データベースの高可用性を実現する必要性は非常に一般的なタスクであり、多くの場合、必須です。会社の予算が限られている場合、同じクラウドプロバイダーで実行されているレプリケーションスレーブ(または複数)を維持する(いつか必要になる場合は待機する)のはコストがかかる可能性があります。アプリケーションの種類によっては、RTO(目標復旧時間)を改善するためにレプリケーションスレーブが必要になる場合があります。
ただし、会社がシステムをオンラインに戻すための短い遅延を受け入れることができる場合は、別のオプションがあります。
コールドスタンバイは、プライマリノードのスタンバイノード(バックアップとして)がある冗長方式です。このノードは、マスター障害時にのみ使用されます。残りの時間は、コールドスタンバイノードがシャットダウンされ、必要な場合にのみバックアップをロードするために使用されます。
この方法を使用するには、会社の許容可能なRPO(目標復旧時点)に従って、事前定義されたバックアップポリシー(冗長性あり)を用意する必要があります。 12時間のデータを失うことはビジネスにとって許容できることであるか、1時間だけを失うことは大きな問題になる可能性があります。すべての企業とアプリケーションは、独自の基準を決定する必要があります。
このブログでは、バックアップポリシーを作成する方法と、ClusterControlとAmazonAWSとの統合を使用してバックアップポリシーをコールドスタンバイサーバーに復元する方法を学習します。
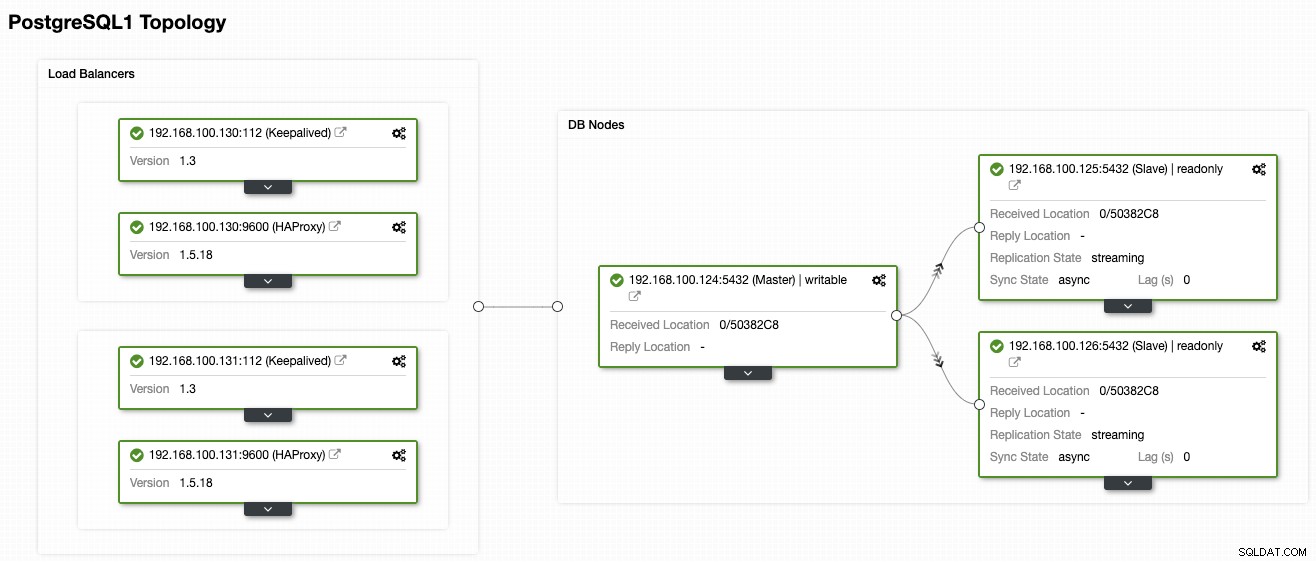
このブログでは、AWSアカウントとClusterControlがすでにインストールされていることを前提としています。この例ではクラウドプロバイダーとしてAWSを使用しますが、別のプロバイダーを使用することもできます。 ClusterControlを使用してデプロイされた次のPostgreSQLトポロジを使用します。
- 1PostgreSQLプライマリノード
- 2つのPostgreSQLホットスタンバイノード
- 2つのロードバランサー(HAProxy +キープアライブ)
このタイプのポリシーを作成するためのベストプラクティスは、バックアップファイルを3つの異なる場所に保存することです。1つはデータベースサーバーにローカルに保存され(リカバリを高速化するため)、もう1つは集中バックアップサーバーに保存されます。クラウドの最後のもの。
