PostgreSQLストリーミングレプリケーションは、PostgreSQLクラスターをスケーリングし、それを実行することで高可用性を追加するための優れた方法です。すべてのレプリケーションと同様に、スレーブはマスターのコピーであり、スレーブは、ある種のレプリケーションメカニズムを使用してマスターで発生した変更で常に更新されるという考え方です。
何らかの理由で、スレーブがマスターと同期しなくなる場合があります。どうすればレプリケーションチェーンに戻すことができますか?スレーブが再びマスターと同期していることを確認するにはどうすればよいですか?この短いブログ投稿を見てみましょう。
非常に役立つのは、スレーブがリカバリモードの場合、スレーブに書き込む方法がないことです。次のようにテストできます:
postgres=# SELECT pg_is_in_recovery();
pg_is_in_recovery
-------------------
t
(1 row)
postgres=# CREATE DATABASE mydb;
ERROR: cannot execute CREATE DATABASE in a read-only transactionpg_basebackupを使用したスレーブの再構築
主な手順は、マスターからのデータを使用してスレーブをプロビジョニングすることです。ストリーミングレプリケーションを使用することを考えると、論理バックアップを使用することはできません。幸いなことに、設定に使用できる準備が整ったツールpg_basebackupがあります。スレーブサーバーをプロビジョニングするために必要な手順を見てみましょう。明確にするために、このブログ投稿ではPostgreSQL12を使用しています。
example@sqldat.com:~# systemctl stop postgresqlまたは:
