すべての最新のデータベースシステムは、SQLクエリを実行するための最も効率的な戦略を自動的に識別するクエリオプティマイザーモジュールをサポートしています。効率的な戦略は「プラン」と呼ばれ、「クエリの実行/応答時間」に正比例するコストで測定されます。プランは、クエリオプティマイザからのツリー出力の形式で表されます。プランツリーノードは、大きく次の3つのカテゴリに分類できます。
- スキャンノード :以前のブログ「PostgreSQLのさまざまなスキャン方法の概要」で説明したように、ベーステーブルデータをフェッチする方法を示しています。
- ノードに参加 :以前のブログ「PostgreSQLのJOINメソッドの概要」で説明したように、2つのテーブルの結果を取得するには、2つのテーブルを結合する必要があることを示しています。
- マテリアライゼーションノード :補助ノードとも呼ばれます。前の2種類のノードは、ベーステーブルからデータをフェッチする方法と、2つのテーブルから取得したデータを結合する方法に関連していました。このカテゴリのノードは、レポートなどをさらに分析または準備するために、取得されたデータの上に適用されます。データの並べ替え、データの集計など。
SELECT * FROM TBL1, TBL2 where TBL1.ID > TBL2.ID order by TBL.ID;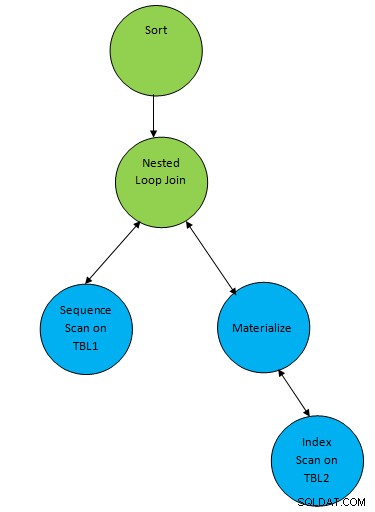
したがって、ここでは、結果の上に1つの補助ノード「Sort」が追加されます。結合して、必要な順序でデータを並べ替えます。
PostgreSQLクエリオプティマイザによって生成される補助ノードの一部は次のとおりです。
- 並べ替え
- 集計
- Group By Aggregate
- 制限
- ユニーク
- LockRows
- SetOp
名前が示すように、このノードは、並べ替えられたデータが必要な場合はいつでも、プランツリーの一部として追加されます。並べ替えられたデータは、次の2つの場合のように、明示的または暗黙的に要求される可能性があります。
ユーザーシナリオでは、出力として並べ替えられたデータが必要です。この場合、Sortノードは、他のすべての処理を含むデータ取得全体の上に置くことができます。
postgres=# CREATE TABLE demotable (num numeric, id int);
CREATE TABLE
postgres=# INSERT INTO demotable SELECT random() * 1000, generate_series(1, 10000);
INSERT 0 10000
postgres=# analyze;
ANALYZE
postgres=# explain select * from demotable order by num;
QUERY PLAN
----------------------------------------------------------------------
Sort (cost=819.39..844.39 rows=10000 width=15)
Sort Key: num
-> Seq Scan on demotable (cost=0.00..155.00 rows=10000 width=15)
(3 rows)注: ユーザーが並べ替えられた順序で最終出力を要求した場合でも、対応するテーブルと並べ替え列にインデックスがある場合、並べ替えノードが最終計画に追加されない場合があります。この場合、インデックススキャンを選択する可能性があります。これにより、データの順序が暗黙的にソートされます。たとえば、上記の例でインデックスを作成して、結果を確認してみましょう。
postgres=# CREATE INDEX demoidx ON demotable(num);
CREATE INDEX
postgres=# explain select * from demotable order by num;
QUERY PLAN
--------------------------------------------------------------------------------
Index Scan using demoidx on demotable (cost=0.29..534.28 rows=10000 width=15)
(1 row)以前のブログ「PostgreSQLのJOINメソッドの概要」で説明したように、Merge Joinでは、結合する前に両方のテーブルデータを並べ替える必要があります。そのため、並べ替えの追加コストがあっても、マージ結合が他のどの結合方法よりも安価であることが判明する場合があります。したがって、この場合、ソートされたレコードを結合メソッドに渡すことができるように、テーブルの結合メソッドとスキャンメソッドの間にソートノードが追加されます。
postgres=# create table demo1(id int, id2 int);
CREATE TABLE
postgres=# insert into demo1 values(generate_series(1,1000), generate_series(1,1000));
INSERT 0 1000
postgres=# create table demo2(id int, id2 int);
CREATE TABLE
postgres=# create index demoidx2 on demo2(id);
CREATE INDEX
postgres=# insert into demo2 values(generate_series(1,100000), generate_series(1,100000));
INSERT 0 100000
postgres=# analyze;
ANALYZE
postgres=# explain select * from demo1, demo2 where demo1.id=demo2.id;
QUERY PLAN
------------------------------------------------------------------------------------
