情報技術の世界では、自動化は私たちのほとんどにとって新しいことではありません。実際、ほとんどの組織は、作業の種類や目的に応じて、さまざまな目的で使用しています。たとえば、データアナリストは自動化を使用してレポートを生成し、システム管理者は自動化を使用してディスクスペースのクリーニングなどの反復タスクを実行し、開発者は自動化を使用して開発プロセスを自動化します。
現在、DevOpsの時代のおかげで、IT向けの自動化ツールが多数利用可能であり、選択することができます。最高のツールはどれですか?答えは、私たちが達成しようとしていることや環境の設定に依存するため、予測可能な「依存する」です。自動化ツールには、Terraform、Bolt、Chef、SaltStackがあり、非常にトレンディなツールはAnsibleです。 Ansibleは、アプリケーションの展開、構成管理、ITオーケストレーションを自動化できるオープンソースのエージェントレスITエンジンです。 Ansibleは2012年に設立され、最も人気のある言語であるPythonで書かれています。プレイブックを使用してすべての自動化を実装し、すべての構成は人間が読める言語であるYAMLで記述されています。
本日の投稿では、Ansibleを使用してPostgresqlデータベースのデプロイを行う方法を学習します。
ansibleが主にその機能のために使用される理由。それらの機能は次のとおりです。
-
人間が読める形式の単純な言語YAMLを使用してすべてを自動化できます
-
リモートマシンにエージェントはインストールされません(エージェントレスアーキテクチャ)
-
構成はローカルマシンからローカルマシンからサーバーにプッシュされます(プッシュモデル)
-
Python(現在使用されている人気のある言語の1つ)を使用して開発され、多くのライブラリを選択できます
-
RedHadエンジニアリングチームによって慎重に選択されたAnsibleモジュールのコレクション
Ansibleがリモートホストに対して操作タスクを実行する前に、コントローラーノードとなる1つのホストにインストールする必要があります。このコントローラーノードでは、管理対象ノードとも呼ばれるリモートホストに対して実行するタスクを調整します。
コントローラーノードには、管理対象ノードのインベントリと、それを管理するためのAnsibleソフトウェアが必要です。管理対象ノードのホスト名やIPアドレスなど、Ansibleが使用する必要のあるデータは、このインベントリ内に配置されます。適切なインベントリがないと、Ansibleは自動化を正しく実行できませんでした。在庫の詳細については、こちらをご覧ください。
Ansibleはエージェントレスであり、SSHを使用して変更をプッシュします。つまり、すべてのノードにAnsibleをインストールする必要はありませんが、すべての管理対象ノードにpythonと必要なpythonライブラリがインストールされている必要があります。コントローラノードと管理対象ノードの両方をパスワードなしとして設定する必要があります。すべてのコントローラーノードと管理対象ノード間の接続は良好であり、適切にテストされていることに言及する価値があります。
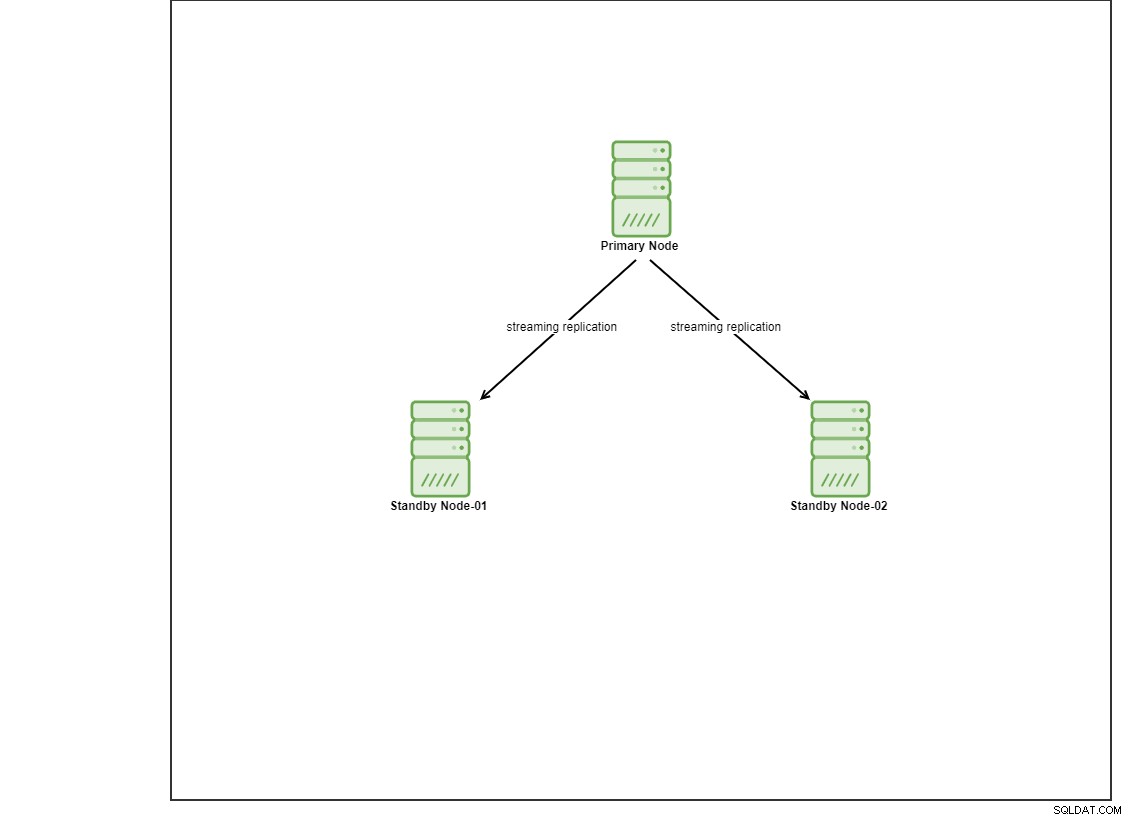
