高可用性の重要な側面の1つは、障害に迅速に対応する機能です。データベースを手動で管理し、監視ソフトウェアにデータベースの状態を監視させることは珍しくありません。障害が発生した場合、監視ソフトウェアはオンコールスタッフにアラートを送信します。これは、誰かが目を覚まし、コンピューターにアクセスしてシステムにログインし、ログを確認する必要がある可能性があることを意味します。つまり、修復を開始するまでにかなりのリードタイムがあります。理想的には、プロセス全体を自動化する必要があります。
このブログでは、プライマリデータベースの障害を検出し、セカンダリデータベースを昇格させることでフェイルオーバー手順を開始する、完全に自動化されたシステムを導入する方法について説明します。 ClusterControlを使用して、MoodlePostgreSQLデータベースの自動フェイルオーバーを実行します。
- データベースサービスを回復するための時間の短縮
- システムの稼働時間の延長
- データベースの高可用性を設定したDBAまたは管理者への依存度が低くなります。
アーキテクチャ
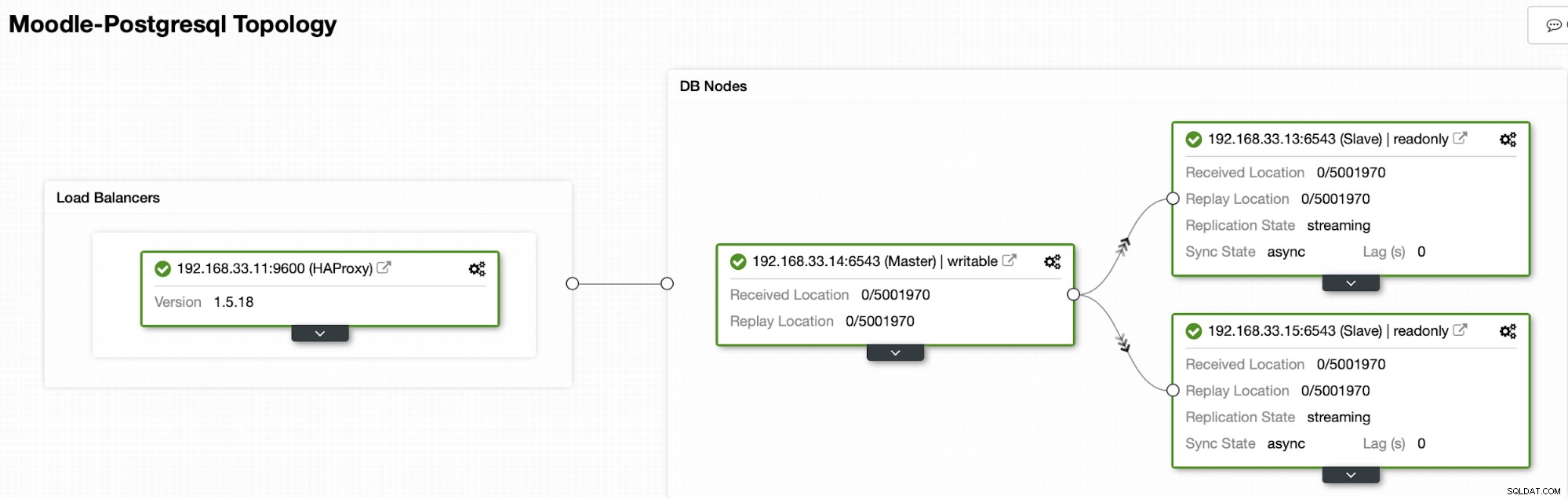
現在、HAProxyロードバランサーの下に1台のPostgresプライマリサーバーと2台のセカンダリサーバーがありますMoodleトラフィックをプライマリPostgreSQLノードに送信します。 ClusterControlのクラスターリカバリとノード自動リカバリは、自動フェイルオーバープロセスを実行するための重要な設定です。

ClusterControlは、フェイルオーバーに参加する、または候補として除外する一連のサーバーのホワイトリストとブラックリストを提供します。
cmon構成で設定できる変数は2つあります
- Replication_failover_whitelist:潜在的なプライマリ候補として使用する必要があるセカンダリサーバーのIPまたはホスト名のリストが含まれています。この変数が設定されている場合、それらのホストのみが考慮されます。
- Replication_failover_blacklist:プライマリ候補とは見なされないホストのリストが含まれています。これを使用して、バックアップまたは分析クエリに使用されるセカンダリサーバーを一覧表示できます。セカンダリサーバー間でハードウェアが異なる場合は、低速のハードウェアを使用するサーバーをここに配置することをお勧めします。
sysbenchツールを使用してプライマリサーバー(192.168.33.14)へのデータの読み込みを開始しました。
[example@sqldat.com sysbench]# /bin/sysbench --db-driver=pgsql --oltp-table-size=100000 --oltp-tables-count=24 --threads=2 --pgsql-host=****** --pgsql-port=6543 --pgsql-user=sbtest --pgsql-password=***** --pgsql-db=sbtest /usr/share/sysbench/tests/include/oltp_legacy/parallel_prepare.lua run
sysbench 1.0.20 (using bundled LuaJIT 2.1.0-beta2)
Running the test with following options:
Number of threads: 2
Initializing random number generator from current time
Initializing worker threads...