完全バックアップ、増分バックアップ、および差分バックアップも使用することで、これを改善できます。 ClusterControlを使用すると、使いやすく使いやすいUIを使用して、上記のすべてのベストプラクティスをすべて同じシステムから実行できます。 ClusterControlでAWS統合を作成することから始めましょう。
ClusterControlAWS統合の設定
ClusterControl->統合->クラウドプロバイダー->クラウドクレデンシャルの追加に移動します。
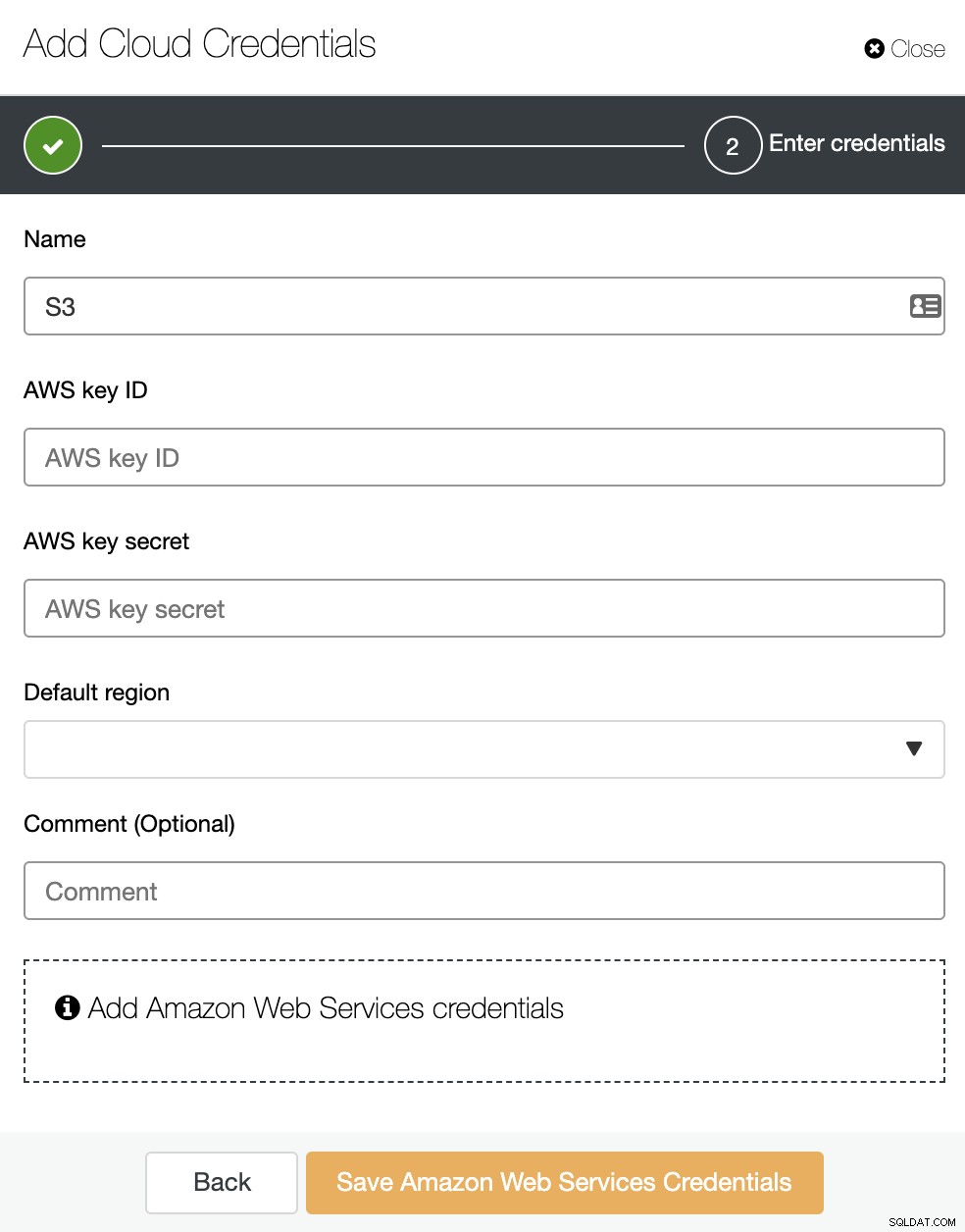
ここで、名前、デフォルトリージョン、AWSを追加する必要がありますキーIDとキーシークレット。これらの最後のものを取得または作成するには、AWSマネジメントコンソールのIAM(IDおよびアクセス管理)セクションに移動する必要があります。詳細については、当社のドキュメントまたはAWSのドキュメントを参照してください。
これで統合が作成されたので、次を使用して最初のバックアップをスケジュールします。 ClusterControl。
ClusterControlを使用したバックアップのスケジュール
ClusterControl->PostgreSQLクラスター->バックアップ->バックアップの作成を選択します。
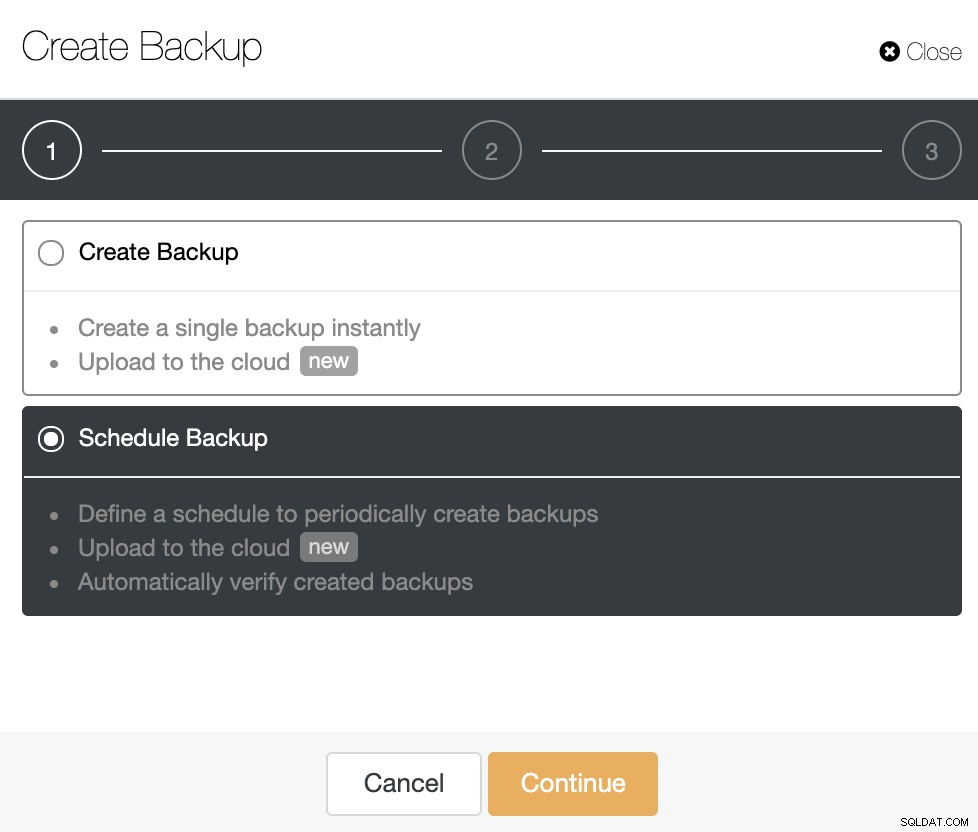
