数年前(マドリードで開催されたpgconf.eu 2014で)、最近のPostgreSQLリリースでパフォーマンスがどのように変化したかを示す「パフォーマンス考古学」と呼ばれる講演を行いました。長期的な見方は興味深いものであり、非常に価値のある洞察を私たちに与えるかもしれないと思うので、私はその話をしました。私のように実際にPostgreSQLコードに取り組んでいる人にとっては、将来の開発に役立つガイドであり、PostgreSQLユーザーにとっては、アップグレードの評価に役立つ可能性があります。
そこで、この演習を繰り返して、PostgreSQLのいくつかのバージョンのパフォーマンスを分析するブログ投稿をいくつか書くことにしました。 2014年の講演では、PostgreSQL 7.4から始めました。その時点で、約10年前(2003年にリリース)でした。今回は、約12年前のPostgreSQL8.3から始めます。
PostgreSQL 7.4からもう一度始めてみませんか?私がPostgreSQL8.3から始めることにした主な理由は3つあります。まず、一般的な怠惰。バージョンが古いほど、現在のコンパイラバージョンなどを使用してビルドするのが難しくなる可能性があります。次に、特に大量のデータで適切なベンチマークを実行するには時間がかかるため、メジャーバージョンを1つ追加すると、マシン時間が数日長くなる可能性があります。それだけの価値はなかったようです。そして最後に、8.3では、自動真空の改善(デフォルトで有効、同時ワーカープロセスなど)、コアに統合された全文検索、スプレッドチェックポイントなど、いくつかの重要な変更が導入されました。したがって、PostgreSQL8.3から始めるのは完全に理にかなっていると思います。これは約12年前にリリースされたため、この比較は実際にはより長い期間をカバーします。
私は、OLTP、分析、全文検索の3つの基本的なワークロードタイプのベンチマークを行うことにしました。ほとんどのアプリケーションはこれら2つの基本的なタイプの組み合わせであるため、OLTPと分析はかなり明白な選択だと思います。全文検索により、JSONB、PostGISで使用されるタイプなどの一般的なデータタイプのインデックス作成にも使用される特殊なタイプのインデックスの改善を示すことができます。
なぜこれを行うのですか?
それは実際に努力する価値がありますか?結局のところ、パッチが役立つこと、および/またはそれがリグレッションを引き起こさないことを示すために、開発中に常にベンチマークを実行しますよね?問題は、これらは通常、2つの特定のコミットを比較する「部分的な」ベンチマークであり、通常、関連すると思われるワークロードの選択がかなり限られていることです。これは完全に理にかなっています。コミットごとにフルバッテリーのワークロードを実行することはできません。
たまに(通常、新しいPostgreSQLメジャーバージョンのリリース直後)、人々は新しいバージョンを前のバージョンと比較するテストを実行します。これは素晴らしいことであり、そのようなベンチマークを実行することをお勧めします(ある種の標準ベンチマーク、またはアプリケーションに固有の何か)。ただし、これらのテストでは異なる構成とハードウェア(通常は新しいバージョンではより新しいもの)などを使用するため、これらの結果を長期的なビューに組み合わせるのは困難です。そのため、一般的な変更について明確な判断を下すのは困難です。
もちろん、「究極のベンチマーク」であるアプリケーションのパフォーマンスにも同じことが当てはまります。ただし、すべてのメジャーバージョンにアップグレードするわけではありません(たとえば、9.5から12など、いくつかのバージョンをスキップする場合があります)。また、アップグレードすると、ハードウェアのアップグレードなどと組み合わされることがよくあります。言うまでもなく、アプリケーションは時間の経過とともに進化し(新機能、複雑さが増す)、データ量や同時ユーザー数が増加します。
これが、このブログシリーズが示していることです。いくつかの基本的なワークロードでのPostgreSQLパフォーマンスの長期的な傾向により、開発者は、長年にわたる優れた作業について温かく曖昧な気持ちになります。そして、PostgreSQLは現時点では成熟した製品ですが、すべての新しいメジャーバージョンにはまだ大幅な改善があることをユーザーに示すためです。
これらのベンチマークを他のデータベース製品との比較に使用したり、公式のランキング(TPC-Hなど)を満たす結果を生成したりすることは私の目標ではありません。私の目標は、PostgreSQL開発者として自分自身を教育し、問題を特定して調査し、その結果を他の人と共有することです。
公正な比較?
