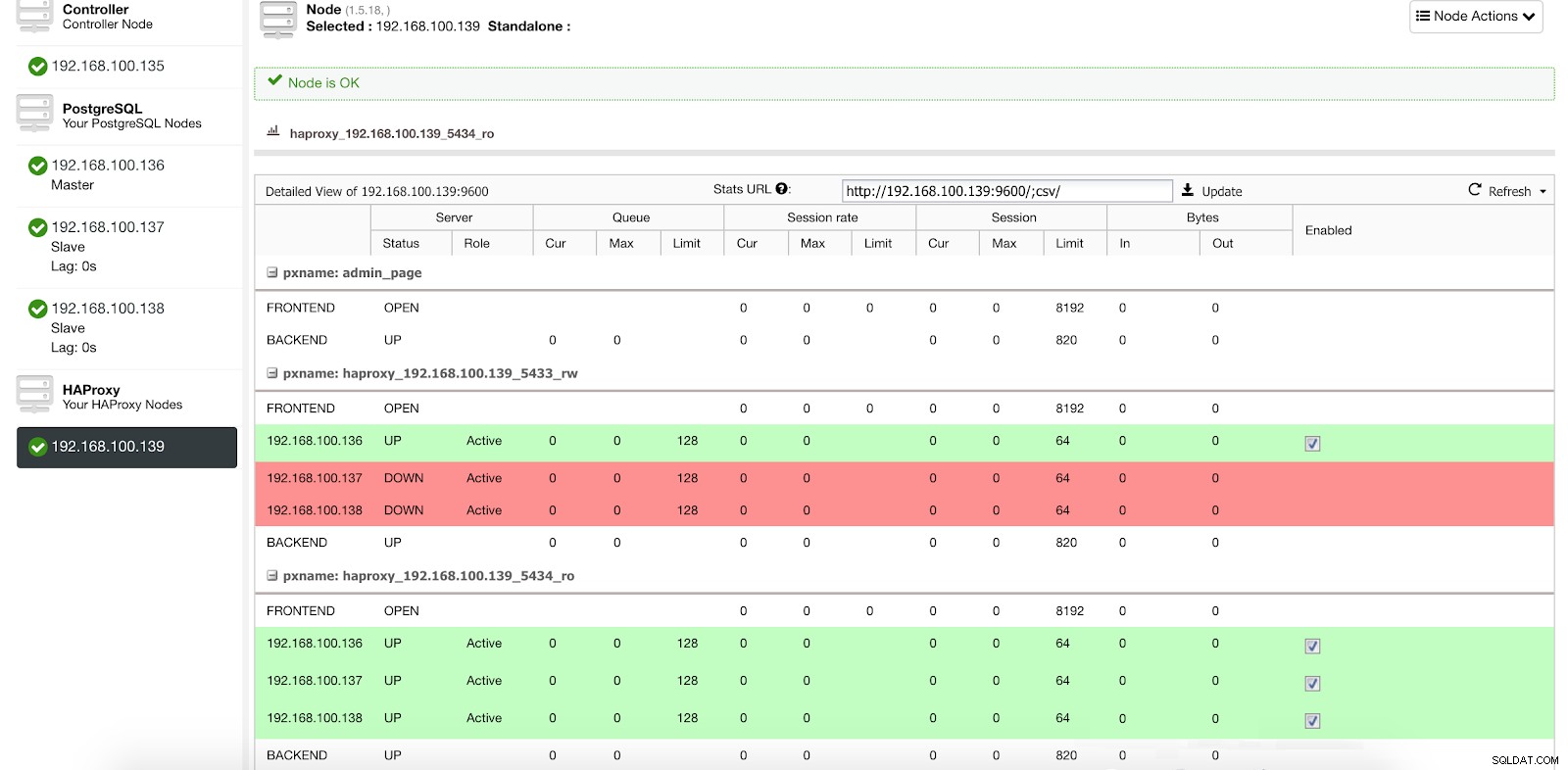 ClusterControlロードバランサーの統計1
ClusterControlロードバランサーの統計1 HAProxyは、マスターまたはスレーブのいずれかのノードにアクセスできないことを検出すると、自動的にオフラインとしてマークし、トラフィックの送信時に考慮しません。検出は、デプロイメント時にClusterControlによって構成されたヘルスチェックスクリプトによって行われます。これらは、インスタンスが稼働しているかどうか、回復中かどうか、または読み取り専用かどうかを確認します。
ClusterControlがスレーブをマスターにプロモートすると、HAProxyは古いマスターをオフライン(両方のポート)としてマークし、プロモートされたノードをオンライン(読み取り/書き込みポート)にします。
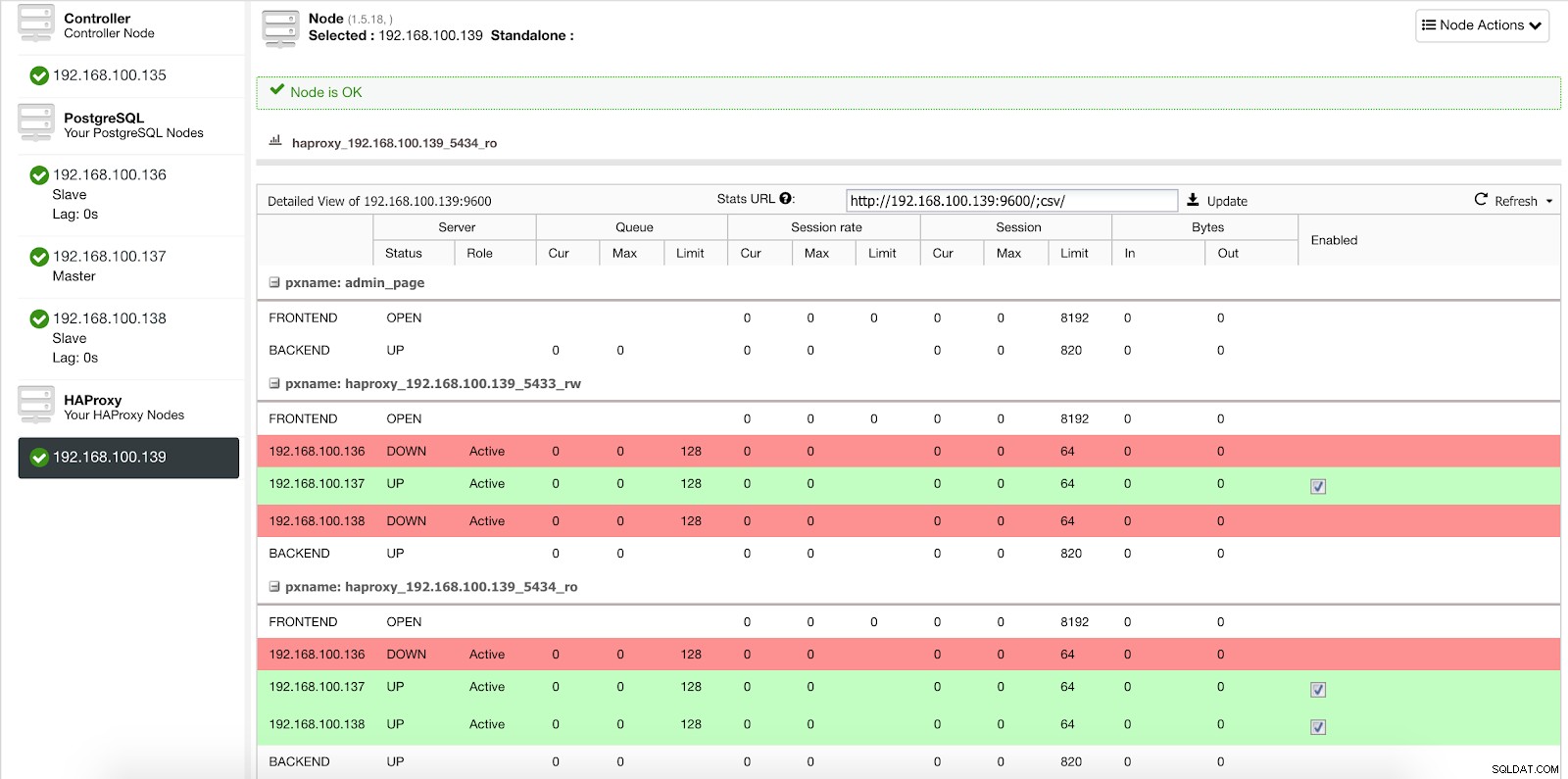 ClusterControlロードバランサーの統計2
ClusterControlロードバランサーの統計2 このようにして、私たちのシステムは私たちの介入なしに正常に動作し続けます。
ClusterControlを使用してHAProxyをデプロイする方法
