このブログシリーズの最初の部分では、2008年にリリースされた8.3以降のPostgreSQL OLTPのパフォーマンスの変化を示すベンチマーク結果をいくつか紹介しました。この部分では、同じことを行う予定ですが、分析/ BIクエリでは、大規模な処理を行います。データ量。
このワークロードをテストするための業界ベンチマークは多数ありますが、おそらく最も一般的に使用されるものはTPC-Hであるため、このブログ投稿で使用します。意思決定支援システムをテストするためのもう1つのTPCベンチマークであるTPC-DSもあります。これは、TPC-Hの進化または代替と見なされる場合があります。いくつかの理由から、TPC-Hを使用することにしました。
まず、TPC-DSは、スキーマ(より多くのテーブル)とクエリの数(22対99)の両方の点で、はるかに複雑です。これを適切に調整することは、特に複数のPostgreSQLバージョンを処理する場合、はるかに困難になります。次に、一部のTPC-DSクエリは、古いPostgreSQLバージョンでサポートされていない機能(グループ化セットなど)を使用しているため、これらのクエリは一部のバージョンには関係ありません。そして最後に、人々はTPC-DSと比較してTPC-Hにはるかに精通していると思います。
これの目的は、他のデータベース製品との比較を可能にすることではなく、PostgreSQL8.3以降のPostgreSQLのパフォーマンスの進化に関する合理的な長期的な特性を提供することだけです。
注 :TPC-Hベンチマークの非常に興味深い分析については、Boncz、Neumann、Erlingの「TPC-H分析:影響力のあるベンチマークから学んだ隠されたメッセージと教訓」の論文を強くお勧めします。
ハードウェア
このブログ投稿の結果のほとんどは、私がオフィスに持っている「より大きなボックス」からのものであり、次のパラメーターがあります。
- 2x E5-2620 v4(16コア、32スレッド)
- 64GB RAM
- Intel Optane 900P 280GB NVMe SSD(データ)
- 3 x 7.2k SATA RAID0(一時表領域)
- カーネル5.6.15、ext4ファイルシステム
