高可用性は、使用しているテクノロジーに関係なく、多くのシステムの要件です。これは、アプリケーションが依存するデータを格納するデータベースにとって特に重要です。要件に応じて、PostgreSQLの高可用性環境を展開するさまざまな方法がありますが、ネイティブのPostgreSQL機能では不十分であるため、常に補完的なツールを使用する必要があります。
このブログでは、高可用性を実現するためにPostgreSQL用のPercona Distributionを展開する方法と、それを実行するために必要なツールの種類について説明します。
PostgreSQLのPerconaディストリビューション
これは、PostgreSQLデータベースシステムの管理を支援するツールのコレクションです。 PostgreSQLをインストールし、次のような重要な実用的なタスクを効率的に解決できるようにする拡張機能を選択することで、PostgreSQLを補完します。
- pg_repack :PostgreSQLデータベースオブジェクトを再構築します。
- pgaudit :標準のPostgreSQLログ機能を介して詳細なセッションまたはオブジェクト監査ログを提供します。
- pgBackRest :これはPostgreSQLのバックアップと復元のソリューションです。
- パトロニ :PostgreSQL用の高可用性ソリューションです。
- pg_stat_monitor :PostgreSQLの統計を収集して集約し、ヒストグラム情報を提供します。
PostgreSQLの高可用性
PostgreSQLの高可用性にはさまざまなアーキテクチャがありますが、最も一般的なのはマスタースレーブトポロジ(プライマリ-スタンバイ)を使用することです。これは、1つ以上のスタンバイノードを備えた1つのプライマリデータベースに基づいています。