監視は、システムが正常に機能しているかどうかを知るための基盤であり、ビジネスに影響を与える前に問題を修正または防止できます。 PostgreSQLのような堅牢なテクノロジーでも、監視は必須であり、主な目標は何を監視するかを知ることです。そうしないと、使用する必要がある場合に意味がないか、役に立たない可能性があります。このブログでは、PostgreSQL用のPercona Distributionとは何か、およびPostgreSQLで監視する主要なメトリックについて説明します。
PostgreSQLのPerconaディストリビューション
これは、PostgreSQLデータベースシステムの管理を支援するツールのコレクションです。 PostgreSQLをインストールし、次のような重要な実用的なタスクを効率的に解決できるようにする拡張機能を選択することで、PostgreSQLを補完します。
- pg_repack :PostgreSQLデータベースオブジェクトを再構築します。
- pgaudit :標準のPostgreSQLログ機能を介して詳細なセッションまたはオブジェクト監査ログを提供します。
- pgBackRest :これはPostgreSQLのバックアップと復元のソリューションです。
- パトロニ :PostgreSQL用の高可用性ソリューションです。
- pg_stat_monitor :PostgreSQLの統計を収集して集約し、ヒストグラム情報を提供します。
PostgreSQL用のPerconaディストリビューションもlibpqライブラリに付属しています。これには、クライアントプログラムがPostgreSQLバックエンドサーバーにクエリを渡し、これらのクエリの結果を受信できるようにする一連のライブラリ関数が含まれています。
PostgreSQL用のPerconaディストリビューションで監視するもの
データベースクラスターを監視する場合、考慮すべき主な事項が2つあります。オペレーティングシステムとデータベース自体です。両側から監視するメトリックとその方法を定義する必要があります。
メトリックの1つが影響を受けると、他のメトリックにも影響を与える可能性があり、問題のトラブルシューティングがより複雑になることに注意してください。このタスクをできるだけ簡単にするためには、優れた監視およびアラートシステムを用意することが重要です。