かなり強力なマシンを購入できると確信していますが、これは関連データを提供するのに十分だと思います。 2つの構成バリアントがありました。1つは並列処理が無効になっており、もう1つは並列処理が有効になっています。ほとんどのパラメーター値はどちらの場合も同じであり、使用可能なハードウェアリソース(CPU、RAM、ストレージ)に合わせて調整されています。構成の詳細については、この投稿の最後にあります。
ベンチマーク
TPCに必要なすべての基準に合格できる有効なTPC-Hベンチマークを実装することが私の目標ではないことを明確にしたいと思います。私の目標は、さまざまな分析クエリのパフォーマンスが時間の経過とともにどのように変化したかを評価することであり、1ドルあたりのパフォーマンスの抽象的な測定値などを追跡することではありません。
そのため、TPC-Hのサブセットのみを使用することにしました。基本的には、データをロードし、22個のクエリを実行します(すべてのバージョンで同じパラメーター)。データの更新はありません。データセットは、初期ロード後は静的です。いくつかのスケール係数、1、10、および75を選択したので、共有バッファーへの適合(1)、メモリーへの適合(10)、およびメモリー以上(75)の結果が得られます。 。場合によっては(インデックスや一時ファイルなどのおかげで)280 GBのストレージに収まらない、「適切なシーケンス」にするために100を使用します。スケールファクター75は、TPC-Hによって有効なスケールファクターとして認識されないことに注意してください。
しかし、1GBまたは10GBのデータセットをベンチマークすることは理にかなっていますか?人々ははるかに大きなデータベースに集中する傾向があるので、それらをテストするのに煩わされるのは少しばかげているように見えるかもしれません。しかし、それは役に立たないと思います。私の経験では、野生のデータベースの大部分はかなり小さいです。データベース全体が大きい場合でも、人々は通常、データベースの小さなサブセット(最近のデータ)でしか作業しません。未解決の注文など。したがって、これらの小さなデータセットでもテストするのは理にかなっていると思います。
データの読み込み
まず、並列処理の有無にかかわらず、データベースにデータをロードするのにかかる時間を見てみましょう。全体的な動作は小さなケースでもほぼ同じであるため、75GBのデータセットの結果のみを表示します。
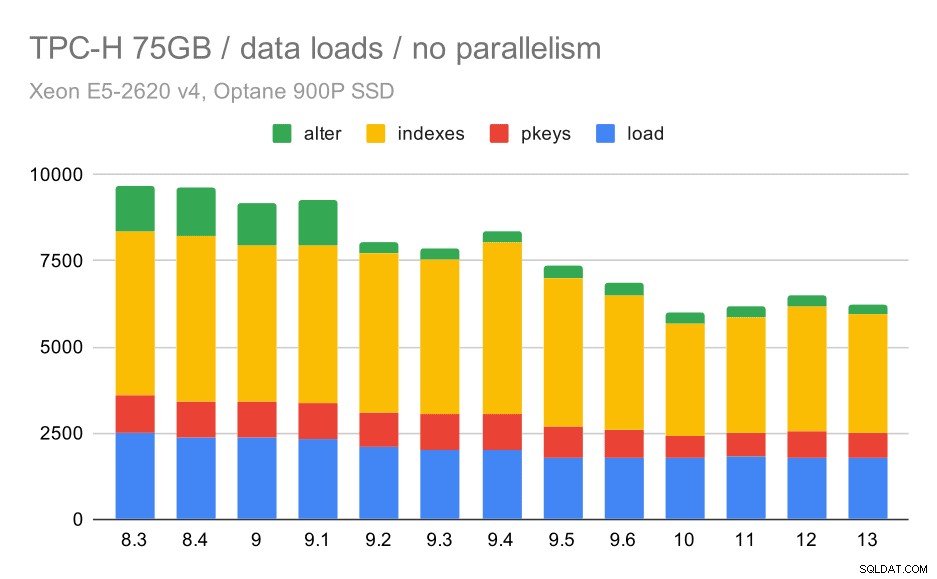
