独自のスケジューラが組み込まれている他のデータベース管理システム(Oracle、MSSQL、MySQLなど)とは異なり、PostgreSQLにはまだこの種の機能がありません。
PostgreSQLでスケジューリング機能を提供するには、...
のような外部ツールを使用する必要があります。- Linux crontab
このブログでは、これらのツールについて説明し、それらの操作方法とその主な機能に焦点を当てます。
Linux crontab
これは最も古いものですが、スケジューリングタスクを実行するための効率的で便利な方法です。このプログラムはデーモン(cron)に基づいており、タスクをバックグラウンドで定期的に自動的に実行し、実行するスクリプト/コマンドとそのスケジューリングが定義されている構成ファイル(crontabファイルと呼ばれる)を定期的に検証します。
>各ユーザーは独自のcrontabファイルを持つことができ、最新のUbuntuリリースについては次の場所にあります:
/var/spool/cron/crontabs (for other linux distributions the location could be different):
example@sqldat.com:/var/spool/cron/crontabs# ls -ltr
total 12
-rw------- 1 dbmaster crontab 1128 Jan 12 12:18 dbmaster
-rw------- 1 slonik crontab 1126 Jan 12 12:22 slonik
-rw------- 1 nines crontab 1125 Jan 12 12:23 ninesmm hh dd mm day <<command or script to execute>>
mm: Minute(0-59)
hh: Hour(0-23)
dd: Day(1-31)
mm: Month(1-12)
day: Day of the week(0-7 [7 or 0 == Sunday])この構文でいくつかの演算子を使用して、スケジューリング定義を合理化できます。これらの記号を使用すると、フィールドに複数の値を指定できます。
アスタリスク(*)-フィールドに可能なすべての値を意味します
コンマ(、)-値のリストを定義するために使用されます
ダッシュ(-)-値の範囲を定義するために使用されます
セパレータ(/)-ステップ値を指定します
スクリプトall_db_backup.shは、各スケジューリング式に従って実行されます。
| 0 6 * * * /home/backup/all_db_backup.sh | |
| 20 22 * *月、火、水、木、金/home/backup/all_db_backup.sh | |
| 0 23 * * 1-5 /home/backup/all_db_backup.sh | |
| 0 0/5 14 * * /home/backup/all_db_backup.sh | 午後2時から5時間ごと毎日午後2時55分に終了します |
example@sqldat.com:~$ crontab -eexample@sqldat.com:~$ crontab -lこのファイルを削除する必要がある場合、適切なパラメータは-r:
example@sqldat.com:~$ crontab -rcronデーモンのステータスは、次のコマンドの実行によって表示されます。
pgAgentは、PostgreSQLで使用可能なジョブスケジューリングエージェントであり、ストアドプロシージャ、SQLステートメント、およびシェルスクリプトの実行を可能にします。その構成は、クラスター内のpostgresデータベースに保存されます。
このエージェントをLinuxシステムでデーモンとして実行し、定期的にデータベースに接続して、実行するジョブがあるかどうかを確認することが目的です。
このスケジュールはPgAdmin4で簡単に管理できますが、pgAdminをインストールするとデフォルトではインストールされないため、自分でダウンロードしてインストールする必要があります。
以下では、pgAgentを正しく機能させるために必要なすべての手順について説明します。
ステップ1
pgAdmin4のインストール