1つの重要なことは、オペレーティングシステムの動作を監視することです。ここで確認するポイントをいくつか見てみましょう。
通常の動作でない場合、CPU使用率の過剰な割合が問題になる可能性があります。この場合、この問題を引き起こしているプロセスを特定することが重要です。問題がデータベースプロセスにある場合は、データベース内で何が起こっているかを確認する必要があります。
RAMメモリまたはSWAPの使用量
このメトリックに高い値が表示されていて、システムに何も変更がない場合は、データベース構成を確認する必要があります。 shared_buffersやwork_memなどのパラメーターは、PostgreSQLデータベースに使用できるメモリの量を定義するため、これに直接影響を与える可能性があります。
PostgreSQLログファイルに多数のエラーが記録されたり、キャッシュ構成が正しくなかったりする可能性があるため、ディスクスペースの使用量の異常な増加やディスクアクセスの過剰な消費を監視することが重要です。クエリの処理にメモリを使用する代わりに、重要なディスクアクセスの消費を生成します。
アプリケーションがデータベースに接続できない(または失われたパッケージを接続できない)ため、ネットワークの問題がすべてのシステムに影響を与える可能性があるため、これは実際に監視する重要な指標です。遅延またはパケット損失を監視できます。主な問題は、ネットワークの飽和、ハードウェアの問題、または単にネットワーク構成の不良である可能性があります。
PostgreSQLデータベースの監視
PostgreSQLデータベースを監視することは、問題が発生しているかどうかを確認するだけでなく、データベースのパフォーマンスを向上させるために何かを変更する必要があるかどうかを知ることも重要です。これはおそらく最も重要なことの1つです。データベースで監視します。これに重要ないくつかの指標を見てみましょう。
デフォルトでは、PostgreSQLは互換性と安定性を念頭に置いて構成されているため、クエリとそのパターンを理解し、トラフィックに応じてデータベースを構成する必要があります。ここでは、EXPLAINコマンドを使用して、特定のクエリのクエリプランを確認できます。また、各ノードのSELECT、INSERT、UPDATE、またはDELETEの量を監視することもできます。長いクエリまたは多数のクエリを同時に実行している場合、それはすべてのシステムで問題になる可能性があります。