TPC-Hデータロード期間–スケール75GB、並列処理なし
COPY、主キーとインデックスの作成、(特に)外部キーの設定の4つのステップすべてで効率を改善するだけで、期間の約30%が短縮され、着実に改善の傾向があることがはっきりとわかります。 9.2での「変更」の改善は特に明白です。
| コピー | PKEYS | INDEXES | ALTER | |
| 8.3 | 2531 | 1156 | 1922 | 1615 |
| 8.4 | 2374 | 1171 | 1891 | 1370 |
| 9.0 | 2374 | 1137 | 1797 | 1282 |
| 9.1 | 2376 | 1118 | 1807 | 1268 |
| 9.2 | 2104 | 1120 | 1833 | 1157 |
| 9.3 | 2008 | 1089 | 1836 | 1229 |
| 9.4 | 1990 | 1168 | 1818 | 1197 |
| 9.5 | 1982 | 1000 | 1903 | 1203 |
| 9.6 | 1779 | 872 | 1797 | 1174 |
| 10 | 1773 | 777 | 1469 | 1012 |
| 11 | 1807 | 762 | 1492 | 758 |
| 12 | 1760 | 768 | 1513 | 741 |
| 13 | 1782 | 836 | 1587 | 675 |
それでは、並列処理を有効にすると動作がどのように変化するかを見てみましょう。次のグラフは、並列処理を有効にした結果(「(p)」でマーク)と並列処理を無効にした結果を比較しています。
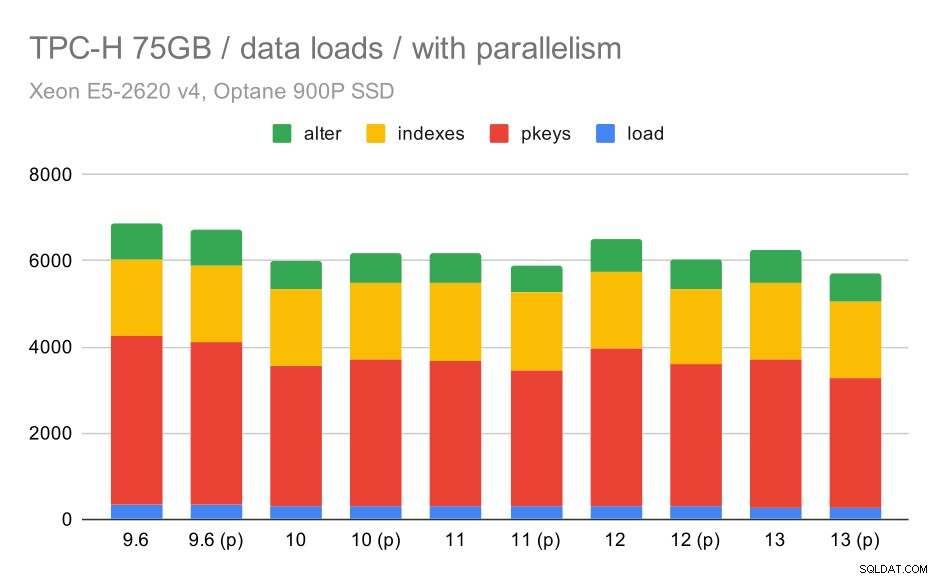
TPC-Hデータのロード期間–スケール75GB、並列処理が有効。
残念ながら、このテストでは並列処理の効果は非常に限られているようです。少しは役立ちますが、違いはかなり小さいです。したがって、全体的な改善は約30%のままです。
| コピー | PKEYS | INDEXES | ALTER | |
| 9.6 | 344 | 3902 | 1786 | 831 |
| 9.6(p) | 346 | 3781 | 1780 | 832 |
| 10 | 318 | 3259 | 1766 | 671 |
