PostgreSQLデータベースを回復するにはさまざまな方法がありますが、論理バックアップからデータを復元するための最も便利な方法の1つです。論理バックアップは、災害復旧計画(DRP)にとって重要な役割を果たします。論理バックアップは、たとえばpg_dumpまたはpg_dumpallを使用して作成されたバックアップであり、バイナリファイルに書き込まれるすべてのテーブルデータを取得するためのSQLステートメントを生成します。
物理バックアップが失敗したり利用できなくなったりした場合に備えて、定期的な論理バックアップを実行することもお勧めします。 PostgreSQLの場合、使用するツールがわからない場合、復元が問題になる可能性があります。バックアップツールpg_dumpは通常、復元ツールpg_restoreとペアになっています。
災害が発生し、データを回復する必要がある場合、pg_dumpとpg_restoreは連携して動作します。これらはダンプと復元の主な目的を果たしますが、クラスターを回復してフェイルオーバーを実行する必要がある場合(ハードウェア障害またはVMシステムの破損のためにアクティブなプライマリまたはマスターが停止した場合)、いくつかの追加タスクを実行する必要があります。最終的に、フェイルオーバーまたは自動クラスター回復を処理できるサードパーティのツールを見つけて利用することになります。
このブログでは、pg_restoreがどのように機能するかを見て、災害が発生した場合にClusterControlがデータのバックアップと復元を処理する方法と比較します。
pg_restoreのメカニズム
pg_restoreは、次のタスクを取得するときに役立ちます。
- pg_dumpと組み合わせて、データ、アクセスロール、データベース、およびテーブル定義を含むSQL生成ファイルを生成します
- pg_dumpによって作成されたアーカイブからプレーンテキスト以外の形式の1つでPostgreSQLデータベースを復元します。
- データベースを、保存時の状態に再構築するために必要なコマンドを発行します。
- アーカイブファイルに基づいて復元する前に、アイテムを選択したり、並べ替えたりする機能があります。
- アーカイブファイルは、アーキテクチャ間で移植できるように設計されています。
- pg_restoreは2つのモードで動作できます。
- データベース名が指定されている場合、pg_restoreはそのデータベースに接続し、アーカイブの内容をデータベースに直接復元します。
- または、データベースの再構築に必要なSQLコマンドを含むスクリプトが作成され、ファイルまたは標準出力に書き込まれます。そのスクリプト出力は、pg_dumpによって生成された形式と同等です
- したがって、出力を制御するオプションのいくつかは、pg_dumpオプションに類似しています。
データを復元したら、復元された各テーブルでANALYZEを実行して、オプティマイザーが有用な統計情報を取得できるようにすることをお勧めします。 READ LOCKを取得しますが、トラフィックが少ないときやメンテナンス期間中にこれを実行する必要がある場合があります。
pg_restoreの利点
pg_dumpとpg_restoreを連携させることで、DBAが利用するのに便利な機能を利用できます。
- pg_dumpとpg_restoreには、-jオプションを指定することで並行して実行する機能があります。 -j /-jobs
を使用すると、特にデータのロード、インデックスの作成、または複数の同時ジョブを使用した制約の作成のために、並行して実行できるジョブの数を指定できます。 - 使用するのは静かで便利で、特定のデータベースまたはテーブルを選択的にダンプまたはロードできます
- 特定のデータベース、スキーマ、またはリストに基づいて実行するプロシージャの並べ替えをユーザーが柔軟に行えるようにします。必要に応じて、ACLや特権を防ぐように、SQLのシーケンスを大まかに生成してロードすることもできます。ニーズに合わせてたくさんのオプションがあります。
- アーカイブからpg_dumpのようにSQLファイルを生成する機能を提供します。これは、別のデータベースまたはホストにロードして別の環境をプロビジョニングする場合に非常に便利です。
- 生成されたSQLプロシージャのシーケンスに基づいて、簡単に理解できます。
- これは、レプリケーション環境でデータをロードするための便利な方法です。ステートメントはスタンバイノードとリカバリノードに複製されたSQLであるため、レプリカを再ステージングする必要はありません。
pg_restoreの制限
論理バックアップの場合、pg_restoreとpg_dumpの明らかな制限は、ツールを使用する際のパフォーマンスと速度です。テストまたは開発データベース環境をプロビジョニングしてデータをロードする場合は便利ですが、データセットが膨大な場合は適用できません。 PostgreSQLは、データを1つずつダンプするか、データベースエンジンによってデータを順番に実行して適用する必要があります。これを緩く柔軟にして、-jを指定したり、-single-transactionを使用してデータベースへの影響を回避したりすることができますが、SQLを使用したロードはエンジンで解析する必要があります。
さらに、PostgreSQLのドキュメントには次の制限が記載されていますが、これらのツール(pg_dumpおよびpg_restore)を観察したときに追加されました:
- 既存のテーブルにデータを復元し、オプション--disable-triggersを使用すると、pg_restoreは、データを挿入する前にユーザーテーブルのトリガーを無効にするコマンドを発行し、次にそれらを再度有効にするコマンドを発行します。データが挿入された後。復元が途中で停止した場合、システムカタログが間違った状態のままになる可能性があります。
- pg_restoreは大きなオブジェクトを選択的に復元できません。たとえば、特定のテーブルのものだけです。アーカイブにラージオブジェクトが含まれている場合、すべてのラージオブジェクトが復元されます。または、-L、-t、またはその他のオプションで除外されている場合は、いずれも復元されません。
- どちらのツールも、特に巨大なデータベースの場合、膨大なサイズ(ファイル、ディレクトリ、またはtarアーカイブ)を生成することが期待されています。
- pg_dumpの場合、単一のテーブルをダンプするとき、またはプレーンテキストとしてダンプするとき、pg_dumpは大きなオブジェクトを処理しません。大きなオブジェクトは、非テキストアーカイブ形式のいずれかを使用してデータベース全体でダンプする必要があります。
