PostgreSQLは素晴らしいプロジェクトであり、驚くべき速度で進化しています。一連のブログ投稿を使用して、バージョン全体でPostgreSQLのフォールトトレランス機能の進化に焦点を当てます。これはシリーズの3回目の投稿であり、タイムラインの問題と、PostgreSQLのフォールトトレランスと信頼性に対するそれらの影響について説明します。
最初から進化の進展を目撃したい場合は、シリーズの最初の2つのブログ投稿を確認してください。
- PostgreSQLのフォールトトレランスの進化
- PostgreSQLのフォールトトレランスの進化:レプリケーションフェーズ

タイムライン
データベースを以前の時点に復元する機能は、いくつかの複雑さを生み出します。これについては、フェイルオーバーについて説明することでいくつかのケースをカバーします。 (図1)、スイッチオーバー (図2)および pg_rewind (図3)このトピックの後半のケース。
たとえば、データベースの元の履歴で、火曜日の夜の午後5時15分に重要なテーブルをドロップしたが、水曜日の正午まで間違いに気づかなかったとします。落ち着いて、バックアップを取得し、火曜日の夕方の午後5時14分に復元して、稼働します。このデータベースユニバースの歴史では、テーブルを削除したことはありません。しかし、後でこれがそれほど素晴らしいアイデアではなかったことに気づき、元の歴史の水曜日の朝に戻りたいとしましょう。データベースが稼働しているときに、WALセグメントファイルの一部が上書きされて、現在の状態に戻れるようになっている場合は、それを行うことはできません。
したがって、これを回避するには、ポイントインタイムリカバリを実行した後に生成された一連のWALレコードを、元のデータベース履歴で生成されたものと区別する必要があります。