| 10(p) | 315 | 3400 | 1769 | 693 |
| 11 | 319 | 3357 | 1817 | 690 |
| 11(p) | 320 | 3144 | 1791 | 618 |
| 12 | 314 | 3643 | 1803 | 754 |
| 12(p) | 313 | 3296 | 1752 | 657 |
| 13 | 276 | 3437 | 1790 | 744 |
| 13(P) | 274 | 3011 | 1770 | 641 |
クエリ
これで、クエリを確認できます。 TPC-Hには22のクエリテンプレートがあります。実際のクエリのセットを1つ生成し、すべてのバージョンで2回実行しました。最初はすべてのキャッシュを削除してインスタンスを再起動した後、次にウォームアップしたキャッシュを使用しました。グラフに示されているすべての数値は、これら2つの実行の中で最も優れています(もちろん、ほとんどの場合、2番目の実行です)。
並列処理なし
並列処理がなければ、最小のデータセットでの結果は非常に明確です。各バーは、22のクエリごとに異なる色の複数の部分に分割されます。どの部分がどの正確なクエリに対応しているかを判断するのは難しいですが、2回の実行で1つのクエリが改善または悪化した場合を特定するには、十分です。たとえば、最初のグラフでは、Q21が8.3から8.4の間ではるかに速くなったことが非常に明確です。
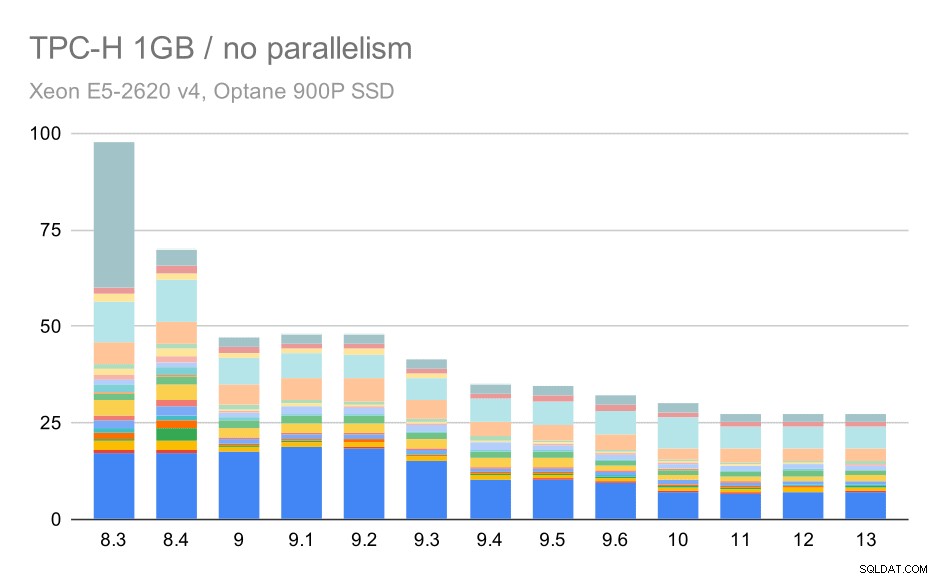
小さなデータセット(1GB)に対するTPC-Hクエリ–並列処理が無効
10GBスケールの場合、8.3ではクエリの1つ(Q21)の実行に非常に時間がかかり、他のすべてを小さくするため、結果を解釈するのはやや困難です。
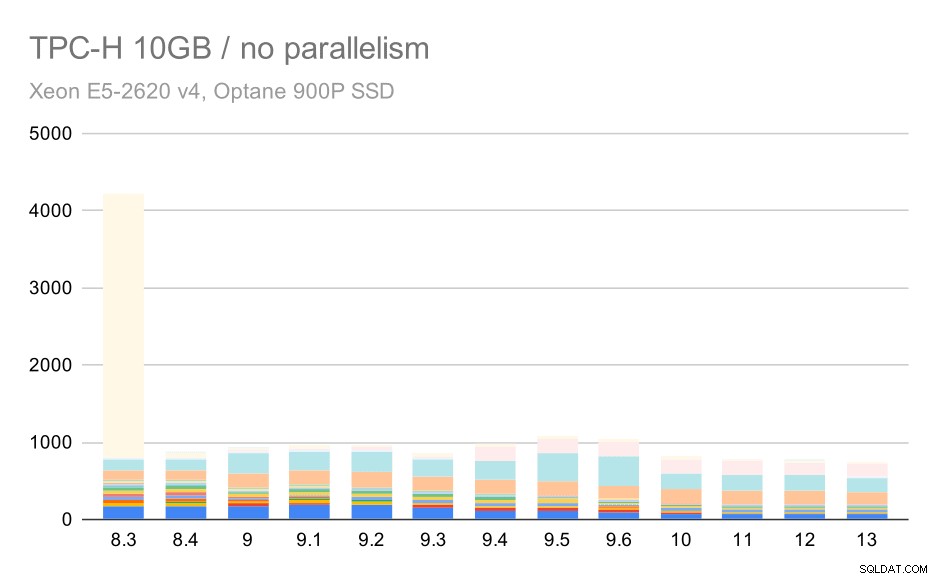
中程度のデータセット(10GB)でのTPC-Hクエリ–並列処理が無効
では、Q21なしでグラフがどのように表示されるかを見てみましょう:
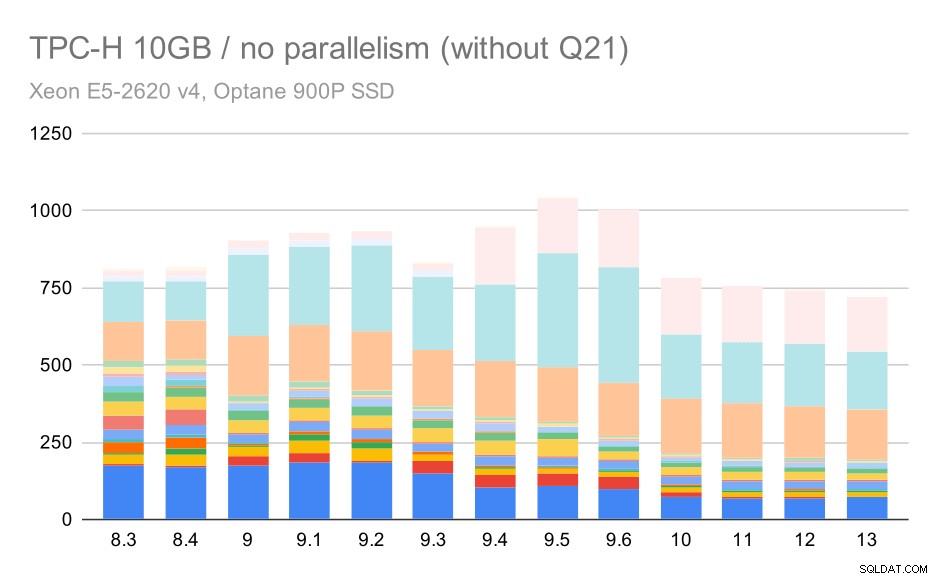
中程度のデータセット(10GB)でのTPC-Hクエリ–並列処理は無効で、問題のあるQ2はありません