ソフトウェアは特定のコンテキストで開発されているため、12年以上にわたってリリースされたバージョンのそのような比較は、完全に公平ではないと思います。ハードウェアは、データベースシステムの良い例です。 12年前に使用したマシンを見ると、コアはいくつあり、RAMはどれくらいありますか?彼らはどのタイプのストレージを使用しましたか?
2008年の典型的なミッドレンジサーバーには、おそらく8〜12コア、16 GBのRAM、および2台のSASドライブを備えたRAIDがありました。今日の典型的なミッドレンジサーバーには、数十のコア、数百GBのRAM、SSDストレージが搭載されている可能性があります。
ソフトウェア開発は優先順位に従って編成されています。時間よりも潜在的なタスクが常に多いため、ユーザー(特に、プロジェクトに直接または間接的に資金を提供しているユーザー)にとって最適な費用便益比のタスクを選択する必要があります。また、2008年には、一部の最適化はおそらくまだ関連性がありませんでした。たとえば、ほとんどのマシンには極端な量のRAMがなかったため、大規模な共有バッファーの最適化はまだ価値がありませんでした。また、ほとんどのマシンには「回転する錆」ストレージがあったため、CPUのボトルネックの多くはI/Oによって影が薄くなりました。
注:もちろん、当時でもかなり大型のマシンを使用しているお客様がいました。コミュニティPostgresをさまざまな調整で使用したものもあれば、追加機能(大規模な並列処理、分散クエリ、FPGAの使用など)を備えたさまざまなPostgresフォークの1つで実行することを決定したものもあります。もちろん、これはコミュニティの発展にも影響を及ぼしました。
