はじめに
データベースで計算を実行することについては、2つの考え方があります。それは、すばらしいと思う人と間違っている人です。これは、関数、ストアドプロシージャ、生成または計算された列、およびトリガーの世界がすべて太陽の光とバラであるということではありません。これらのツールは絶対確実なものではなく、不適切な実装はパフォーマンスが低下したり、メンテナにトラウマを与えたりする可能性があります。これは、論争の存在を説明するのに役立ちます。
しかし、データベースは、定義上、情報の処理と操作に非常に優れており、それらのほとんどは、ユーザーが同じ制御とパワーを利用できるようにします(SQLiteとMS Accessの程度は低くなります)。外部データ処理プログラムは、何かを実行する前に、多くの場合ネットワークを介してデータベースから情報を引き出す必要があることから始まります。また、データベースプログラムが、ネイティブセット操作、インデックス作成、一時テーブル、およびデータベースの半世紀の進化のその他の成果を最大限に活用できる場合、複雑な外部プログラムには、ある程度のホイールの再発明が必要になる傾向があります。では、データベースを機能させてみませんか?
これが、しない理由です。 データベースをプログラムしたい!
- データベース機能は見えなくなる傾向があります-特にトリガー。この弱点は、データベース内のプログラミングを覚えている、または認識している人が少ないため、データベースと対話するチームやアプリケーションのサイズにほぼ比例します。ドキュメントは役に立ちますが、それだけです。
- SQLは、データセットを操作するために設計された言語です。データセットを操作していないものは特に得意ではなく、他のものが複雑になるほど良くはありません。
- RDBMS機能とSQLダイアレクトは異なります。単純に生成された列は広くサポートされていますが、より複雑なデータベースロジックを他のストアに移植するには、少なくとも時間と労力がかかります。
- データベーススキーマのアップグレードは、通常、アプリケーションのアップグレードよりも複雑です。急速に変化するロジックは他の場所で維持するのが最適ですが、状況が安定したらもう一度確認する価値があります。
- データベースプログラムの管理は、思ったほど簡単ではありません。多くのスキーマ移行ツールは、組織にとってほとんどまたはまったく何もせず、広大な差異と面倒なコードレビューにつながります(sqitchの依存関係グラフと個々のオブジェクトの作り直しはそれを注目に値する例外にし、migraは問題を完全に回避しようとします)。テストでは、pgTAPやutPLSQLなどのフレームワークはブラックボックス統合テストを改善しますが、追加のサポートとメンテナンスのコミットメントも表します。
- 確立された外部コードベースでは、構造の変更は労力とリスクの両方を伴う傾向があります。
一方、SQLは、それが適しているタスクに対して、速度、簡潔さ、耐久性、および自動化されたワークフローを「正規化」する機会を提供します。データモデリングは、昆虫のようにエンティティを板紙に固定するだけではなく、移動中のデータと保存中のデータを区別するのは難しいものです。休息は、細かいグレードでは本当に遅い動きです。情報は常にここからそこへと流れており、データベースのプログラマビリティはそれらの流れを管理および指示するための強力なツールです。
一部のデータベースエンジンは、SQLと他のプログラミング言語の違いを、他のプログラミング言語にも対応することで分割します。 SQL Serverは、任意の.NETFramework言語で記述された関数をサポートしています。 OracleにはJavaストアドプロシージャがあります。 PostgreSQLはCでの拡張を可能にし、Python、Perl、およびTclでユーザーがプログラム可能であり、プラグインはシェルスクリプト、R、JavaScriptなどを追加します。通常の容疑者を締めくくると、それはSQLであるか、MySQLとMariaDBには何もありません。MSAccessはのみ VBAでプログラム可能であり、SQLiteはユーザーがまったくプログラムできません。
SQLが一部のタスクに不十分な場合、または他のコードを再利用したい場合は、SQL以外の言語を使用することもできますが、データベースプログラミングを多目的な剣にする他の問題を回避することはできません。どちらかといえば、これらに頼ると、展開と相互運用性がさらに複雑になります。警告スクリプター:ライターに注意させてください。
関数とプロシージャ
SQL標準の実装の他の側面と同様に、正確な詳細はRDBMSごとに少し異なります。一般的に:
- 関数はトランザクションを制御できません。
- 関数は値を返します。プロシージャは、
OUTで指定されたパラメータを変更する場合があります またはINOUTその後、呼び出し元のコンテキストで読み取ることができますが、結果を返すことはありません(SQL Serverを除く)。 - プロシージャがスタンドアロンである間に、SQLステートメント内から関数を呼び出して、取得または保存されているレコードに対していくつかの作業を実行します。
より具体的には、MySQLは関数内の再帰といくつかの追加のSQLステートメントも許可しません。 SQL Serverは、関数によるデータの変更、動的SQLの実行、およびエラーの処理を禁止しています。 PostgreSQLは、バージョン11の2017年まで、ストアドプロシージャを関数からまったく分離していなかったため、Postgres関数は、トランザクション制御を除いて、プロシージャが実行できるほとんどすべてのことを実行できます。
では、どちらをいつ使用するのですか?関数は、データの保存と取得時にレコードごとに適用するロジックに最適です。自分で呼び出してデータを内部で移動する、より複雑なワークフローは、手順として優れています。
デフォルトと生成
単純な計算でも、十分な頻度で実行されている場合、または複数の競合する実装が存在する場合は、問題が発生する可能性があります。単一行の値の操作(メートル法とインペリアル単位の間の変換、請求書の小計の稼働時間の乗算、地理ポリゴンの面積の計算)をテーブル定義で宣言して、いずれかの問題に対処できます。 :
CREATE TABLE pythag ( a INT NOT NULL, b INT NOT NULL, c DOUBLE PRECISION NOT NULL GENERATED ALWAYS AS (sqrt(pow(a, 2) + pow(b, 2))) STORED);
ほとんどのRDBMSは、「保存された」列と「仮想」で生成された列のどちらかを選択できます。前者の場合、値は行が挿入または更新されたときに計算されて保存されます。これは、バージョン12以降のPostgreSQLおよびMSAccessの唯一のオプションです。仮想生成された列は、ビューのようにクエリされたときに計算されるため、スペースを占有しませんが、より頻繁に再計算されます。どちらの種類も厳しく制限されています。値は、それらが属する行の外側の情報に依存することはできず、更新することもできません。また、個々のRDBMSにはさらに具体的な制限があります。たとえば、PostgreSQLは、生成された列でテーブルを分割することを禁止しています。
生成された列は特殊なツールです。多くの場合、挿入時に値が指定されない場合に必要なのはデフォルトだけです。 now()のような関数 列のデフォルトとして頻繁に表示されますが、ほとんどのデータベースでは、カスタム関数と組み込み関数が許可されています(MySQLを除き、current_timestampのみ デフォルト値の場合があります。
YYYYXXX形式のロット番号のかなり乾燥しているが単純な例を見てみましょう。最初の4桁は現在の年を表し、後の3桁は増分カウンターを表します。今年生成される最初のロットは2020001、2番目のロットは2020002というように続きます。 。このような値を生成するデフォルトのタイプや組み込み関数はありませんが、ユーザー定義関数は、作成時に各ロットに番号を付けることができます
CREATE SEQUENCE lot_counter;CREATE OR REPLACE FUNCTION next_lot_number () RETURNS TEXT AS $$BEGIN RETURN date_part('year', now())::TEXT || lpad(nextval('lot_counter'::REGCLASS)::TEXT, 2, '0');END;$$LANGUAGE plpgsql;CREATE TABLE lots ( lot_number TEXT NOT NULL DEFAULT next_lot_number () PRIMARY KEY, current_quantity INT NOT NULL DEFAULT 0, target_quantity INT NOT NULL, created_at TIMESTAMPTZ NOT NULL DEFAULT now(), completed_at TIMESTAMPTZ, CHECK (target_quantity > 0));
関数でのデータの参照