Threads started!
thread prepare0
Creating table 'sbtest1'...
Inserting 100000 records into 'sbtest1'
Creating secondary indexes on 'sbtest1'...
Creating table 'sbtest2'...
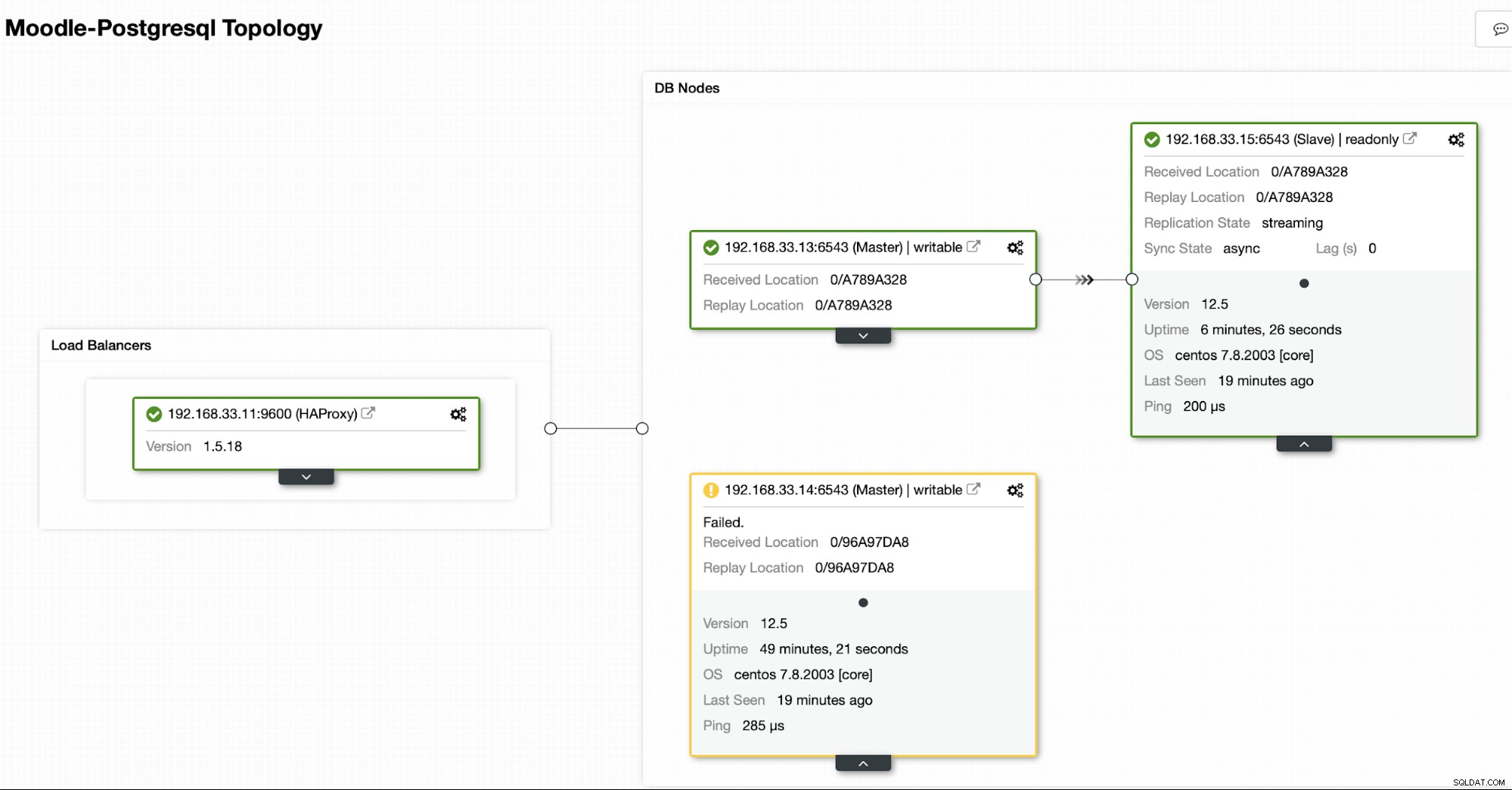
Postgresプライマリサーバー(192.168.33.14)を停止します。 ClusterControlでは、(enable_cluster_autorecovery)パラメーターが有効になっているため、次の適切なプライマリーがプロモートされます。