別のクエリを待機しているクエリがある場合は、その別のクエリが通常のプロセスであるか、何か新しいものであるかを確認する必要があります。たとえば、誰かが大きなテーブルを更新している場合、このアクションはデータベースの通常の動作に影響を及ぼし、多数のロックを生成する可能性があります。
レプリケーションを監視するための主要なメトリックは、ラグとレプリケーションの状態です。最も一般的な問題は、ネットワーキングの問題、ハードウェアリソースの問題、または寸法の問題です。レプリケーションの問題に直面している場合は、高可用性環境を確保するために修正する必要があるため、このことをできるだけ早く知る必要があります。
データ損失の回避は基本的なDBAタスクの1つであるため、バックアップを取る必要があるだけでなく、バックアップが完了したかどうか、およびバックアップが使用可能かどうかを知る必要があります。通常、この最後の点は考慮されませんが、バックアッププロセスでおそらく最も重要なチェックです。
FATALやデッドロックなどのエラー、または認証の問題や長時間実行されるクエリなどの一般的なエラーについても、データベースログを監視する必要があります。ほとんどのエラーはログファイルに書き込まれ、それを修正するための詳細な有用な情報が含まれています。
可視性は、問題を迅速に検出するのに役立ちます。グラフを見るよりも、コマンド出力を読み取る方が間違いなく時間のかかる作業です。したがって、ダッシュボードの使用法は、現在の問題の検出と今後15分間の問題の検出の違いになる可能性があり、会社にとって時間が非常に重要になる可能性があります。
各問題に関する通知を受け取らなければ、システムを監視するだけでは意味がありません。警告システムがない場合は、監視ツールにアクセスしてすべてが正常かどうかを確認する必要があります。何時間も前から大きな問題が発生している可能性があります。
ClusterControlを使用したPostgreSQLデータベースの監視
PostgreSQLに必要なすべてのメトリックを監視するツールを見つけることは非常に困難です。一般に、複数を使用する必要があり、スクリプトを作成する必要があります。監視とアラートのタスクを一元化する1つの方法は、ClusterControlを使用することです。これは、バックアップ管理、監視とアラート、展開とスケーリング、自動回復、およびデータベースの管理に役立つより重要な機能などの機能を提供します。同じシステム上のこれらすべての機能。