Merge Join (cost=65.18..109.82 rows=1000 width=16)
Merge Cond: (demo2.id = demo1.id)
-> Index Scan using demoidx2 on demo2 (cost=0.29..3050.29 rows=100000 width=8)
-> Sort (cost=64.83..67.33 rows=1000 width=8)
Sort Key: demo1.id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(6 rows)複数の入力行から単一の結果を計算するために使用される集計関数がある場合、集計ノードはプランツリーの一部として追加されます。使用される集計関数には、COUNT、SUM、AVG(AVERAGE)、MAX(MAXIMUM)、およびMIN(MINIMUM)があります。
集約ノードは、基本リレーションスキャンの上に、または(および)リレーションの結合時に来ることができます。例:
postgres=# explain select count(*) from demo1;
QUERY PLAN
---------------------------------------------------------------
Aggregate (cost=17.50..17.51 rows=1 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=0)
(2 rows)
postgres=# explain select sum(demo1.id) from demo1, demo2 where demo1.id=demo2.id;
QUERY PLAN
-----------------------------------------------------------------------------------------------
Aggregate (cost=112.32..112.33 rows=1 width=8)
-> Merge Join (cost=65.18..109.82 rows=1000 width=4)
Merge Cond: (demo2.id = demo1.id)
-> Index Only Scan using demoidx2 on demo2 (cost=0.29..3050.29 rows=100000 width=4)
-> Sort (cost=64.83..67.33 rows=1000 width=4)
Sort Key: demo1.id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)HashAggregate / GroupAggregate
これらの種類のノードは、「Aggregate」ノードの拡張です。集計関数を使用してグループごとに複数の入力行を組み合わせる場合、これらの種類のノードがプランツリーに追加されます。したがって、クエリで使用されている集計関数があり、それに加えてクエリにGROUP BY句がある場合、HashAggregateノードまたはGroupAggregateノードのいずれかがプランツリーに追加されます。
PostgreSQLはCostBasedOptimizerを使用して最適なプランツリーを生成するため、これらのノードのどれが使用されるかを推測することはほとんど不可能です。しかし、いつどのように使用されるかを理解しましょう。
HashAggregate
HashAggregateは、データをグループ化するためにデータのハッシュテーブルを作成することで機能します。したがって、HashAggregateは、集約がソートされていないデータセットで発生している場合、グループレベルの集約によって使用される可能性があります。
postgres=# explain select count(*) from demo1 group by id2;
QUERY PLAN
---------------------------------------------------------------
HashAggregate (cost=20.00..30.00 rows=1000 width=12)
Group Key: id2
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)
(3 rows)ここで、demo1テーブルスキーマデータは、前のセクションで示した例のとおりです。グループ化する行は1000行しかないため、ハッシュテーブルの作成に必要なリソースは、並べ替えのコストよりも少なくなります。クエリプランナーは、HashAggregateを選択することを決定します。
GroupAggregate
GroupAggregateは並べ替えられたデータを処理するため、追加のデータ構造は必要ありません。 GroupAggregateは、集計がソートされたデータセットで行われる場合、グループレベルの集計で使用できます。並べ替えられたデータをグループ化するために、明示的に並べ替えることができます(並べ替えノードを追加することにより)。または、インデックスによってフェッチされたデータで機能する場合があります。この場合、暗黙的に並べ替えられます。
postgres=# explain select count(*) from demo2 group by id2;
QUERY PLAN
-------------------------------------------------------------------------
GroupAggregate (cost=9747.82..11497.82 rows=100000 width=12)
Group Key: id2
-> Sort (cost=9747.82..9997.82 rows=100000 width=4)
Sort Key: id2
