新しいデータベースを作成するときに何か考えますか?私たち全員がデフォルトのパラメータを使用しているので、ほとんどの人はノーと言うでしょうが、それらは最適とはほど遠いです。ただし、ディスク設定はたくさんあり、システムの信頼性とパフォーマンスを向上させるのに役立ちます。
データの信頼性に対するNTFSファイルシステムの重要性については説明しませんが、このファイルシステムを使用すると、MSSQLServerで最も効果的な方法でディスクを使用できます。
リソースが不足していて、何かが遅くなり始めた場合、最初に頭に浮かぶのはアップグレードです。ただし、すべての場合にアップグレードは必要ありません。サーバーの動作が遅くなり始めたときではなく、設計とインストールの段階で行う必要がありますが、調整は回避できます。
最適化は複雑なプロセスであり、特定のプログラム(この場合は特定のデータベース)だけでなく、OSやハードウェアにも関連していることがよくあります。私たちは主にデータベースについて話しますが、外見的なことを無視することはできません。
データアーキテクチャ
SQL Serverは、各8 KBのブロックごとにデータを格納、読み取り、および書き込みます。これらのブロックはページと呼ばれます。データベースは、1メガバイトあたり128ページを格納できます(1メガバイトまたは1048576バイトを8キロバイトまたは8192バイトで割ったもの)。すべてのページがエクステントに保存されます。エクステントは、最後の8つの連続したページまたは64KBです。したがって、1メガバイトには16個のエクステントが格納されます。
ページとエクステントは、SQLServerの物理データベース構造の基礎です。 MS SQL Serverはさまざまなページタイプを使用します。割り当てられたスペースを追跡するものもあれば、ユーザーデータとインデックスを含むものもあります。割り当てられたスペースを追跡するページには、高密度に圧縮されたデータが含まれています。これにより、MSSQLServerはそれらをメモリに効果的に保存して読みやすくすることができます。
SQL Serverは、次の2種類のエクステントを使用します。
- 2つから多数のオブジェクトのページを格納するエクステントは、混合エクステントと呼ばれます。各テーブルは、混合エクステントとして始まります。主にスペースを格納し、小さなオブジェクトを含むページに混合エクステントを使用します。
- 8ページすべてが1つのオブジェクトに割り当てられているエクステントは、均一エクステントと呼ばれます。テーブルまたはインデックスに64KB以上が必要な場合に使用されます。
各ファイルの最初のエクステントは統一されたものであり、ファイルヘッダーのページが含まれ、次のエクステントにはそれぞれ3つの割り当てられたページが含まれます。サーバーは、基本データファイルを作成するときにこれらの混合エクステントを割り当て、内部タスクにこれらのページを使用します。ファイルヘッダーページには、ファイルに保存されているデータベースの名前、ファイルグループ、最小サイズ、増分サイズなどのファイル属性が含まれています。これは、各ファイルの最初のページ(0ページ)です。
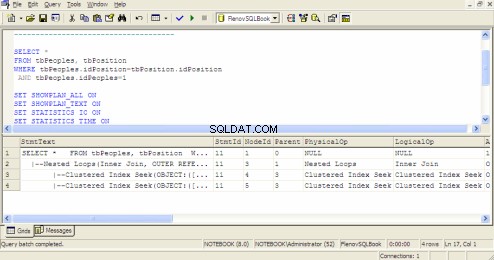
SQLクエリアナライザのクエリ実行プラン
ページの空き容量( PFS )ファイルで使用可能な空き領域に関する情報を含む割り当てられたページ。この情報はページ1に保存されます。このような各ページは、8000の連続したページに拡張できます。これは、約64Mbのデータです。
トランザクションログは、サーバーで行われた変更に関するすべての情報を収集して、システムエラーの瞬間にデータベースを復元し、データの整合性を確保します。
すべての数値は8または16の倍数であることに注意してください。これは、ハードディスクコントローラがこのサイズのデータをより簡単に読み取るためです。データはディスクからページ単位、つまり8キロバイト単位で読み取られます。これは非常に最適な値です。
ページ保護
MS SQL Server 2005と同様に、データベースサーバーには、ページレベルのデータ制御という新しいオプションがあります。 AGE_VERIFY_CHECKSUMの場合 パラメータが有効になっている場合(デフォルトで有効になっています)、サーバーがページのチェックサムを制御します。このパラメータのマニュアルを調べると、チェックサムにより、OSが追跡できない入出力エラーを追跡できることがわかります。それらはどのようなエラーですか?それらはデータベースサーバーの内部の問題のようです。
データの整合性チェックが失敗することはないため、有効にすることをお勧めします。このためには、次のコマンドを実行する必要があります。
ALTER DATABASE имя базы SET PAGE_VERIFY
ページにエラーがある場合、サーバーはそれについて通知します。しかし、どうすればそれをすばやく修正できますか?このためにページレベルでデータを復元するオプションがあります。
