ほとんどのOLTPワークロードには、ランダムなディスクI/Oの使用が含まれます。ディスク(SSDを含む)はRAMを使用するよりもパフォーマンスが遅いことを知っているため、データベースシステムはキャッシュを使用してパフォーマンスを向上させます。キャッシングとは、後の時点でより高速にアクセスできるように、データをメモリ(RAM)に保存することです。
PostgreSQLは、shared_buffersと呼ばれるスペースへのデータのキャッシュも利用します。このブログでは、パフォーマンスの向上に役立つこの機能について説明します。
PostgreSQLキャッシングの基本
キャッシングの概念を深く掘り下げる前に、基本をブラッシュアップしましょう。
PostgreSQLでは、データはサイズ8KBのページの形式で編成され、そのようなすべてのページに複数のタプルを含めることができます(タプルのサイズによって異なります)。単純な表現は次のようになります。
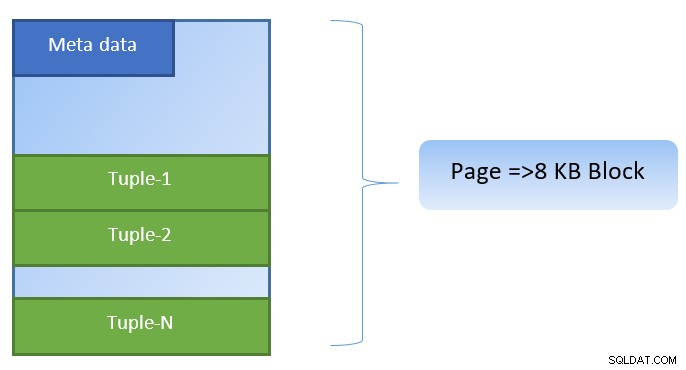
PostgreSQLは、データアクセスを高速化するために以下をキャッシュします。
クエリ実行プランのキャッシュの焦点は、CPUサイクルの節約にあります。テーブルデータとインデックスデータのキャッシュは、コストのかかるディスクI/O操作を節約することに重点を置いています。
PostgreSQLを使用すると、ユーザーは、データ用にそのようなキャッシュを保持するために予約するメモリの量を定義できます。関連する設定は、postgresql.conf構成ファイルのshared_buffersです。 shared_buffersの有限値は、任意の時点でキャッシュできるページ数を定義します。
クエリが実行されると、PostgreSQLは関連するタプルを含むディスク上のページを検索し、ラテラルアクセスのためにshared_buffersキャッシュにプッシュします。次回、同じタプル(または同じページ内の任意のタプル)にアクセスする必要がある場合、PostgreSQLはディスクIOをメモリに読み取ることで節約できます。
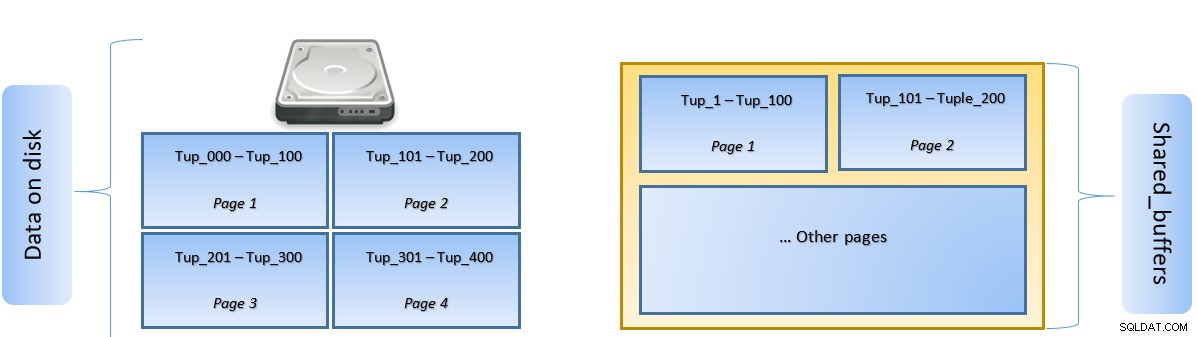
上の図では、特定のページ1とページ2テーブルがキャッシュされました。ユーザークエリがTuple-1からTuple-200の間のタプルにアクセスする必要がある場合、PostgreSQLはRAM自体からタプルをフェッチできます。
ただし、クエリがタプル250〜350にアクセスする必要がある場合は、ページ3およびページ4のディスクI / Oを実行する必要があります。タプル201〜400のそれ以降のアクセスは、キャッシュからフェッチされ、ディスクI/Oが不要になるため、クエリが高速化されます。
高レベルでは、PostgreSQLはLRU(最も最近使用されていない)アルゴリズムに従ってキャッシュから削除する必要のあるページを特定します。つまり、PostgreSQLが新しいページをキャッシュにフェッチする必要がある場合に備えて、一度だけアクセスされたページは、(複数回アクセスされたページと比較して)削除される可能性が高くなります。
PostgreSQLキャッシングの動作
例を実行して、パフォーマンスに対するキャッシュの影響を見てみましょう。
shared_bufferをデフォルトの128MBに設定したままPostgreSQLを起動します
$ initdb -D ${HOME}/data
$ echo “shared_buffers=128MB” >> ${HOME}/data/postgresql.conf
$ pg_ctl -D ${HOME}/data startサーバーに接続し、ダミーテーブルtblDummyとc_idのインデックスを作成します
CREATE Table tblDummy
(
id serial primary key,
p_id int,
c_id int,
entry_time timestamp,
entry_value int,
description varchar(50)
);
CREATE INDEX ON tblDummy(c_id );ダミーデータに200000タプルを入力します。たとえば、10000個の一意のp_idがあり、すべてのp_idに対して200個のc_idがあります。
DO $$
DECLARE
random_value integer:= 1;
BEGIN
FOR p_id_ctr IN 1..10000 BY 1 LOOP
FOR c_id_ctr IN 1..200 BY 1 LOOP
random_value = (( random() * 75 ) + 25);
INSERT INTO tblDummy (p_id,c_id,entry_time, entry_value, description )
VALUES (p_id_ctr,c_id_ctr,'now', random_value, CONCAT('Description for :',p_id_ctr, c_id_ctr));
END LOOP ;
END LOOP ;
END $$;SELECT pg_stat_reset();
EXPLAIN ANAYZE SELECT count(*) from tbldummy where c_id=1;
QUERY PLAN
--------------------------------------------------------------
