以前のブログでは、単一のテーブルからデータを選択またはスキャンするさまざまな方法について説明しました。しかし実際には、単一のテーブルからデータをフェッチするだけでは不十分です。複数のテーブルからデータを選択し、それらの間で相関させる必要があります。テーブル間のこのデータの相関は、テーブルの結合と呼ばれ、さまざまな方法で実行できます。テーブルの結合には入力データ(テーブルスキャンなど)が必要なため、生成されたプランのリーフノードになることはできません。
例:簡単なクエリの例をSELECT*FROM TBL1、TBL2と考えてください。ここでTBL1.ID> TBL2.ID;生成された計画は次のとおりであると想定します。
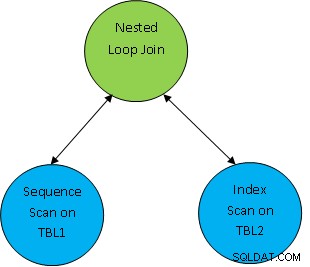
ここでは、最初に両方のテーブルがスキャンされ、次に次のように結合されます。 TBL.ID> TBL2.ID
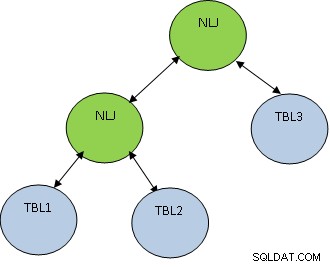
としての相関条件ごと結合方法に加えて、結合順序も非常に重要です。以下の例を考えてみましょう:
SELECT * FROM TBL1、TBL2、TBL3 WHERE TBL1.ID =TBL2.ID AND TBL2.ID =TBL3.ID;
TBL1、TBL2、TBL3にはそれぞれ10、100、1000レコードがあると考えてください。
条件TBL1.ID=TBL2.IDは5レコードのみを返しますが、TBL2.ID =TBL3.IDは100レコードを返すため、最初にTBL1とTBL2を結合して、より少ないレコード数を取得することをお勧めします。 TBL3に参加しました。計画は以下のようになります:
PostgreSQLは以下の種類の結合をサポートしています:
- ネストされたループ結合
- ハッシュ結合
- マージ参加
これらのJoinメソッドはそれぞれ、クエリやその他のパラメータに応じて同じように役立ちます。クエリ、テーブルデータ、結合句、選択性、メモリなど。これらの結合メソッドは、ほとんどのリレーショナルデータベースによって実装されています。
事前設定テーブルを作成し、これらのスキャン方法をよりよく説明するために頻繁に使用されるデータを入力しましょう。
postgres=# create table blogtable1(id1 int, id2 int);
CREATE TABLE
postgres=# create table blogtable2(id1 int, id2 int);
CREATE TABLE
postgres=# insert into blogtable1 values(generate_series(1,10000),3);
INSERT 0 10000
postgres=# insert into blogtable2 values(generate_series(1,1000),3);
INSERT 0 1000
postgres=# analyze;
ANALYZE以降のすべての例では、特に指定されていない限り、デフォルトの構成パラメーターを考慮します。
ネストされたループ結合(NLJ)は、外部関係の各レコードが内部関係の各レコードと一致する最も単純な結合アルゴリズムです。条件A.ID ネストされたループ結合(NLJ)は最も一般的な結合方法であり、あらゆるタイプの結合句を持つほぼすべてのデータセットで使用できます。このアルゴリズムは、内部関係と外部関係のすべてのタプルをスキャンするため、最もコストのかかる結合操作と見なされます。 上記の表とデータに従って、次のクエリを実行すると、次のようにネストされたループ結合が生成されます。 結合句は「<」であるため、ここで可能な結合方法はネストされたループ結合のみです。For each tuple r in A
For each tuple s in B
If (r.ID < s.ID)
Emit output tuple (r,s)postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 < bt2.id1;
QUERY PLAN
------------------------------------------------------------------------------
Nested Loop (cost=0.00..150162.50 rows=3333333 width=16)
Join Filter: (bt1.id1 < bt2.id1)
-> Seq Scan on blogtable1 bt1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 bt2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
ヒント:結合句が「=」で、リレーション間でネストされたループ結合が選択されている場合、ハッシュやマージ結合などのより効率的な結合方法を次の方法で選択できるかどうかを調べることが非常に重要です。構成の調整(例:work_memですが、これに限定されません)またはインデックスの追加など
一部のクエリには結合句がない場合があります。その場合、結合する唯一の選択肢はネストされたループ結合です。例えば。事前設定データに従って、以下のクエリを検討してください。
postgres=# explain select * from blogtable1, blogtable2;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=0.00..125162.50 rows=10000000 width=16)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(4 rows)上記の例の結合は、両方のテーブルのデカルト積にすぎません。