# service postgresql-12 stopClusterControlは、プライマリの障害を検出し、最新のデータを使用してセカンダリを新しいプライマリとしてプロモートします。また、残りのセカンダリサーバーでも機能して、新しいプライマリから複製します。

この場合、(192.168.33.13)は新しいプライマリサーバーであり、セカンダリサーバーは、この新しいプライマリサーバーから複製されます。これで、HAProxyはデータベーストラフィックをMoodleサーバーから最新のプライマリサーバーにルーティングします。
From(192.168.33.13)
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
f
(1 row)(192.168.33.15)から
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
t
(1 row)
現在のトポロジ
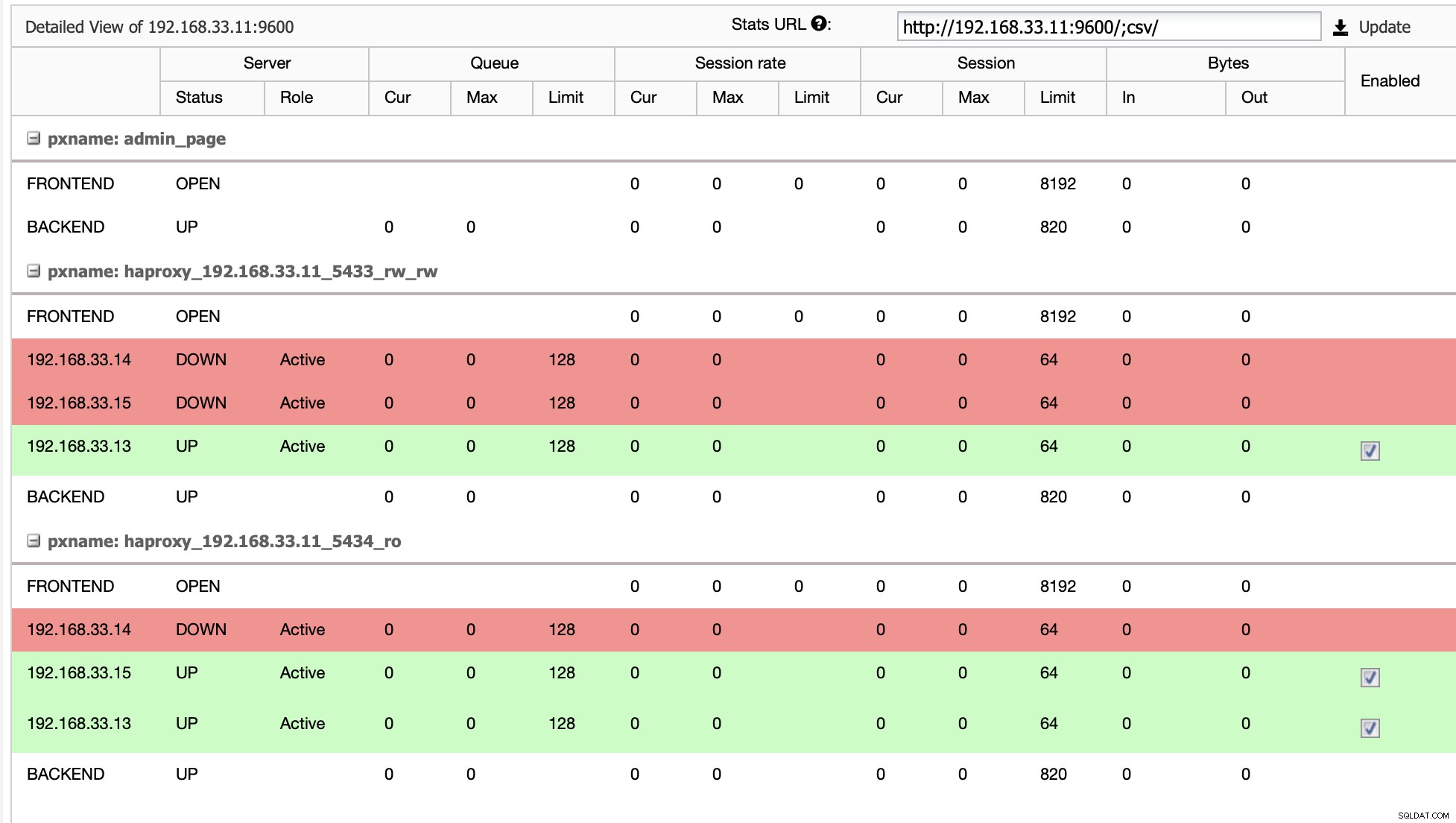
HAProxyが、プライマリまたはレプリカのいずれかのノードがアクセスできない場合は、自動的にオフラインとしてマークされます。 HAProxyはMoodleアプリケーションからそれにトラフィックを送信しません。このチェックは、展開時にClusterControlによって構成されたヘルスチェックスクリプトによって実行されます。
ClusterControlがレプリカサーバーをプライマリにプロモートすると、HAProxyは古いプライマリをオフラインとしてマークし、プロモートされたノードをオンラインにします。
古いプライマリがオンラインに戻ると、新しいプライマリサーバーに自動的に同期されません。トポロジに戻す必要があります。