大型のマシンが長年にわたって一般的になるにつれて、より多くの人々が大量のRAMと高いコア数を備えたマシンを購入できるようになり、費用便益比が変化しました。ボトルネックが調査されて対処され、新しいバージョンのパフォーマンスが向上しました。
これは、このようなベンチマークが常に少し不公平であることを意味します。セットアップ(ハードウェア、構成)に応じて、古いバージョンまたは新しいバージョンのいずれかが優先されます。ただし、古いバージョンではそれほど悪くないように、ハードウェアと構成のパラメーターを選択しようとしました。
私が言いたいのは、これは古いPostgreSQLバージョンがくだらないという意味ではないということです。これがソフトウェア開発の仕組みです。 10年間に遭遇する可能性のあるボトルネックではなく、ユーザーが遭遇する可能性のあるボトルネックに対処します。
ハードウェア
直接アクセスできる物理ハードウェアでベンチマークを実行することを好みます。これにより、すべての詳細を制御したり、すべての詳細にアクセスしたりできるためです。ですから、私はオフィスにあるマシンを使用しました。派手なものは何もありませんが、この目的には十分であるといいのですが。
- 2x E5-2620 v4(16コア、32スレッド)
- 64GB RAM
- Intel Optane 900P 280GB NVMe SSD(データ)
- 3 x 7.2k SATA RAID0(一時表領域)
- カーネル5.6.15、ext4
- gcc 9.2.0、clang 9.0.1
また、4コアと8GBのRAMのみを備えた2台目の(はるかに小さい)マシンを使用しました。これは、一般的に同じ改善/回帰を示していますが、あまり目立たないものです。
pgbench
