postgresql.confを微調整している間 、full_page_writesというオプションがあることに気付いたかもしれません。 。その横のコメントは部分的なページ書き込みについて何かを言っており、人々は一般的にそれをonに設定したままにします –これは良いことです。これについては、この投稿の後半で説明します。ただし、パフォーマンスへの影響は非常に大きい可能性があるため、ページ全体の書き込みが何を行うかを理解することは有用です。
チェックポイントの調整に関する以前の投稿とは異なり、これはサーバーを調整する方法のガイドではありません。実際に微調整できることはあまりありませんが、アプリケーションレベルの決定(データ型の選択など)がページ全体の書き込みとどのように相互作用するかを示します。
部分的な書き込み/ページの破損
それで、全ページは何について書いていますか? postgresql.confのコメントとして 部分的なページ書き込みから回復する方法だと言います– PostgreSQLは8kBページ(デフォルト)を使用しますが、スタックの他の部分は異なるチャンクサイズを使用します。 Linuxファイルシステムは通常4kBページを使用し(小さいページを使用することも可能ですが、x86では4kBが最大です)、ハードウェアレベルでは、古いドライブは512Bセクターを使用し、新しいデバイスは多くの場合、大きいチャンク(多くの場合4kBまたは8kB)でデータを書き込みます。 。
したがって、PostgreSQLが8kBページを書き込むとき、ストレージスタックの他のレイヤーは、これを個別に管理される小さなチャンクに分割する場合があります。これは、書き込みの原子性に関する問題を提示します。 8kB PostgreSQLページは2つの4kBファイルシステムページに分割され、次に512Bセクターに分割される場合があります。では、サーバーがクラッシュした場合はどうなりますか(電源障害、カーネルバグなど)?
サーバーがそのような障害に対処するように設計されたストレージシステム(コンデンサーを備えたSSD、バッテリーを備えたRAIDコントローラーなど)を使用している場合でも、カーネルはすでにデータを4kBページに分割しています。したがって、データベースが8kBのデータページを書き込んだ可能性がありますが、クラッシュする前にその一部だけがディスクに記録されました。
この時点で、おそらくこれがトランザクションログ(WAL)がある理由であると考えていると思いますが、その通りです。したがって、サーバーの起動後、データベースは(最後に完了したチェックポイント以降)WALを読み取り、変更を再度適用して、データファイルが完全であることを確認します。シンプル。
ただし、落とし穴があります。リカバリは変更を盲目的に適用せず、データページなどを読み取る必要があることがよくあります。これは、たとえば部分的な書き込みが原因で、ページがまだ何らかの方法で中断されていないことを前提としています。データの破損を修正するために、データの破損はないと想定しているため、これは少し矛盾しているようです。
全ページ書き込みは、この難問を回避する方法です。チェックポイント後に初めてページを変更する場合、ページ全体がWALに書き込まれます。これにより、リカバリ中に、ページに接触する最初のWALレコードにページ全体が含まれることが保証され、データファイルから(壊れている可能性のある)ページを読み取る必要がなくなります。
ライトアンプリフィケーション
もちろん、これによる悪影響はWALサイズの増加です。8kBページで1バイトを変更すると、全体がWALに記録されます。フルページ書き込みは、チェックポイント後の最初の書き込みでのみ発生するため、チェックポイントの頻度を減らすことは、状況を改善する1つの方法です。通常、チェックポイント後のフルページ書き込みの「バースト」は短く、その後、フルページ書き込みは比較的少なくなります。チェックポイントが終了するまで。
UUIDとBIGSERIALキー
ただし、アプリケーションレベルで行われる設計上の決定には、予期しない相互作用がいくつかあります。 BIGSERIALのいずれかの主キーを持つ単純なテーブルがあると仮定します。 またはUUID 、それにデータを挿入します。生成されるWALの量に違いはありますか(同じ数の行を挿入すると仮定します)?
