先週、PGDay UKに参加できてとても嬉しかったです。とても素敵なイベントで、来年もまた戻ってくる機会があればいいのですが。興味深い話はたくさんありましたが、特に私の注意を引いたのは、AlexeyBashtanovによるグループ化を使用したクエリのPerformaceでした。
私は過去にかなりの数の同様のパフォーマンス指向の講演を行ったので、ベンチマーク結果をわかりやすく興味深い方法で提示することがどれほど難しいかを知っています。Alexeyはかなり良い仕事をしたと思います。したがって、データ集約(BI、分析、または同様のワークロードなど)を扱う場合は、スライドを確認することをお勧めします。他の会議での講演に参加する機会があれば、そうすることを強くお勧めします。
しかし、私がその話に反対する点が1つあります。多くの場所で、ソートが遅いので、一般的にHashAggregateを好むべきだと話が示唆しました。
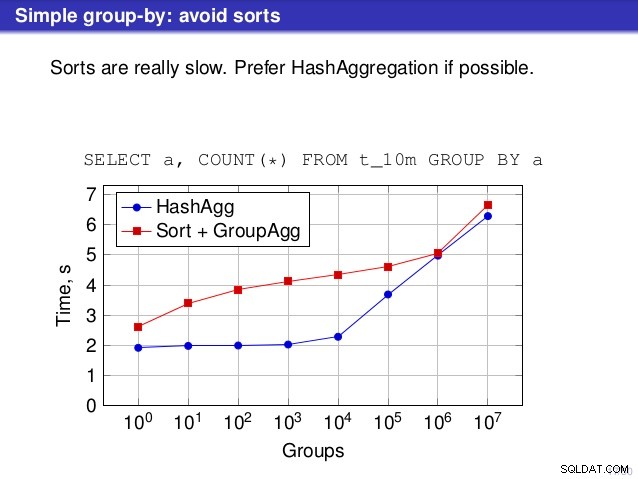
HashAggregateの代替はSortではなくGroupAggregateであるため、これは少し誤解を招くと思います。したがって、推奨事項では、各GroupAggregateにネストされたSortがあることを前提としていますが、それは完全には当てはまりません。 GroupAggregateには並べ替えられた入力が必要であり、明示的な並べ替えだけがそれを行う方法ではありません。IndexScanノードとIndexOnlyScanノードもあり、並べ替えのコストを削減し、並べ替えられたパスに関連するその他の利点(特に、IndexOnlyScan)を維持します。
(IndexOnlyScan + GroupAggregate)がHashAggregateと(Sort + GroupAggregate)の両方と比較してどのように機能するかを示しましょう。測定に使用したスクリプトはここにあります。 4つの単純なテーブルを作成し、それぞれが1億行で、「branch_id」列に異なる数のグループがあります(ハッシュテーブルのサイズを決定します)。最小のものには1万のグループがあります
-- table with 10k groups create table t_10000 (branch_id bigint, amount numeric); insert into t_10000 select mod(i, 10000), random() from generate_series(1,100000000) s(i);
さらに3つのテーブルには、100k、1M、および5Mのグループがあります。データを集約するこの単純なクエリを実行してみましょう:
SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1
次に、3つの異なる計画を使用するようにデータベースを説得します。
1)HashAggregate
SET enable_sort = off;
SET enable_hashagg = on;
EXPLAIN SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1;
QUERY PLAN
----------------------------------------------------------------------------
HashAggregate (cost=2136943.00..2137067.99 rows=9999 width=40)
Group Key: branch_id
-> Seq Scan on t_10000 (cost=0.00..1636943.00 rows=100000000 width=19)
(3 rows) 2)GroupAggregate(ソートあり)
SET enable_sort = on;
SET enable_hashagg = off;
EXPLAIN SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1;
QUERY PLAN
-------------------------------------------------------------------------------
GroupAggregate (cost=16975438.38..17725563.37 rows=9999 width=40)
Group Key: branch_id
-> Sort (cost=16975438.38..17225438.38 rows=100000000 width=19)
Sort Key: branch_id
-> Seq Scan on t_10000 (cost=0.00..1636943.00 rows=100000000 ...)
