私は長い間、正しいデータ型を選択することを提案してきました。以前の「BadHabits」ブログ投稿でいくつかの例について話しましたが、今週末のSQL土曜日#162(ケンブリッジ、英国)で、DATETIMEの使用に関するトピックがあります。 デフォルトで登場しました。 T-SQL:Bad Habits and Best Practicesのプレゼンテーション後の会話で、ユーザーはDATETIMEを使用しているだけだと述べました。 分または日の粒度のみが必要な場合でも、このようにして、企業全体の日付/時刻列は常に同じデータ型になります。これは無駄であり、一貫性は価値がないかもしれないと提案しましたが、今日、私は自分の理論を証明するために着手することにしました。
TL;DRバージョン
以下の私のテストでは、DATETIMEに固執する代わりに、より細いデータ型の使用を検討したいシナリオが確かにあることがわかります。 どこにでも。ただし、これに対する私のテストが別の方向を示していることを確認することは重要です。また、可能な限り本番環境に忠実なハードウェアとデータを使用して、環境内のスキーマに対してこれらのシナリオをテストすることも重要です。結果は変わる可能性があり、ほぼ確実に変わるでしょう。
宛先テーブル
粒度が1日だけ重要である場合を考えてみましょう(時間、分、秒は気にしません)。このために、DATETIMEを選択できます (ユーザーが提案したように)、またはSMALLDATETIME 、またはDATE SQLServer2008以降。検討したいデータには、次の2種類もあります。
- リアルタイムでほぼ順番に挿入されるデータ(例:現在発生しているイベント)。
- ランダムに挿入されるデータ(例:新しいメンバーの生年月日)
次のような2つのテーブルから始めて、さらに4つ作成しました(SMALLDATETIME用に2つ、DATE用に2つ):
CREATE TABLE dbo.BirthDatesRandom_Datetime(ID INT IDENTITY(1,1)PRIMARY KEY、dt DATETIME NOT NULL); CREATE TABLE dbo.EventsSequential_Datetime(ID INT IDENTITY(1,1)PRIMARY KEY、dt DATETIME NOT NULL); CREATE INDEX d ON dbo.BirthDatesRandom_Datetime(dt); CREATE INDEX d ON dbo.EventsSequential_Datetime(dt); -次に、DATEとSMALLDATETIMEについて繰り返します。
そして、私の目標は、これら2つの異なる方法でバッチ挿入のパフォーマンスをテストすることと、全体的なストレージサイズと断片化への影響、そして最後に範囲クエリのパフォーマンスをテストすることでした。
サンプルデータ
いくつかのサンプルデータを生成するために、私は便利な手法の1つを使用して、そうでないものから意味のあるものを生成しました。それはカタログビューです。私のシステムでは、これは約12秒で971個の異なる日付/時刻値(合計1,000,000行)を返しました:
; WITH y AS(SELECT TOP(1000000)d =DATEADD(SECOND、x、DATEADD(DAY、DATEDIFF(DAY、x、0)、 '20120101'))FROM(SELECT s1。[object_id]%1000 FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2)AS x(x)ORDER BY NEWID())SELECT DISTINCT d FROM y;
これらの100万行をテーブルに配置して、3つの異なるセッションウィンドウからのまったく同じデータに対して異なるアクセス方法を使用して、順次/ランダム挿入をシミュレートできるようにしました。
CREATE TABLE dbo.Staging(ID INT IDENTITY(1,1)PRIMARY KEY、source_date DATETIME NOT NULL);; WITH Staging_Data AS(SELECT TOP(1000000)dt =DATEADD(SECOND、x、DATEADD(DAY、DATEDIFF(DAY、x、0)、 '20110101'))FROM(SELECT s1。[object_id]%1000 FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2)AS sd(x)ORDER BY NEWID())INSERT dbo.Staging(source_date)SELECT dt FROM y ORDER BY dt;