ベンチマークツールとして、よく知られているpgbenchを使用し、最新バージョン(PostgreSQL 13から)を使用してすべてのバージョンをテストしました。これにより、pgbenchで時間の経過とともに行われる最適化によるバイアスの可能性が排除され、結果がより比較可能になります。
ベンチマークでは、さまざまなケースをテストし、さまざまなパラメータをテストします。つまり、次のとおりです。
スケール
- 小さい–データは共有バッファに収まり、ロックの問題などを示します。
- 中–共有バッファーよりも大きいが、RAMに収まるデータ、通常はCPUバウンド(または読み取り/書き込みワークロードの場合はI / O)
- 大– RAMよりも大きいデータ、主にI/Oバウンド
モード
- 読み取り専用– pgbench -S
- 読み取り/書き込み– pgbench -N
クライアント数
- 1、4、8、16、32、64、128、256
- pgbenchスレッドの数(-j)はそれに応じて調整されます
結果
では、結果を見てみましょう。最初にNVMeストレージの結果を示し、次にSATARAIDストレージを使用した興味深い結果をいくつか示します。
NVMeSSD/読み取り専用
小さなデータセット(共有バッファーに完全に収まる)の場合、読み取り専用の結果は次のようになります。
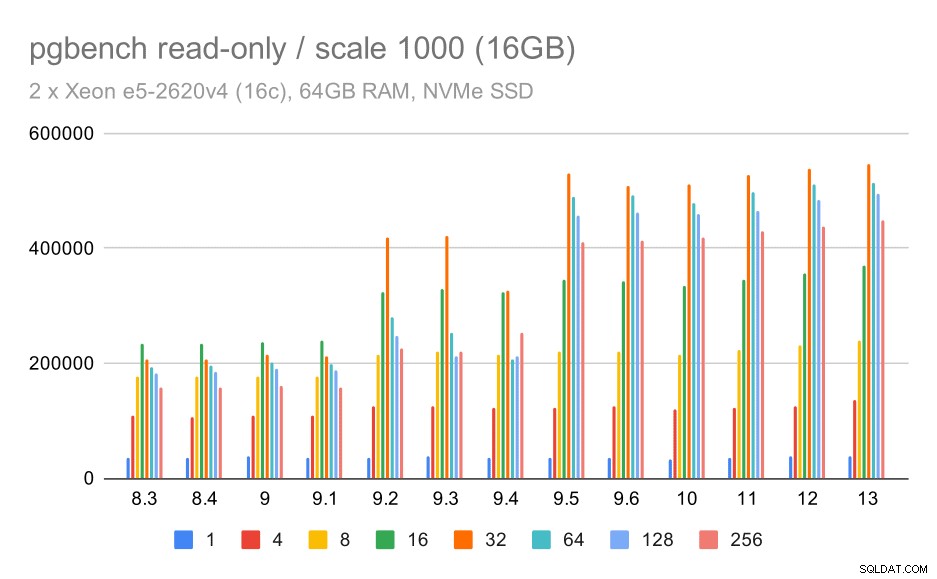
pgbenchの結果/小さなデータセット(スケール100、つまり1.6GB)での読み取り専用
明らかに、9.2ではスループットが大幅に向上しました。これには、ロックの高速パスなど、多くのパフォーマンスの向上が含まれていました。単一のクライアントのスループットは、実際には少し低下します–47ktpsからわずか約42ktpsになります。しかし、クライアント数が多い場合、9.2での改善はかなり明白です。
pgbenchの結果/中程度のデータセット(スケール1000、つまり16GB)で読み取り専用