この例では、1つのマスターと2つのスレーブを持つ環境を作成しました。ClusterControlのトポロジビューのスクリーンショットを参照してください。次に、HAProxyロードバランサーを追加します。
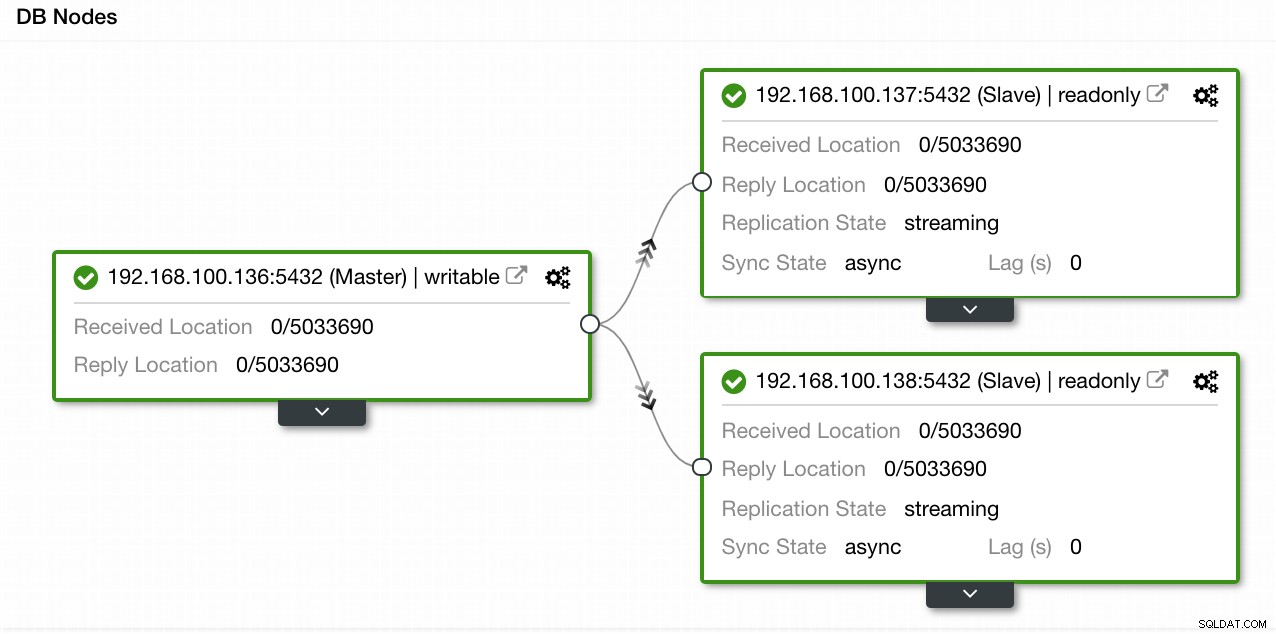 ClusterControlトポロジビュー1
ClusterControlトポロジビュー1 このタスクでは、ClusterControl-> PostgreSQL Cluster Actions-> Add Load Balancer
に移動する必要があります。 ClusterControlクラスターアクションメニュー
ClusterControlクラスターアクションメニュー ここで、ClusterControlがHAProxyロードバランサーのインストールと構成に使用する情報を追加する必要があります。
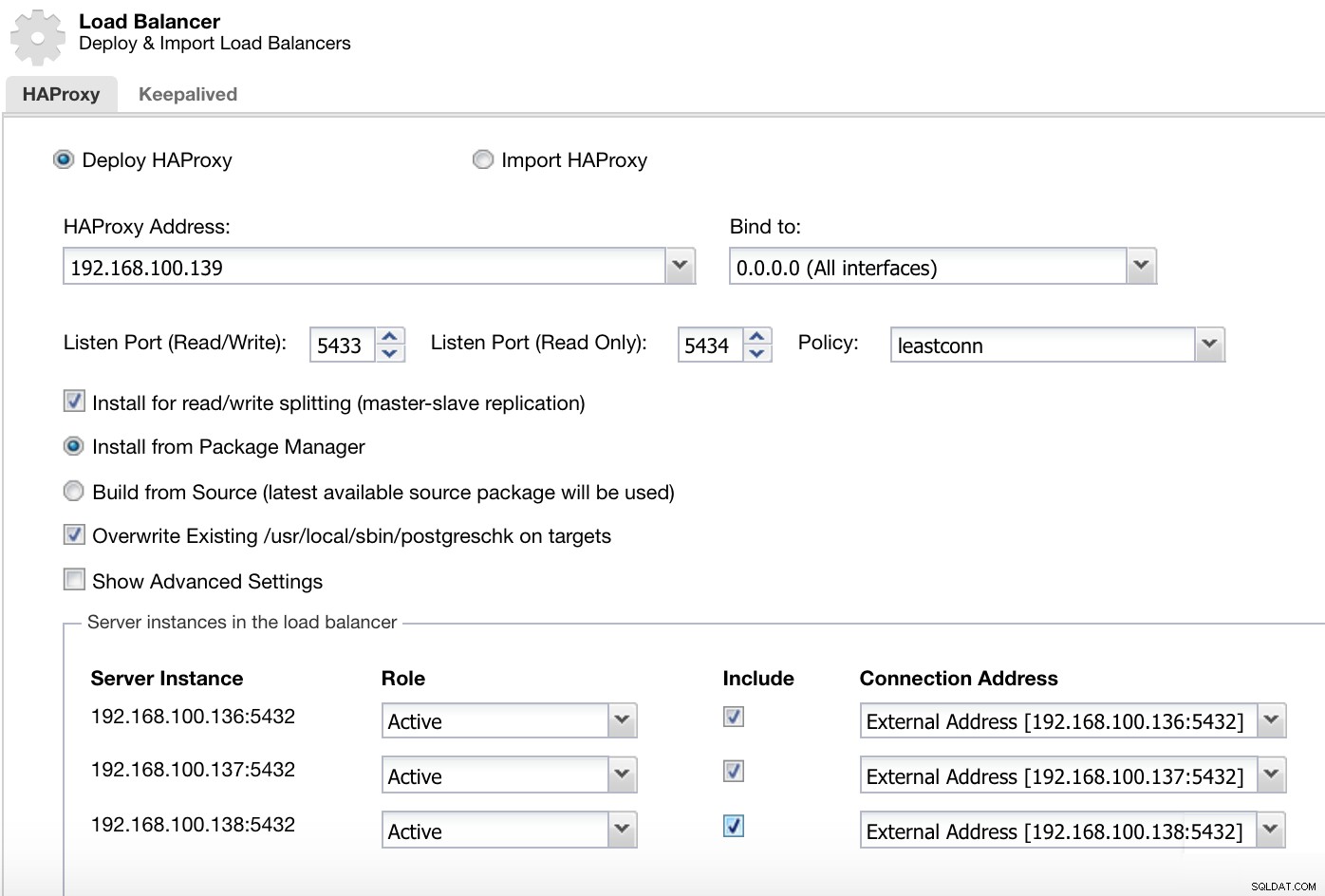 ClusterControlロードバランサーのデプロイ情報2
ClusterControlロードバランサーのデプロイ情報2 紹介する必要のある情報は次のとおりです。
アクション:デプロイまたはインポートします。
HAProxyアドレス:HAProxyサーバーのIPアドレス。
バインド先:HAProxyがリッスンするインターフェースまたはIPアドレス。