このプロセスの完了には少し時間がかかりました(20秒)。次に、同じデータを格納するために2番目のテーブルを作成しましたが、ランダムに分散しました(すべての挿入で同じ分散を繰り返すことができるように)。
CREATE TABLE dbo.Staging_Random(ID INT IDENTITY(1,1)PRIMARY KEY、source_date DATETIME NOT NULL); INSERT dbo.Staging_Random(source_date)SELECT source_date FROM dbo.Staging ORDER BY NEWID();
テーブルにデータを入力するためのクエリ
次に、3つのクエリウィンドウを使用して少なくとも少しの同時実行性をシミュレートし、他のテーブルにこのデータを入力する一連のクエリを作成しました。
WAITFOR TIME '13:53'; GO DECLARE @d DATETIME2 =SYSDATETIME(); INSERT dbo。{table_name}(dt)-メソッド/データ型に応じてSELECT source_date FROM dbo.Staging[_Random]-宛先に応じてWHEREID%3=<0,1,2>-クエリウィンドウに応じてORDER IDによる; SELECT DATEDIFF(MILLISECOND、@d、SYSDATETIME()); 前回の投稿と同様に、データベースを事前に拡張して、あらゆる種類のデータファイルの自動拡張イベントが結果に干渉しないようにしました。このような大規模なトランザクションのログアクティビティが干渉するのを防ぐことはできないため、1回のパスで100万行の挿入を実行することは完全に現実的ではありませんが、各メソッドで一貫して実行する必要があります。私がテストしているハードウェアが使用しているハードウェアとは完全に異なることを考えると、絶対的な結果は重要なポイントではなく、相対的な比較にすぎません。
(将来のテストでは、比較的混合されたデータを含むログファイルからの実際のバッチでこれを試し、ソーステーブルのチャンクをループで使用します。これらも興味深い実験になると思います。もちろん追加します。ミックスへの圧縮。)
結果:
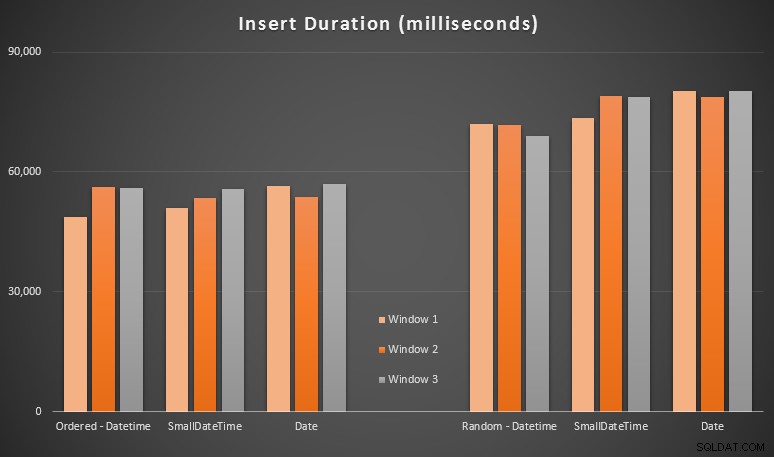
これらの結果は私にとってそれほど驚くべきことではありませんでした。ランダムな順序で挿入すると、順番に挿入するよりも実行時間が長くなりました。SQLServerのインデックスがどのように機能し、より多くの「悪い」ページ分割が発生する可能性があるかを理解するというルーツに戻ることができます。このシナリオ(この演習ではページ分割を特に監視していませんが、今後のテストで検討します)。
ランダムな側面では、着信データの暗黙的な変換がタイミングに影響を与えている可能性があることに気付きました。これは、ネイティブのDATETIME -> DATETIMEよりも少し高いように見えたためです。 挿入します。そこで、ソースデータを含む2つの新しいテーブルを作成することにしました。1つはDATEを使用しています 1つはSMALLDATETIMEを使用します 。これにより、データ型を挿入ステートメントに渡す前にデータ型を適切に変換することがある程度シミュレートされるため、挿入中に暗黙的な変換は必要ありません。新しいテーブルとその入力方法は次のとおりです。
CREATE TABLE dbo.Staging_Random_SmallDatetime(ID INT IDENTITY(1,1)PRIMARY KEY、source_date SMALLDATETIME NOT NULL); CREATE TABLE dbo.Staging_Random_Date(ID INT IDENTITY(1,1)PRIMARY KEY、source_date DATE NOT NULL); INSERT dbo.Staging_Random_SmallDatetime(source_date)SELECT CONVERT(SMALLDATETIME、source_date)FROM dbo.Staging_Random ORDER BY ID; INSERT dbo.Staging_Random_Date(source_date)SELECT CONVERT(DATE、source_date)FROM dbo.Staging_Random ORDER BY ID;