OK、それは読みやすいです。ほとんどのクエリ(Q17まで)は速くなりましたが、2つのクエリ(Q18とQ20)はやや遅くなっていることがはっきりとわかります。最大のデータセットでも同様の問題が発生するため、その根本的な原因について説明します。
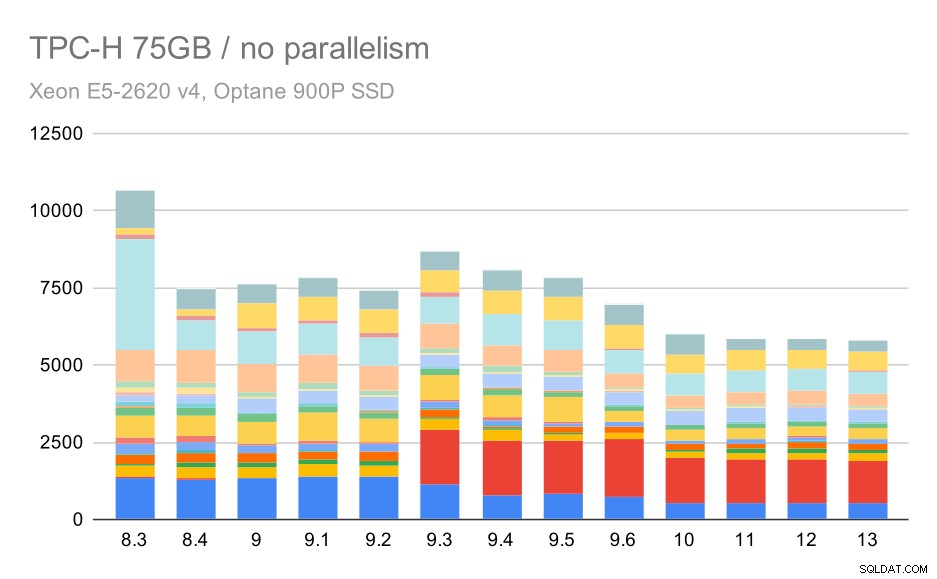
大規模なデータセット(75GB)に対するTPC-Hクエリ–並列処理が無効
繰り返しになりますが、9.3ではクエリの1つが突然増加しています。今回は、第2四半期です。これがないと、グラフは次のようになります。
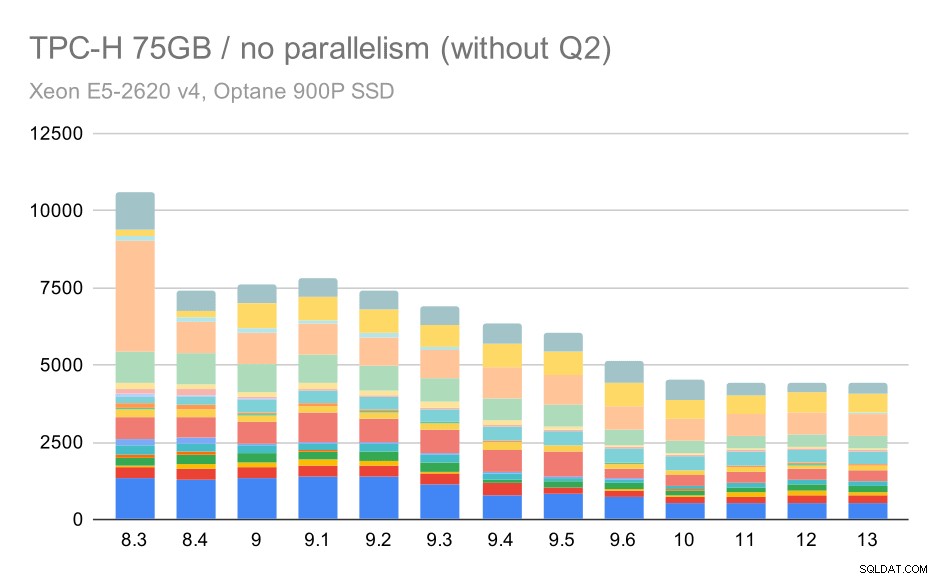
大規模なデータセット(75GB)に対するTPC-Hクエリ–並列処理が無効になり、問題のあるQ2は発生しません
これは一般的にかなり良い改善であり、プランナーとオプティマイザーをよりスマートにし、エグゼキューターをより効率的にすることで、実行全体を約2.7時間からわずか約1.2時間に高速化します(これらの実行では並列処理が無効になっていることを忘れないでください) 。
では、Q2で何が問題になり、9.3で遅くなる可能性がありますか?簡単な答えは、プランナーとオプティマイザーをよりスマートにするたびに、新しいタイプのパス/プランを構築するか、いくつかの統計に依存させることによって、統計または推定が間違っているときに新しい間違いを犯す可能性があることを意味します。 Q2では、WHERE句は集約サブクエリを参照します–クエリの簡略化されたバージョンは次のようになります:
select 1 from partsupp where ps_supplycost = ( select min(ps_supplycost) from partsupp, supplier, nation, region where p_partkey = ps_partkey and s_suppkey = ps_suppkey and s_nationkey = n_nationkey and n_regionkey = r_regionkey and r_name = 'AMERICA' );
問題は、計画時に平均値がわからないため、WHERE条件に対して十分に適切な推定値を計算できないことです。実際の第2四半期には追加の結合が含まれており、それらの計画は基本的に結合関係の適切な見積もりに依存します。古いバージョンでは、オプティマイザーは正しいことを行っていたようですが、9.3では、何らかの方法でそれをよりスマートにしましたが、見積もりが不十分なため、正しい決定を下すことができません。言い換えれば、プランナーの制限のおかげで、古いバージョンの良いプランは運が良かったのです。