$ sudo apt install pgadmin4 pgadmin4-apacheステップ2
定義されていない場合のplpgsql手続き型言語の作成
CREATE TRUSTED PROCEDURAL LANGUAGE ‘plpgsql’
HANDLER plpgsql_call_handler
HANDLER plpgsql_validator;ステップ3
pgAgentのインストール
$ sudo apt-get install pgagentステップ4
pgagent拡張機能の作成
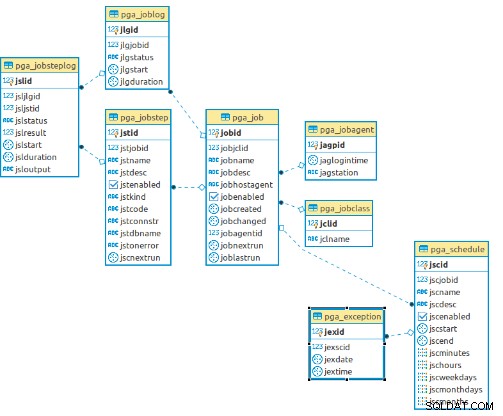
CREATE EXTENSION pageant この拡張機能は、pgAgent操作のすべてのテーブルと関数を作成します。以降、この拡張機能で使用されるデータモデルを示します。
これで、pgAdminインターフェイスにはすでにオプション「pgAgentJobs」があります。 pgAgentを管理する:

新しいジョブを定義するには、[作成]を選択するだけです。 「pgAgentジョブ」の右ボタンを使用すると、このジョブの指定が挿入され、実行する手順が定義されます。
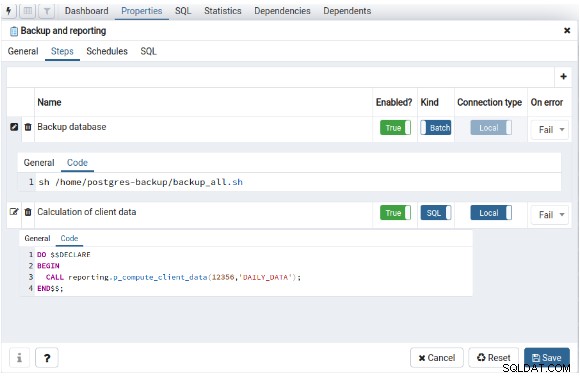
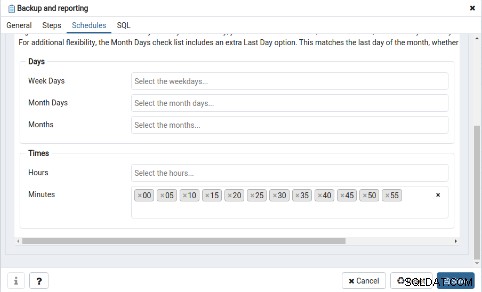
[スケジュール]タブで、この新しいジョブのスケジュールを定義する必要があります:
最後に、エージェントをバックグラウンドで実行するには、次のプロセスを手動で:
/usr/bin/pgagent host=localhost dbname=postgres user=postgres port=5432 -l 1それでも、このエージェントに最適なオプションは、前のコマンドでデーモンを作成することです。
pg_cronは、拡張機能としてデータベース内で実行されるPostgreSQL用のcronベースのジョブスケジューラであり(OracleのDBMS_SCHEDULERと同様)、データベースから直接データベースタスクを実行できます。バックグラウンドワーカー。
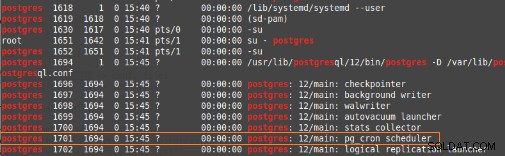
実行するタスクは、次のいずれかになります。
>- SQLステートメント
- PostgreSQLコマンド(VACUUMまたはVACUUM ANALYZEとして)
pg_cronは複数のジョブを並行して実行できますが、一度に実行できるのはプログラムの1つのインスタンスのみです。
最初の実行が終了する前に2番目の実行を開始する必要がある場合は、キューに入れられ、最初の実行が完了するとすぐに開始されます。
この拡張機能は、バージョン9.5以降のPostgreSQL用に定義されています。
pg_cronのインストール
この拡張機能のインストールには、次のコマンドのみが必要です。
example@sqldat.com:~$ sudo apt-get -y install postgresql-10-cronPostgreSQLサーバーの起動後にpg_cronバックグラウンドワーカーを起動するには、postgresql.confでpg_cronをshared_preload_librariesパラメーターに設定する必要があります。
shared_preload_libraries = ‘pg_cron’このファイルでは、次のパラメータを追加して、pg_cron拡張子が作成されるデータベースを定義する必要もあります。
cron.database_name= ‘postgres’一方、認証を管理するpg_hba.confファイルでは、postgresログインをIPV4接続の信頼として定義する必要があります。これは、pg_cronではそのようなユーザーがデータベースに接続できる必要があるためです。パスワードを指定しないため、このファイルに次の行を追加する必要があります。
host postgres postgres 192.168.100.53/32 trusttrust認証方式を使用すると、誰でもpg_hba.confファイルで指定されたデータベース(この場合はpostgresデータベース)に接続できます。これは、シングルユーザーマシンでUnixドメインソケットを使用してデータベースにアクセスできるようにするためによく使用される方法であり、サーバーへの接続に適切なオペレーティングシステムレベルの保護がある場合にのみ使用する必要があります。