これは私が望んでいた効果はありませんでした–タイミングはすべての場合で同様でした。だから、それは野生のガチョウの追跡でした。
使用スペースと断片化
次のクエリを実行して、各テーブルに予約されているページ数を確認しました。
SELECT name='dbo。' + OBJECT_NAME([object_id])、pages =SUM(reserved_page_count)FROM sys.dm_db_partition_stats GROUP BY OBJECT_NAME([object_id])ORDERBYページ;
結果:
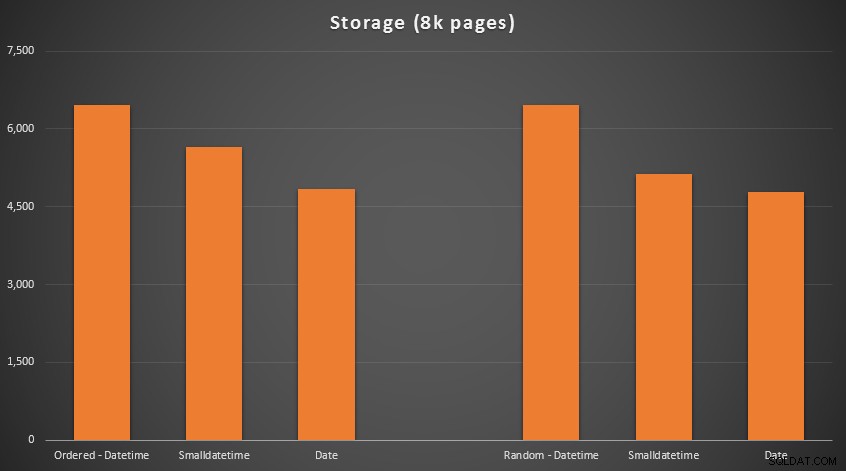
ここにはロケット科学はありません。より小さなデータ型を使用する場合は、より少ないページを使用する必要があります。 DATETIMEからの切り替え DATEへ SMALLDATETIMEが使用されるページ数は、一貫して25%削減されました。 要件を13〜20%削減しました。
非クラスター化インデックスの断片化とページ密度について(クラスター化インデックスの違いはほとんどありませんでした):
SELECT'{table_name}'、index_id avg_page_space_used_in_percent、avg_fragmentation_in_percent FROM sys.dm_db_index_physical_stats(DB_ID()、OBJECT_ID('{table_name}')、NULL、NULL、'DETAILED')WHERE index_level =0 AND index / pre>
結果:
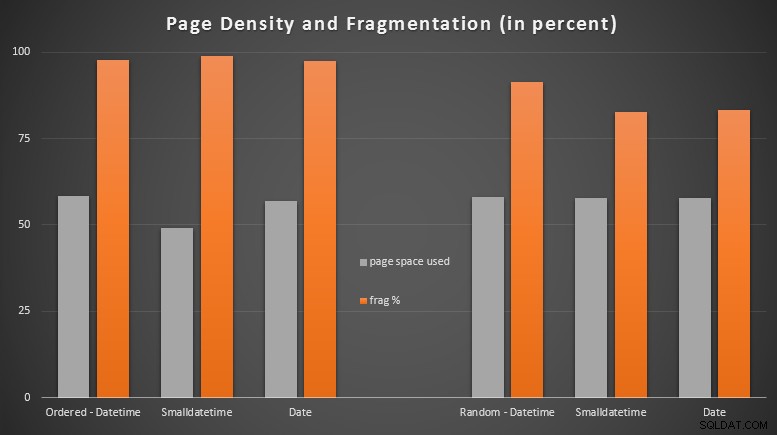
順序付けられたデータがほぼ完全に断片化されているのを見て、私は非常に驚きましたが、ランダムに挿入されたデータは、実際にはわずかにページの使用率が向上しました。これは、これらの特定のテストの範囲外でさらに調査する必要があることに注意しましたが、大部分が順次挿入に依存している非クラスター化インデックスがあるかどうかを確認する必要があるかもしれません。
[6つのテーブルすべての非クラスター化インデックスのオンライン再構築は7秒で実行され、ページ密度は99.5%の範囲に戻り、断片化は1%未満になりました。しかし、以下のクエリテストを実行するまでそれを実行しませんでした…]
範囲クエリテスト
最後に、OLTPタイプの書き込みアクティビティによって引き起こされる固有の断片化と、再構築されるクリーンなインデックスの両方で、さまざまなインデックスに対する単純な日付範囲クエリの実行時間への影響を確認したいと思いました。クエリ自体は非常に単純です:
SELECT TOP(200000)dtFROMdbo。{table_name}WHEREdt> ='20110101' ORDER BY dt;
SQL SentryPlanExplorerを使用してインデックスを再構築する前の結果は次のとおりです。
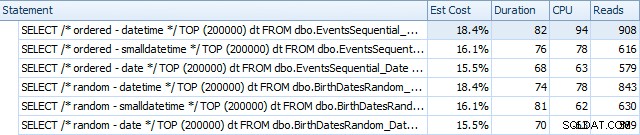
そして、それらは再構築後にわずかに異なります:
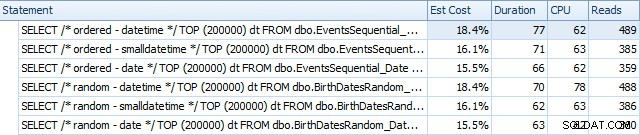
基本的に、DATETIMEバージョンの期間と読み取りはわずかに長くなりますが、CPUの違いはほとんどありません。また、SMALLDATETIMEとDATEの違いは比較するとごくわずかです。すべてのクエリには、次のような単純なクエリプランがありました:

(もちろん、シークは順序付けられた範囲スキャンです。)
結論
確かに、これらのテストは非常に細工されており、より多くの順列の恩恵を受けることができますが、私が期待したことを大まかに示しています。この特定の選択に対する最大の影響は、非クラスター化インデックスが占めるスペースにあります(より細いデータ型を選択すると、確かにメリットがあります)、そして挿入を順番ではなく任意の順序で実行するために必要な時間(DATETIME わずかなエッジしかありません。
このようなデータ型の選択肢をより徹底的で罰則的なテストにかける方法について、あなたのアイデアを聞いてみたいと思います。今後の投稿でさらに詳しく説明する予定です。