(5 rows) 3)GroupAggregate(IndexOnlyScanを使用)
SET enable_sort = on;
SET enable_hashagg = off;
CREATE INDEX ON t_10000 (branch_id, amount);
EXPLAIN SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1;
QUERY PLAN
--------------------------------------------------------------------------
GroupAggregate (cost=0.57..3983129.56 rows=9999 width=40)
Group Key: branch_id
-> Index Only Scan using t_10000_branch_id_amount_idx on t_10000
(cost=0.57..3483004.57 rows=100000000 width=19)
(3 rows) 結果
すべてのテーブルで各プランのタイミングを測定すると、結果は次のようになります。
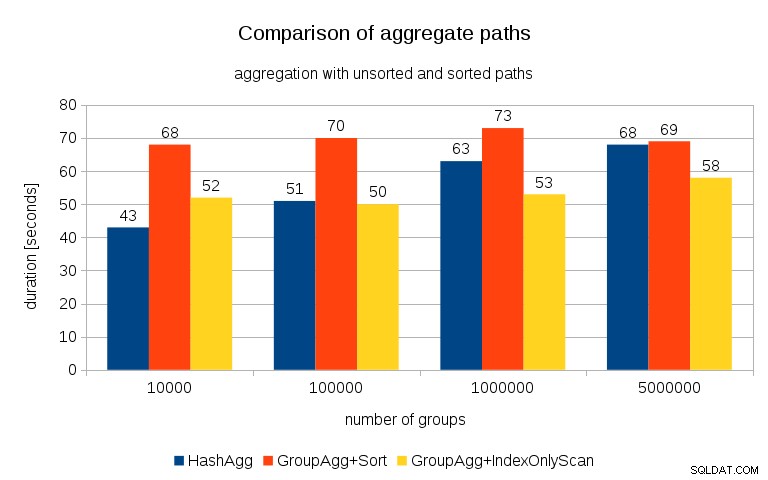
小さなハッシュテーブル(この場合は16MBのL3キャッシュに収まる)の場合、HashAggregateパスは両方のソートされたパスよりも明らかに高速です。しかし、すぐにGroupAgg + IndexOnlyScanが同じくらい速く、またはさらに速くなります。これは、GroupAggregateの主な利点であるキャッシュ効率によるものです。 HashAggregateはハッシュテーブル全体を一度にメモリに保持する必要がありますが、GroupAggregateは最後のグループのみを保持する必要があります。また、使用するメモリが少ないほど、それをL3キャッシュに収める可能性が高くなります。これは、通常のRAMと比較して約1桁高速です(L1 / L2キャッシュの場合、差はさらに大きくなります)。
したがって、IndexOnlyScanに関連するかなりのオーバーヘッドがありますが(10kの場合、HashAggregateパスよりも約20%遅くなります)、ハッシュテーブルが大きくなると、L3キャッシュヒット率が急速に低下し、その差によって最終的にGroupAggregateが高速になります。そして最終的には、GroupAggregate+SortでさえHashAggregateパスと同等になります。
データのグループ数は一般にかなり少ないため、ハッシュテーブルは常にL3キャッシュに収まると主張するかもしれません。ただし、L3キャッシュは、CPUで実行されているすべてのプロセスと、クエリプランのすべての部分で共有されていることを考慮してください。したがって、現在、ソケットあたり最大20MBのL3キャッシュがありますが、クエリはその一部のみを取得し、そのビットは(おそらく非常に複雑な)クエリ内のすべてのノードで共有されます。
更新2016/07/26 :Peter Geogheganのコメントで指摘されているように、データが生成された方法は、おそらく相関関係をもたらします。値(または値のハッシュ)ではなく、メモリ割り当てです。適切にランダム化されたデータを使用してクエリを繰り返しました。つまり、
insert into t_10000 select (10000*random())::bigint, random() from generate_series(1,100000000) s(i);
代わりに
insert into t_10000 select mod(i, 10000), random() from generate_series(1,100000000) s(i);
結果は次のようになります:
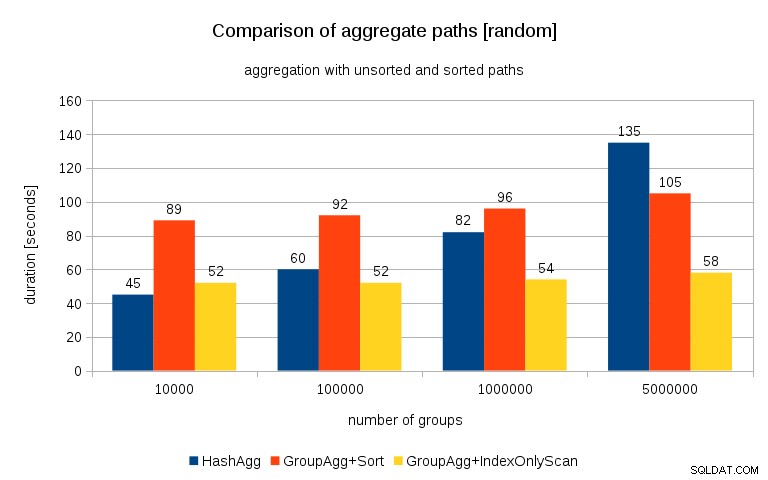
これを前のグラフと比較すると、特に5Mグループのデータセットの場合、結果がソートされたパスをさらに支持していることはかなり明らかだと思います。 5Mデータセットは、明示的な並べ替えを使用したGroupAggがHashAggよりも高速である可能性があることも示しています。
概要
HashAggregateは、明示的な並べ替えを使用したGroupAggregateよりもおそらく高速ですが(ただし、常にそうなるとは言いませんが)、IndexOnlyScanでGroupAggregateを高速に使用すると、HashAggregateよりもはるかに高速になります。
もちろん、正確な計画を直接選択することはできません。計画担当者があなたに代わってそれを行う必要があります。ただし、(a)インデックスを作成し、(b)work_memを設定することで、選択プロセスに影響を与えます。 。そのため、work_memを下げることがあります (およびmaintenance_work_mem )値を指定すると、パフォーマンスが向上します。
ただし、追加のインデックスは無料ではありません。CPU時間(新しいデータを挿入する場合)とディスク容量の両方がかかります。 IndexOnlyScanの場合、インデックスにはクエリによって参照されるすべての列を含める必要があるため、ディスク容量の要件は非常に重要になる可能性があります。通常のIndexScanでは、テーブルに対して大量のランダムI / Oが生成されるため、同じパフォーマンスは得られません(すべてが削除されます)。潜在的な利益)。
もう1つの優れた機能は、パフォーマンスの安定性です。GroupAggregateパスのパフォーマンスはほとんど同じですが、HashAggregateのタイミングがグループの数に応じてどのように発生するかに注意してください。