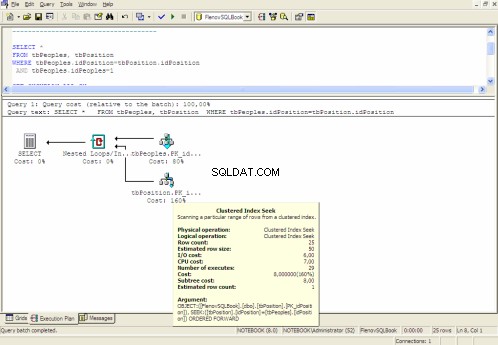
グラフィカル実行プラン
ファイルの増加
データベースを作成すると、初期サイズと増分方法を選択するように求められます。現在のスペースが不足すると、サーバーは事前設定された増分方法に対応してスペースを拡張します。
ファイルには3つのインクリメント方法があります:
- メガバイト単位の成長。
- 成長率。
- 手動による拡張。
最初の2つの方法は自動的に実行されますが、管理者はファイルサイズを制御できないため、テストデータベースにのみお勧めします。
ファイルが一定のメガバイト単位で増分されると、ある時点で、データ挿入の速度が向上し、ファイルの増大が頻繁になりすぎる可能性があり、これは余分なコストになります。パーセントで表したファイルの増加も不採算です。 10%のファイル増加を使用することをお勧めします。これは、中小規模のデータベースでは問題ありません。ただし、1000ギガバイトに達すると、成長ごとに100ギガバイトが必要になります。ディスクスペースの無駄になります。
ファイルとトランザクションログのサイズの変更は常に管理してください。これにより、ディスクリソースを最も効果的な方法で使用できるようになります。
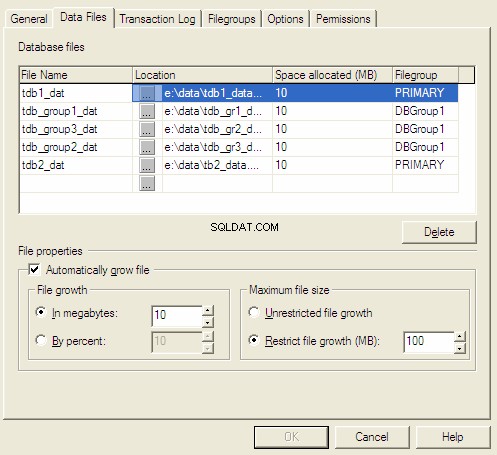
MSSQLServerデータベースのプロパティ
データ圧縮
ハードドライブは、コンピュータの賢明な場所のままです。プロセッサのパフォーマンスは大幅に向上しますが、ハードディスクは新しいものを提供できません。入出力操作の数を節約し、ハードディスクに保存されるデータを減らすために、圧縮されたディスクを使用できます。そのようなディスクだけが、読み取り専用のファイルグループを保存するのに適しています。おそらく、書き込みには圧縮が必要であり、追加のプロセッサコストが必要になるためです。
データ圧縮と読み取り専用状態は、アーカイブデータに適しています。たとえば、過去数年間の会計データは書き込みに必要ではなく、多くのスペースを占める可能性があります。ディスクのアーカイブセクションにデータを配置することで、スペースを大幅に節約できます。
信頼性のためのディスク
次の方法では、信頼性とパフォーマンスを同時に向上させることができます。これも、ハードドライブに関連しています。そうですね、メカニックは最も遅いだけでなく、最も信頼性が低いのです。信頼性については、統計を収集しませんでしたが、自宅と職場の両方で、主にハードドライブを扱っています。
したがって、パフォーマンスと信頼性を向上させるために、1台ではなく2台以上のハードドライブを使用することができます。それらを別々のコントローラーに接続するとさらに良いでしょう。データベースを1つのディスクに保存し、トランザクションログを別のディスクに保存できます。 3つ目のディスクがある場合は、システムを保存できます。
データとログを別々のディスクに保存すると、信頼性を大幅に向上させることができます。 1つのディスクにすべてがあり、それがダウンしたとします。何をすべきか?あなたはすべてを回復しようとするか、あなた自身で同じことをしようとする会社に到達することができますが、回復の可能性は100%にはほど遠いです。さらに、サーバーを仕事に戻すにはかなりの時間がかかる場合があります。高速リカバリは、最後のバックアップコピーの瞬間までしか実行できません。残りは疑わしいです。
そして今、異なるディスクにデータとトランザクションログがあると仮定します。ログのあるディスクがオフになっても、データはまだそこにあります。唯一のことは、新しいデータを追加できないことですが、新しいログを作成すると、作業を続行できます。
データのあるディスクがなくなった場合でも、トランザクションログを予約して、データの損失を最小限に抑えることができます。その後、完全なバックアップからデータを回復し(常に事前に実行する必要があります。優れた管理者は、これを少なくとも1日に1回実行します)、ログのバックアップコピーから変更を追加します。
パフォーマンスのためのディスク
データとログが別々のディスクにある場合、それは安全性だけでなくパフォーマンスの向上も意味します。重要なのは、データベースサーバーがログとデータファイルに同時にデータを書き込むことができるということです。
さらに進んで、1台のハードドライブをトランザクションログに割り当て、複数のハードドライブをデータに割り当てることができます。サーバーはデータをより頻繁に処理するため、同時に操作できる複数のストレージが必要です。また、これらのストレージが異なるコントローラーに接続されている場合、同時作業が保証されます。
最も高速で信頼性の高いバリアントは、 RAIDを使用することです。 。ただし、すべての RAIDが 信頼性が高く、同時に高速です。ファイルグループには、 RAID10を選択することをお勧めします 、バランスの取れた機能が含まれているため、データベースデータに応じて、別のバリアントを選択できます。