この問題に対処するために、PostgreSQLにはタイムラインの概念があります。アーカイブのリカバリが完了するたびに、そのリカバリ後に生成された一連のWALレコードを識別するための新しいタイムラインが作成されます。タイムラインID番号はWALセグメントファイル名の一部であるため、新しいタイムラインが以前のタイムラインによって生成されたWALデータを上書きすることはありません。実際、さまざまなタイムラインをアーカイブすることが可能です。
どの時点に回復するかがよくわからない状況を考えてみてください。そのため、古い歴史から分岐するのに最適な場所が見つかるまで、試行錯誤によっていくつかの時点の回復を行う必要があります。タイムラインがなければ、このプロセスはすぐに管理不能な混乱を引き起こします。タイムラインを使用すると、以前に放棄したタイムラインブランチの状態を含め、以前の状態に回復できます。
新しいタイムラインが作成されるたびに、PostgreSQLは「タイムライン履歴」ファイルを作成します。このファイルには、どのタイムラインからいつ分岐したかが示されます。これらの履歴ファイルは、複数のタイムラインを含むアーカイブからリカバリするときに、システムが適切なWALセグメントファイルを選択できるようにするために必要です。したがって、それらはWALセグメントファイルと同じようにWALアーカイブ領域にアーカイブされます。履歴ファイルは小さなテキストファイルであるため、(大きなセグメントファイルとは異なり)無期限に保持するのが安価で適切です。必要に応じて、履歴ファイルにコメントを追加して、この特定のタイムラインが作成された方法と理由に関する独自のメモを記録できます。このようなコメントは、実験の結果としてさまざまなタイムラインの茂みがある場合に特に役立ちます。
リカバリのデフォルトの動作は、ベースバックアップが作成されたときと同じタイムラインに沿ってリカバリすることです。子タイムラインにリカバリする場合(つまり、リカバリの試行後にそれ自体が生成された状態に戻りたい場合)、recovery.confでターゲットタイムラインIDを指定する必要があります。基本バックアップよりも早く分岐したタイムラインに回復することはできません。