どちらの変更でも、PostgreSQLサービスを再起動する必要があります:
example@sqldat.com:~$ sudo system restart postgresql.serviceサーバーがホットスタンバイモードである限り、pg_cronはジョブを実行しませんが、サーバーが昇格すると自動的に起動することを考慮することが重要です。
pg_cron拡張子の作成
この拡張機能は、メタデータとそれを管理するためのプロシージャを作成するため、psqlで次のコマンドを実行する必要があります。
postgres=#CREATE EXTENSION pg_cron;
CREATE EXTENSION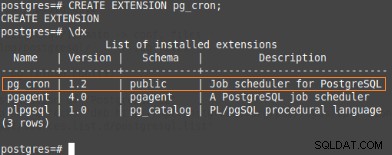
これで、ジョブをスケジュールするために必要なオブジェクトは、cronスキーマですでに定義されています。 :
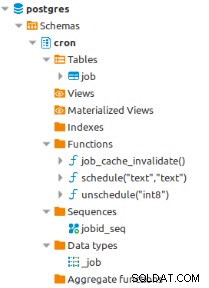
この拡張機能は非常にシンプルで、すべてを管理するにはジョブテーブルだけで十分です。この機能:
pg_cronでジョブを定義するためのスケジューリング構文は、cronツールで使用されるものと同じであり、新しいジョブの定義は非常に単純です。関数cron.scheduleを呼び出すだけで済みます:
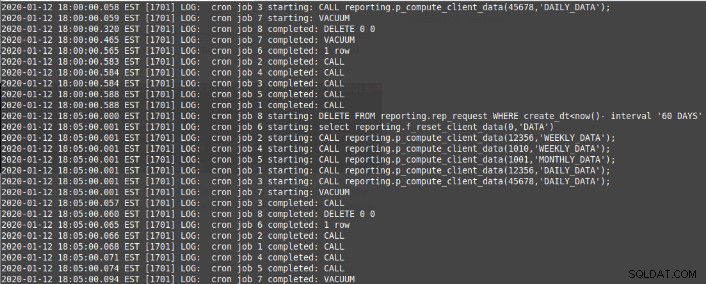
>select cron.schedule('*/5 * * * *','CALL reporting.p_compute_client_data(12356,''DAILY_DATA'');')
select cron.schedule('*/5 * * * *','CALL reporting.p_compute_client_data(998934,''WEEKLY_DATA'');')
select cron.schedule('*/5 * * * *','CALL reporting.p_compute_client_data(45678,''DAILY_DATA'');')
select cron.schedule('*/5 * * * *','CALL reporting.p_compute_client_data(1010,''WEEKLY_DATA'');')
select cron.schedule('*/5 * * * *','CALL reporting.p_compute_client_data(1001,''MONTHLY_DATA'');')
select cron.schedule('*/5 * * * *','select reporting.f_reset_client_data(0,''DATA'')')
select cron.schedule('*/5 * * * *','VACUUM')
select cron.schedule('*/5 * * * *','$$DELETE FROM reporting.rep_request WHERE create_dt<now()- interval '60 DAYS'$$)ジョブの設定はジョブテーブルに保存されます:
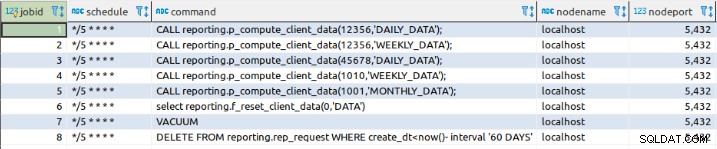
ジョブを定義する別の方法は、データをcronに直接挿入することです。 .jobテーブル:
INSERT INTO cron.job (schedule, command, nodename, nodeport, database, username)
VALUES ('0 11 * * *','call loader.load_data();','postgresql-pgcron',5442,'staging', 'loader');ノード名とノードポートのカスタム値を使用して、別のマシン(および他のデータベース)に接続します。
一方、ジョブを非アクティブ化するには、次の機能を実行するだけで済みます。
select cron.schedule(8)これらのジョブのログは、PostgreSQLログファイル/var/log/postgresql/postgresql-12-main.logにあります: