PostgreSQLでのEXPLAINの基本に関する一連の記事を続けます。これは、Guillaume LelargeによるEXPLAINの理解の短いレビューです。
この問題をよりよく理解するために、GuillaumeLelargeによるオリジナルの「UnderstandingEXPLAIN」を確認することを強くお勧めします。私の最初と2番目の記事を読んでください。
注文者
DROP INDEX foo_c1_idx; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

最初に、fooテーブルのシーケンシャルスキャン(Seq Scan)を実行してから、並べ替え(Sort)を実行します。 EXPLAINコマンドの->記号は、ステップ(ノード)の階層を示します。ステップが実行されるのが早いほど、インデントが大きくなります。
並べ替えキーは並べ替えの条件です。
並べ替え方法:外部マージディスク並べ替えには、4592kBの容量を持つディスク上の一時ファイルが使用されます。
BUFFERSオプションで確認してください:
DROP INDEX foo_c1_idx; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;
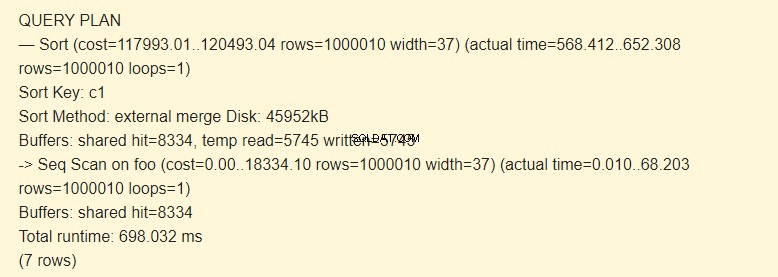
実際、temp read =5745written =5745行は、45960Kb(それぞれ8 Kbの5745ブロック)が一時ファイルに保存され、読み取られたことを意味します。 8334ブロックの操作はキャッシュで実行されました。
ファイルシステムでの操作は、RAMでの操作よりも低速です。
work_memのメモリ容量を増やしてみましょう:
SET work_mem TO '200MB'; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

並べ替え方法:クイックソートメモリ:102702kB –並べ替え全体がRAMで実行されました。
インデックスは次のとおりです:
CREATE INDEX ON foo(c1); EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

インデックススキャンのみが残っているため、クエリの速度に大きな影響がありました。
制限
以前に作成したインデックスを削除します:
DROP INDEX foo_c2_idx1; EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo WHERE c2 LIKE 'ab%';
予想どおり、Seqスキャンとフィルターが使用されます。
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo WHERE c2 LIKE 'ab%' LIMIT 10;

Seq Scanはテーブルの行を読み取り、それらを条件と比較します(フィルター)。条件を満たすレコードが10個あるとすぐに、スキャンは終了します。この場合、10行の結果を取得するには、テーブル全体ではなく、3063レコードのみを読み取る必要がありました。この番号の3053行が拒否されました(行はフィルターによって削除されました)。
同じことがインデックススキャンでも発生します。
参加
新しいテーブルを作成し、その統計を生成します:
CREATE TABLE bar (c1 integer, c2 boolean); INSERT INTO bar SELECT i, i%2=1 FROM generate_series(1, 500000) AS i; ANALYZE bar;
2つのテーブルのクエリは次のとおりです。
EXPLAIN (ANALYZE) SELECT * FROM foo JOIN bar ON foo.c1=bar.c1;
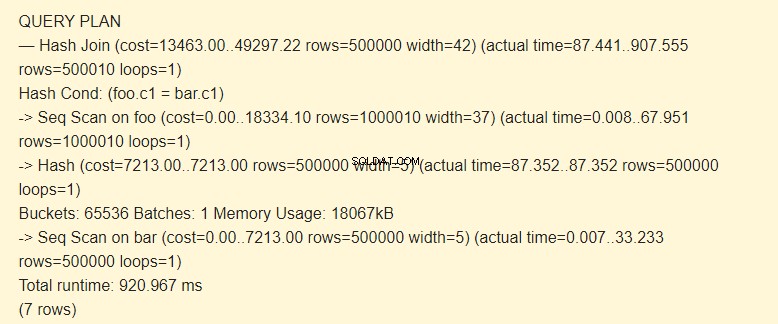
まず、シーケンシャルスキャン(Seq Scan)がバーテーブルを読み取ります。ハッシュ(ハッシュ)は行ごとに計算されます。
次に、fooテーブルをスキャンし、行ごとにハッシュが計算され、ハッシュ条件によってバーテーブルのハッシュと比較されます(ハッシュ結合)。それらが一致する場合、結果の文字列が出力されます。
18067kBのメモリは、バーのハッシュを格納するために使用されます。
インデックスを追加します:
CREATE INDEX ON bar(c1); EXPLAIN (ANALYZE) SELECT * FROM foo JOIN bar ON foo.c1=bar.c1;

ハッシュは使用されなくなりました。両方のテーブルのインデックスで結合とインデックススキャンをマージすると、パフォーマンスが大幅に向上します。
左参加:
EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;
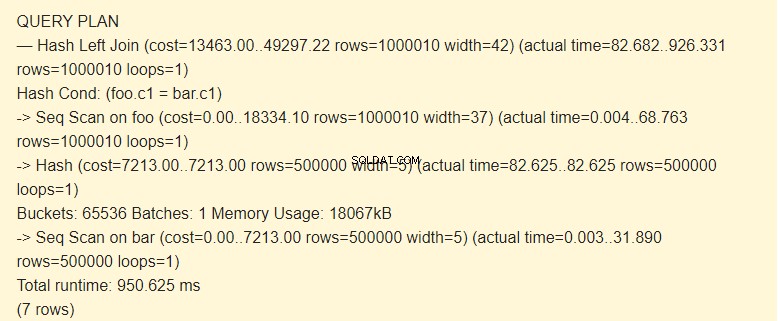
シーケンススキャン?
SeqScanを無効にした場合の結果を見てみましょう。
SET enable_seqscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;

スケジューラーによると、インデックスの使用はハッシュの使用よりもコストがかかります。これは、十分な量のメモリが割り当てられている場合に可能です。 work_memを増やしたことを覚えていますか?
ただし、十分なメモリがない場合、スケジューラの動作は異なります。
SET work_mem TO '15MB'; SET enable_seqscan TO ON; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;

インデックススキャンを無効にすると、EXPLAINはどのような結果を表示しますか?
SET work_mem TO '15MB'; SET enable_indexscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;
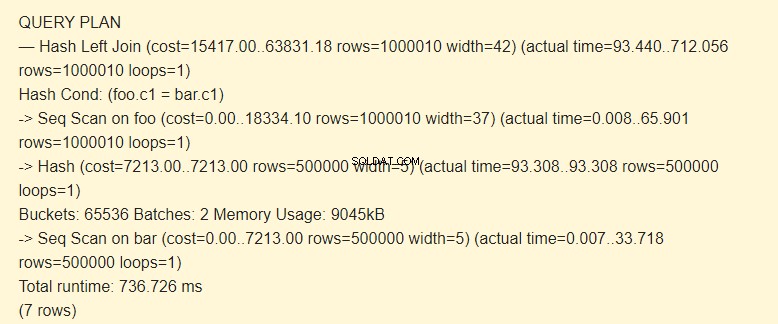
バッチ:2はコストが増加しました。ハッシュ全体がメモリに収まりませんでした。それを9045kBの2つのパッケージに分割する必要がありました。
私の記事を読んでくれてありがとう!それらがお役に立てば幸いです。コメントやフィードバックがありましたら、お気軽にお知らせください。