中程度のデータセット(共有バッファよりも大きいがRAMに収まる)の場合、9.2でもある程度の改善があるようですが、上記ほど明確ではありませんが、ロックのスケーラビリティの改善により、9.5ではるかに明確な改善が続く可能性があります。 。
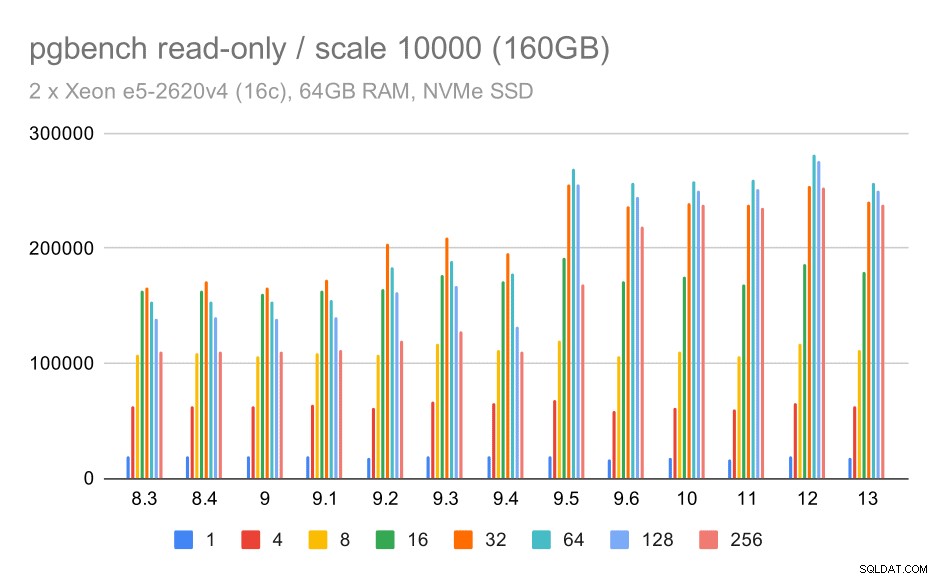
pgbenchの結果/大規模なデータセット(スケール10000、つまり160GB)での読み取り専用
大部分がストレージを効率的に利用する能力に関する最大のデータセットでは、ある程度のスピードアップもあります。おそらく9.5の改善のおかげです。
NVMeSSD/読み取り/書き込み
読み取り/書き込みの結果も、それほど顕著ではありませんが、いくつかの改善を示しています。小さなデータセットでは、結果は次のようになります。
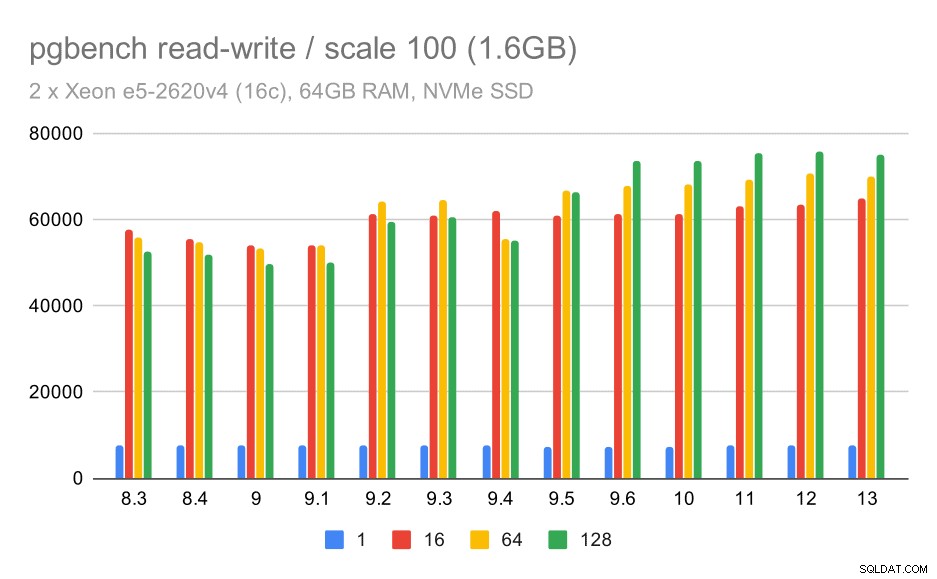
pgbenchの結果/小さなデータセット(スケール100、つまり1.6GB)での読み取り/書き込み
したがって、十分な数のクライアントを使用すると、約52kから75ktpsにわずかに改善されます。
中程度のデータセットの場合、改善ははるかに明確です。約27kから63k tpsになります。つまり、スループットは2倍以上になります。
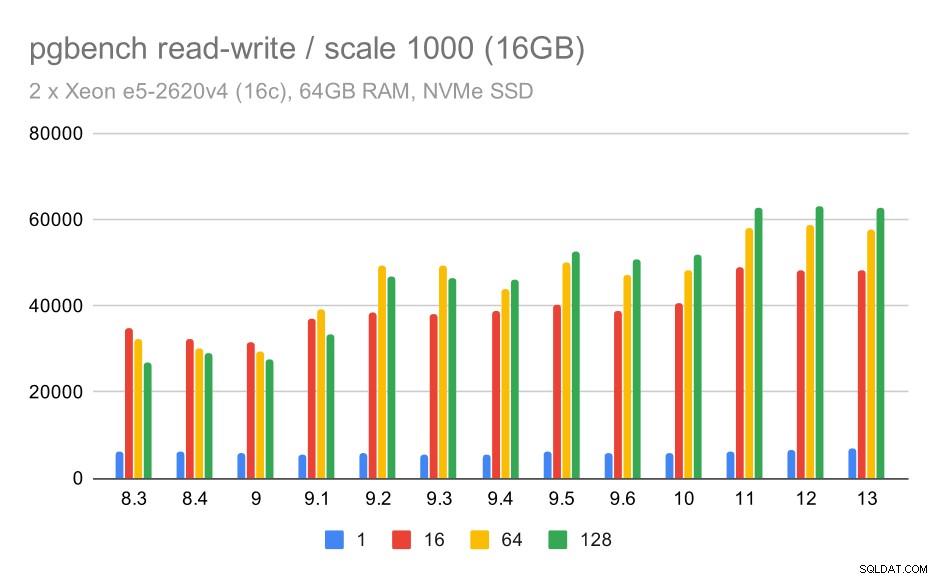
pgbenchの結果/中程度のデータセット(スケール1000、つまり16GB)での読み取り/書き込み
最大のデータセットについても、同様の全体的な改善が見られますが、9.5と11の間でいくらかの回帰があるようです。
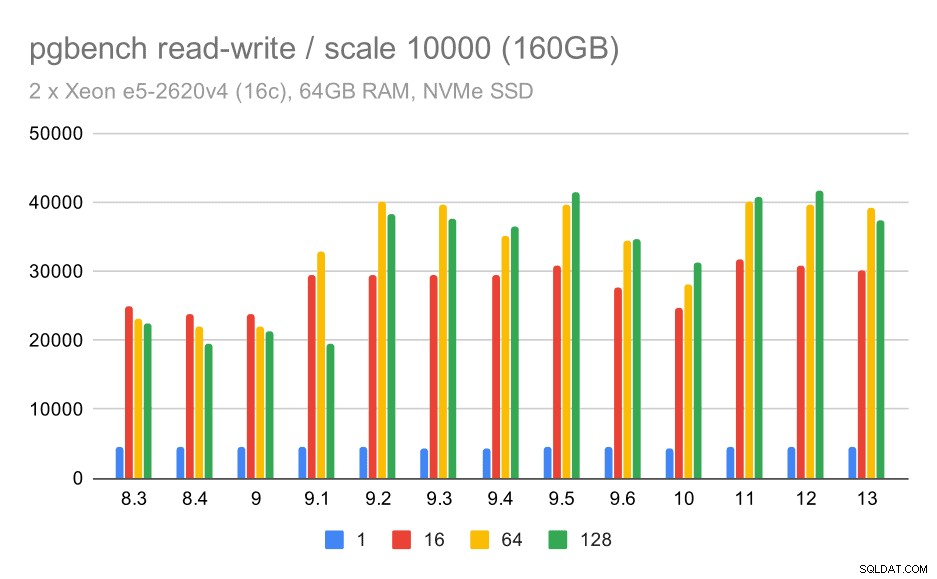