どちらの場合もほぼ同じ量のWALが生成されると予想するのは妥当なようですが、次のグラフが示すように、実際には大きな違いがあります。
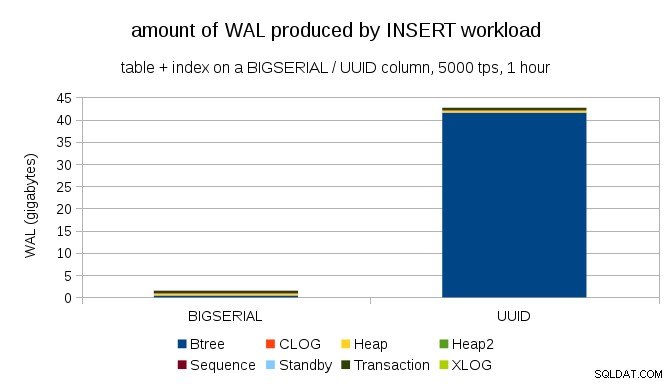
これは、1時間のベンチマーク中に生成されたWALの量を示しており、1秒あたり5000インサートに抑制されています。 BIGSERIALを使用 UUIDを使用している場合、主キーは最大2GBのWALを生成します 40GB以上です。これは非常に重要な違いであり、WALのほとんどが主キーを裏付けるインデックスに関連付けられていることは明らかです。 WALレコードの種類として見てみましょう。
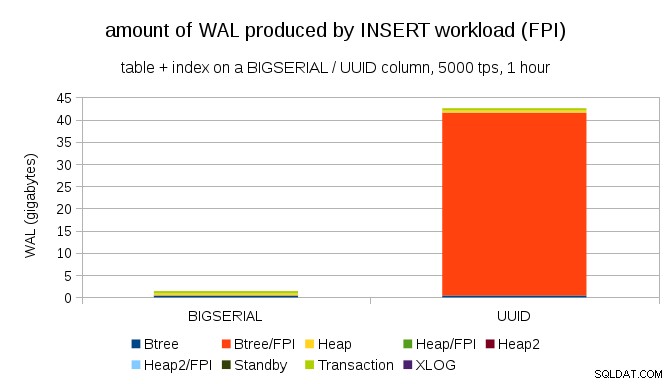
明らかに、レコードの大部分はフルページイメージ(FPI)、つまりフルページ書き込みの結果です。しかし、なぜこれが起こっているのですか?
もちろん、これは固有のUUIDによるものです。 ランダム性。 BIGSERIALを使用 newはシーケンシャルであるため、btreeインデックスの同じリーフページに挿入されます。ページへの最初の変更のみがページ全体の書き込みをトリガーするため、WALレコードのごく一部のみがFPIです。 UUIDを使用 まったく別のケースです。値はまったく連続していません。実際、各挿入は完全に新しいリーフインデックスリーフページに触れる可能性があります(インデックスが十分に大きいと仮定します)。
データベースでできることはあまりありません。ワークロードは本質的にランダムであり、多くのフルページ書き込みがトリガーされます。
BIGSERIALを使用しても、同様のライトアンプリフィケーションを取得することは難しくありません。 もちろん、キー。必要なワークロードは異なります。たとえば、UPDATEを使用します。 ワークロード、一様分布でレコードをランダムに更新すると、グラフは次のようになります。
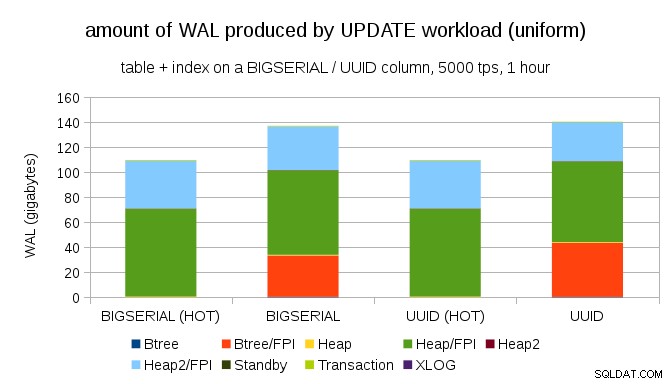
突然、データ型間の違いがなくなりました。どちらの場合もアクセスはランダムであり、ほぼ同じ量のWALが生成されます。もう1つの違いは、ほとんどのWALが「ヒープ」、つまりテーブルに関連付けられており、インデックスに関連付けられていないことです。 「HOT」ケースは、HOT UPDATEの最適化(つまり、インデックスに触れることなく更新)を可能にするように設計されており、インデックスに関連するすべてのWALトラフィックをほぼ排除します。
ただし、ほとんどのアプリケーションはデータセット全体を更新しないと主張するかもしれません。通常、「アクティブ」なデータのサブセットはごくわずかです。人々は、ディスカッションフォーラムの過去数日間の投稿、eショップでの未解決の注文などにのみアクセスします。これにより、結果はどのように変化しますか?