このデモでは、vagrantを使用して4つのCentos8VMをプロビジョニングしました。 1つはコントローラーノードとして機能し、他の2つのVMは展開されるデータベースノードとして機能します。このブログ投稿では、Ansibleのインストール方法の詳細については説明しませんが、ガイドをご覧になりたい場合は、このリンクにアクセスしてください。 3つのノードを使用して、1つのプライマリノードと2つのスタンバイノードを持つストリーミングレプリケーショントポロジを設定していることに注意してください。現在、多くの本番データベースは高可用性セットアップにあり、3ノードセットアップが一般的です。
PostgreSQLのインストール
Ansibleを使用してPostgreSQLをインストールする方法はいくつかあります。今日は、この目的を達成するためにAnsibleロールを使用します。一言で言えば、Ansibleロールは、サービスの構成などの特定の目的を果たすようにホストを構成するための一連のタスクです。 Ansibleロールは、AnsibleGalaxyポータルからダウンロードできる事前定義されたディレクトリ構造を持つYAMLファイルを使用して定義されます。
一方、Ansible Galaxyは、自動化プロジェクトを合理化するためにPlaybookに直接ドロップできるAnsibleロールのリポジトリです。
このデモでは、dudefellahによって維持されている役割を選択しました。この役割を利用するには、この役割をダウンロードしてコントローラーノードにインストールする必要があります。このタスクは非常に簡単で、Ansibleがコントローラーノードにインストールされている場合は、次のコマンドを実行することで実行できます。
$ ansible-galaxy install dudefellah.postgresqlロールがコントローラーノードに正常にインストールされると、次の結果が表示されます。
$ ansible-galaxy install dudefellah.postgresql
- downloading role 'postgresql', owned by dudefellah
- downloading role from https://github.com/dudefellah/ansible-role-postgresql/archive/0.1.0.tar.gz
- extracting dudefellah.postgresql to /home/ansible/.ansible/roles/dudefellah.postgresql
- dudefellah.postgresql (0.1.0) was installed successfully
この役割を使用してPostgreSQLをインストールするには、いくつかの手順を実行する必要があります。これがAnsiblePlaybookです。 Ansible Playbookは、管理対象ノードで実行するAnsibleコードまたはスクリプトのコレクションを記述できる場所です。 Ansible PlaybookはYAMLを使用し、特定の順序で実行される1つ以上のプレイで構成されます。ホストと、割り当てられたホストまたは管理対象ノードで実行する一連のタスクを定義できます。
すべてのタスクは、ログインしたansibleユーザーとして実行されます。「root」を含む別のユーザーでタスクを実行するために、becomeを利用できます。以下のpg-play.ymlを見てみましょう:
$ cat pg-play.yml
- hosts: pgcluster
become: yes
vars_files:
- ./custom_var.yml
roles:
- role: dudefellah.postgresql
postgresql_version: 13ご覧のとおり、ホストをpgclusterとして定義し、becomeを利用して、Ansibleがsudo特権でタスクを実行できるようにしました。ユーザーvagrantはすでにsudoerグループに含まれています。また、dudefellah.postgresqlをインストールした役割も定義しました。 pgclusterは、私が作成したhostsファイルで定義されています。どのように見えるか疑問に思われる場合は、以下をご覧ください:
$ cat pghost
[pgcluster]
10.10.10.11 ansible_user=ansible
10.10.10.12 ansible_user=ansible
10.10.10.13 ansible_user=ansibleそれに加えて、実装したいPostgreSQLのすべての構成と設定を含む別のカスタムファイル(custom_var.yml)を作成しました。カスタムファイルの詳細は次のとおりです。
$ cat custom_var.yml
postgresql_conf:
listen_addresses: "*"
wal_level: replica
max_wal_senders: 10
max_replication_slots: 10
hot_standby: on
postgresql_users:
- name: replication
password: example@sqldat.com
privs: "ALL"
role_attr_flags: "SUPERUSER,REPLICATION"
postgresql_pg_hba_conf:
- { type: "local", database: "all", user: "all", method: "trust" }
- { type: "host", database: "all", user: "all", address: "0.0.0.0/0", method: "md5" }
- { type: "host", database: "replication", user: "replication", address: "0.0.0.0/0", method: "md5" }
- { type: "host", database: "replication", user: "replication", address: "127.0.0.1/32", method: "md5" }インストールを実行するには、次のコマンドを実行するだけです。プレイブックファイル(私の場合はpg-play.yml)を作成しないと、ansible-playbookコマンドを実行できません。
$ ansible-playbook pg-play.yml -i pghostこのコマンドを実行すると、ロールによって定義されたいくつかのタスクが実行され、コマンドが正常に実行された場合は次のメッセージが表示されます。
PLAY [pgcluster] *************************************************************************************
TASK [Gathering Facts] *******************************************************************************