小さいデータセットでのQ18とQ20の回帰も、詳細な調査はしていませんが、同様の原因によるものだと思います。
これらのオプティマイザーの問題のいくつかは、コストパラメーター(random_page_costなど)を調整することで修正できると思いますが、時間の制約があるため、試していません。ただし、アップグレードによってすべてのクエリが自動的に改善されるわけではないことを示しています。アップグレードによってリグレッションがトリガーされる場合があるため、アプリケーションを適切にテストすることをお勧めします。
並列処理
それでは、クエリの並列処理によって結果がどの程度変化するかを見てみましょう。繰り返しになりますが、並列クエリが有効になっている9.6のラベル付け結果に「(p)」を付けてからのリリースの結果のみを確認します。
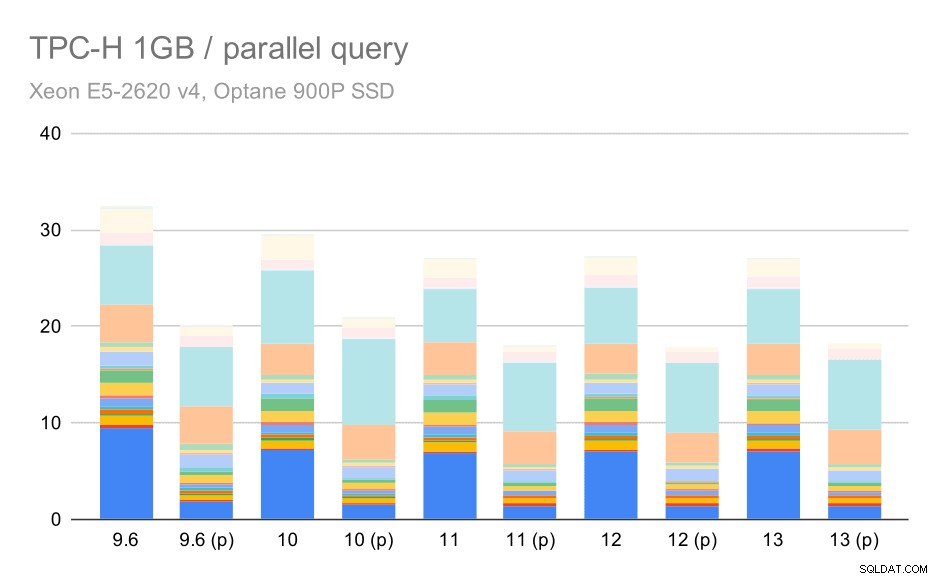
小さなデータセット(1GB)に対するTPC-Hクエリ–並列処理が有効
明らかに、並列処理はかなり役立ちます。この小さなデータセットでも約30%削減されます。中程度のデータセットでは、通常の実行と並列実行の間に大きな違いはありません。
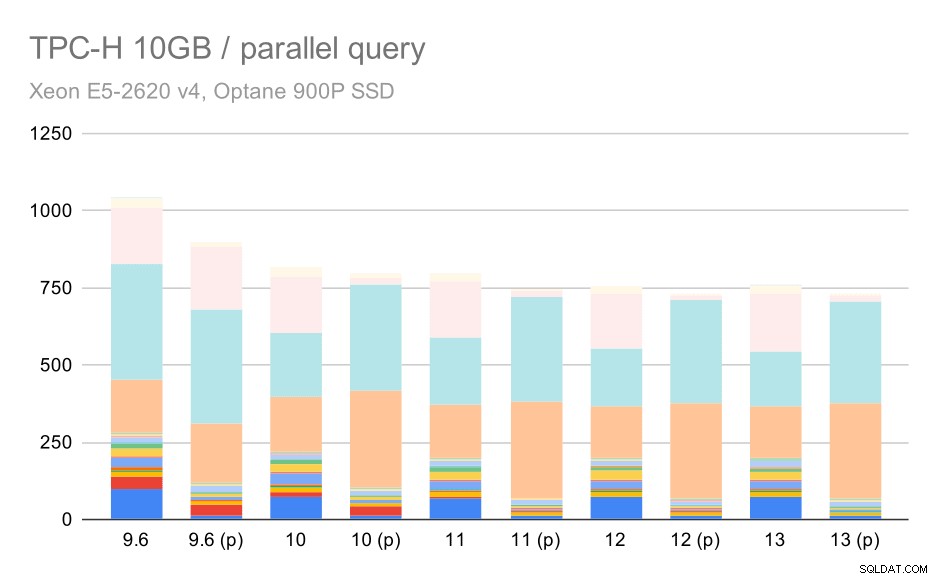
中程度のデータセット(10GB)でのTPC-Hクエリ–並列処理が有効
これは、すでに説明した問題のさらに別のデモンストレーションです。並列処理を有効にすると、追加のクエリプランを検討でき、明らかに見積もりやコストが現実と一致しないため、プランの選択が不十分になります。
そして最後に、完全な結果が次のようになる大規模なデータセット:
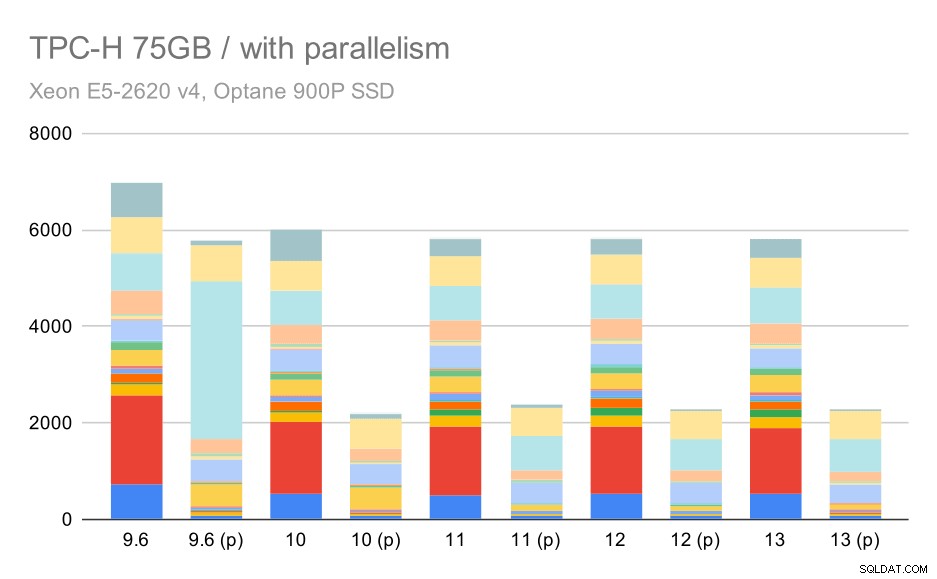
大規模なデータセット(75GB)に対するTPC-Hクエリ–並列処理が有効
ここで、並列処理を有効にすることは私たちの利点として機能します。オプティマイザーは、9.3で導入された貧弱な計画の選択を無効にして、第2四半期のより安価な並列計画を構築することができます。ただし、完全を期すために、Q2を除いた結果を次に示します。