example@sqldat.com:~# killall -9 postgresでは、postgresql.auto.confファイルの内容を確認しましょう。後で、そのファイルに保存されているレプリケーションクレデンシャルをpg_basebackupに使用できます。
example@sqldat.com:~# cat /var/lib/postgresql/12/main/postgresql.auto.conf
# Do not edit this file manually!
# It will be overwritten by the ALTER SYSTEM command.
promote_trigger_file='/tmp/failover_5432.trigger'
recovery_target_timeline=latest
primary_conninfo='application_name=pgsql_0_node_1 host=10.0.0.126 port=5432 user=cmon_replication password=qZnVoV7LV97CFX9F'最後に、データを削除してもかまいません:
example@sqldat.com:~# rm -rf /var/lib/postgresql/12/main/*データが削除されたら、pg_basebackupを使用してマスターからデータを取得する必要があります:
example@sqldat.com:~# pg_basebackup -h 10.0.0.126 -U cmon_replication -Xs -P -R -D /var/lib/postgresql/12/main/
Password:
waiting for checkpoint- -Xs:バックアップの作成中にWALをストリーミングしたいと思います。これにより、データセットが大きい場合にWALファイルを削除する際の問題を回避できます。
- -P:バックアップの進捗状況を確認したい。
- -R:pg_basebackupでstandby.signalファイルを作成し、接続設定を使用してpostgresql.auto.confファイルを準備します。
pg_basebackupは、バックアップを開始する前にチェックポイントを待機します。時間がかかりすぎる場合は、2つのオプションを使用できます。まず、「-c fast」オプションを使用して、pg_basebackupでチェックポイントモードをfastに設定できます。または、次を実行してチェックポイントを強制することもできます:
postgres=# CHECKPOINT;
CHECKPOINTいずれかの方法で、pg_basebackupが開始されます。 -Pフラグを使用すると、進行状況を追跡できます:
416906/1588478 kB (26%), 0/1 tablespaceceaceバックアップの準備ができたら、データディレクトリのコンテンツに正しいユーザーとグループが割り当てられていることを確認するだけです。pg_basebackupを「root」として実行したため、「postgres」に変更します。 ':
example@sqldat.com:~# chown -R postgres.postgres /var/lib/postgresql/12/main/これで、スレーブを起動でき、マスターからの複製を開始する必要があります。
example@sqldat.com:~# systemctl start postgresqlマスターで次のクエリを実行することにより、レプリケーションの進行状況を再確認できます。
postgres=# SELECT * FROM pg_stat_replication;
pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | backend_xmin | state | sent_lsn | write_lsn | flush_lsn | replay_lsn | write_lag | flush_lag | replay_lag | sync_priority | sync_state | reply_time
-------+----------+------------------+------------------+-------------+-----------------+-------------+-------------------------------+--------------+-----------+------------+------------+------------+------------+-----------+-----------+------------+---------------+------------+-------------------------------
23565 | 16385 | cmon_replication | pgsql_0_node_1 | 10.0.0.128 | | 51554 | 2020-02-27 15:25:00.002734+00 | | streaming | 2/AA5EF370 | 2/AA5EF2B0 | 2/AA5EF2B0 | 2/AA5EF2B0 | | | | 0 | async | 2020-02-28 13:45:32.594213+00
11914 | 16385 | cmon_replication | 12/main | 10.0.0.127 | | 25058 | 2020-02-28 13:42:09.160576+00 | | streaming | 2/AA5EF370 | 2/AA5EF2B0 | 2/AA5EF2B0 | 2/AA5EF2B0 | | | | 0 | async | 2020-02-28 13:45:42.41722+00
(2 rows)ご覧のとおり、両方のスレーブが正しく複製されています。
ClusterControlを使用したスレーブの再構築
ClusterControlユーザーの場合、UIからオプションを選択するだけで、まったく同じことを簡単に実現できます。
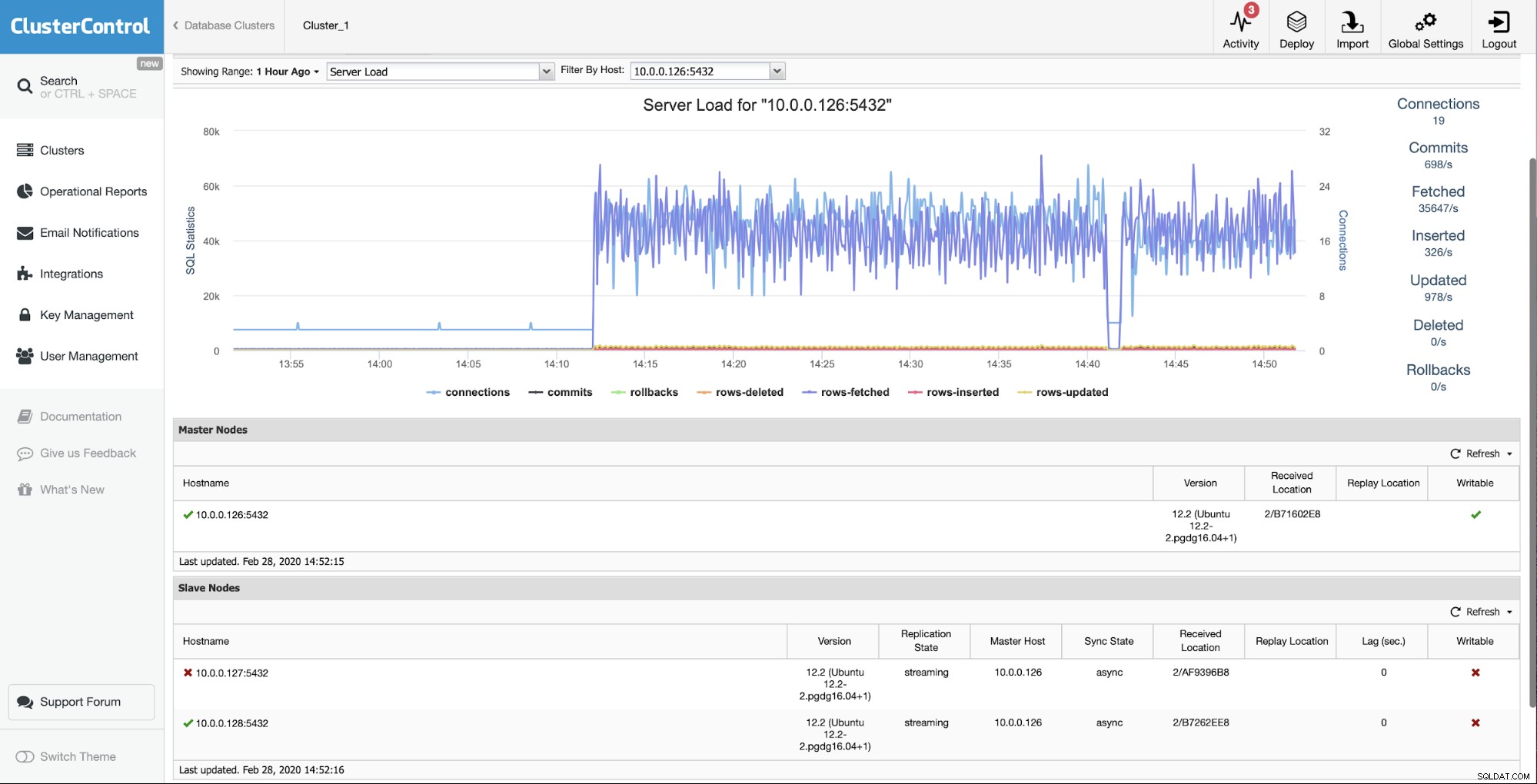
最初の状況は、スレーブの1つ(10.0.0.127)が動作せず、複製されていません。再構築が私たちにとって最良の選択肢であると考えました。
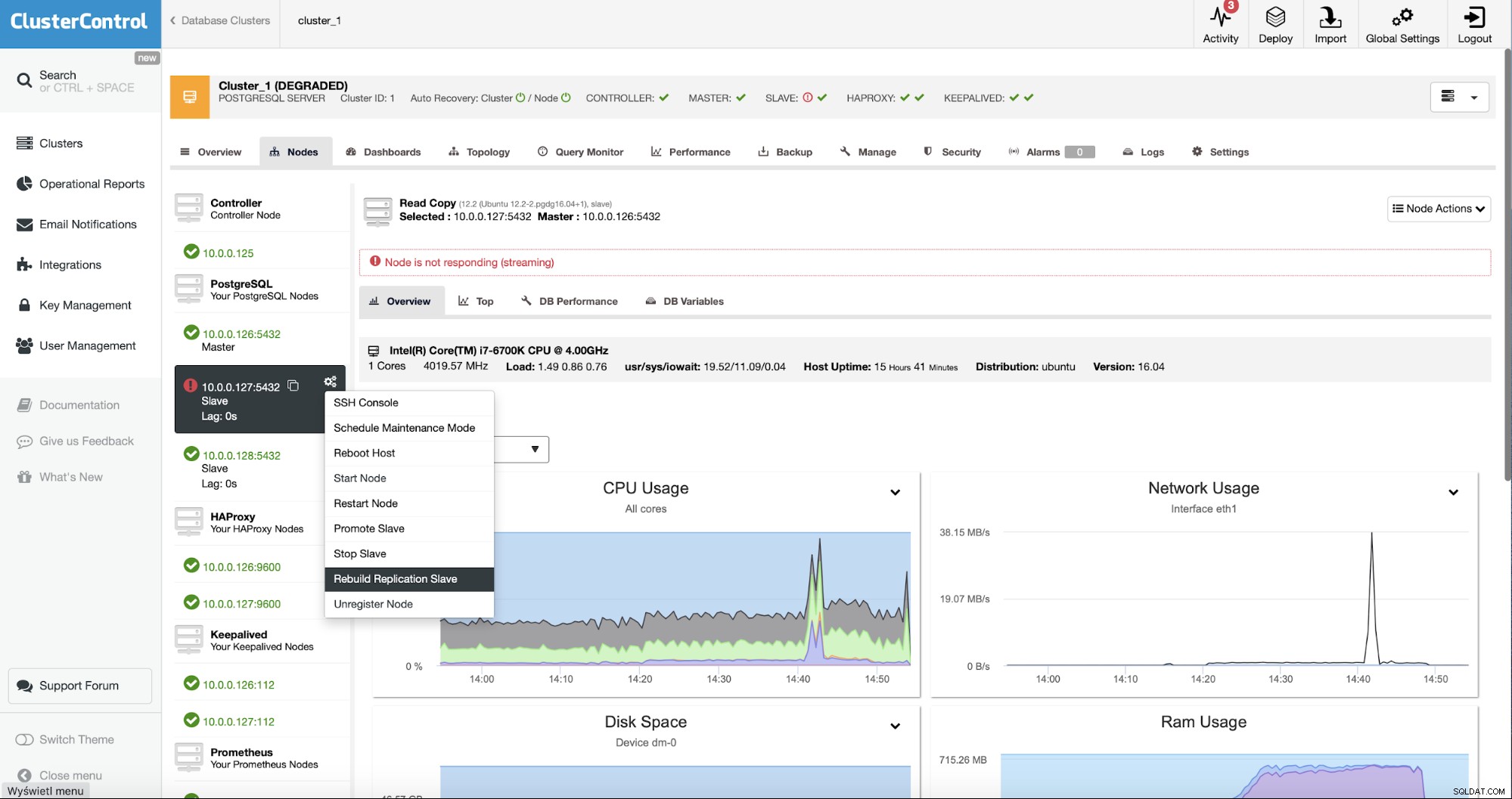
ClusterControlユーザーとして、私たちがしなければならないのは「ノード」に移動することだけです。 」タブをクリックし、「レプリケーションスレーブの再構築」ジョブを実行します。
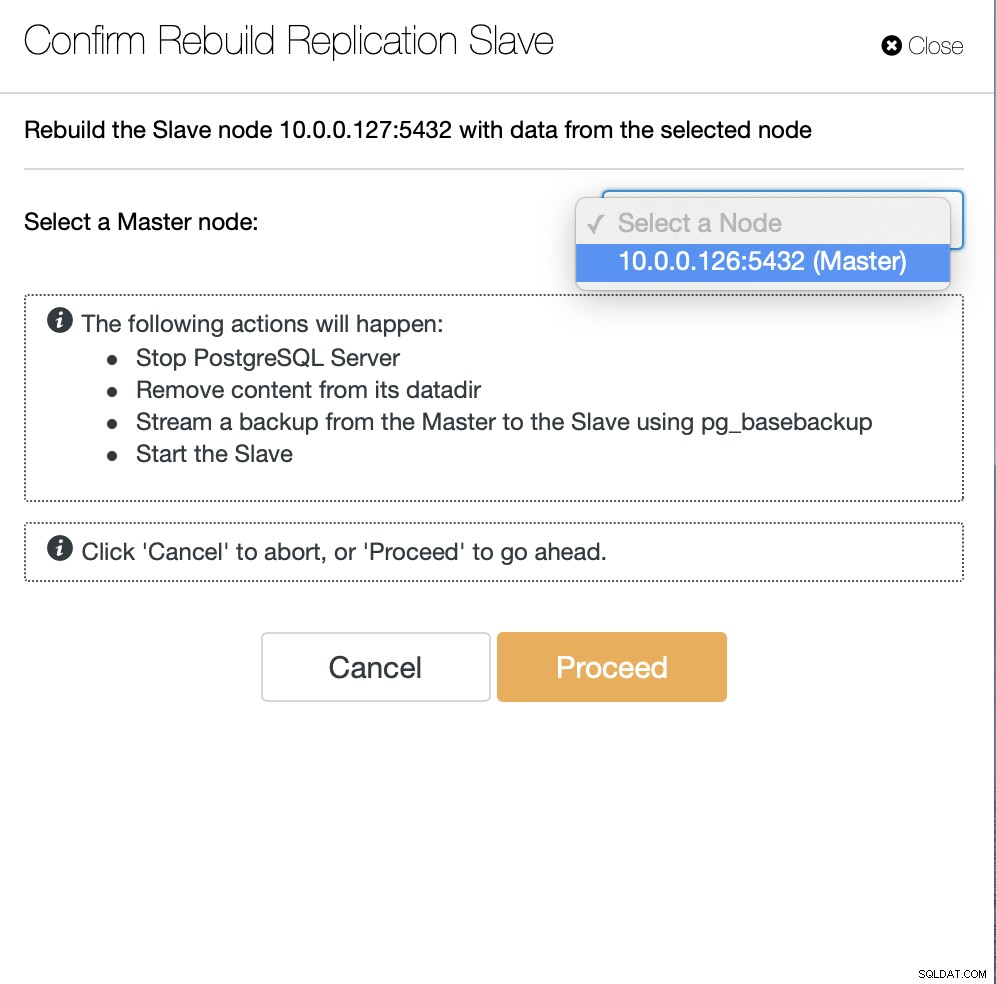
次に、スレーブを再構築するノードを選択する必要があります。すべて。 ClusterControlは、pg_basebackupを使用してレプリケーションスレーブをセットアップし、データが転送されるとすぐにレプリケーションを構成します。
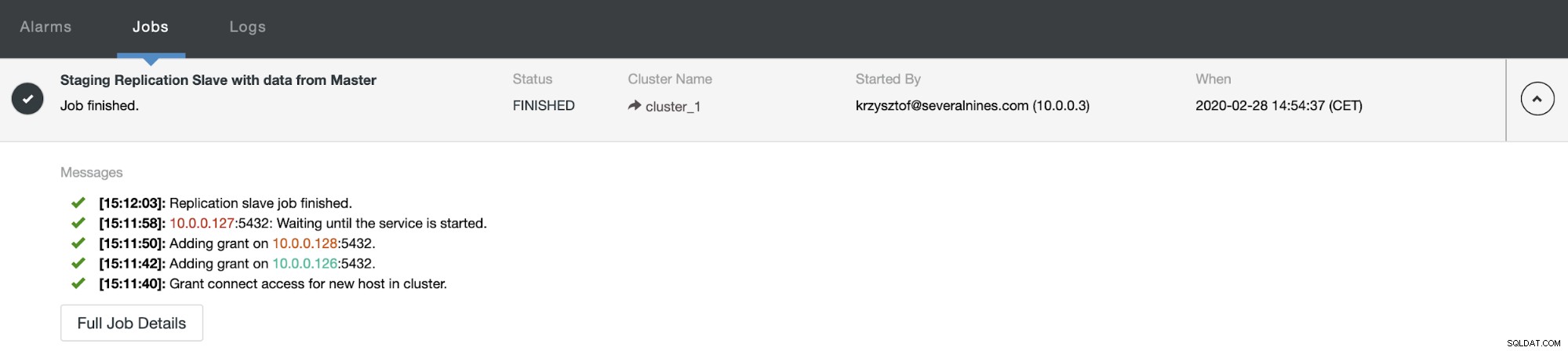
しばらくすると、ジョブが完了し、スレーブがレプリケーションチェーンに戻ります。
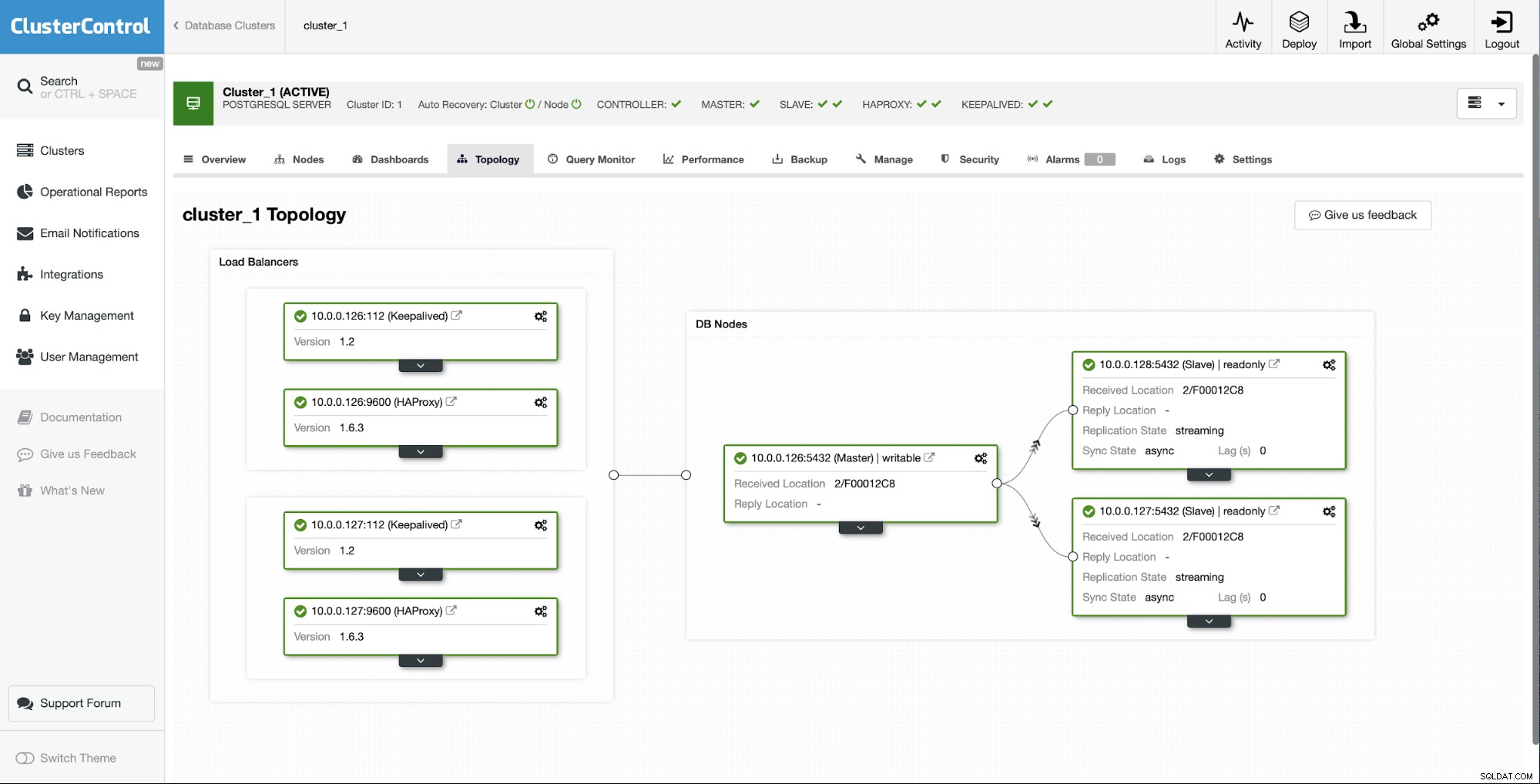
ご覧のとおり、ClusterControlのおかげで、数回クリックするだけで、失敗したスレーブを再構築し、クラスターに戻すことができました。