これらのスタンバイデータベースは、レプリケーションが同期であるか非同期であるかに応じて、プライマリと同期(またはほぼ同期)されたままになります。メインサーバーに障害が発生した場合、スタンバイにはメインサーバーのほぼすべてのデータが含まれ、すぐに新しいプライマリデータベースサーバーに変えることができます。
ただし、障害を処理する必要があるため、マスタースレーブのセットアップでは高可用性を効果的に確保するのに十分ではありません。障害が検出されると、スタンバイノードを選択して、可能な限り短い遅延でフェイルオーバーできるようになります。 PostgreSQL自体には自動フェイルオーバーメカニズムが含まれていないため、この自動化にはカスタムスクリプトまたはサードパーティツールが必要になります。
フェイルオーバーが発生した後、アプリケーションはそれに応じて通知を受ける必要があります。これにより、アプリケーションは新しいプライマリノードの使用を開始できます。また、フェイルオーバー後のアーキテクチャの状態を評価する必要があります。これは、新しいプライマリのみが実行されている状況(つまり、問題が発生する前にプライマリとスタンバイノードが1つしかない状況)で実行できるためです。その場合、高可用性のために元々持っていたマスタースレーブセットアップを再作成するために、何らかの方法で新しいスタンバイノードを追加する必要があります。
これを機能させるには、このタスクを支援するさまざまなツール/サービスが必要になります。
ロードバランサーは、アプリケーションからのトラフィックを管理してデータベースアーキテクチャを最大限に活用するために使用できるツールです。
データベースの負荷を分散するのに役立つだけでなく、アプリケーションを使用可能な/正常なノードにリダイレクトしたり、異なる役割のポートを指定したりするのにも役立ちます。