リッスンポート(読み取り/書き込み):読み取り/書き込みモードのポート。
リッスンポート(読み取り専用):読み取り専用モードのポート。
ポリシー:次のようになります:
- lessonconn:接続数が最も少ないサーバーが接続を受信します。
- ラウンドロビン:各サーバーは、その重みに応じて順番に使用されます。
- ソース:ソースIPアドレスはハッシュ化され、実行中のサーバーの総重量で除算されて、リクエストを受信するサーバーを指定します。
読み取り/書き込み分割用にインストール:マスター/スレーブレプリケーション用。
出典:パッケージマネージャーからインストールするか、ソースからビルドするかを選択できます。
ターゲットの既存のpostgreschkを上書きします。
また、HAProxy構成に追加するサーバーと、次のような追加情報を選択する必要があります。
役割:アクティブまたはバックアップにすることができます。
含める:はいまたはいいえ。
接続アドレス情報。
また、管理者ユーザー、バックエンド名、タイムアウトなどの詳細設定を構成できます。
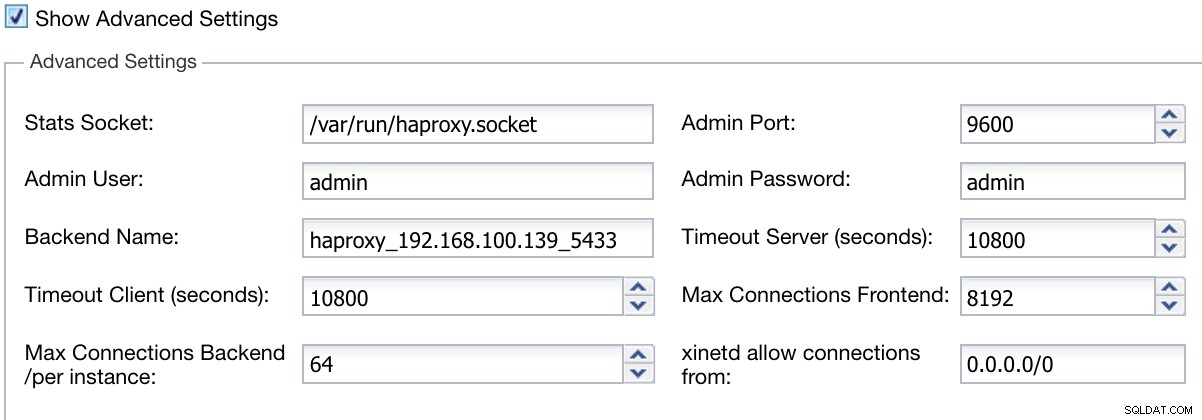 ClusterControlロードバランサーデプロイ情報詳細
ClusterControlロードバランサーデプロイ情報詳細 構成を完了してデプロイを確認すると、ClusterControlUIの[アクティビティ]セクションで進行状況を確認できます。