単一のバックアップを即座に作成するか、スケジュールを設定するかを選択できます新しいバックアップ。それでは、2番目のオプションを選択して続行しましょう。
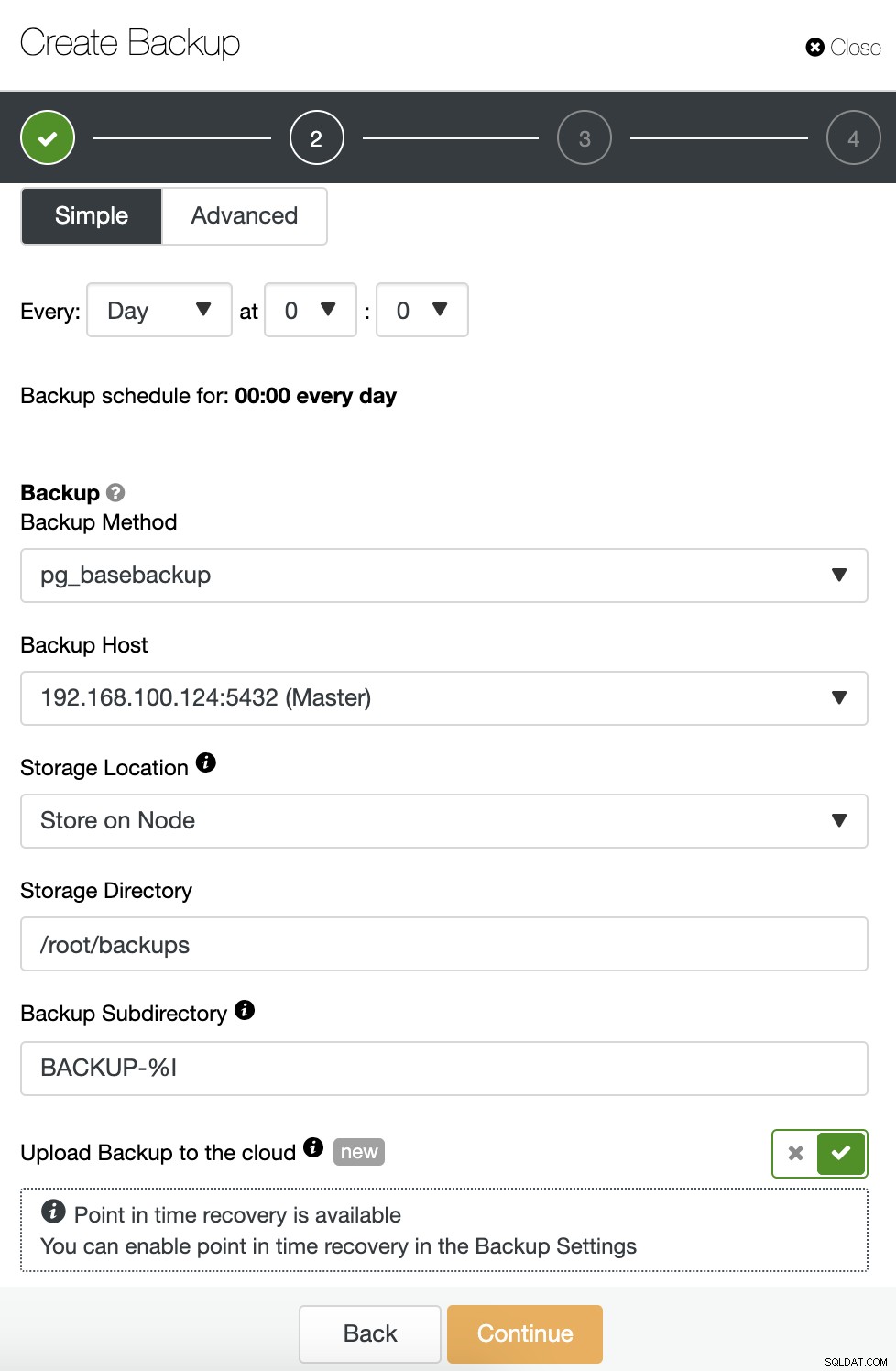
バックアップをスケジュールするときは、最初にスケジュールを指定する必要があります/周波数。次に、バックアップ方法(pg_dumpall、pg_basebackup、pgBackRest)、バックアップの取得元のサーバー、およびバックアップの保存場所を選択する必要があります。対応するボタンを有効にして、バックアップをクラウド(AWS、Google、またはAzure)にアップロードすることもできます。
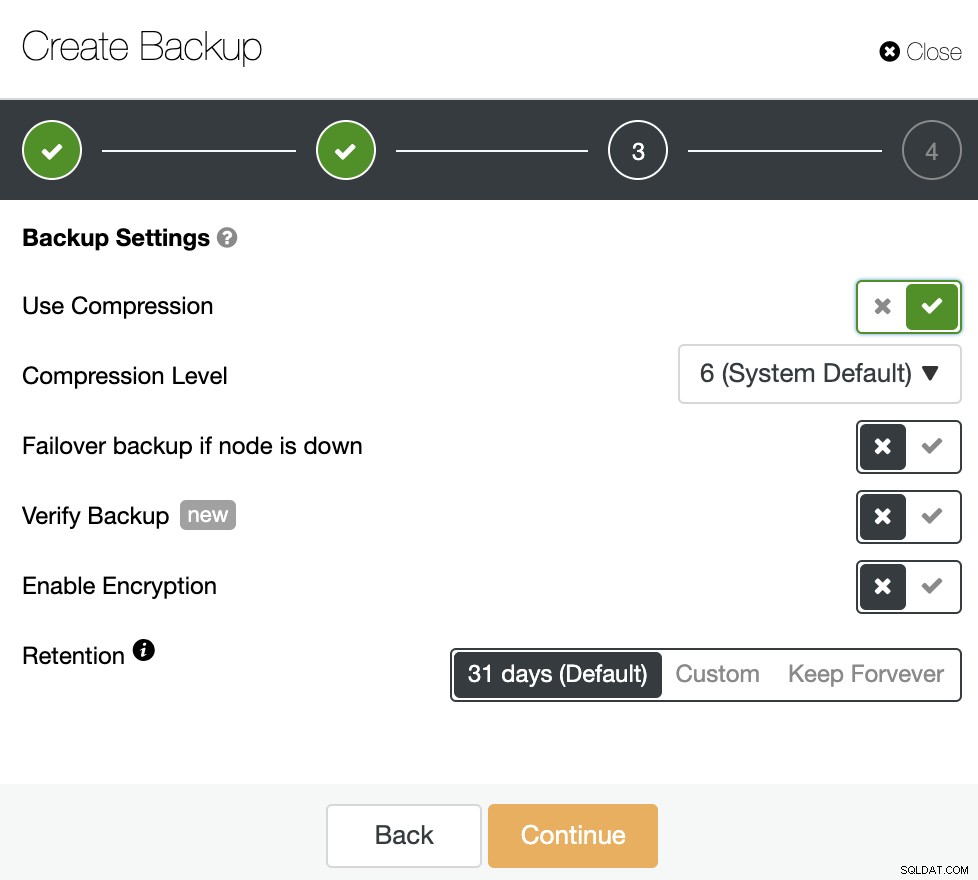
次に、圧縮の使用、圧縮レベル、暗号化、および保持期間を指定しますあなたのバックアップのために。 「バックアップの確認」と呼ばれる別の機能があります。これについては、このブログ投稿ですぐに詳しく説明します。
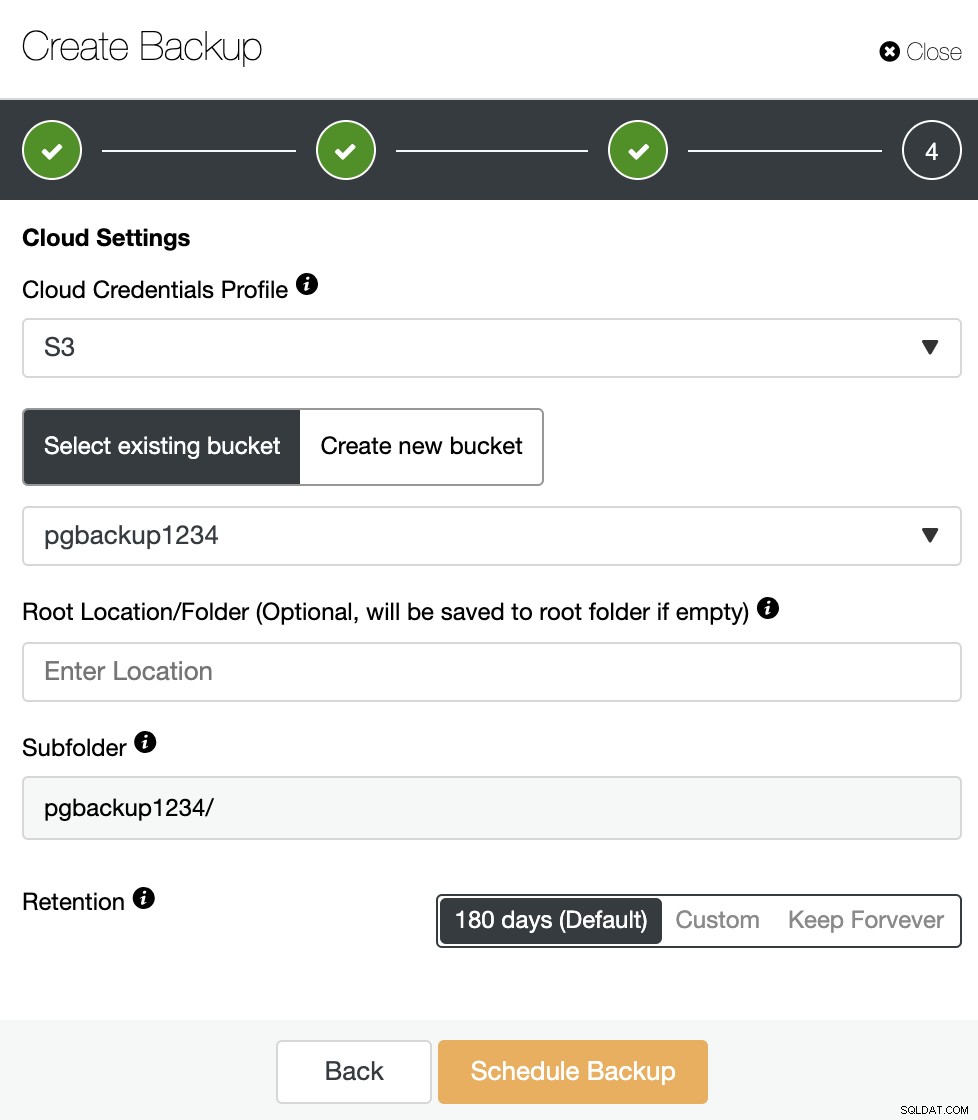
[クラウドにバックアップをアップロード]オプションが有効になっている場合は、クラウド資格情報を選択し、バックアップを保存するS3バケットを作成または選択する必要があるこの手順を参照してください。保存期間も指定する必要があります。
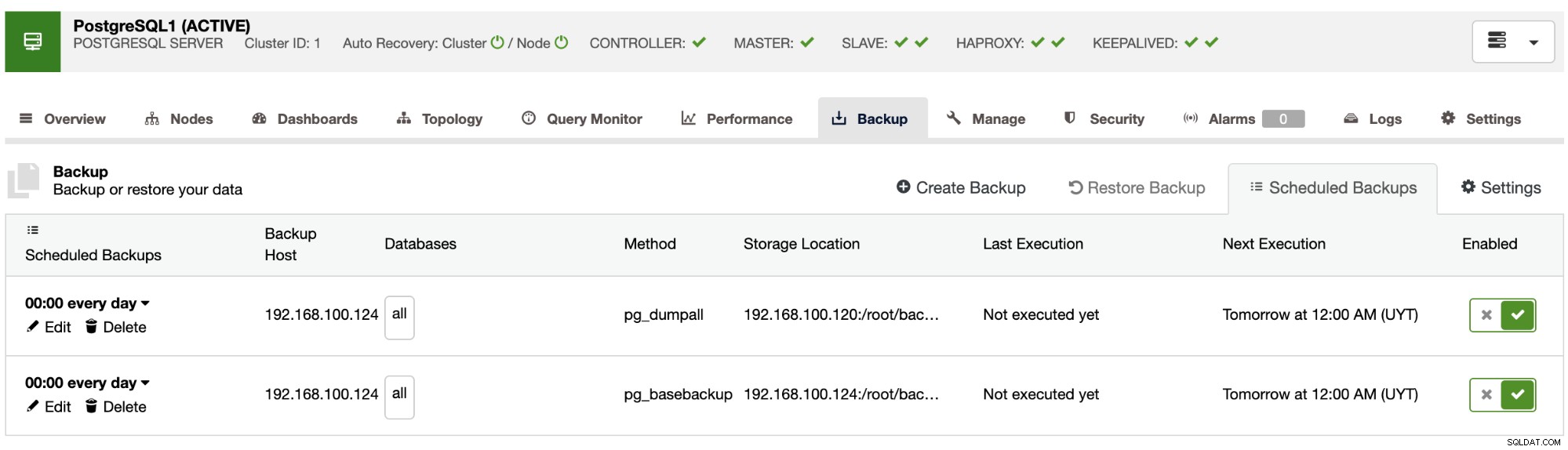
これで、ClusterControlの[スケジュールのバックアップ]セクションにスケジュールされたバックアップが表示されます。前述のベストプラクティスをカバーするために、バックアップをスケジュールして外部サーバー(ClusterControlサーバー)とクラウドに保存し、別のバックアップをスケジュールしてデータベースノードにローカルに保存してリカバリを高速化することができます。
>AmazonEC2でのバックアップの復元
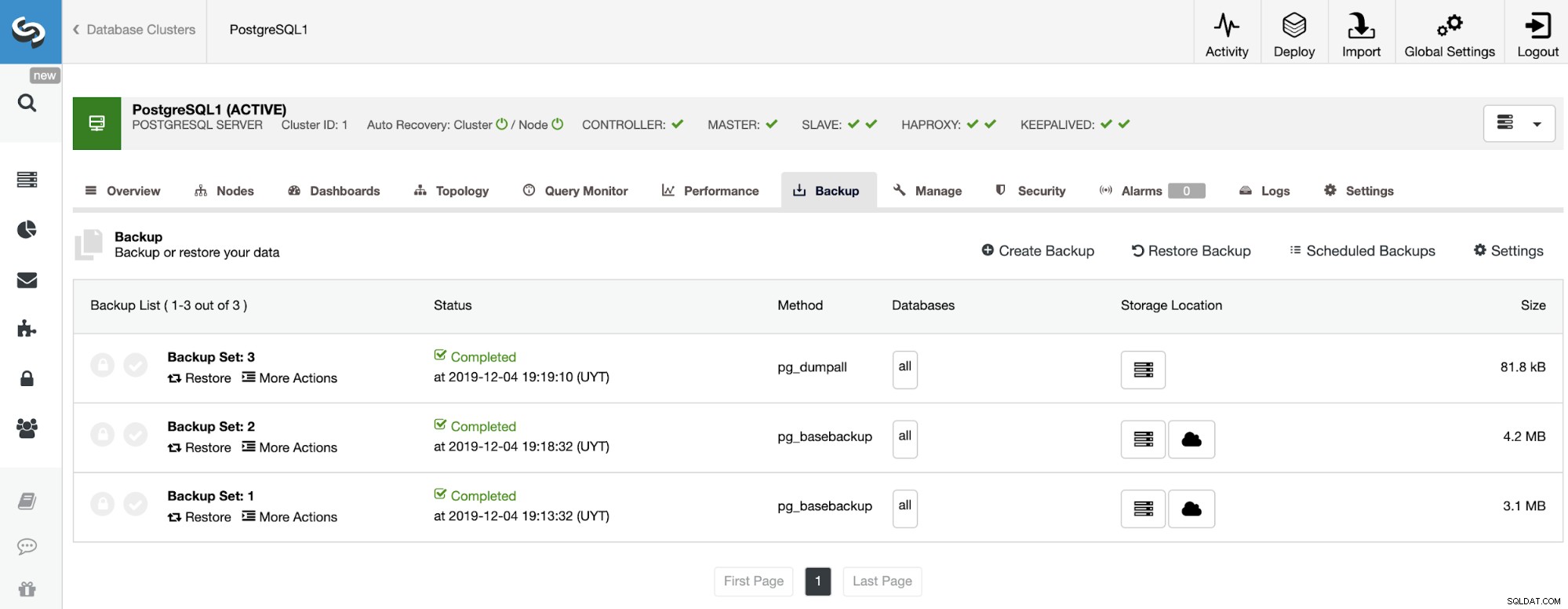
バックアップが終了したら、[バックアップ]セクションのClusterControlを使用してバックアップを復元できます。
AmazonEC2インスタンスの作成
まず、復元するにはどこかで復元する必要があるので、基本的なAmazonEC2インスタンスを作成しましょう。 EC2セクションのAWS管理コンソールの「LaunchInstance」に移動し、インスタンスを設定します。
インスタンスが作成されたら、SSH公開をコピーする必要がありますClusterControlサーバーからのキー。