HAProxyは、1つの発信元から1つ以上の宛先にトラフィックを分散し、このタスクの特定のルールやプロトコルを定義できるロードバランサーです。いずれかの宛先が応答を停止すると、オフラインとしてマークされ、トラフィックは残りの利用可能な宛先に送信されます。
Keepalivedは、サーバーのアクティブ/パッシブグループ内で仮想IPを構成できるようにするサービスです。この仮想IPはアクティブサーバーに割り当てられます。このサーバーに障害が発生した場合、IPは自動的に「セカンダリ」パッシブサーバーに移行され、システムに対して透過的な方法で同じIPを引き続き使用できるようになります。
これらすべてを実装するには、手動で実行できます。これは、余分な作業と時間のかかるタスクを意味します。または、ClusterControlを使用して1つのシステムから実行することもできます。
既存のPostgreSQL用PerconaディストリビューションをClusterControlにインポートする方法と、HAProxyとKeepalivedを使用して、使いやすく使いやすいインターフェイスからこのセットアップを中心に高可用性環境を構成する方法を見てみましょう。
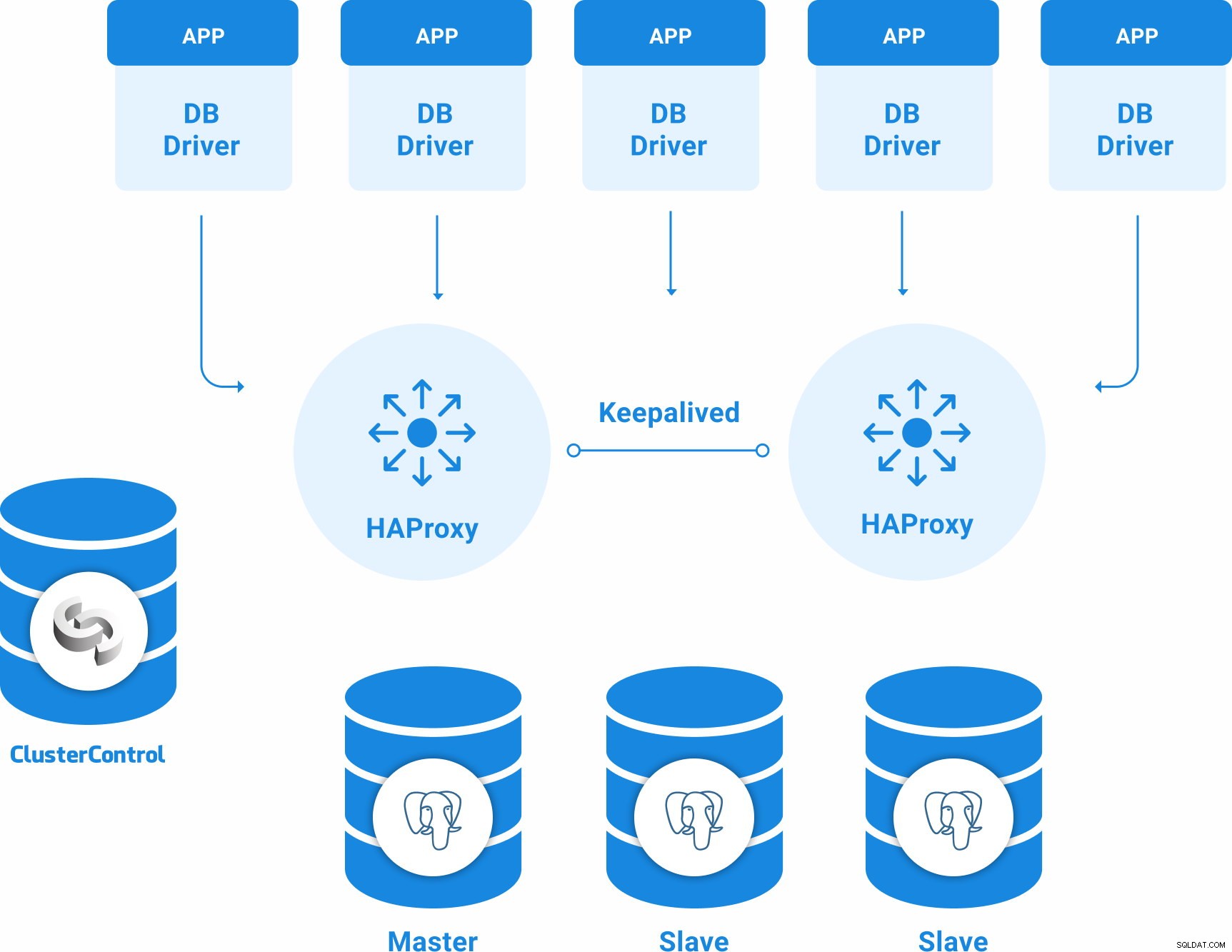
>PostgreSQLの基本的な高可用性トポロジは次のとおりです。
- 3台のPostgreSQL12サーバー(1台のプライマリノードと2台のスタンバイノード)。
- 2つのHAProxyロードバランサー。
- 1つのClusterControlサーバー
したがって、次のトポロジになります。
PostgreSQL用のPerconaディストリビューションをインストールする方法