PostgreSQLのタイムラインの概念を簡素化するために、フェイルオーバーの場合のタイムライン関連の問題 、スイッチオーバー およびpg_rewind 図1、図2、図3で要約して説明します。
フェイルオーバーシナリオ:
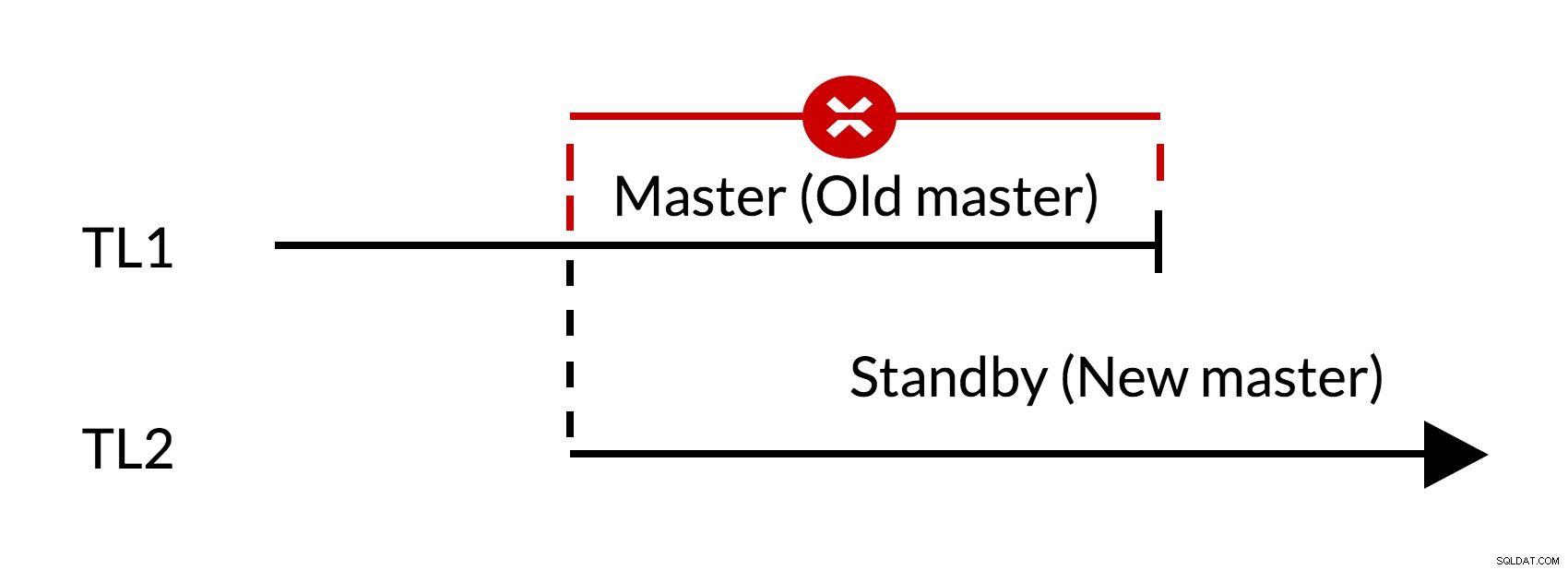
図1フェイルオーバー
- オールドマスター(TL1)には未解決の変更があります
- タイムラインの増加は、新しい変更履歴(TL2)を表します
- 古いタイムラインからの変更は、新しいタイムラインに切り替えたサーバーでは再生できません
- 古いマスターは新しいマスターをフォローできません
切り替えシナリオ:
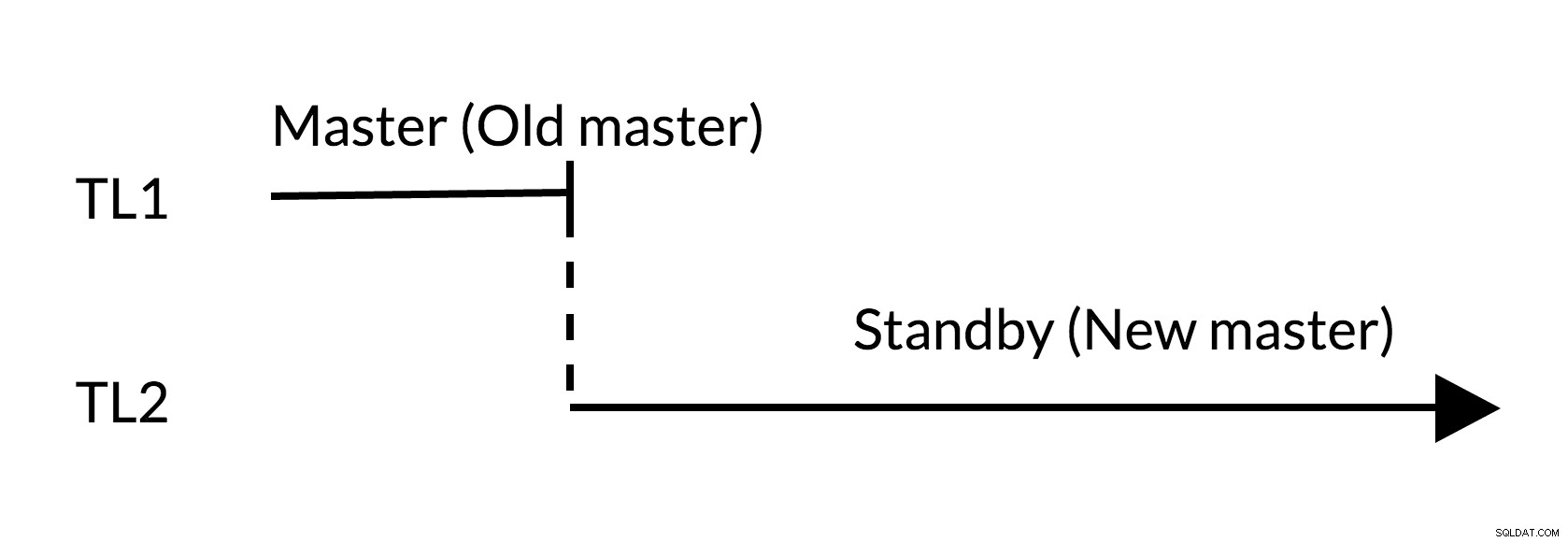 図2スイッチオーバー
図2スイッチオーバー
- 古いマスター(TL1)に目立った変更はありません
- タイムラインの増加は、新しい変更履歴(TL2)を表します
- 古いマスターは新しいマスターのスタンバイになることができます
pg_rewindシナリオ:
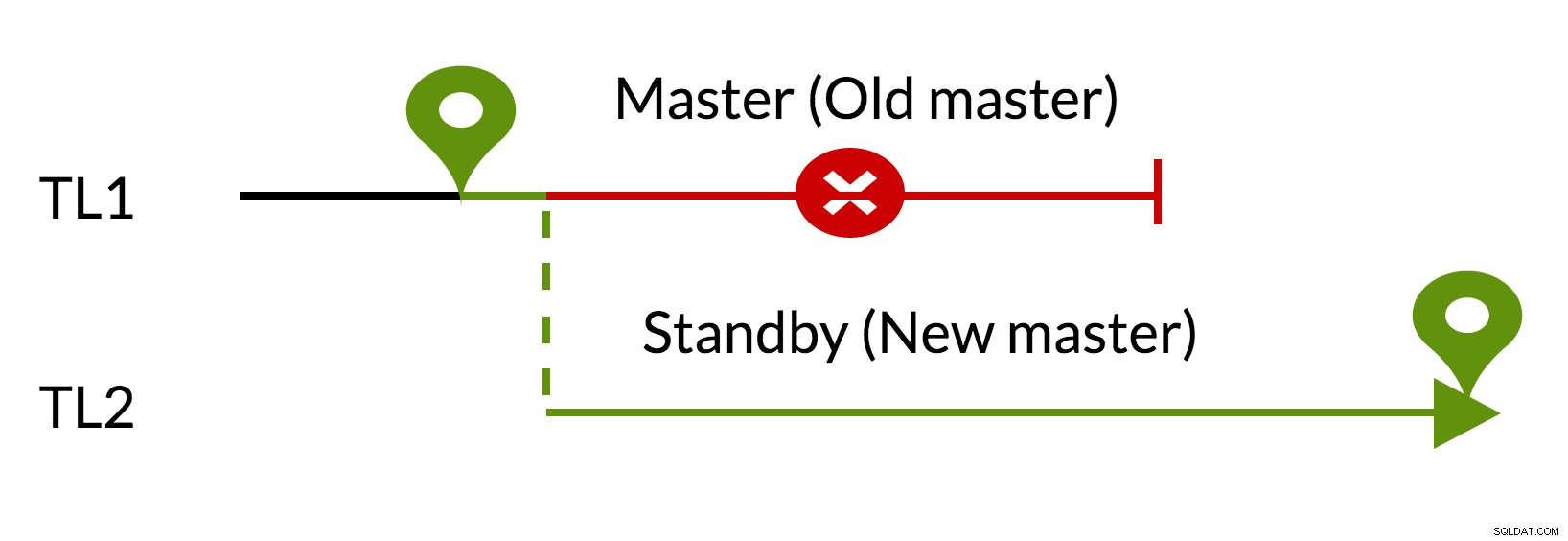 図3pg_rewind
図3pg_rewind
- 未解決の変更は、新しいマスター(TL1)のデータを使用して削除されます
- 古いマスターは新しいマスター(TL2)をフォローできます
pg_rewind
pg_rewindは、クラスターのタイムラインが分岐した後、PostgreSQLクラスターを同じクラスターの別のコピーと同期するためのツールです。典型的なシナリオは、フェイルオーバー後に古いマスターサーバーを新しいマスターに続くスタンバイとしてオンラインに戻すことです。
結果は、ターゲットデータディレクトリをソースディレクトリに置き換えるのと同じです。構成ファイルを含むすべてのファイルがコピーされます。新しいベースバックアップやrsyncなどのツールを使用する場合のpg_rewindの利点は、pg_rewindがクラスター内の変更されていないすべてのファイルを読み取る必要がないことです。これにより、データベースが大きく、クラスター間でデータベースのごく一部のみが異なる場合に、はるかに高速になります。