- これらのツールによって生成されたtarアーカイブがある場合、tarアーカイブは8GB未満のサイズに制限されていることに注意してください。これは、tarファイル形式に固有の制限です。したがって、テーブルのテキスト表現がそのサイズを超える場合、この形式は使用できません。 tarアーカイブとその他の出力形式の合計サイズは、オペレーティングシステムによる場合を除いて、制限されていません。
pg_restoreの使用
pg_restoreの使用は非常に便利で、簡単に利用できます。 pg_dumpと連携してペアになっているため、これらのツールは両方とも、ターゲット出力が他方に適合している限り、十分に機能します。たとえば、次のpg_dumpはpg_restoreには役立ちません
[example@sqldat.com ~]# pg_dump --format=p --create -U dbapgadmin -W -d paultest -f plain.sql
Password: この結果は、次のようなpsql互換になります。
[example@sqldat.com ~]# less plain.sql
--
-- PostgreSQL database dump
--
-- Dumped from database version 12.2
-- Dumped by pg_dump version 12.2
SET statement_timeout = 0;
SET lock_timeout = 0;
SET idle_in_transaction_session_timeout = 0;
SET client_encoding = 'UTF8';
SET standard_conforming_strings = on;
SELECT pg_catalog.set_config('search_path', '', false);
SET check_function_bodies = false;
SET xmloption = content;
SET client_min_messages = warning;
SET row_security = off;
--
-- Name: paultest; Type: DATABASE; Schema: -; Owner: postgres
--
CREATE DATABASE paultest WITH TEMPLATE = template0 ENCODING = 'UTF8' LC_COLLATE = 'en_US.UTF-8' LC_CTYPE = 'en_US.UTF-8';
ALTER DATABASE paultest OWNER TO postgres;ただし、従うべきプレーン形式がないため、pg_restoreでは失敗します:
[example@sqldat.com ~]# pg_restore -U dbapgadmin --format=p -C -W -d postgres plain.sql
pg_restore: error: unrecognized archive format "p"; please specify "c", "d", or "t"
[example@sqldat.com ~]# pg_restore -U dbapgadmin --format=c -C -W -d postgres plain.sql
pg_restore: error: did not find magic string in file headerでは、pg_restoreのより便利な用語に進みましょう。
pg_restore:ドロップして復元
postgres=# drop database maxtest;
DROP DATABASE
postgres=# \l+
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
-----------+----------+----------+-------------+-------------+-----------------------+---------+------------+--------------------------------------------
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 83 MB | pg_default |
postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 8209 kB | pg_default | default administrative connection database
template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +| 8049 kB | pg_default | unmodifiable empty database
| | | | | postgres=CTc/postgres | | |
template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | postgres=CTc/postgres+| 8193 kB | pg_default | default template for new databases
| | | | | =c/postgres | | |
(4 rows)pg_restoreを使用して復元するのは非常に簡単です
[example@sqldat.com ~]# sudo -iu postgres pg_restore -C -d postgres /opt/pg-files/dump/f.dump -C /-create hereは、ヘッダーでデータベースが検出されるとデータベースを作成することを示します。 -d postgresはpostgresデータベースを指しますが、postgresデータベースへのテーブルを作成するという意味ではありません。データベースが存在する必要があります。 -Cが指定されていない場合、テーブルとレコードは-d引数で参照されるデータベースに格納されます。
pg_restoreを使用したテーブルの復元は簡単です。たとえば、「b」テーブルと「d」テーブルの2つのテーブルがあります。以下のpg_dumpコマンドを実行するとします
[example@sqldat.com ~]# pg_dump --format=d --create -U dbapgadmin -W -d paultest -f pgdump_inserts
Password:[example@sqldat.com ~]# ls -alth pgdump_inserts/
total 16M
-rw-r--r--. 1 root root 14M May 15 20:27 3696.dat.gz
drwx------. 2 root root 59 May 15 20:27 .
-rw-r--r--. 1 root root 2.5M May 15 20:27 3694.dat.gz
-rw-r--r--. 1 root root 4.0K May 15 20:27 toc.dat
dr-xr-x---. 5 root root 275 May 15 20:27 ..テーブル(この例では「d」)を復元する場合は、
[example@sqldat.com ~]# pg_restore -U postgres -Fd -d paultest -t d pgdump_inserts/paultest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | d | table | postgres | 51 MB |
(1 row)pg_restore:データベーステーブルを別のデータベースにコピーする
既存のデータベースの内容をコピーして、ターゲットデータベースに保存することもできます。たとえば、次のデータベースがあります
paultest=# \l+ (paultest|maxtest)
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
----------+----------+----------+-------------+-------------+-------------------+---------+------------+-------------
maxtest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 84 MB | pg_default |
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 8273 kB | pg_default |
(2 rows)maxtestデータベース内にあるものをコピーする間、paultestデータベースは空のデータベースです
maxtest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | d | table | postgres | 51 MB |
(1 row)
maxtest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | b | table | postgres | 69 MB |
public | d | table | postgres | 51 MB |
(2 rows)コピーするには、次のようにmaxtestデータベースからデータをダンプする必要があります
[example@sqldat.com ~]# pg_dump --format=t --create -U dbapgadmin -W -d maxtest -f pgdump_data.tar
Password: 次に、次のようにロードまたは復元します。
これで、paultestデータベースにデータが取得され、それに応じてテーブルが保存されました。
postgres=# \l+ (paultest|maxtest)
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
----------+----------+----------+-------------+-------------+-------------------+--------+------------+-------------
maxtest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 153 MB | pg_default |
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 154 MB | pg_default |
(2 rows)
paultest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | b | table | postgres | 69 MB |
public | d | table | postgres | 51 MB |
(2 rows)pg_restoreで多くの使用法を見てきましたが、この機能は通常は紹介されていないようです。このアプローチは、含めたくないものに基づいて順序付けし、次に続行したい順序からSQLファイルを生成できるため、非常に興味深いと思いました。
たとえば、前に生成したサンプルpgdump_data.tarを使用して、リストを作成します。これを行うには、次のコマンドを実行します。
[example@sqldat.com ~]# pg_restore -l pgdump_data.tar > my.listこれにより、以下に示すようなファイルが生成されます:
[example@sqldat.com ~]# cat my.list
;
; Archive created at 2020-05-15 20:48:24 UTC
; dbname: maxtest
; TOC Entries: 13
; Compression: 0
; Dump Version: 1.14-0
; Format: TAR
; Integer: 4 bytes
; Offset: 8 bytes
; Dumped from database version: 12.2
; Dumped by pg_dump version: 12.2
;
;
; Selected TOC Entries:
;
204; 1259 24811 TABLE public b postgres
202; 1259 24757 TABLE public d postgres
203; 1259 24760 SEQUENCE public d_id_seq postgres
3698; 0 0 SEQUENCE OWNED BY public d_id_seq postgres
3560; 2604 24762 DEFAULT public d id postgres
3691; 0 24811 TABLE DATA public b postgres
3689; 0 24757 TABLE DATA public d postgres
3699; 0 0 SEQUENCE SET public d_id_seq postgres
3562; 2606 24764 CONSTRAINT public d d_pkey postgresでは、並べ替えてみましょう。または、SEQUENCEの作成と制約の作成を削除したとしましょう。これは次のようになります
TL;DR
...
;203; 1259 24760 SEQUENCE public d_id_seq postgres
;3698; 0 0 SEQUENCE OWNED BY public d_id_seq postgres
TL;DR
….