PostgreSQL用のPerconaディストリビューションをインストールすることから始めましょう。この例では、CentOS7とPostgreSQL12を使用します。
クラスタがインストールされている場合は、次のセクションに進んで、既存のデータベースをClusterControlにインポートします。
epel-releaseとpercona-releaseをインストールする
$ yum install epel-release
$ yum install https://repo.percona.com/yum/percona-release-latest.noarch.rpmPostgreSQL12リポジトリを有効にする
$ percona-release setup ppg-12
* Disabling all Percona Repositories
* Enabling the Percona Distribution for PostgreSQL 12 repository
<*> All done!サーバーパッケージをインストールする
$ yum install percona-postgresql12-serverこのパッケージでは、すべてのPerconaディストリビューションコンポーネントがインストールされるわけではないことに注意してください。これらのコンポーネントをインストールするには、以下に示す適切なオプションのパッケージを使用してください。
$ yum install percona-pg_repack12
$ yum install percona-pgaudit
$ yum install percona-pgbackrest
$ yum install percona-patroni
$ yum install percona-pg-stat-monitor12
$ yum install percona-postgresql12-contribデータベースを初期化する
$ /usr/pgsql-12/bin/postgresql-12-setup initdb
Initializing database ... OK次のように、PostgreSQLレプリケーションを構成できるように正しい構成になっていることを確認してください。
$ vi /var/lib/pgsql/12/data/postgresql.conf
listen_addresses = '*'
wal_level=logical
max_wal_senders = 16
wal_keep_segments = 32
hot_standby = on次に、データベースサービスを開始します
$ systemctl start postgresql-12ここで、スタンバイノードを追加する場合は、クラスターに追加するすべてのノードで手順1、2、および3を繰り返します。これらのノードの場合、ClusterControlが対応する構成を作成するため、他に何も構成する必要はありません。
ClusterControlでPostgreSQL用のPerconaディストリビューションをインポートする
ClusterControlを使用すると、同じシステムからさまざまなオープンソースデータベースエンジンをデプロイまたはインポートできます。SSHアクセスと特権ユーザーのみが使用できます。
[インポート]セクションに移動して、PostgreSQLサーバーに必要な情報を入力します。
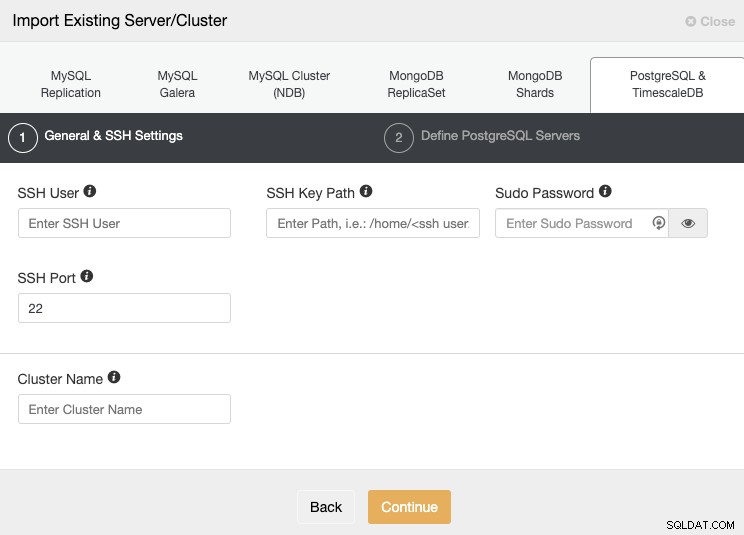
SSHで接続するには、ユーザー、キーまたはパスワード、およびポートを指定する必要がありますあなたのサーバーに。新しいクラスターの名前も必要です。名前がない場合、ClusterControlによって一般的な名前が割り当てられます。