どのように機能しますか?
基本的な考え方は、同じであることがわかっているブロックを除いて、新しいクラスターから古いクラスターにすべてをコピーすることです。
- 新しいクラスターのタイムライン履歴が古いクラスターから分岐する前の最後のチェックポイントから開始して、古いクラスターのWALログをスキャンします。 WALレコードごとに、変更されたデータブロックをメモします。これにより、新しいクラスターが分岐した後、古いクラスターで変更されたすべてのデータブロックのリストが生成されます。
- 変更されたすべてのブロックを新しいクラスターから古いクラスターにコピーします。
- clogや構成ファイルなど、他のすべてのファイルを新しいクラスターから古いクラスターにコピーします。リレーションファイルを除くすべてのファイルをコピーします。
- フェイルオーバー時に作成されたチェックポイントから開始して、新しいクラスターからWALを適用します。 (厳密に言えば、pg_rewindはWALを適用せず、PostgreSQLが起動すると、そのチェックポイントから再生を開始し、必要なすべてのWALを適用することを示すバックアップラベルファイルを作成するだけです。)
注: pg_rewindを機能させるには、postgresql.confでwal_log_hintsを設定する必要があります。このパラメーターは、サーバーの起動時にのみ設定できます。デフォルト値は
結論
このブログ投稿では、Postgresのタイムラインと、フェイルオーバーとスイッチオーバーのケースの処理方法について説明しました。また、pg_rewindがどのように機能するか、およびPostgresのフォールトトレランスと信頼性に対するその利点についても話しました。次のブログ投稿で同期コミットを続行します。
参照
PostgreSQLドキュメント
PostgreSQL9管理クックブック–第2版
pg_rewindHeikkiLinnakangasによる北欧PGDayプレゼンテーション