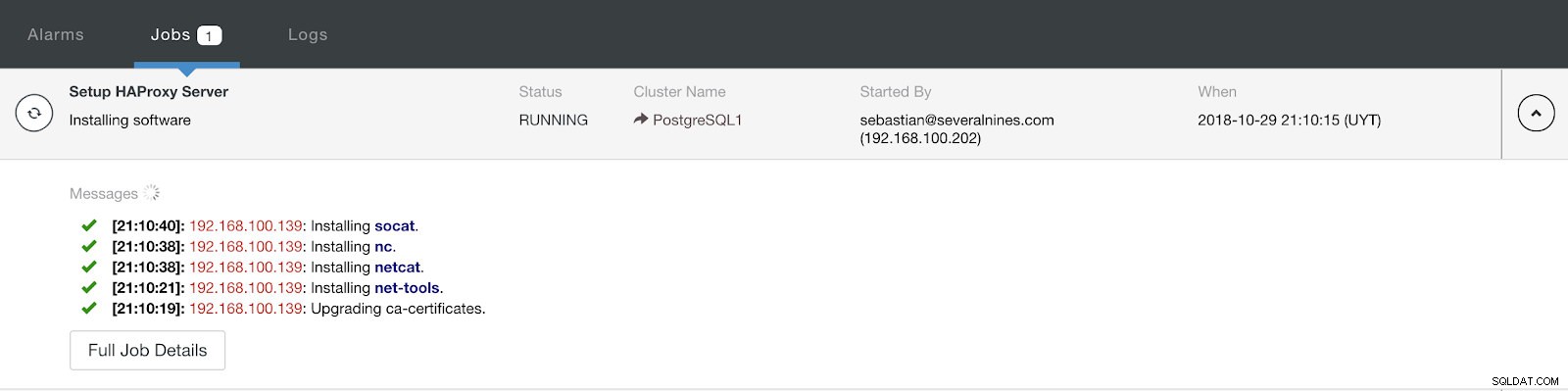 ClusterControlアクティビティセクション
ClusterControlアクティビティセクション 完了すると、次のトポロジが作成されます。
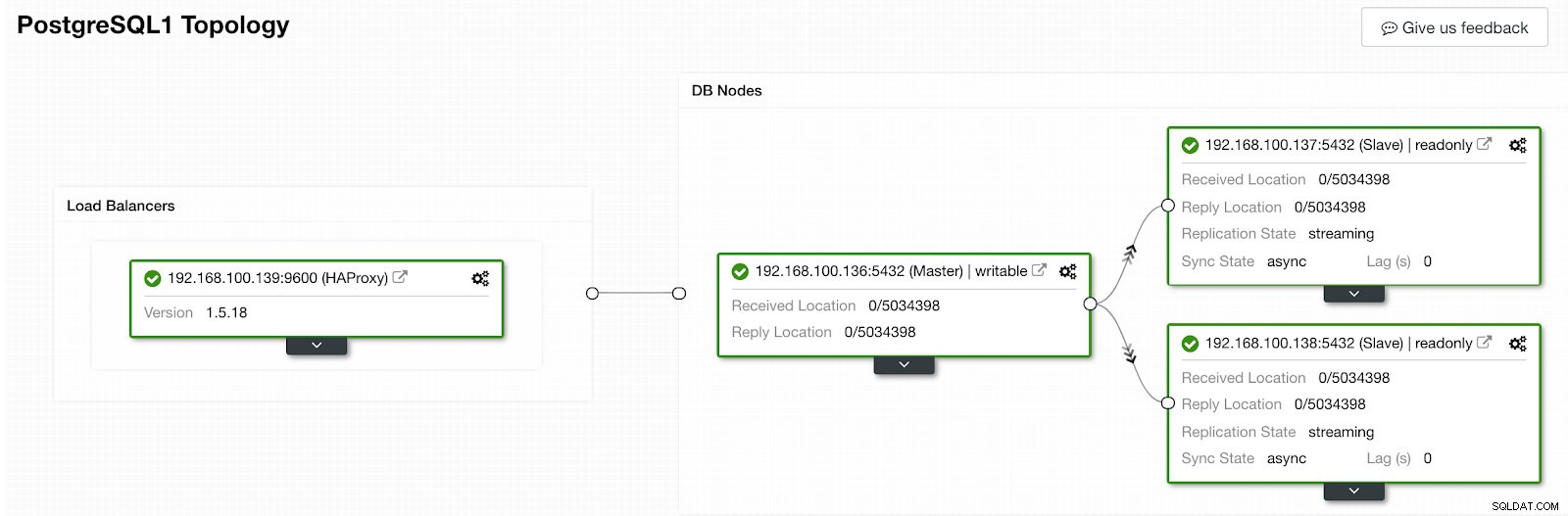 ClusterControlトポロジビュー2
ClusterControlトポロジビュー2 新しいHAProxyノードを追加し、それらの間にキープアライブサービスを構成することで、HA設計を改善できます。これはすべてClusterControlで実行できます。詳細については、PostgreSQLとHAに関する以前のブログを確認してください。
ClusterControlCLIを使用してHAProxyロードバランサーを追加する
s9s-toolsとも呼ばれるこのオプションのパッケージは、ClusterControlバージョン1.4.1で導入されました。これには、s9sと呼ばれるバイナリが含まれています。これは、ClusterControlを使用してデータベースインフラストラクチャを操作、制御、および管理するためのコマンドラインツールです。 s9sコマンドラインプロジェクトはオープンソースであり、GitHubにあります。