-> Seq Scan on demo2 (cost=0.00..1443.00 rows=100000 width=4)
(5 rows) ここで、demo2テーブルスキーマデータは、前のセクションで示した例のとおりです。ここではグループ化する行が100000であるため、ハッシュテーブルの作成に必要なリソースは、並べ替えのコストよりもコストがかかる可能性があります。したがって、クエリプランナーはGroupAggregateを選択することを決定します。ここで、「demo2」テーブルから選択されたレコードが明示的にソートされており、プランツリーにノードが追加されていることを確認してください。
以下の別の例を参照してください。ここでは、インデックススキャンのために、すでにデータがソートされて取得されています。
postgres=# create index idx1 on demo1(id);
CREATE INDEX
postgres=# explain select sum(id2), id from demo1 where id=1 group by id;
QUERY PLAN
------------------------------------------------------------------------
GroupAggregate (cost=0.28..8.31 rows=1 width=12)
Group Key: id
-> Index Scan using idx1 on demo1 (cost=0.28..8.29 rows=1 width=8)
Index Cond: (id = 1)
(4 rows) 以下のもう1つの例を参照してください。これには、インデックススキャンがありますが、インデックスとグループ化列が同じではない列として明示的に並べ替える必要があります。したがって、グループ化の列に従って並べ替える必要があります。
postgres=# explain select sum(id), id2 from demo1 where id=1 group by id2;
QUERY PLAN
------------------------------------------------------------------------------
GroupAggregate (cost=8.30..8.32 rows=1 width=12)
Group Key: id2
-> Sort (cost=8.30..8.31 rows=1 width=8)
Sort Key: id2
-> Index Scan using idx1 on demo1 (cost=0.28..8.29 rows=1 width=8)
Index Cond: (id = 1)
(6 rows)注: GroupAggregate / HashAggregateは、クエリにgroup byがない場合でも、他の多くの間接クエリに使用できます。これは、プランナーがクエリをどのように解釈するかによって異なります。例えば。テーブルから個別の値を取得する必要があるとすると、対応する列からグループとして表示され、各グループから1つの値を取得できます。
postgres=# explain select distinct(id) from demo1;
QUERY PLAN
---------------------------------------------------------------
HashAggregate (cost=17.50..27.50 rows=1000 width=4)
Group Key: id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)
(3 rows)したがって、ここでは、関与する集計とグループ化がない場合でも、HashAggregateが使用されます。
SELECTクエリで「limit/offset」句が使用されている場合、制限ノードがプランツリーに追加されます。この句は、行数を制限し、オプションでデータの読み取りを開始するためのオフセットを提供するために使用されます。以下の例:
postgres=# explain select * from demo1 offset 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.15..15.00 rows=990 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)
postgres=# explain select * from demo1 limit 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.00..0.15 rows=10 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)
postgres=# explain select * from demo1 offset 5 limit 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.07..0.22 rows=10 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)このノードは、基になる結果から明確な値を取得するために選択されます。クエリ、選択性、およびその他のリソース情報に応じて、一意のノードを使用せずに、HashAggregate/GroupAggregateを使用して個別の値を取得できることに注意してください。例:
postgres=# explain select distinct(id) from demo2 where id<100;
QUERY PLAN
-----------------------------------------------------------------------------------
Unique (cost=0.29..10.27 rows=99 width=4)
-> Index Only Scan using demoidx2 on demo2 (cost=0.29..10.03 rows=99 width=4)