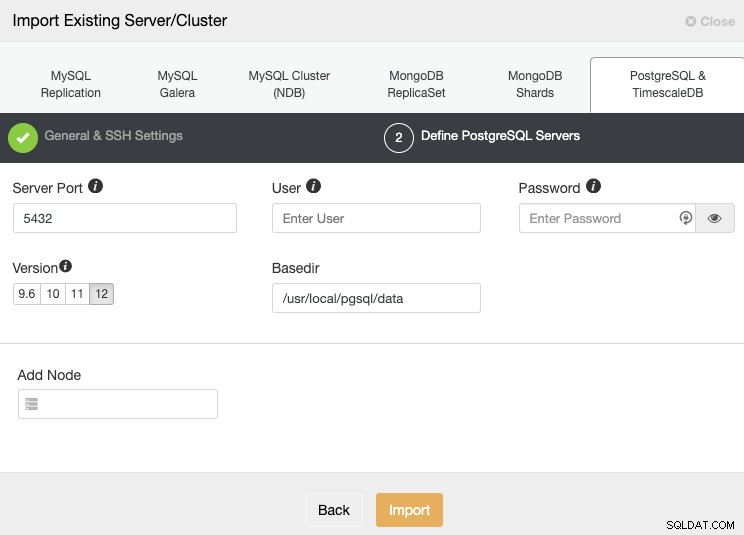
SSHアクセス情報を設定した後、データベースの資格情報を定義する必要があります。バージョン、basedir、および各データベースノードのIPアドレスまたはホスト名。
レプリケーションをまだ構成していない場合は、プライマリノードのIPアドレスまたはホスト名を追加するだけで済みます。これについては、後で残りのノードを追加する方法を説明します。
ホスト名またはIPアドレスを入力するときに緑色のチェックマークが表示されていることを確認してください。これは、ClusterControlがノードと通信できることを示します。次に、[インポート]ボタンをクリックし、ClusterControlがジョブを終了するまで待ちます。 ClusterControlアクティビティセクションでプロセスを監視できます。完了すると、ClusterControlのメイン画面に新しいクラスターが表示されます。新しいレプリカを追加するには、クラスターアクションに移動し、[レプリケーションスレーブの追加]オプションを選択します。
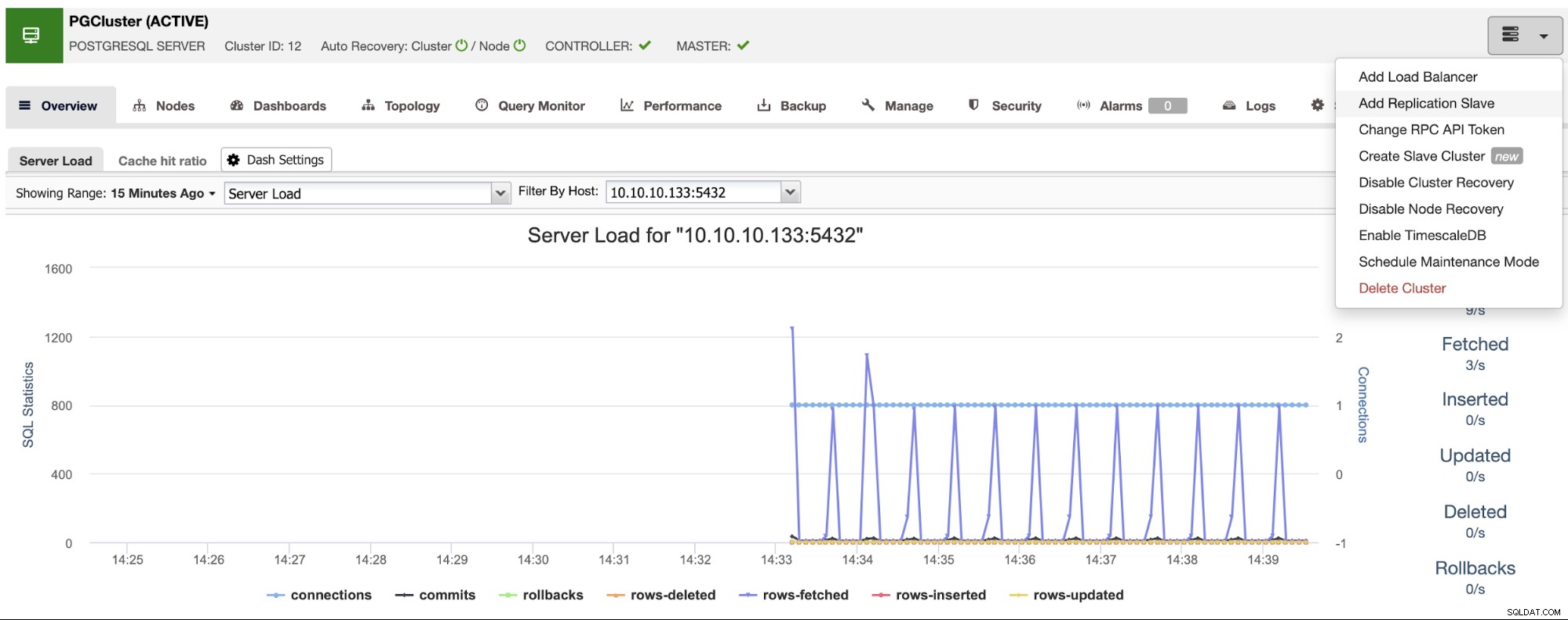
前の手順に従った場合、PostgreSQL用のPerconaディストリビューションがインストールされますすべてのスタンバイノードで、このセクションの「PostgreSQLソフトウェアのインストール」を無効にする必要があります。
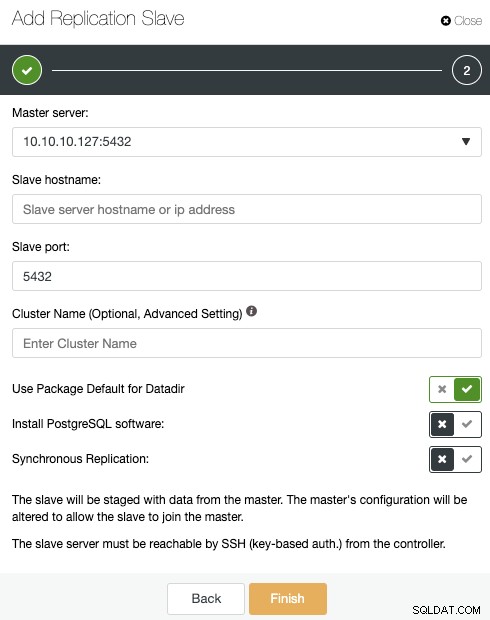
このように、ClusterControlはインストールされているPercona DistributionforPostgreSQLパッケージを代わりに使用します公式のPostgreSQLパッケージをインストールします。