ClusterControlを使用したバックアップの復元
これで新しいEC2インスタンスができたので、それを使用してバックアップを復元しましょう。このためには、ClusterControlでバックアップセクション(ClusterControl-> Select Cluster-> Backup)に移動し、そこで[Restore Backup]を選択するか、復元するバックアップで直接[Restore]を選択できます。
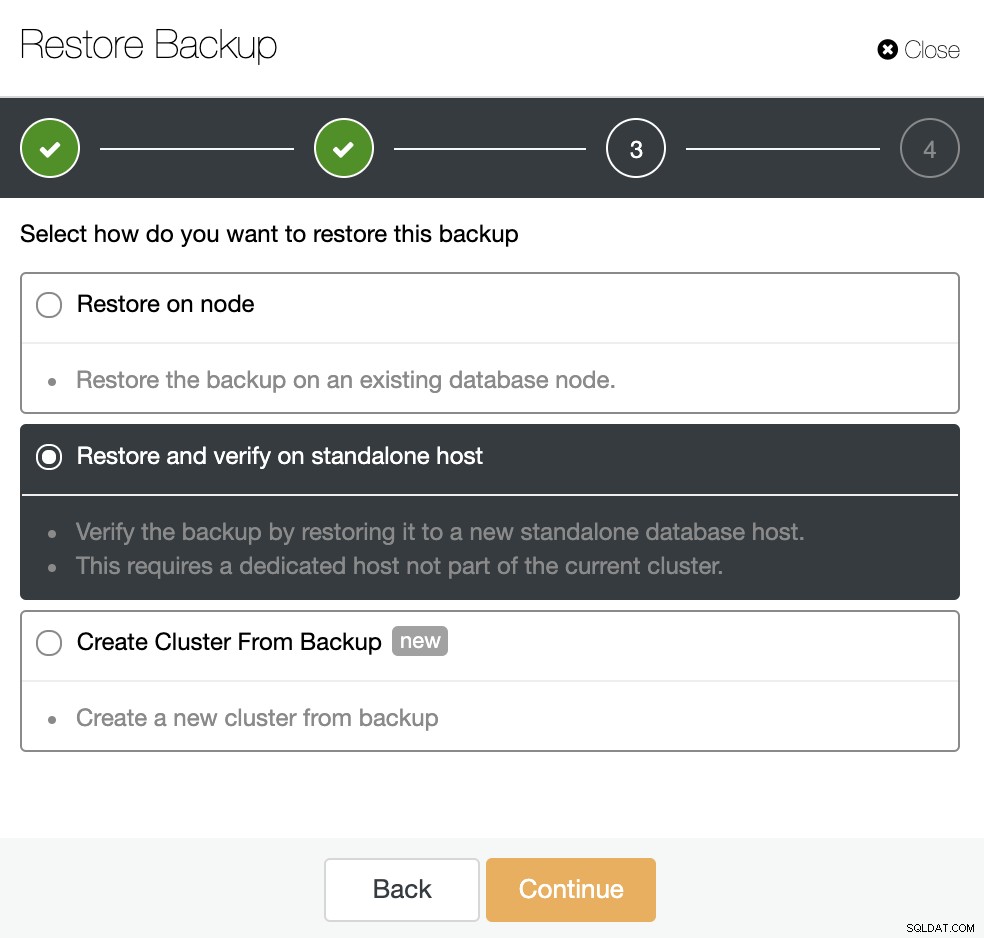
バックアップを復元するには3つのオプションがあります。既存のデータベースノードでバックアップを復元したり、スタンドアロンホストでバックアップを復元して確認したり、バックアップから新しいクラスターを作成したりできます。コールドスタンバイノードを作成する場合は、2番目のオプション「スタンドアロンホストでの復元と検証」を使用しましょう。
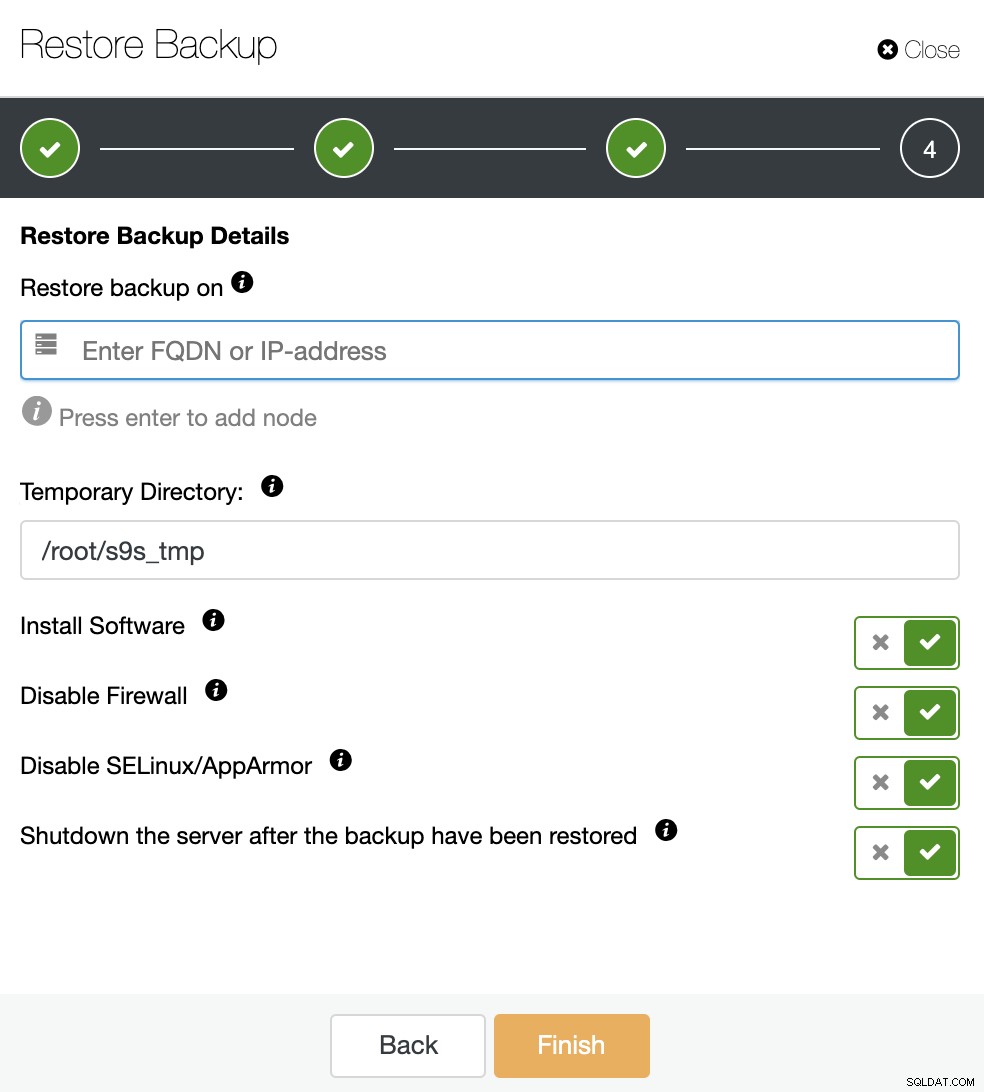
一部ではない専用ホスト(またはVM)が必要ですクラスタのバックアップを復元するため、このジョブ用に作成されたEC2インスタンスを使用してみましょう。 ClusterControlはソフトウェアをインストールし、このホストにバックアップを復元します。