Index Cond: (id < 100)
(3 rows)LockRows
PostgreSQLは、選択したすべての行をロックする機能を提供します。行は、それぞれ「FORSHARE」および「FORUPDATE」句に応じて、「共有」モードまたは「排他的」モードで選択できます。この操作を実行するために、新しいノード「LockRows」がプランツリーに追加されます。
postgres=# explain select * from demo1 for update;
QUERY PLAN
----------------------------------------------------------------
LockRows (cost=0.00..25.00 rows=1000 width=14)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=14)
(2 rows)
postgres=# explain select * from demo1 for share;
QUERY PLAN
----------------------------------------------------------------
LockRows (cost=0.00..25.00 rows=1000 width=14)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=14)
(2 rows)SetOp
PostgreSQLは、2つ以上のクエリの結果を組み合わせる機能を提供します。したがって、2つのテーブルを結合するためにJoinノードのタイプが選択されると、2つ以上のクエリの結果を組み合わせるために同様のタイプのSetOpノードが選択されます。たとえば、次のように、ID、名前、年齢、給与が記載された従業員の表を考えてみます。
postgres=# create table emp(id int, name char(20), age int, salary int);
CREATE TABLE
postgres=# insert into emp values(1,'a', 30,100);
INSERT 0 1
postgres=# insert into emp values(2,'b', 31,90);
INSERT 0 1
postgres=# insert into emp values(3,'c', 40,105);
INSERT 0 1
postgres=# insert into emp values(4,'d', 20,80);
INSERT 0 1 では、25歳以上の従業員を獲得しましょう:
postgres=# select * from emp where age > 25;
id | name | age | salary
----+----------------------+-----+--------
1 | a | 30 | 100
2 | b | 31 | 90
3 | c | 40 | 105
(3 rows) では、9,500万人以上の給与を持つ従業員を獲得しましょう:
postgres=# select * from emp where salary > 95;
id | name | age | salary
----+----------------------+-----+--------
1 | a | 30 | 100
3 | c | 40 | 105
(2 rows)25歳以上、給与が9,500万人以上の従業員を獲得するために、以下の交差クエリを記述できます。
postgres=# explain select * from emp where age>25 intersect select * from emp where salary > 95;
QUERY PLAN
---------------------------------------------------------------------------------
HashSetOp Intersect (cost=0.00..72.90 rows=185 width=40)
-> Append (cost=0.00..64.44 rows=846 width=40)
-> Subquery Scan on "*SELECT* 1" (cost=0.00..30.11 rows=423 width=40)
-> Seq Scan on emp (cost=0.00..25.88 rows=423 width=36)
Filter: (age > 25)
-> Subquery Scan on "*SELECT* 2" (cost=0.00..30.11 rows=423 width=40)
-> Seq Scan on emp emp_1 (cost=0.00..25.88 rows=423 width=36)
Filter: (salary > 95)
(8 rows) ここでは、これら2つの個別のクエリの交差を評価するために、新しい種類のノードHashSetOpが追加されています。
このノードは、複数の結果セットを1つに結合するために追加されます。
このノードは、サブクエリを評価するために追加されます。上記の計画では、サブクエリを追加して、特定の行に貢献した入力セットを示す1つの追加の定数列値を評価します。
HashedSetopは、基になる結果のハッシュを使用して機能しますが、クエリオプティマイザーによってソートベースのSetOp操作を生成することができます。ソートベースのSetopノードは「Setop」として示されます。
注:1回のクエリで上記の結果と同じ結果を得ることができますが、ここでは簡単なデモンストレーションのために交差を使用して示しています。
PostgreSQLのすべてのノードは便利であり、クエリやデータなどの性質に基づいて選択されます。句の多くは、ノードと1対1でマッピングされます。一部の条項には、ノードに複数のオプションがあり、基礎となるデータコストの計算に基づいて決定されます。