ok: [10.10.10.11]
ok: [10.10.10.12]
TASK [dudefellah.postgresql : Load platform variables] ***********************************************
ok: [10.10.10.11]
ok: [10.10.10.12]
TASK [dudefellah.postgresql : Set up role-specific facts based on some inputs and the OS distribution] ***
included: /home/ansible/.ansible/roles/dudefellah.postgresql/tasks/role_facts.yml for 10.10.10.11, 10.10.10.12ansibleがタスクを完了したら、スレーブ(n2)にログインし、PostgreSQLサービスを停止し、データディレクトリ(/ var / lib / pgsql / 13 / data /)の内容を削除します。次のコマンドを実行して、バックアップタスクを開始します。
$ sudo -u postgres pg_basebackup -h 10.10.10.11 -D /var/lib/pgsql/13/data/ -U replication -P -v -R -X stream -C -S slaveslot1
10.10.10.11 is the IP address of the master. We can now verify the replication slot by logging into the master:
$ sudo -u postgres psql
postgres=# SELECT * FROM pg_replication_slots;
-[ RECORD 1 ]-------+-----------
slot_name | slaveslot1
plugin |
slot_type | physical
datoid |
database |
temporary | f
active | t
active_pid | 63854
xmin |
catalog_xmin |
restart_lsn | 0/3000148
confirmed_flush_lsn |
wal_status | reserved
safe_wal_size |PostgreSQLサービスを再開した後、次のコマンドを使用して、スタンバイ状態のレプリケーションのステータスを確認することもできます。
$ sudo -u postgres psql
postgres=# SELECT * FROM pg_stat_wal_receiver;
-[ RECORD 1 ]---------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
pid | 229552
status | streaming
receive_start_lsn | 0/3000000
receive_start_tli | 1
written_lsn | 0/3000148
flushed_lsn | 0/3000148
received_tli | 1
last_msg_send_time | 2021-05-09 14:10:00.29382+00