pgbenchの結果/大規模なデータセット(スケール10000、つまり160GB)での読み取り/書き込み
SATARAID/読み取り専用
SATA RAIDストレージの場合、読み取り専用の結果はそれほど良くありません。ストレージシステムが関係のない中小規模のデータセットは無視できます。大規模なデータセットの場合、スループットはややノイズが多くなりますが、実際には時間の経過とともに低下するようです。特にPostgreSQL9.6以降です。この理由はわかりませんが(9.6リリースノートには明確な候補として目立つものはありません)、ある種の回帰のようです。
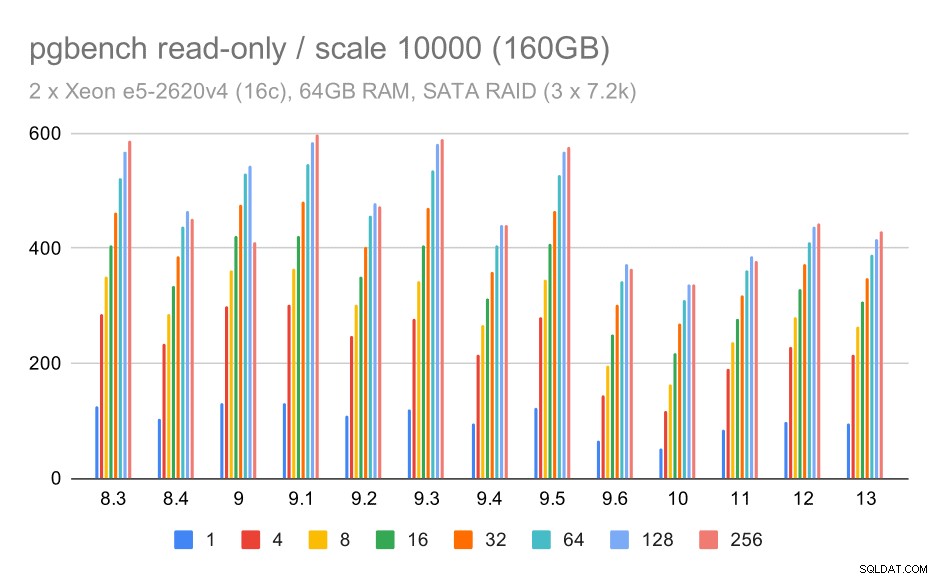
SATA RAIDでのpgbenchの結果/大規模なデータセット(スケール10000、つまり160GB)での読み取り専用
SATARAID/読み取り/書き込み
ただし、読み取り/書き込みの動作ははるかに優れているようです。小さなデータセットでは、スループットは約600tpsから6000tps以上に増加します。これは、9.1と9.2でのグループコミットの改善のおかげだと思います。
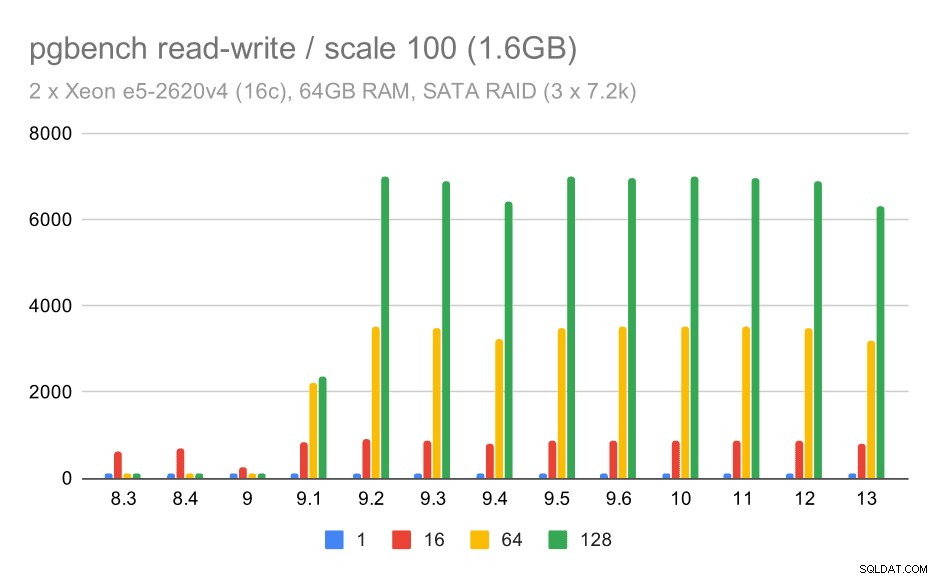
SATA RAIDでのpgbenchの結果/小さなデータセット(スケール100、つまり1.6GB)での読み取り/書き込み
中規模および大規模の場合、ストレージはデータブロックの読み取りと書き込みのI / O要求も処理する必要があるため、同様の、しかし小規模な改善が見られます。中規模の場合は(データがRAMに収まるため)書き込みのみを行う必要があり、大規模の場合は読み取りも行う必要があるため、最大スループットはさらに低くなります。
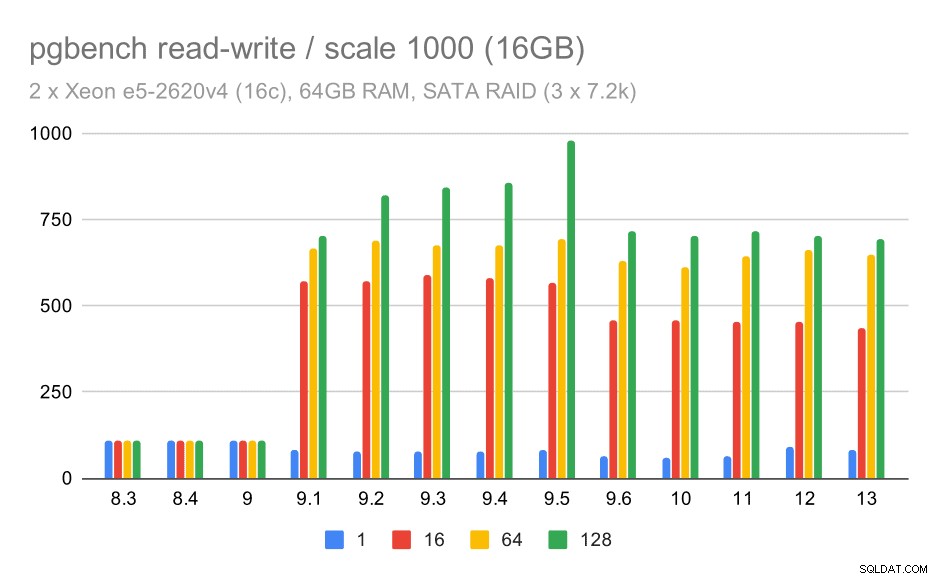