「バックアップの復元後にサーバーをシャットダウンする」オプションが有効になっている場合、ClusterControlは復元ジョブの終了後にデータベースノードを停止します。これは、まさにこのコールドスタンバイの作成に必要なものです。
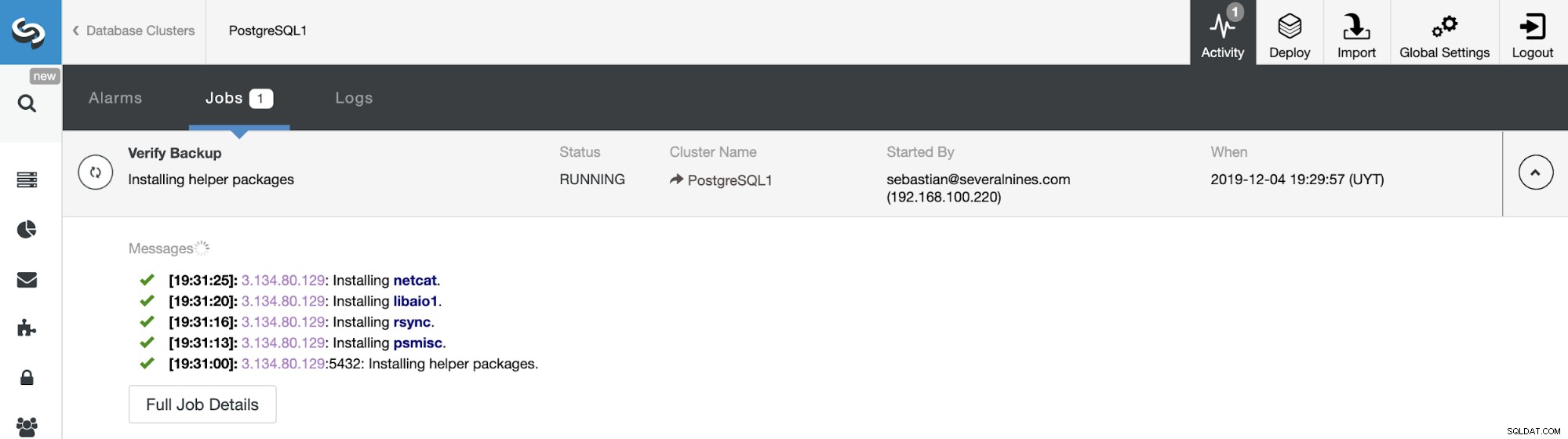
ClusterControlアクティビティセクションでバックアップの進行状況を監視できます。
>ClusterControl検証バックアップ機能の使用
復元できない場合、バックアップはバックアップではありません。したがって、バックアップが機能していることを確認し、コールドスタンバイノードで頻繁に復元する必要があります。
このClusterControl検証バックアップバックアップ機能は、コールドスタンバイノードのメンテナンスを自動化して最近のバックアップを復元し、手動の復元バックアップジョブを回避してこれを可能な限り最新の状態に保つ方法です。それがどのように機能するか見てみましょう。
「スタンドアロンホストでの復元と検証」タスクとして、バックアップを復元するにはクラスターの一部ではない専用ホスト(またはVM)が必要になるため、同じEC2インスタンスを使用しましょうここ。