last_msg_receipt_time | 2021-05-09 14:09:59.954983+00
latest_end_lsn | 0/3000148
latest_end_time | 2021-05-09 13:53:28.209279+00
slot_name | slaveslot1
sender_host | 10.10.10.11
sender_port | 5432
conninfo | user=replication password=******** channel_binding=prefer dbname=replication host=10.10.10.11 port=5432 fallback_application_name=walreceiver sslmode=prefer sslcompression=0 ssl_min_protocol_version=TLSv1.2 gssencmode=prefer krbsrvname=postgres target_session_attrs=anyご覧のとおり、一部のタスクを自動化したにもかかわらず、PostgreSQLのレプリケーションをセットアップするには多くの作業を行う必要があります。 ClusterControlを使用してこれを実現する方法を見てみましょう。
ClusterControlGUIを使用したPostgreSQLの展開
Ansibleを使用してPostgreSQLをデプロイする方法がわかったので、ClusterControlを使用してデプロイする方法を見てみましょう。 ClusterControlは、MySQL、MariaDB、MongoDB、TimescaleDBなどのデータベースクラスター用の管理および自動化ソフトウェアです。これは、データベースクラスターの展開、監視、管理、およびスケーリングに役立ちます。データベースをデプロイする方法は2つあります。このブログ投稿では、ご使用の環境にClusterControlが既にインストールされていることを前提として、グラフィカルユーザーインターフェイス(GUI)を使用してデータベースをデプロイする方法を示します。
最初のステップは、ClusterControlにログインし、[デプロイ]をクリックすることです。
展開の次のステップのために、以下のスクリーンショットが表示されます、続行するには[PostgreSQL]タブを選択してください:
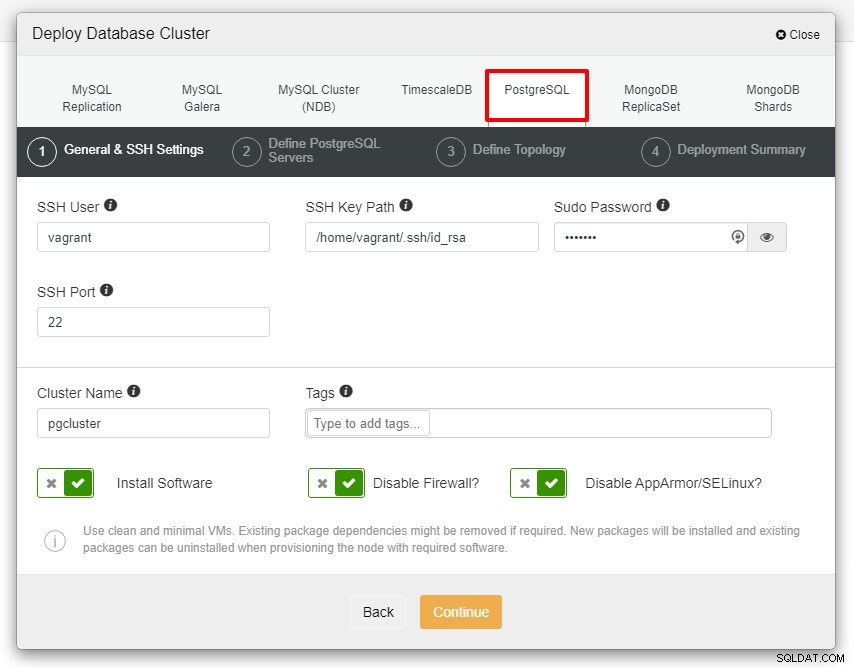
先に進む前に、ClusterControlノードとデータベースノード間の接続はパスワードなしである必要があることを思い出してください。デプロイする前に、ClusterControlノードからssh-keygenを生成し、それをすべてのノードにコピーするだけです。要件に応じて、SSHユーザー、Sudoパスワード、およびクラスター名の入力を入力し、[続行]をクリックします。
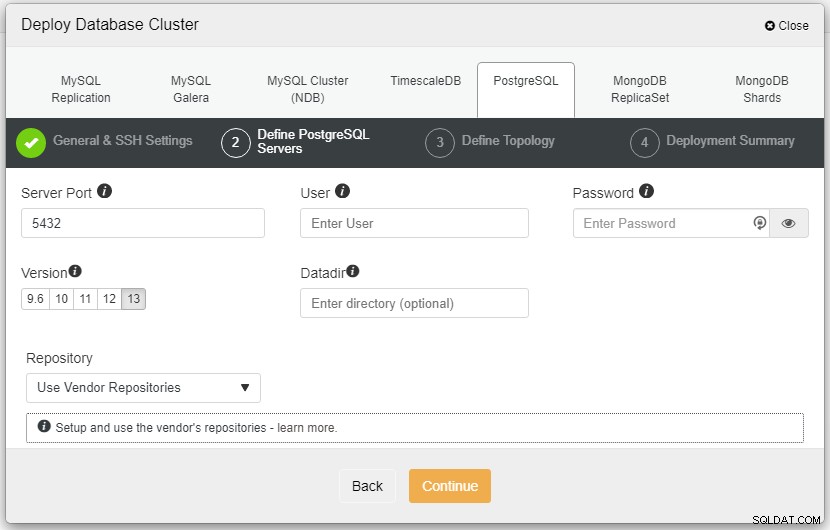
上のスクリーンショットでは、サーバーポート(他のユーザーを使用する場合)、使用するユーザー、パスワード、および必要なバージョンを定義する必要があります。インストールします。
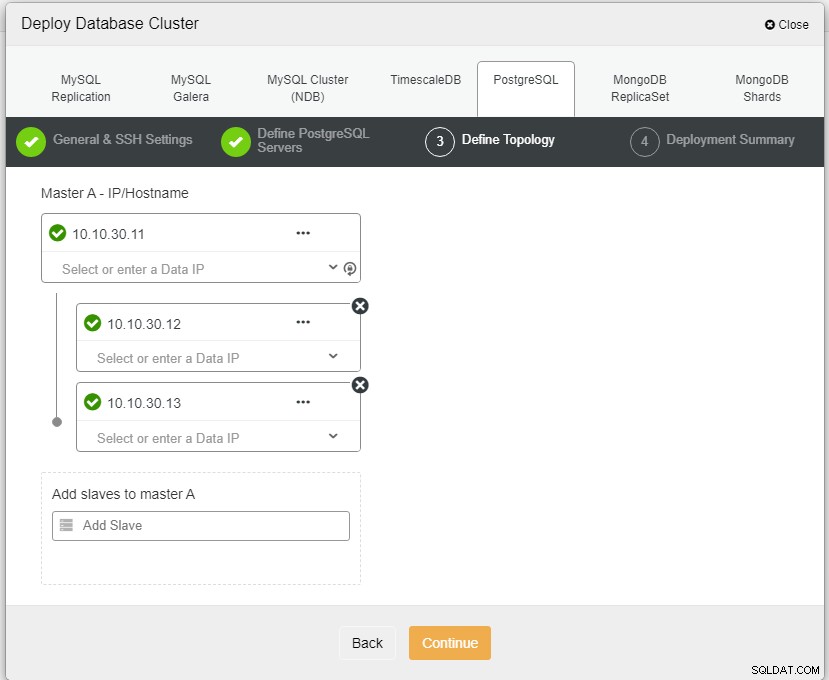
