メモリからの読み取りは、ディスクに移動するよりも常にパフォーマンスが高いため、すべてのデータベーステクノロジで、できるだけ多くのメモリを使用する必要があります。構成がわからない場合、またはエラーが発生した場合は、メモリ使用率が高くなるか、メモリ不足の問題が発生する可能性があります。
このブログでは、PostgreSQLのメモリ使用率を確認する方法と、それを調整するために考慮する必要のあるパラメータについて説明します。このために、PostgreSQLのアーキテクチャの概要を確認することから始めましょう。
PostgreSQLアーキテクチャ
PostgreSQLのアーキテクチャは、プロセス、メモリ、ディスクの3つの基本的な部分に基づいています。
- ローカルメモリ :クエリ処理に使用するために、各バックエンドプロセスによってロードされます。サブエリアに分かれています:
- work mem:work memは、ORDER BYおよびDISTINCT操作によるタプルの並べ替え、およびテーブルの結合に使用されます。
- メンテナンス作業メンバー:一部の種類のメンテナンス操作では、この領域が使用されます。たとえば、autovacuum_work_memを指定していない場合は、VACUUMです。
- 一時バッファ:一時テーブルの保存に使用されます。
- 共有メモリ :起動時にPostgreSQLサーバーによって割り当てられ、すべてのプロセスで使用されます。サブエリアに分かれています:
- 共有バッファプール:PostgreSQLがディスクからテーブルとインデックスを含むページをロードし、メモリから直接作業して、ディスクアクセスを削減します。
- WALバッファー:WALデータはPostgreSQLのトランザクションログであり、データベースの変更が含まれています。 WALバッファは、WALデータをディスクに書き込んでからWALファイルに書き込む前に一時的に保存される領域です。これは、チェックポイントと呼ばれる事前定義された時間ごとに実行されます。これは、サーバーに障害が発生した場合に情報が失われないようにするために非常に重要です。
- コミットログ:同時実行制御のためにすべてのトランザクションのステータスを保存します。
メモリ使用率が高い場合は、最初に、どのプロセスが消費を生成しているかを確認する必要があります。
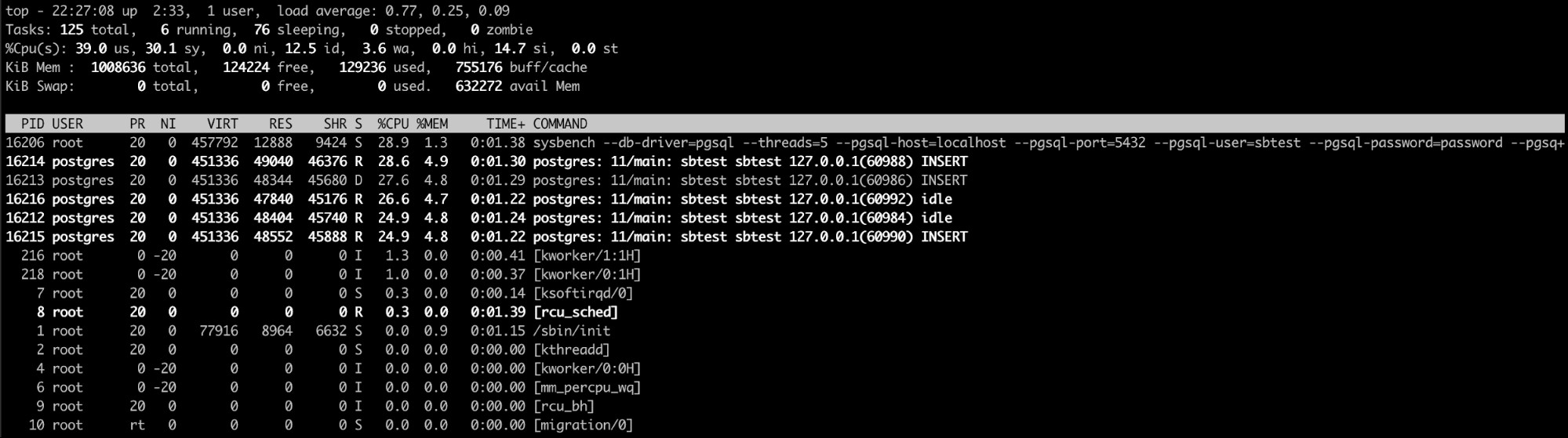
ここでは、最上位のLinuxコマンドがおそらく最良のオプションです(または同様のものですら)。 htopのようなもの)。このコマンドを使用すると、メモリを大量に消費している1つまたは複数のプロセスを確認できます。
PostgreSQLがこの問題の原因であることを確認したら、次のステップは理由を確認することです。
PostgreSQLログの使用
PostgreSQLとシステムの両方のログを確認することは、データベース/システムで何が起こっているかについてより多くの情報を得るのに間違いなく良い方法です。次のようなメッセージが表示される可能性があります:
Resource temporarily unavailable
Out of memory: Kill process 1161 (postgres) score 366 or sacrifice childまたは、次のような複数のデータベースメッセージエラーもあります:
FATAL: password authentication failed for user "username"
ERROR: duplicate key value violates unique constraint "sbtest21_pkey"