Aggregate (cost=17407.33..17407.34 rows=1 width=8) (actual time=160.269..160.269 rows=1 loops=1)
-> Bitmap Heap Scan on tbldummy (cost=189.52..17382.46 rows=9948 width=0) (actual time=10.627..156.275 rows=10000 loops=1)
Recheck Cond: (c_id = 1)
Heap Blocks: exact=10000
-> Bitmap Index Scan on tbldummy_c_id_idx (cost=0.00..187.04 rows=9948 width=0) (actual time=5.091..5.091 rows=10000 loops=1)
Index Cond: (c_id = 1)
Planning Time: 1.325 ms
Execution Time: 160.505 ms次に、ディスクから読み取られたブロックを確認します
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
---------------+---------------
10000 | 0上記の例では、c_id =1のカウントタプルを見つけるためにディスクから1000ブロックが読み取られました。これらのレコードをディスクからフェッチするためにディスクI/Oが関与していたため、160ミリ秒かかりました。
この段階ではすべてのブロックがPostgreSQLサーバーのキャッシュに残っているため、同じクエリを再実行すると実行が速くなります
SELECT pg_stat_reset();
EXPLAIN ANAYZE SELECT count(*) from tbldummy where c_id=1;
QUERY PLAN
-------------------------------------------------------------------------------------
Aggregate (cost=17407.33..17407.34 rows=1 width=8) (actual time=33.760..33.761 rows=1 loops=1)
-> Bitmap Heap Scan on tbldummy (cost=189.52..17382.46 rows=9948 width=0) (actual time=9.584..30.576 rows=10000 loops=1)
Recheck Cond: (c_id = 1)
Heap Blocks: exact=10000
-> Bitmap Index Scan on tbldummy_c_id_idx (cost=0.00..187.04 rows=9948 width=0) (actual time=4.314..4.314 rows=10000 loops=1)
Index Cond: (c_id = 1)
Planning Time: 0.106 ms
Execution Time: 33.990 msSELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
---------------+---------------
0 | 10000上記から明らかなように、すべてのブロックがキャッシュから読み取られ、ディスクI/Oは必要ありませんでした。したがって、これにより結果も速くなりました。
PostgreSQLキャッシュのサイズの設定
キャッシュのサイズは、使用可能なRAMの量と実行する必要のあるクエリに応じて、実稼働環境で調整する必要があります。
例として–クエリがより多くのタプルをフェッチする場合、128MBのshared_bufferはすべてのデータをキャッシュするのに十分ではない可能性があります:
SELECT pg_stat_reset();
SELECT count(*) from tbldummy where c_id < 150;
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
----------------+---------------
20331 | 288shared_bufferを1024MBに変更して、heap_blks_hitを増やします。
実際、クエリ(c_idに基づく)を考慮すると、データが再編成された場合、より小さなshared_bufferでもより良いキャッシュヒット率を達成できます。
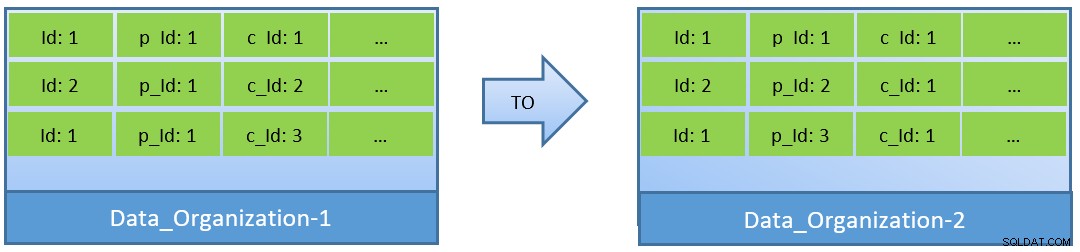
Data_Organization-1では、PostgreSQLは1000ブロックの読み取り(およびキャッシュの消費)が必要になります)c_id=1を見つけるため。一方、Data_Organisation-2の場合、同じクエリの場合、PostgreSQLは104ブロックしか必要としません。
同じクエリに必要なブロックが少なくなると、最終的にはキャッシュの消費量が少なくなり、クエリの実行時間が最適化されます。
shared_bufferはPostgreSQLプロセスレベルで維持されますが、最適化されたクエリ実行プランを識別するためにカーネルレベルのキャッシュも考慮されます。このトピックについては、後の一連のブログで取り上げます。