;3562; 2606 24764 CONSTRAINT public d d_pkey postgresSQL形式でファイルを生成するには、次の手順を実行します。
[example@sqldat.com ~]# pg_restore -L my.list --file /tmp/selective_data.out pgdump_data.tar これで、ファイル/tmp/selective_data.outはSQLで生成されたファイルになります。これは、pg_restoreではなくpsqlを使用すると読み取り可能です。これの優れている点は、テンプレートに従ってSQLファイルを生成できることです。このファイルでは、pg_restoreを使用してpg_dumpを使用して取得した既存のアーカイブまたはバックアップからのみデータを復元できます。
ClusterControlを使用したPostgreSQLの復元
ClusterControlは、機能セットの一部としてpg_restoreまたはpg_dumpを利用しません。 pg_dumpallを使用して論理バックアップを生成しますが、残念ながら、出力はpg_restoreと互換性がありません。
以下に示すように、PostgreSQLでバックアップを生成する方法は他にもいくつかあります。
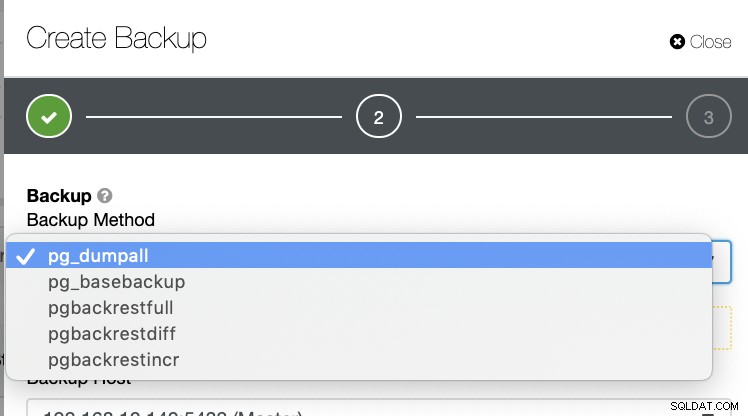
テーブル、データベース、または、あるデータベースから別のデータベースにコピーします。
ClusterControlはポイントインタイムリカバリ(PITR)をサポートしていますが、これではpg_restoreのように柔軟にデータの復元を管理することはできません。バックアップ方法のすべてのリストについて、pg_basebackupとpgbackrestのみがPITR対応です。
ClusterControlが復元を処理する方法は、以下に示すように、自動回復が有効になっている限り、障害が発生したクラスターを回復する機能を備えていることです。