- ビルドフェーズ:ハッシュテーブルは、内部リレーションレコードを使用してビルドされます。ハッシュキーは、結合句キーに基づいて計算されます。
- プローブフェーズ:結合句キーに基づいて外部リレーションレコードがハッシュされ、ハッシュテーブルで一致するエントリが検索されます。
- ビルドフェーズ
- 内部関係Bの各タプルrについて
- キーr.IDを使用してハッシュテーブルHashTabにrを挿入します
- プローブフェーズ
- 外部リレーションAの各タプルについて
- バッカーHashTab[s.ID]のタプルrごとに
- If(s.ID =r.ID)
- 出力タプル(r、s)を出力します
上記の事前設定テーブルとデータに従って、次のクエリは以下に示すようにハッシュ結合になります。
postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 = bt2.id1;
QUERY PLAN
------------------------------------------------------------------------------
Hash Join (cost=27.50..220.00 rows=1000 width=16)
Hash Cond: (bt1.id1 = bt2.id1)
-> Seq Scan on blogtable1 bt1 (cost=0.00..145.00 rows=10000 width=8)
-> Hash (cost=15.00..15.00 rows=1000 width=8)
-> Seq Scan on blogtable2 bt2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows) ここで、ハッシュテーブルはテーブルblogtable2に作成されます。これは、テーブルが小さいため、ハッシュテーブルとハッシュテーブル全体に必要な最小限のメモリをメモリに収めることができるためです。
マージ結合は、結合句が一致する可能性があるまで、外部関係の各レコードが内部関係の各レコードと一致するアルゴリズムです。この結合アルゴリズムは、両方の関係がソートされ、結合句の演算子が「=」である場合にのみ使用されます。条件A.ID=B.IDの関係AとBの間の結合は、次のように表すことができます。
For each tuple r in A
For each tuple s in B
If (r.ID = s.ID)
Emit output tuple (r,s)
Break;
If (r.ID > s.ID)
Continue;
Else
Break;上記のように、ハッシュ結合が発生したクエリの例では、両方のテーブルにインデックスが作成された場合、マージ結合が発生する可能性があります。これは、Merge Joinメソッドの主要な基準の1つであるインデックスにより、テーブルデータを並べ替えられた順序で取得できるためです。
postgres=# create index idx1 on blogtable1(id1);
CREATE INDEX
postgres=# create index idx2 on blogtable2(id1);
CREATE INDEX
postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 = bt2.id1;
QUERY PLAN
---------------------------------------------------------------------------------------
Merge Join (cost=0.56..90.36 rows=1000 width=16)
Merge Cond: (bt1.id1 = bt2.id1)
-> Index Scan using idx1 on blogtable1 bt1 (cost=0.29..318.29 rows=10000 width=8)
-> Index Scan using idx2 on blogtable2 bt2 (cost=0.28..43.27 rows=1000 width=8)
(4 rows)つまり、ご覧のとおり、両方のテーブルがシーケンシャルスキャンではなくインデックススキャンを使用しているため、両方のテーブルが並べ替えられたレコードを出力します。
PostgreSQLは、プランナーに関連するさまざまな構成をサポートしています。これを使用して、クエリオプティマイザーに特定の種類の結合メソッドを選択しないようにヒントを与えることができます。オプティマイザーによって選択された結合メソッドが最適でない場合は、これらの構成パラメーターをオフにして、クエリオプティマイザーに別の種類の結合メソッドを選択させることができます。これらの構成パラメーターはすべて、デフォルトで「オン」になっています。以下は、結合メソッドに固有のプランナー構成パラメーターです。
- enable_nestloop :ネストされたループ結合に対応します。
- enable_hashjoin :ハッシュ結合に対応します。
- enable_mergejoin :マージ結合に対応します。
さまざまな目的で使用される、プランに関連する多くの構成パラメーターがあります。このブログでは、結合メソッドのみに制限されています。