これを完了すると、クラスター内のすべてのノードと、概要セクションにすべてのノードのステータスが表示されます。
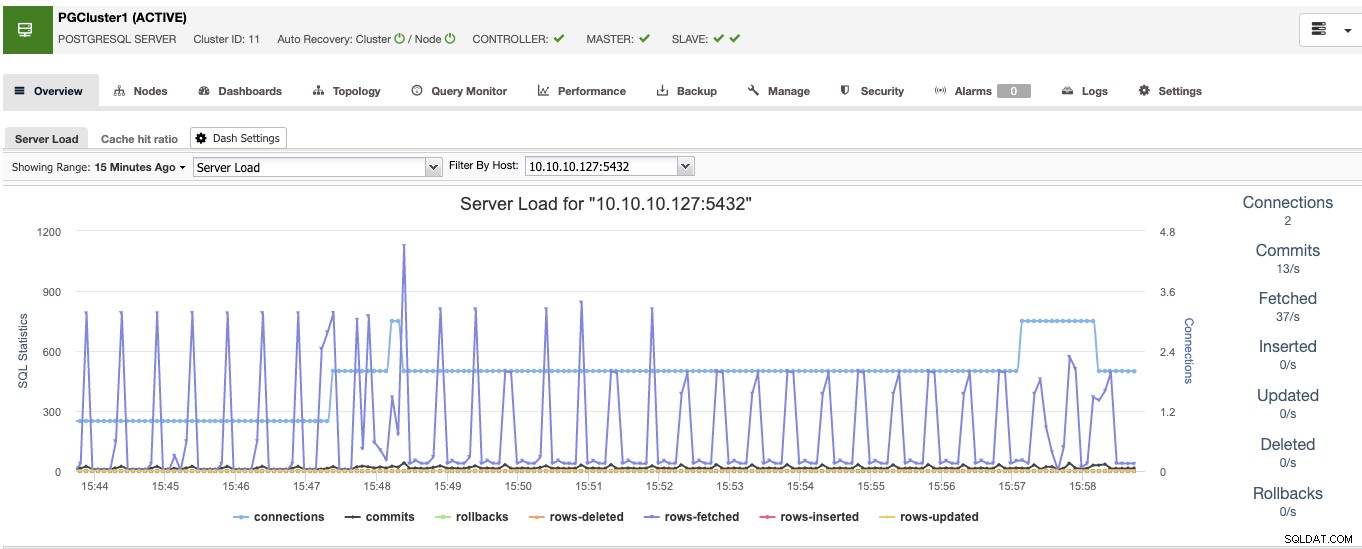
これでデータベース側の準備ができたので、高を完了する方法を見てみましょう。 ClusterControlを使用して残りのツールを追加することによる可用性環境。
ロードバランサーの展開を実行するには、クラスターアクションで[ロードバランサーの追加]オプションを選択し、要求された情報を入力します。 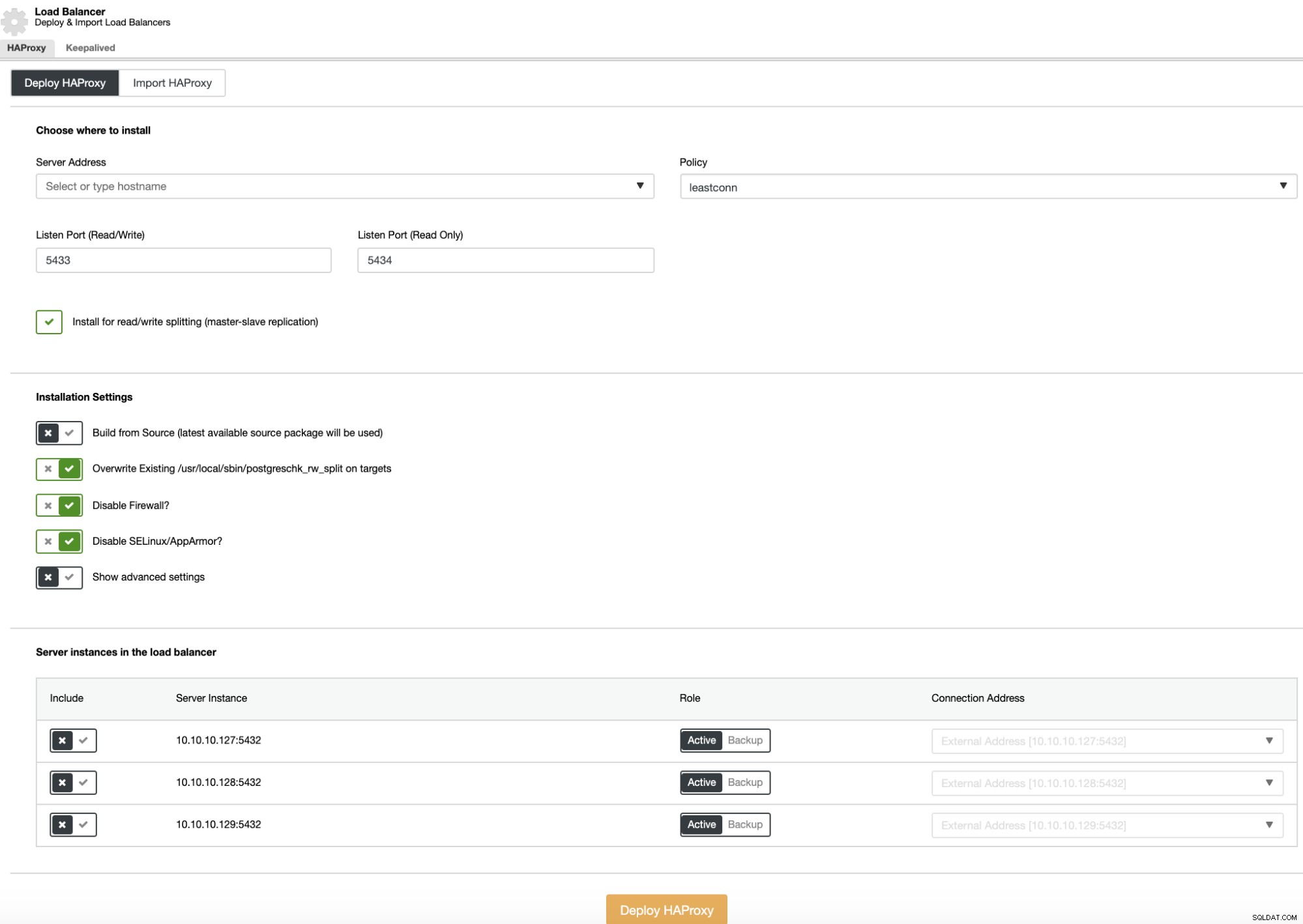
必要なのは、IPアドレスまたはホスト名、ポート、ポリシー、およびロードバランサー構成に追加するノードのみです。
キープアライブ展開を実行するには、クラスターを選択し、クラスターアクションに移動し、[ロードバランサーの追加]を選択してから、[キープアライブ]セクションに移動します。
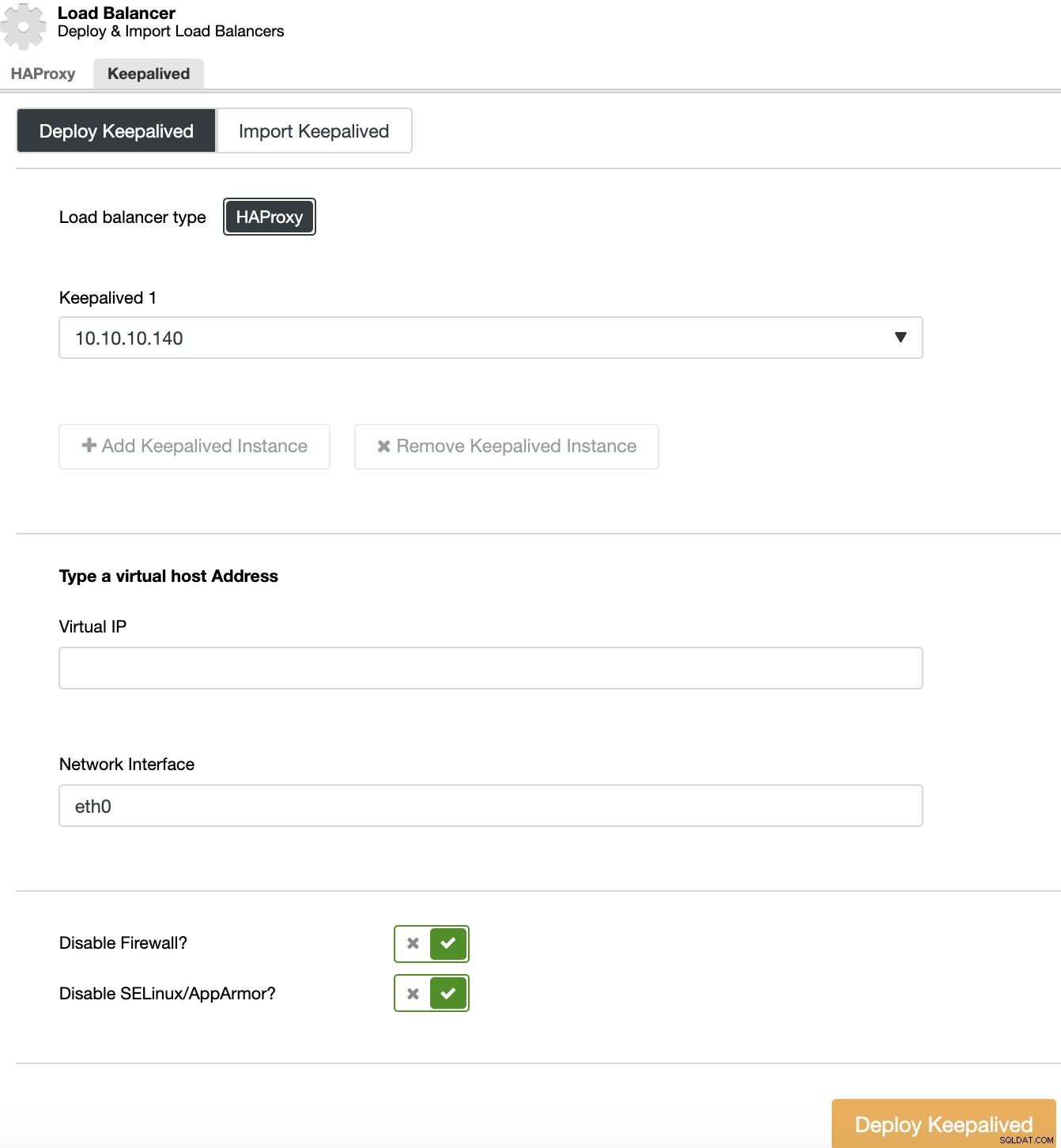
高可用性環境では、クラスターにアクセスするために使用する必要があるロードバランサーサーバーと仮想IPアドレスを選択する必要があります。 Keepalivedは、アクティブなロードバランサーでこの仮想IPを構成し、障害が発生した場合に1つのロードバランサーから別のロードバランサーに移行するため、セットアップは引き続き正常に機能します。
PostgreSQL用のPerconaDistributionをClusterControlから直接デプロイすることはまだできないため、このブログでは、ClusterControlを使用してそれを管理する方法と、HAProxyやKeepalivedなどのさまざまなツールを追加して高可用性環境を導入する方法を紹介しました。簡単な方法で。