バージョン1.4.1以降、インストーラースクリプトは、ClusterControlノードにパッケージ(s9s-tools)を自動的にインストールします。
ClusterControl CLIは、クラスター自動化の新しい扉を開き、Ansible、Puppet、Chef、Saltなどの既存のデプロイメント自動化ツールと簡単に統合できます。
クラスタID1でIPアドレス192.168.100.142のHAProxyロードバランサを作成する方法の例を見てみましょう。
[example@sqldat.com ~]# s9s cluster --add-node --cluster-id=1 --nodes="haproxy://192.168.100.142" --wait
Add HaProxy to Cluster
/ Job 7 FINISHED [██████████] 100% Job finished.次に、コマンドラインからすべてのノードを確認できます。
[example@sqldat.com ~]# s9s node --cluster-id=1 --list --long
STAT VERSION CID CLUSTER HOST PORT COMMENT
coC- 1.7.0.2832 1 PostgreSQL1 192.168.100.135 9500 Up and running.
poS- 10.5 1 PostgreSQL1 192.168.100.136 5432 Up and running.
poM- 10.5 1 PostgreSQL1 192.168.100.137 5432 Up and running.
poS- 10.5 1 PostgreSQL1 192.168.100.138 5432 Up and running.
ho-- 1.5.18 1 PostgreSQL1 192.168.100.142 9600 Process 'haproxy' is running.
Total: 5s9sとその使用方法の詳細については、公式ドキュメントまたはこのトピックのブログの作成方法を確認してください。
結論
このブログでは、HAProxyがアプリケーションからPostgreSQLデータベースへのトラフィックを管理するのにどのように役立つかを確認しました。手動で展開および構成する方法を確認してから、ClusterControlを使用して自動化する方法を確認しました。 HAProxyが単一障害点(SPOF)になるのを防ぐために、少なくとも2つのHAProxyインスタンスをデプロイし、それらの上にKeepalivedやVirtualIPなどを実装するようにしてください。