マスターに障害が発生すると、ClusterControlの実行時に、スレーブはクラスターを自動的に回復できます。フェイルオーバー(自動的に実行されます)。データ回復部分の場合、唯一のオプションは、クラスター全体の回復を行うことです。これは、完全バックアップからの回復であることを意味します。復元したいだけのターゲットデータベースまたはテーブルを選択的に復元する機能はありません。それを実行したい場合は、完全バックアップを復元します。ClusterControlを使用すると簡単に実行できます。以下に示すように、[バックアップ]タブに移動できます。
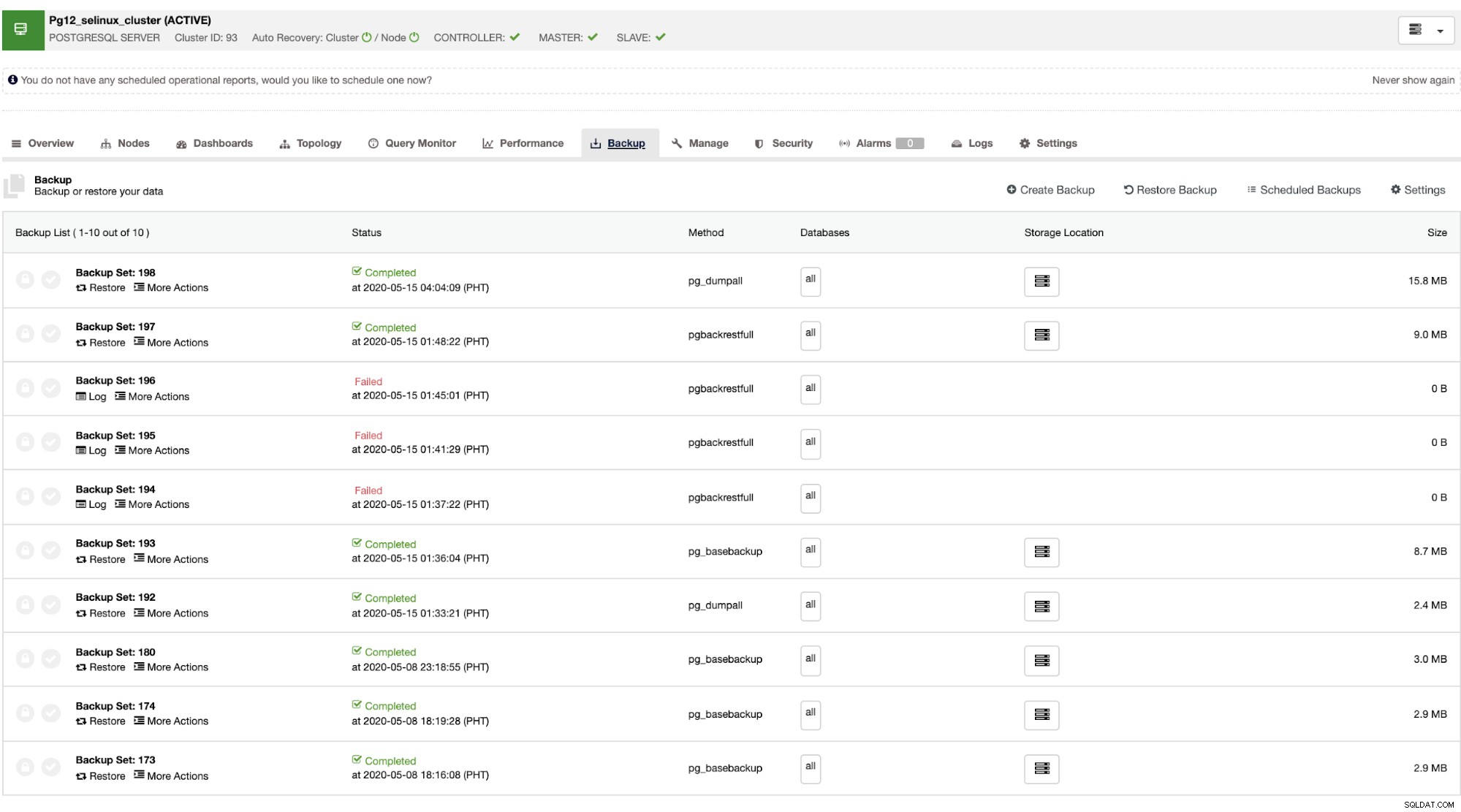
成功したバックアップと失敗したバックアップの完全なリストが表示されます。次に、ターゲットのバックアップを選択して[復元]ボタンをクリックすると、復元を実行できます。これにより、ClusterControl内に登録されている既存のノードで復元したり、スタンドアロンノードで検証したり、バックアップからクラスターを作成したりできます。
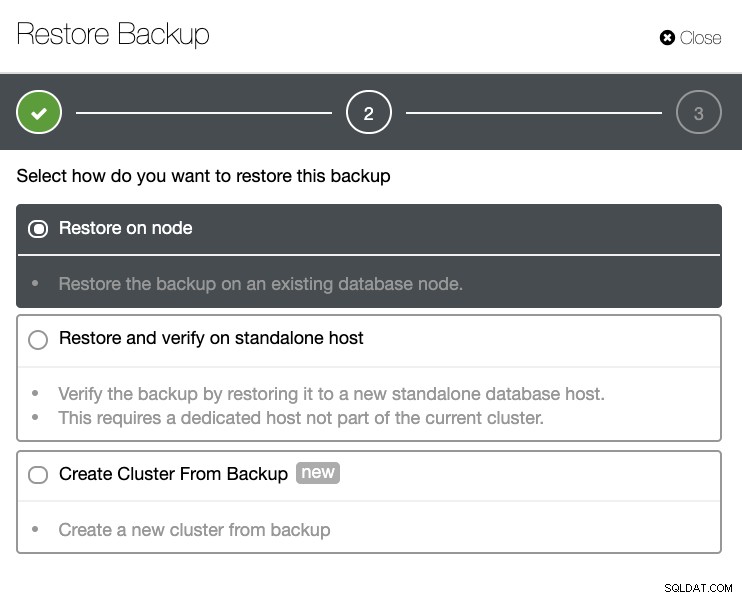
pg_dumpとpg_restoreを使用すると、バックアップ/ダンプと復元のアプローチが簡素化されます。ただし、大規模なデータベース環境の場合、これはディザスタリカバリの理想的なコンポーネントではない可能性があります。最小限の選択と復元手順の場合、pg_dumpとpg_restoreの組み合わせを使用すると、必要に応じてデータをダンプおよびロードすることができます。
実稼働環境(特にエンタープライズアーキテクチャ)の場合、ClusterControlアプローチを使用して、自動リカバリでバックアップと復元を作成できます。
アプローチの組み合わせも良いアプローチです。これにより、RTOとRPOを下げると同時に、必要なときにデータを復元するための最も柔軟な方法を活用できます。