ClusterControlには、最も一般的なメトリックのいくつかを分析するための、事前定義されたダッシュボードのセットがあります。
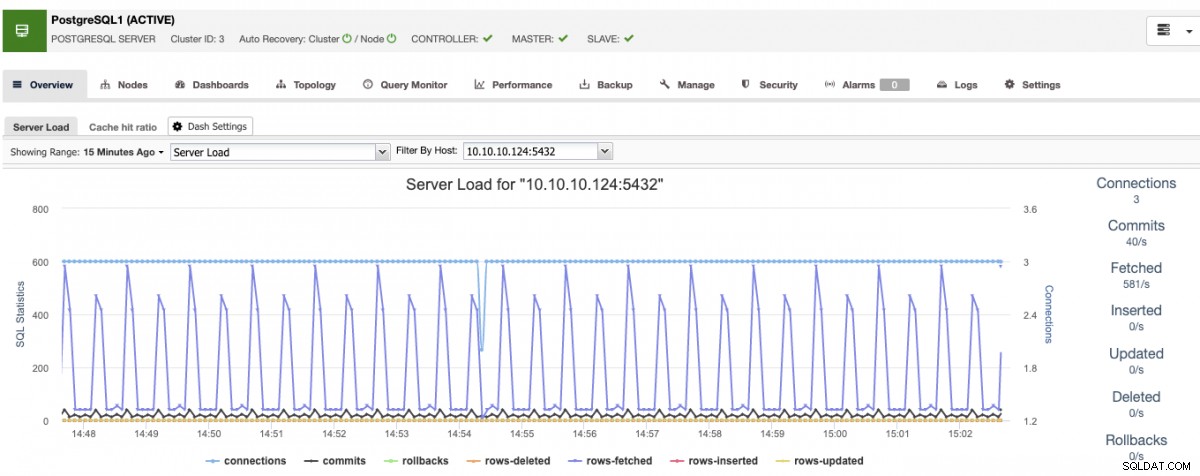
クラスターで使用可能なグラフをカスタマイズでき、次のことができます。エージェントベースの監視を有効にして、より詳細なダッシュボードを生成します。
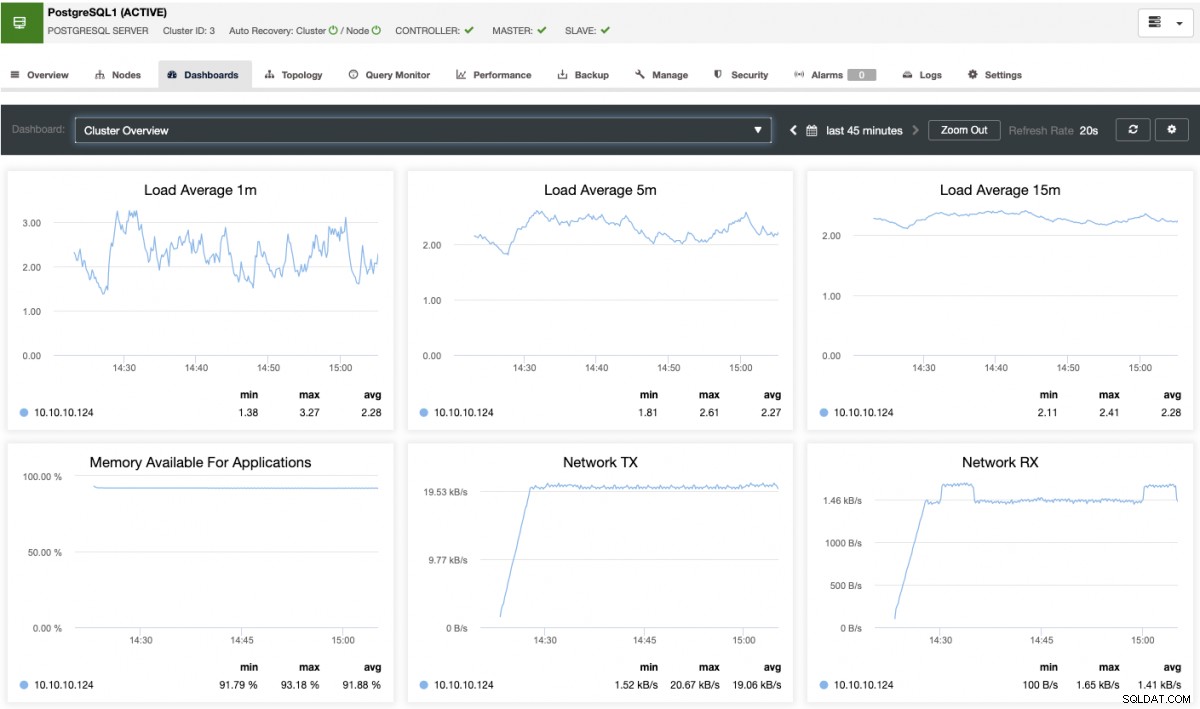
クラスター内のイベントを通知するアラートを作成することもできますが、または、PagerDutyやSlackなどのさまざまなサービスと統合します。
また、クエリモニターセクションを確認できます。上位のクエリ、実行中のクエリ、クエリの外れ値、およびクエリの統計。
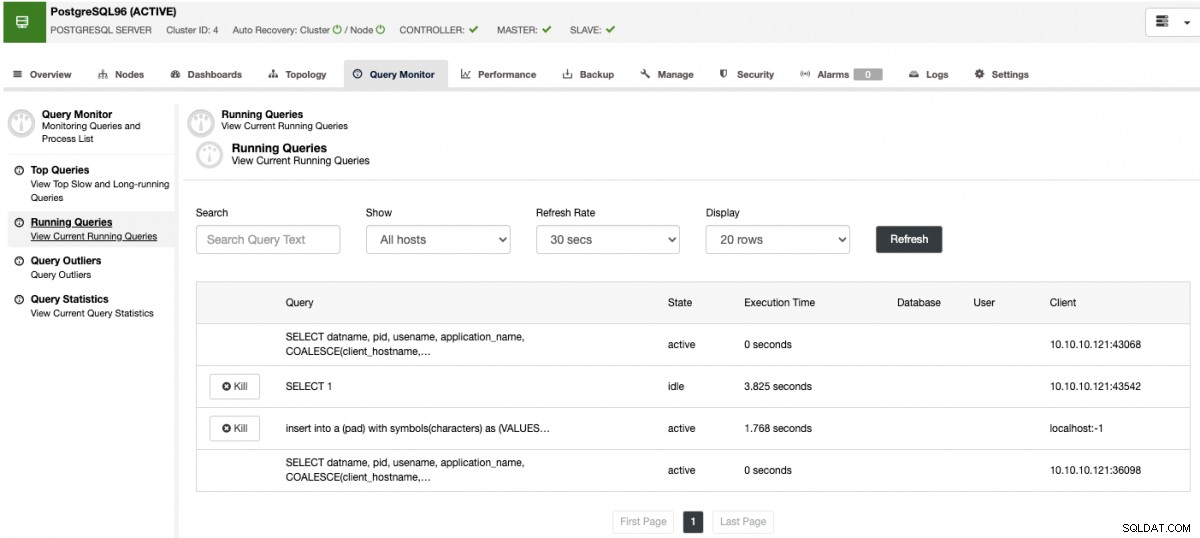
これらの機能を使用すると、PostgreSQLデータベースの状態を確認できます。
バックアップ管理の場合、ClusterControlはデータを一元化して保護、保護、およびリカバリします。検証バックアップ機能を使用すると、バックアップが適切かどうかを確認できます。
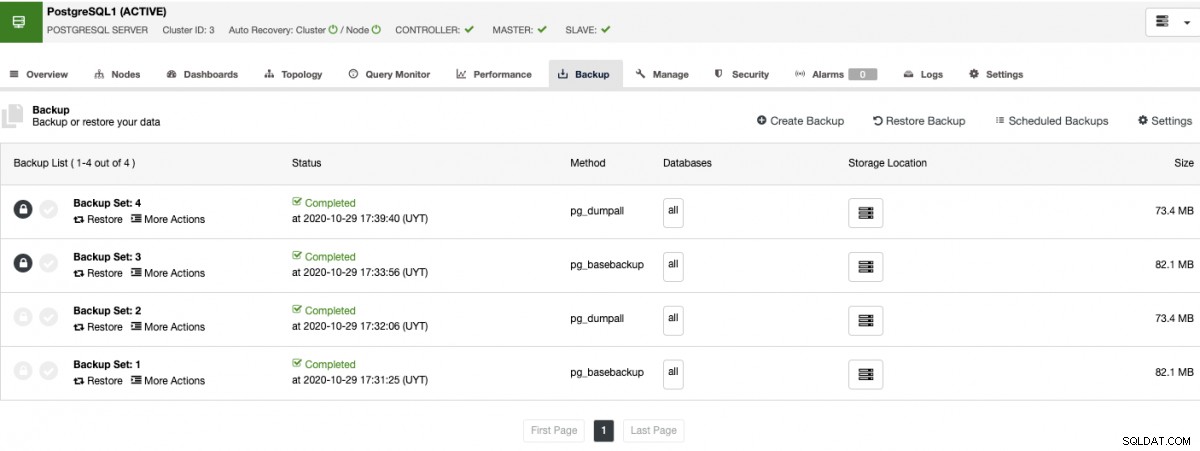
この検証バックアップジョブは、別のスタンドアロンホストにバックアップを復元します。バックアップが機能していることを確認できます。
ClusterControlコマンドラインを使用した監視
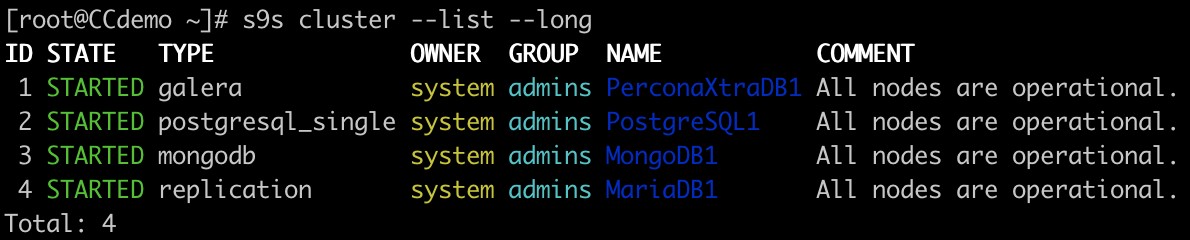
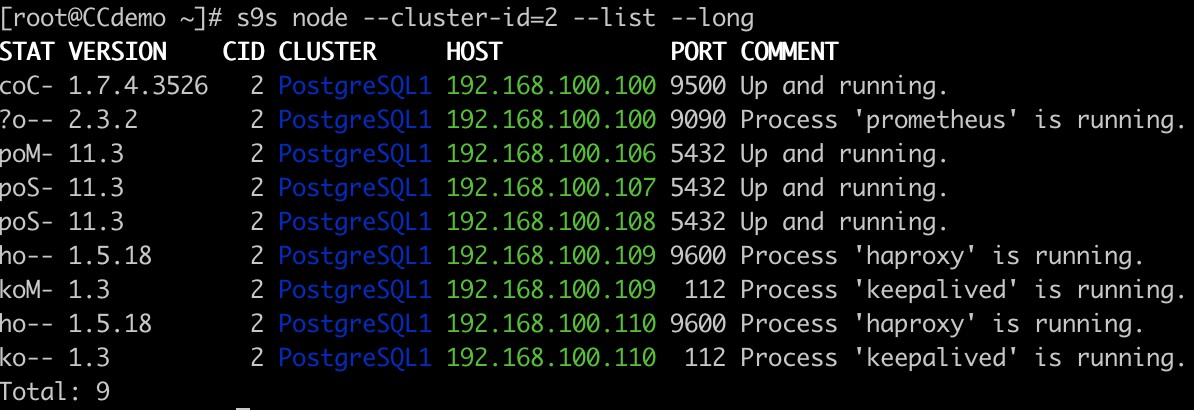
タスクのスクリプト作成と自動化、またはコマンドラインだけを使用する場合でも、ClusterControlにはs9sツールがあります。これは、データベースクラスターを管理するためのコマンドラインツールです。
監視は絶対に必要であり、監視を行うための最善の方法は、インフラストラクチャとシステム自体によって異なります。このブログでは、PostgreSQL用のPercona Distributionを紹介し、PostgreSQL環境で監視するいくつかの重要なメトリックについて説明しました。また、ClusterControlがこのタスクにどのように役立つかについても説明しました。