将来、ほとんどのデータベースサーバー(特にOLTPのようなワークロードを処理するサーバー)はフラッシュベースのストレージを使用しますが、まだありません。フラッシュストレージは従来のハードドライブよりもかなり高価であり、多くのシステムが混合を使用していますSSDおよびHDDドライブの。ただし、これは、データベースを分割する方法を決定する必要があることを意味します。回転する錆(HDD)に何を配置するか、およびより高価であるがランダムI/Oの処理にはるかに優れたフラッシュストレージの適切な候補は何ですか。
>SSDをキャッシュとして自動的に使用し、データのアクティブな部分をSSDに自動的に保持することで、ストレージレベルでこれを自動的に処理しようとするソリューションがあります。ストレージアプライアンス/SANはこれを内部で行うことが多く、単一のパッケージに大きなHDDと小さなSSDを備えたハイブリッドSATA / SASドライブがあります。もちろん、これをホストで直接行うソリューションです。たとえば、Linux、LVMにはdm-cacheがあります。また、2014年にそのような機能(dm-cache上に構築)を取得しました。もちろん、ZFSにはL2ARCがあります。
ただし、これらの自動オプションをすべて無視して、システムに直接接続されている2つのデバイスがあるとします。1つはHDDベースで、もう1つはフラッシュベースです。高価なフラッシュを最大限に活用するには、データベースをどのように分割する必要がありますか?一般的に使用されるパターンの1つは、オブジェクトタイプ、特にテーブルとインデックスでこれを行うことです。これは一般的には理にかなっていますが、インデックスはランダムI / Oに関連付けられているため、SSDストレージにインデックスを配置する人がよく見られます。これは合理的に思えるかもしれませんが、これはあなたがすべきこととは正反対であることがわかります。
ベンチマークをお見せしましょう…
HDDストレージ(4x 10k SASドライブから構築されたRAID10)と単一のSSDデバイス(Intel S3700)の両方を備えたシステムでこれを実証しましょう。システムには16GBのRAMがあるので、スケール300(=4.5GB)と3000(=45GB)のpgbenchを使用しましょう。つまり、RAMとRAMの倍数に簡単に収まります。次に、(テーブルスペースを使用して)さまざまなストレージシステムにテーブルとインデックスを配置し、パフォーマンスを測定しましょう。データベースクラスターは、ハードウェアリソースに関して合理的に構成されています(共有バッファー、WAL制限など)。 WALは、SASドライブと共有されるRAIDコントローラーに接続された別のSSDデバイスに配置されました。
小さい(4.5GB)データセットでは、結果は次のようになります(y軸が3000 tpsで始まることに注意してください):
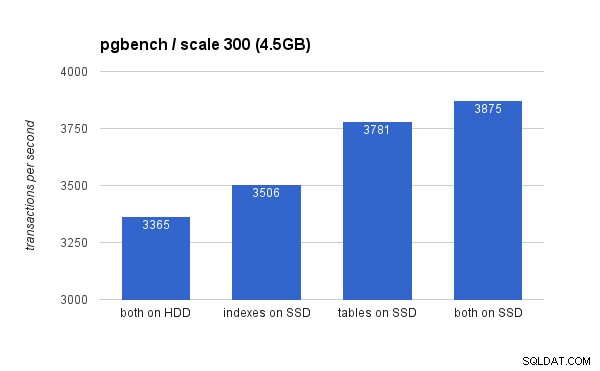
明らかに、SSDにインデックスを配置すると、テーブルにSSDを使用する場合に比べてメリットが少なくなります。データセットはRAMに簡単に収まりますが、変更は最終的にディスクに書き込まれる必要があり、RAIDコントローラーには書き込みキャッシュがありますが、フラッシュストレージと実際に競合することはできません。新しいRAIDコントローラはおそらく少しパフォーマンスが向上しますが、新しいSSDドライブも同様です。
大規模なデータセットでは、違いははるかに重要です(今回はy軸は0から始まります):
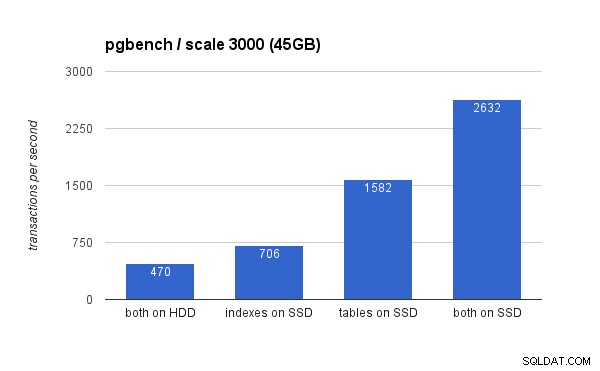
SSDにインデックスを配置すると、パフォーマンスが大幅に向上します(HDDストレージをベースラインとして使用すると、ほぼ50%になります)が、テーブルをSSDに移動すると、200%以上向上します。もちろん、テーブルとインデックスの両方をSSDに配置すると、パフォーマンスがさらに向上しますが、それができれば、他のケースについて心配する必要はありません。
でもなぜですか?
SSDにテーブルを配置することでパフォーマンスを向上させることは、少し直感に反するように思われるかもしれませんが、なぜこのように動作するのでしょうか。まあ、それはおそらくいくつかの要因の組み合わせです:
- インデックスは通常、テーブルよりもはるかに小さいため、メモリに簡単に収まります
- (ツリー内の)インデックスのレベルのページは通常非常に高温であるため、メモリに残ります
- スキャンしてインデックスを作成する場合、実際のI / Oの多くは本質的にシーケンシャルです(特にリーフページの場合)
この結果、インデックスに対する驚くべき量のI / Oがまったく発生しないか(キャッシングのおかげで)、シーケンシャルになります。一方、インデックスは、テーブルに対するランダムI/Oの優れたソースです。
もっと複雑ですが…
もちろん、これは単なる例であり、たとえば、大幅に異なるワークロードでは結論が異なる場合があります。同様に、SSDは高価であるため、システムはSSDドライブよりもHDDドライブの方がディスク容量が多い傾向があるため、インデックスが収まるのにテーブルがSSDに収まらない場合があります。そのような場合、より複雑な配置が必要です。たとえば、オブジェクトのタイプだけでなく、使用頻度(および頻繁に使用されるテーブルをSSDに移動するだけ)、またはテーブルのサブセット(たとえば、徐々に古いものを移動することによる)も考慮します。 SSDからHDDへのデータ)。