これらのパラメータは、特定のセッションから変更できます。したがって、特定のセッションの計画を試してみたい場合は、これらの構成パラメーターを操作しても、他のセッションはそのまま機能し続けます。
ここで、上記のマージ結合とハッシュ結合の例について考えてみます。インデックスがない場合、クエリオプティマイザは以下に示すように以下のクエリに対してハッシュ結合を選択しましたが、構成を使用した後、インデックスがなくても結合をマージするように切り替わります:
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 = blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Hash Join (cost=27.50..220.00 rows=1000 width=16)
Hash Cond: (blogtable1.id1 = blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Hash (cost=15.00..15.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# set enable_hashjoin to off;
SET
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 = blogtable2.id1;
QUERY PLAN
----------------------------------------------------------------------------
Merge Join (cost=874.21..894.21 rows=1000 width=16)
Merge Cond: (blogtable1.id1 = blogtable2.id1)
-> Sort (cost=809.39..834.39 rows=10000 width=8)
Sort Key: blogtable1.id1
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Sort (cost=64.83..67.33 rows=1000 width=8)
Sort Key: blogtable2.id1
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(8 rows)テーブルのデータが並べ替えられていないため、最初はハッシュ結合が選択されています。マージ結合プランを選択するには、最初に両方のテーブルから取得したすべてのレコードを並べ替えてから、マージ結合を適用する必要があります。したがって、並べ替えのコストが追加されるため、全体的なコストが増加します。したがって、この場合、合計(増加を含む)コストがハッシュ結合の合計コストよりも大きい可能性があるため、ハッシュ結合が選択されます。
構成パラメーターenable_hashjoinが「off」に変更されると、これは、クエリオプティマイザーがハッシュ結合のコストを無効化コスト(=1.0e10、つまり10000000000.00)として直接割り当てることを意味します。可能な参加のコストはこれよりも少なくなります。したがって、enable_hashjoinが「off」に変更された後のマージ結合での同じクエリ結果は、並べ替えコストを含めても、マージ結合の合計コストは無効化コストよりも少なくなります。
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 < blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=0.00..150162.50 rows=3333333 width=16)
Join Filter: (blogtable1.id1 < blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# set enable_nestloop to off;
SET
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 < blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=10000000000.00..10000150162.50 rows=3333333 width=16)
Join Filter: (blogtable1.id1 < blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)上記のように、ネストされたループ結合関連の構成パラメーターが「オフ」に変更されても、他の種類の結合メソッドを取得する代替の可能性がないため、ネストされたループ結合が選択されます。選択されました。簡単に言えば、ネストされたループ結合が唯一の可能な結合であるため、コストが何であれ、常に勝者になります(私が一人で走った場合、100メートルレースで勝者だったのと同じです…:-))。また、1番目と2番目のプランのコストの違いに注意してください。最初のプランはネストされたループ結合の実際のコストを示していますが、2番目のプランは同じものの無効化コストを示しています。
すべての種類のPostgreSQL結合メソッドは便利であり、クエリ、データ、結合句などの性質に基づいて選択されます。クエリが期待どおりに実行されない場合、つまり結合メソッドが実行されない場合期待どおりに選択すると、ユーザーは利用可能なさまざまなプラン構成パラメーターを試して、何かが不足していないかどうかを確認できます。