ERROR: deadlock detectedPg_topの使用
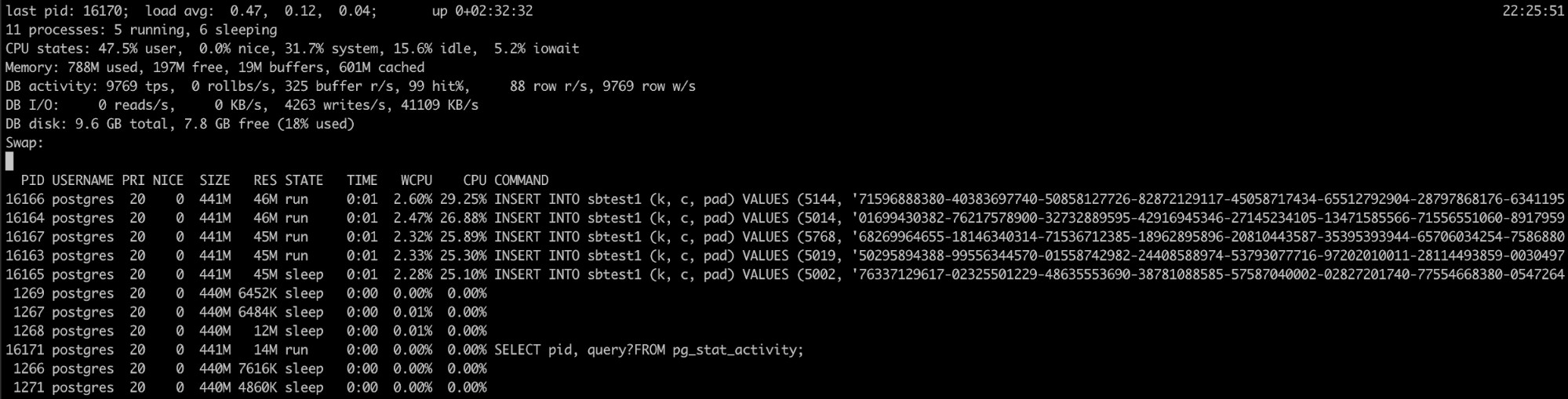
PostgreSQLプロセスのメモリ使用率が高いことがわかっているが、ログは役に立ちませんでした。ここで役立つ別のツール、pg_topがあります。
このツールはトップのLinuxツールに似ていますが、特にPostgreSQL用です。したがって、これを使用すると、データベースを実行しているものに関するより詳細な情報が得られ、クエリを強制終了したり、何か問題を検出した場合に説明ジョブを実行したりすることもできます。このツールの詳細については、こちらをご覧ください。
ただし、エラーを検出できず、データベースがまだ大量のRAMを使用している場合はどうなりますか。したがって、おそらくデータベース構成を確認する必要があります。
すべてが正常に見えるが、それでも高使用率の問題がある場合は、構成をチェックして、それが正しいかどうかを確認する必要があります。したがって、この場合に考慮すべきパラメータは次のとおりです。
shared_buffers
これは、データベースサーバーが共有メモリバッファに使用するメモリの量です。この値が低すぎると、データベースはより多くのディスクを使用するため、速度が低下しますが、高すぎると、メモリ使用率が高くなる可能性があります。ドキュメントによると、1 GB以上のRAMを搭載した専用データベースサーバーがある場合、shared_buffersの適切な開始値はシステムのメモリの25%です。
work_mem
これは、ディスク上の一時ファイルに書き込む前に、ORDER BY、DISTINCT、およびJOINによって使用されるメモリの量を指定します。 shared_buffersと同様に、このパラメーターの構成が低すぎると、ディスクに入る操作が増える可能性がありますが、高すぎると、メモリー使用量にとって危険です。デフォルト値は4MBです。
max_connections
Work_memは、max_connections値とも密接に関連しています。これは、各接続がこれらの操作を同時に実行し、各操作がその前にこの値で指定された量のメモリを使用できるようにするためです。一時ファイルへのデータの書き込みを開始します。このパラメーターは、データベースへの同時接続の最大数を決定します。多数の接続を構成し、これを考慮しない場合、リソースの問題が発生し始める可能性があります。デフォルト値は100です。
temp_buffers
一時バッファは、各セッションで使用される一時テーブルを格納するために使用されます。このパラメーターは、このタスクの最大メモリー量を設定します。デフォルト値は8MBです。
maintenance_work_mem
これは、バキューム、インデックスの追加、外部キーなどの操作で消費できる最大メモリです。良い点は、このタイプの1つの操作のみをセッションで実行できることであり、システムでこれらの複数を同時に実行することは最も一般的なことではありません。デフォルト値は64MBです。
autovacuum_work_mem
バキュームはデフォルトでmaintenance_work_memを使用しますが、このパラメーターを使用して分離できます。ここで、各自動真空ワーカーが使用するメモリの最大量を指定できます。
wal_buffers
メモリ使用率が高い理由はさまざまであり、根本的な問題の検出は時間のかかる作業になる可能性があります。このブログでは、PostgreSQLのメモリ使用率を確認するさまざまな方法と、過度のメモリ使用量を回避するためにどのパラメータを考慮して調整する必要があるかについて説明しました。