自動検証バックアップ機能は、スケジュールされたバックアップで使用できます。したがって、ClusterControl-> PostgreSQL Cluster-> Backup-> Create Backupに移動し、前に見た手順を繰り返して、新しいバックアップをスケジュールします。
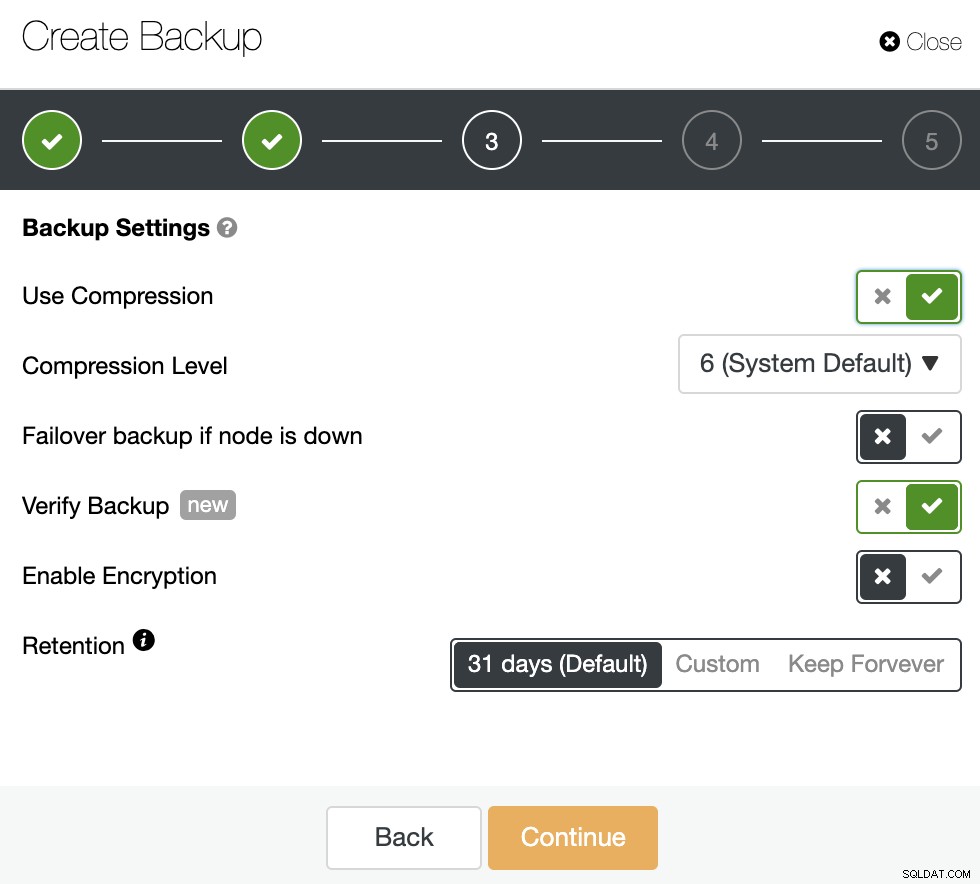
2番目のステップでは、「バックアップの確認」機能を使用できます。有効にします。
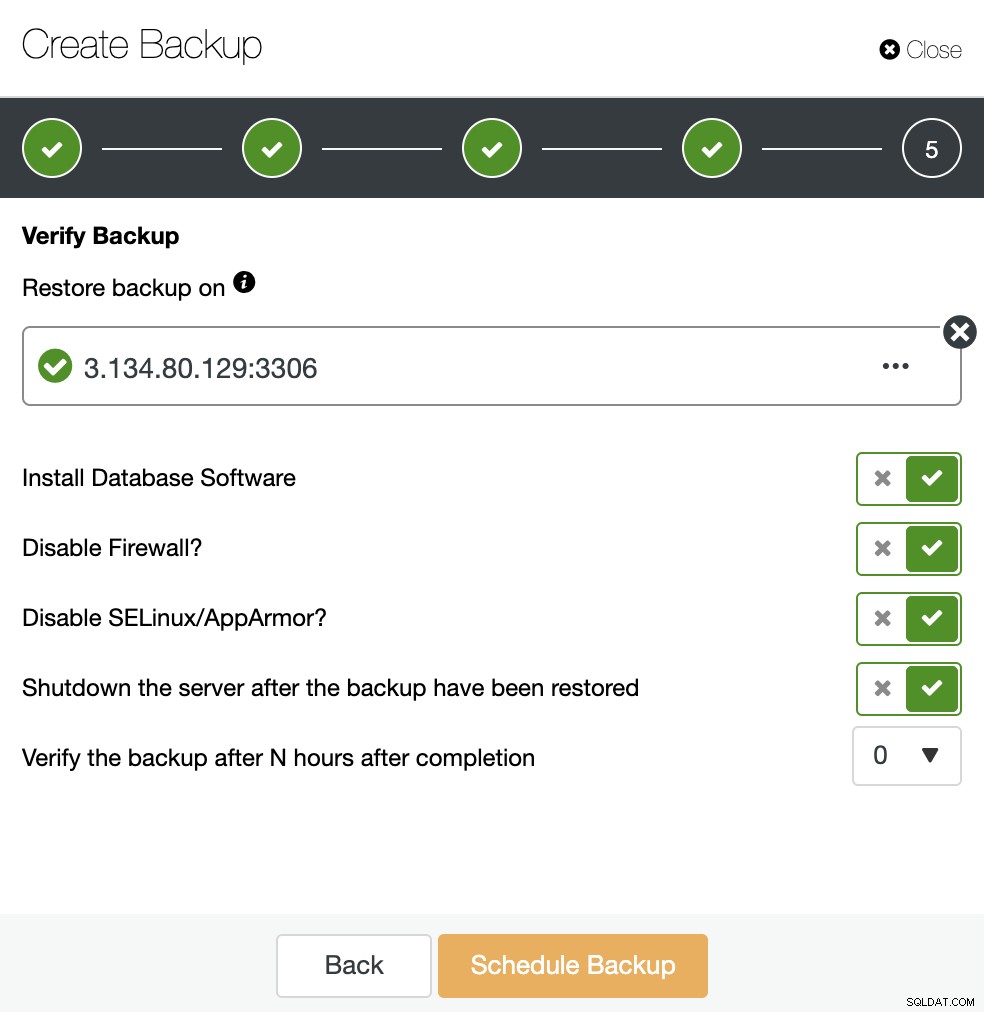
上記のオプションを使用して、ClusterControlはソフトウェアをインストールし、バックアップを復元します。ザ・ホスト。復元後、問題がなければ、ClusterControlバックアップセクションに確認アイコンが表示されます。
予算が限られているが高可用性が必要な場合は、会社のRTOとRPOに応じて有効かどうかにかかわらず、コールドスタンバイPostgreSQLノードを使用できます。このブログでは、(ビジネスポリシーに従って)バックアップをスケジュールする方法と、手動で復元する方法を紹介しました。また、ClusterControl、Amazon S3、AmazonEC2を使用してコールドスタンバイサーバーでバックアップを自動的に復元する方法も示しました。