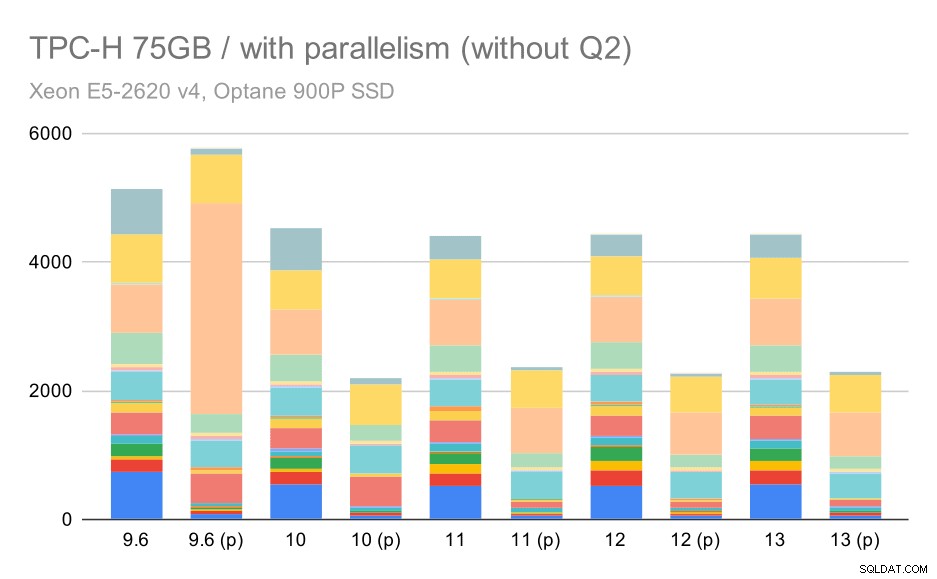
大規模なデータセット(75GB)に対するTPC-Hクエリ–並列処理が有効で、問題のあるQ2はありません
ここでも、いくつかの不十分な並列プランの選択を見つけることができます。たとえば、Q9の並列プランは11まで悪化し、高速になります。おそらく、11が追加の並列エグゼキュータノードをサポートしているためです。一方、一部の並列クエリ(Q18、Q20)は11で遅くなるため、レインボーやユニコーンだけではありません。
概要と将来
これらの結果は、PostgreSQL8.3以降の最適化の実装をうまく示していると思います。並列処理を無効にしたテストは、効率の向上を示しています(つまり、同じ量のリソースでより多くのことを実行します)。データの読み込みが最大30%速くなり、クエリが最大2倍速くなりました。確かに、非効率的なクエリプランでいくつかの問題が発生しましたが、クエリプランナーをよりスマートにする場合、それは固有のリスクです。結果の信頼性を高めるために継続的に取り組んでおり、構成を少し調整することで、これらの問題のほとんどを軽減できると確信しています。
並列処理を有効にした結果は、追加のリソース(特にCPUコア)を効果的に利用できることを示しています。データの読み込みはこれからあまり恩恵を受けていないようです。少なくともこのベンチマークではそうではありませんが、クエリの実行への影響は大きく、結果として最大2倍のスピードアップになります(もちろん、クエリが異なれば影響も異なります)。
>将来のPostgreSQLバージョンでこれを改善する多くの機会があります。たとえば、COPYの並列処理を実装し、データの読み込みを高速化するパッチシリーズがあります。分析クエリの実行を改善するさまざまなパッチがあります–小さなローカライズされた最適化から、列型ストレージと実行、集約プッシュダウンなどの大きなプロジェクトまで。宣言型パーティショニングを使用することでも多くのことが得られます–これに取り組んでいる間私はほとんど無視した機能ベンチマーク。スコープが大きくなりすぎるからです。そして、私が想像することさえできない他の多くの機会があると確信していますが、PostgreSQLコミュニティのより賢い人々はすでにそれらに取り組んでいます。
付録:PostgreSQLの構成
並列処理が無効
shared_buffers = 4GB work_mem = 128MB vacuum_cost_limit = 1000 max_wal_size = 24GB checkpoint_timeout = 30min checkpoint_completion_target = 0.9 # logging log_checkpoints = on log_connections = on log_disconnections = on log_line_prefix = '%t %c:%l %x/%v ' log_lock_waits = on log_temp_files = 1024 # parallel query max_parallel_workers_per_gather = 0 max_parallel_maintenance_workers = 0 # optimizer default_statistics_target = 1000 random_page_cost = 60 effective_cache_size = 32GB
並列処理が有効
shared_buffers = 4GB work_mem = 128MB vacuum_cost_limit = 1000 max_wal_size = 24GB checkpoint_timeout = 30min checkpoint_completion_target = 0.9 # logging log_checkpoints = on log_connections = on log_disconnections = on log_line_prefix = '%t %c:%l %x/%v ' log_lock_waits = on log_temp_files = 1024 # parallel query max_parallel_workers_per_gather = 16 max_parallel_maintenance_workers = 16 max_worker_processes = 32 max_parallel_workers = 32 # optimizer default_statistics_target = 1000 random_page_cost = 60 effective_cache_size = 32GB