SATA RAIDでのpgbenchの結果/中程度のデータセット(スケール1000、つまり16GB)での読み取り/書き込み
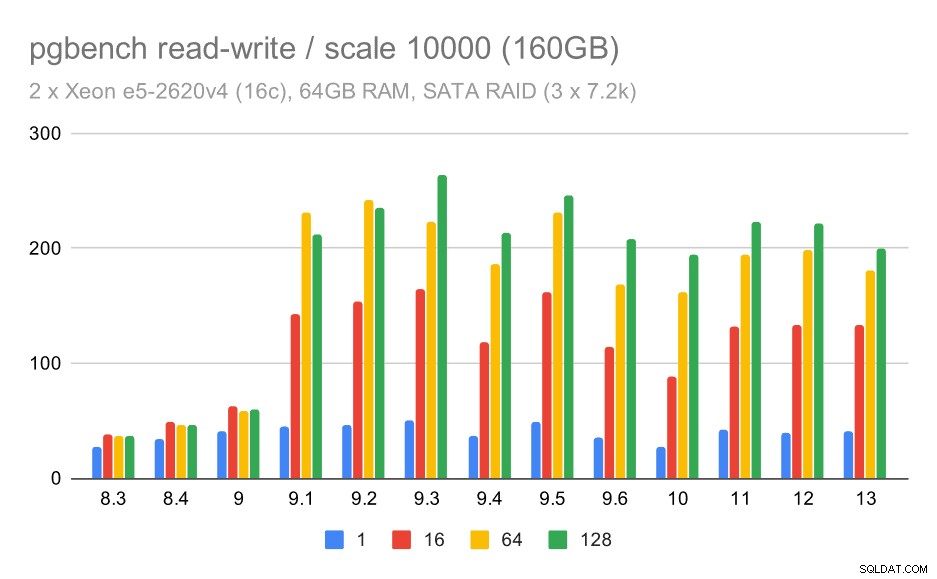
SATA RAIDでのpgbenchの結果/大規模なデータセット(スケール10000、つまり160GB)での読み取り/書き込み
概要と将来
これを要約すると、NVMeのセットアップでは、結論はかなり肯定的なようです。読み取り専用ワークロードの場合、スケーラビリティの最適化により、9.2で中程度のスピードアップ、9.5で大幅なスピードアップがあります。一方、読み取り/書き込みワークロードの場合、複数のバージョン/ステップで、パフォーマンスが時間の経過とともに約2倍向上しました。
ただし、SATA RAIDのセットアップでは、結論は多少複雑です。読み取り専用ワークロードの場合、変動性/ノイズが多く、9.6でリグレッションが発生する可能性があります。読み取り/書き込みワークロードの場合、9.1で大幅な高速化が行われ、スループットが100tpsから約600tpsに突然増加しました。
将来のPostgreSQLバージョンの改善についてはどうですか?次の大きな改善がどうなるかははっきりとはわかりませんが、他のPostgreSQLハッカーが、物事をより効率的にしたり、利用可能なハードウェアリソースを活用したりできる素晴らしいアイデアを思い付くと確信しています。多くの接続でスケーラビリティを改善するパッチ、または不揮発性WALバッファのサポートを追加するパッチは、そのような改善の例です。 PostgreSQLストレージ(より効率的なオンディスクフォーマット、ダイレクトI / Oなどを使用)、インデックス作成などに根本的な改善が見られる場合があります。