これは、ClusterControlインターフェイスを介して実行できます。これにより、そもそもサーバーに障害が発生した理由を調査したい場合に備えて、データの損失や不整合の可能性を回避できます。
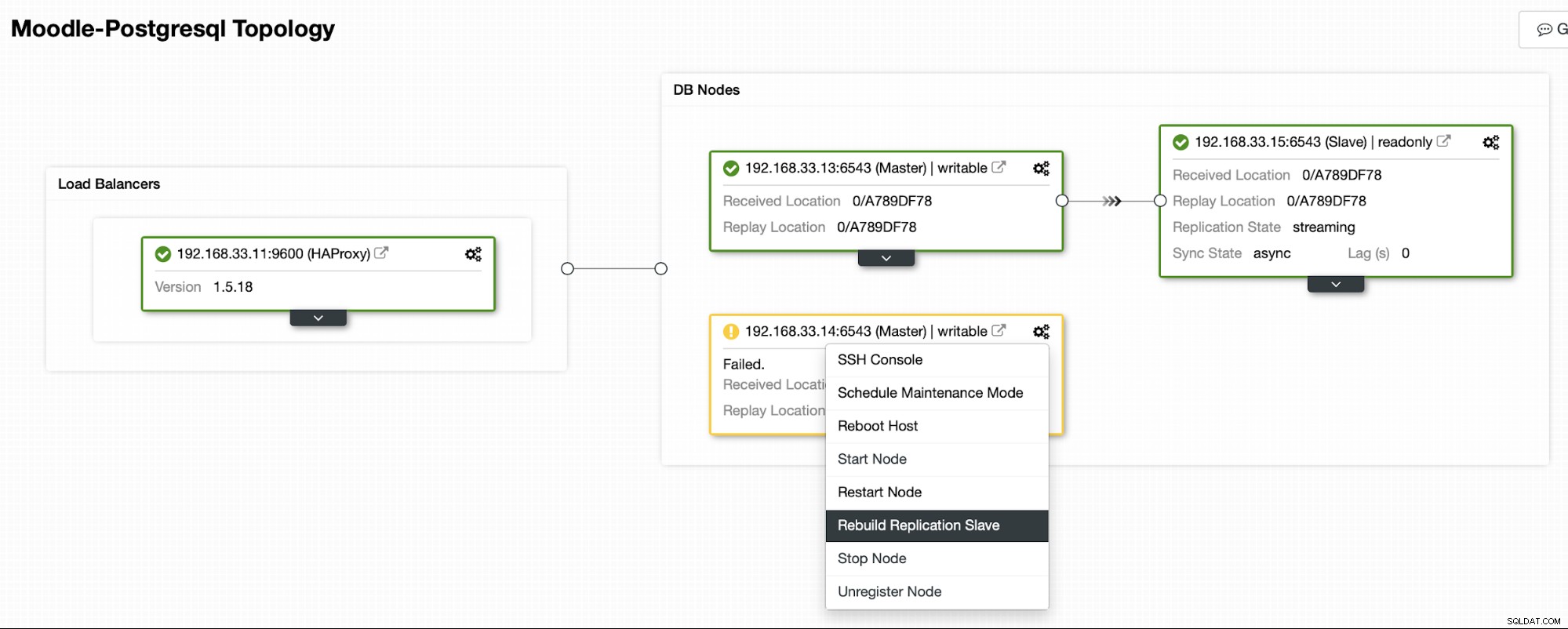
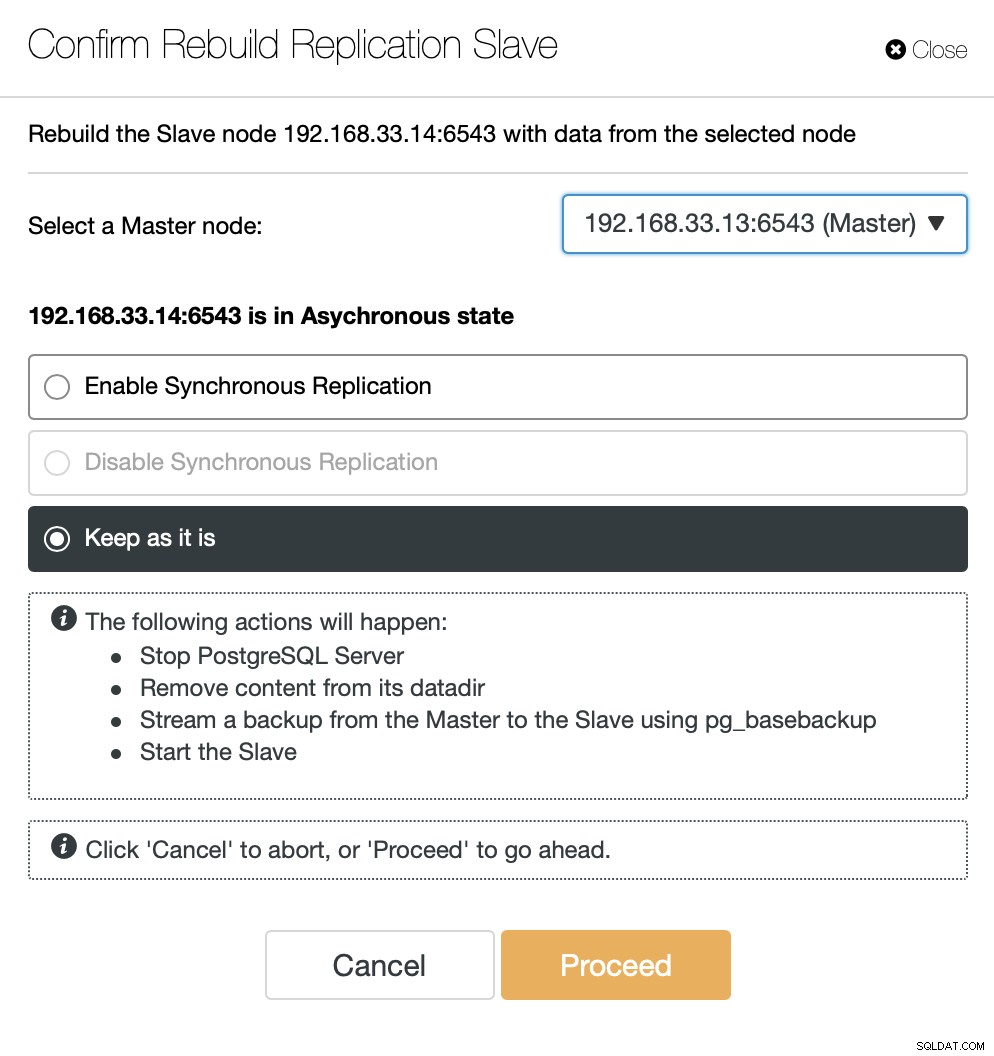
ClusterControlは、新しいプライマリサーバーからバックアップをストリーミングし、レプリケーションを構成します。
自動フェイルオーバーは、Moodle本番データベースの重要な部分です。サーバーがダウンしたときだけでなく、一般的なメンテナンスタスクや移行を実行するときのダウンタイムを減らすことができます。フェイルオーバーソフトウェアが正しい決定を下すことが重要であるため、正しく理解することが重要です。