ソフトウェアまたはハードウェアソリューションをRAIDとして使用できます 。ソフトウェアソリューションの方が安価ですが、CPUの余分なリソースが必要になります。また、プロセッサには予備のリソースがありません。そのため、専用チップが RAIDを担当するハードウェアソリューションを使用することをお勧めします。 。
インデックス
インデックスがデータ検索速度の向上に役立つことは誰もが知っています。私たちのほとんどは、インデックスがデータの挿入と更新に悪影響を与えることを理解しています。したがって、インデックスが多いほど、サーバーがそれらを維持するのが難しくなります。その際、インデックスのメンテナンスが必要だと考える人はあまりいません。インデックスデータを含むデータベースページがオーバーフローし、最終的に不均衡になる可能性があります。
はい、さまざまなパラメータを無視して、月に1回インデックスを再作成するだけで済みます。これは、メンテナンスと同様です。 SQL Serverには、インデックスの作成後30分以内にインデックスが古くなるのを防ぐ2つのパラメーターが含まれています。 FILLFACTOR およびPAD_INDEX 。
FILLFACTORオプションを使用して、クラスター化インデックスまたは非クラスター化インデックスを含む挿入および更新操作のパフォーマンスを最適化できます。インデックスデータは多くのデータページに保存できます。前述したように、各ページは8KBで構成されています。インデックスページがいっぱいになると、サーバーは新しいページを作成し、データ挿入用のページを2つに分割します。
サーバーは、ページの分割と新しいページの作成に時間がかかります。ページ分割を最適化するには、 FILLFACTORを使用します インデックスページのすべてのリーフの空き領域の割合を決定するオプション。リーフレベルのページのディスク容量が大きいほど、インデックスページを分割する頻度が低くなります。その場合、インデックスツリーが大きくなりすぎて、バイパスに余分な時間がかかります。
PAD_INDEX オプションは、非リーフページの塗りつぶし率を示します。 PAD_INDEXを使用できます FILLFACTORの場合のみ PAD_INDEX のパーセンテージ値のため、オプションが指定されています FILLFACTORで指定されたパーセンテージによって異なります 。
統計
統計により、サーバーはインデックスの使用と完全なテーブルスキャンの間で正しい決定を下すことができます。鋳造所の従業員のリストがあるとします。そのようなリストは男性の約90%で構成されます。
ここで、すべての女性を見つける必要があるとします。それらの数は少ないので、最も効果的なオプションはインデックスを使用することです。しかし、すべての男性を見つける必要がある場合、インデックスの効率は低下します。選択されたレコードの数が多すぎるため、各レコードのインデックスツリーをバイパスするとオーバーヘッドが発生します。テーブル全体をスキャンする方がはるかに簡単です。サーバーは、すべてのレベルを何度も読み取る必要がなく、インデックスのすべての低レベルのリーフを1回読み取る必要があるため、実行がはるかに高速になります。
SQL Serverは、すべてのフィールド値を読み取るか、均一に分散およびソートされた値リストを作成するためのテンプレートを使用して、統計を収集します。 SQL Serverは、テーブル内の行数に基づいてテストする必要のある行の割合を動的に検出します。統計を収集するとき、クエリオプティマイザはフルスキャンまたは行テンプレートのいずれかを実行します。
統計を機能させるには、統計を作成する必要があります。大規模なデータ更新の場合、統計に誤ったデータが含まれている可能性があり、サーバーは誤った決定を下します。しかし、すべてを正しく行うことができます–統計を監視する必要があります。詳細については、Transact-SQLまたはMSSQLServerに関する書籍を参照してください。
概要
デフォルト設定では、ハードウェアの可能性をすべて使用することはできず、さまざまなサーバーで動作します。設定の責任は管理者にあります。 Microsoft製品には、簡単なインストールプログラム、グラフィカルな管理ユーティリティ、およびオフラインで動作する機能があるという事実は、これが最適なバリアントであることを意味するわけではありません。
ハードウェアアクセラレーションなどのデータベースチューニングオプションは考慮していません。すべてのチューニングオプションが使い果たされている場合は、ハードウェアアクセラレーションがシステムの信頼性に悪影響を与えるため、アップグレードについて検討することをお勧めします。
最も重要なことは、クエリが最適化されていない場合、データベースサーバーの最適化やアップグレードは役に立たないということです。