ここでは、ホスト名またはIPアドレスのいずれかを使用してサーバーを定義する必要があります。この場合は、1つのマスターと2つのスレーブです。最後のステップは、クラスターのレプリケーションモードを選択することです。
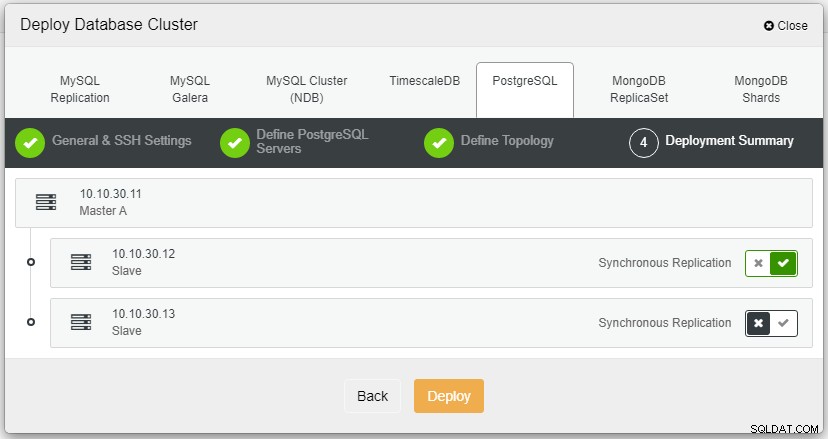
[展開]をクリックすると、展開プロセスが開始され、[アクティビティ]タブで進行状況を監視できます。
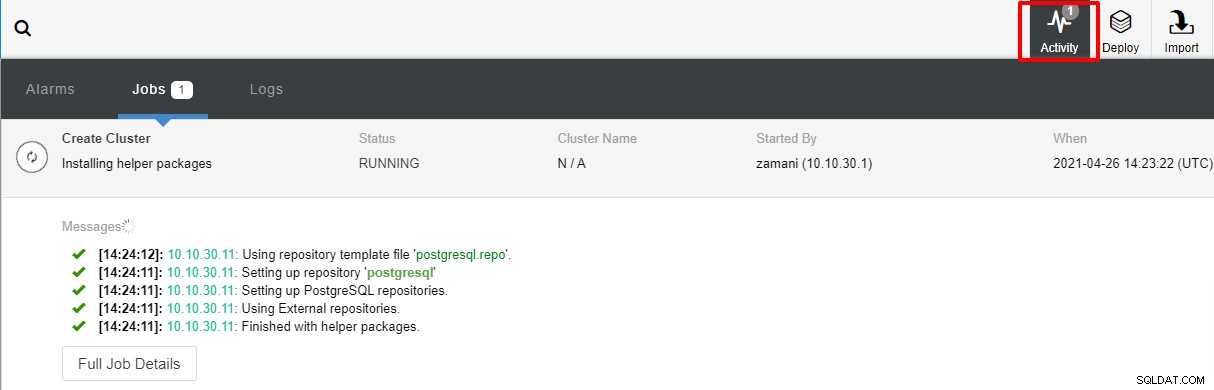
展開には通常数分かかります。パフォーマンスは、主にネットワークとサーバーの仕様によって異なります。

これで、ClusterControlを使用してPostgreSQLがインストールされました。
ClusterControlCLIを使用したPostgreSQLのデプロイ
PostgreSQLをデプロイするもう1つの方法は、CLIを使用することです。パスワードなしの接続をすでに構成している場合は、次のコマンドを実行して終了させることができます。
$ s9s cluster --create --cluster-type=postgresql --nodes="10.10.50.11?master;10.10.50.12?slave;10.10.50.13?slave" --provider-version=13 --db-admin="postgres" --db-admin-passwd="example@sqldat.com$$W0rd" --cluster-name=PGCluster --os-user=root --os-key-file=/root/.ssh/id_rsa --logプロセスが正常に完了し、ClusterControl Webにログインして確認できるようになると、以下のメッセージが表示されます。
...
Saving cluster configuration.
Directory is '/etc/cmon.d'.
Filename is 'cmon_1.cnf'.
Configuration written to 'cmon_1.cnf'.
Sending SIGHUP to the controller process.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Registering the cluster on the web UI.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Generated & set RPC authentication token.ご覧のとおり、PostgreSQLをデプロイする方法はいくつかあります。このブログ投稿では、AnsibleとClusterControlを使用してデプロイする方法を学びました。どちらの方法も簡単に理解でき、最小限の学習曲線で実現できます。 ClusterControlを使用すると、ストリーミングレプリケーションのセットアップをHAProxy、VIP、およびPGBouncerで補完して、接続フェイルオーバー、仮想IP、および接続プールをセットアップに追加できます。
デプロイメントは、実稼働データベース環境の1つの側面にすぎないことに注意してください。稼働を維持し、フェイルオーバーを自動化し、壊れたノードを回復し、監視、アラート、バックアップなどの他の側面が不可欠です。
このブログ投稿があなたの一部に有益であり、PostgreSQLの展開を自動化する方法についてのアイデアを提供することを願っています。