ありがたいことに、pgbenchは不均一な分布をサポートしています。たとえば、指数分布がデータの1%のサブセットに約25%の確率で接触している場合、グラフは次のようになります。
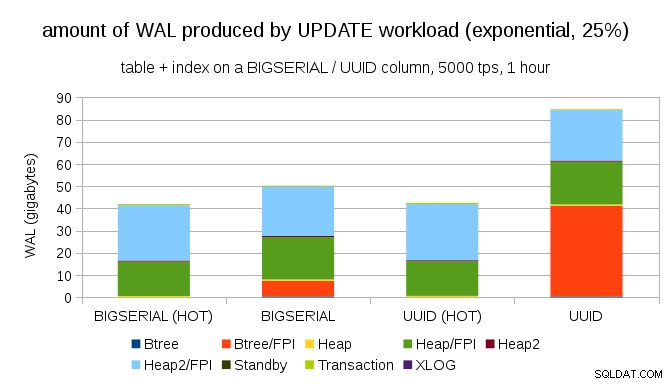
そして、分布をさらに歪めた後、1%のサブセットに約75%の確率で触れます:
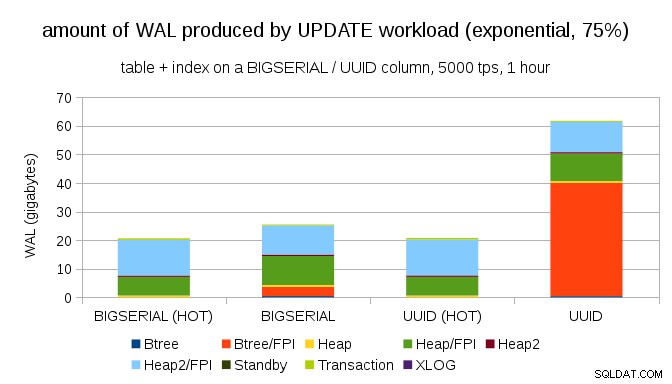
これもまた、データ型の選択がどれほど大きな違いを生む可能性があるか、またHOT更新を調整することの重要性を示しています。
8kBおよび4kBページ
興味深い質問は、PostgreSQLで小さなページを使用することでWALトラフィックをどれだけ節約できるかということです(カスタムパッケージのコンパイルが必要です)。最良の場合、8kBページではなく4kBのみをログに記録するため、最大50%のWALを節約できる可能性があります。 UPDATEが均一に分散されているワークロードの場合、次のようになります。
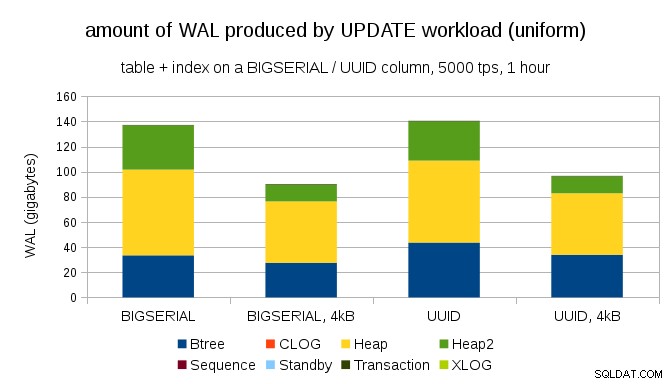
したがって、節約は正確に50%ではありませんが、約140GBから約90GBへの削減は依然として非常に重要です。
まだ全ページの書き込みが必要ですか?
部分的な書き込みの危険性を説明した後はばかげているように見えるかもしれませんが、少なくとも場合によっては、ページ全体の書き込みを無効にすることが実行可能なオプションである可能性があります。
まず、最近のLinuxファイルシステムはまだ部分的な書き込みに対して脆弱かどうか疑問に思いますか?このパラメータは2005年にリリースされたPostgreSQL8.1で導入されたため、それ以降に導入された多くのファイルシステムの改善のいくつかにより、これは問題になりません。おそらく任意のワークロードに対して普遍的ではありませんが、追加の条件(PostgreSQLで4kBのページサイズを使用するなど)を想定するだけで十分でしょうか?また、PostgreSQLが8kBページのサブセットのみを上書きすることはありません。ページ全体が常に書き出されます。
最近、部分的な書き込みをトリガーしようとして多くのテストを実行しましたが、まだ1つのケースを引き起こすことができていません。もちろん、それは問題が存在しないことを実際に証明するものではありません。ただし、それでも問題が発生する場合でも、データチェックサムで十分に保護できる可能性があります(問題は修正されませんが、少なくともページが壊れていることが通知されます)。
次に、最近の多くのシステムは、ストリーミングレプリケーションレプリカに依存しています。ハードウェアの問題(非常に長い時間がかかる場合があります)の後でサーバーが再起動するのを待ってから、リカバリの実行により多くの時間を費やす代わりに、システムは単にホットスタンバイに切り替えます。障害が発生したプライマリのデータベースが削除された場合(その後、新しいプライマリからクローンされた場合)、部分的な書き込みは問題になりません。
しかし、私たちがそれを推奨し始めたとしたら、「データがどのように破損したのかわかりません。システムにfull_page_writes =offを設定しただけです!」 DBAにとって、死の直前に最も一般的な文の1つになります(「このヘビをredditで見たことがありますが、有毒ではありません」)。
概要
フルページの書き込みを直接調整するためにできることはあまりありません。ほとんどのワークロードでは、ほとんどのフルページ書き込みはチェックポイントの直後に発生し、次のチェックポイントまで消えます。したがって、チェックポイントが頻繁に発生しないように調整することが重要です。
一部のアプリケーションレベルの決定により、テーブルとインデックスへの書き込みのランダム性が高まる可能性があります。たとえば、UUID値は本質的にランダムであり、単純なINSERTワークロードでさえランダムなインデックス更新に変わります。例で使用されているスキーマはかなり些細なものでした。実際には、セカンダリインデックス、外部キーなどがあります。ただし、BIGSERIALプライマリキーを内部で使用すると(およびUUIDを代理キーとして保持すると)、少なくとも書き込みの増幅が減少します。
現在のカーネル/ファイルシステムでのフルページ書き込みの必要性についての議論に本当に興味があります。残念ながら、多くのリソースが見つかりませんでした。関連情報があればお知らせください。