上記のシーケンスアプローチには、1つの重要な弱点があります(そしてlot_counter ただし、1年に作成されたロット数を追跡する方法は複数あります。lotsをクエリすることで、12月31日と同じ値になります。 それ自体がnext_lot_number 関数は、年がロールオーバーした後、正しい値を保証できます。
CREATE OR REPLACE FUNCTION next_lot_number () RETURNS TEXT AS $$BEGIN RETURN ( SELECT date_part('year', now())::TEXT || lpad((count(*) + 1)::TEXT, 2, '0') FROM lots WHERE date_part('year', created_at) = date_part('year', now()) );END;$$LANGUAGE plpgsql;ALTER TABLE lots ALTER COLUMN lot_number SET DEFAULT next_lot_number();
ワークフロー
シングルステートメント関数でさえ、外部コードに比べて決定的な利点があります。実行すると、データベースのACID保証の安全性が失われることはありません。 next_lot_numberを比較します 上記のクライアントアプリケーションまたは手動プロセスの可能性について、
SQLには、例外処理からセーブポイントまで、手続き型コードを記述するために必要なすべてのツールが含まれているため、マルチステートメントストアドプログラムは非常に多くの可能性を開きます(ウィンドウ関数と一般的なテーブル式を備えたチューリング完全です!)。データ処理ワークフロー全体をデータベースで実行できるため、システムの他の領域への露出を最小限に抑え、データベースと他のドメイン間の時間のかかるラウンドトリップを排除できます。
一般に、ソフトウェアアーキテクチャの多くは、複雑さを管理および分離し、サブシステム間の境界を越えてこぼれるのを防ぐことを目的としています。多かれ少なかれ複雑なワークフローに、データをアプリケーションのバックエンド、スクリプト、またはcronジョブにプルし、データをダイジェストして追加し、結果を保存することが含まれる場合は、データベースの外に出かける必要があるのは何かを尋ねるときです。
前述のように、これはRDBMSフレーバーとSQLダイアレクトの違いが前面に出てくる領域です。あるデータベース用に開発された関数またはプロシージャは、SQLServerのTOPに置き換わるかどうかに関係なく、変更なしではおそらく別のデータベースでは実行されません。 標準のLIMITの場合 OracleからPostgreSQLへのエンタープライズ移行で一時的な状態がどのように保存されるかを条項または完全に作り直します。 SQLでワークフローを正規化すると、現在のプラットフォームにコミットし、他のほとんどの選択よりも徹底的に方言を使用できます。
クエリでの計算
これまで、テーブル定義にバインドされているか、マルチテーブルワークフローを管理しているかにかかわらず、関数を使用してデータを格納および変更する方法について説明してきました。ある意味では、それはそれらを使用できるより強力な使用法ですが、関数はデータ検索にも使用できます。クエリですでに使用している可能性のある多くのツールは、countなどの標準の組み込み関数から関数として実装されています。 Postgresのjsonb_build_objectなどの拡張機能へ 、PostGISのST_SnapToGrid 、 もっと。もちろん、これらはデータベース自体とより緊密に統合されているため、ほとんどの場合SQL以外の言語で記述されています(たとえば、PostgreSQLやPostGISの場合はC)。
データを取得してから、実際にになる前に各レコードに対して何らかの操作を実行する必要があることがよくある場合(または自分自身を見つける可能性があると思う場合)。 準備ができたら、代わりにデータベースから出る途中でそれらを変換することを検討してください!日付から数営業日を予測しますか? 2つのJSONB間の差分を生成する 田畑?実際には、クエリしている情報のみに依存する計算はSQLで実行できます。そして、データベースで行われることは、データベースが一貫してアクセスされている限り、データベースの上に構築されたものに関する限り、標準的です。
言わなければならないことです。アプリケーションバックエンドを使用している場合、そのデータアクセスツールキットは、関数を使用してクエリ結果を拡張することで得られるマイレージを制限する可能性があります。このようなライブラリのほとんどは任意のSQLを実行できますが、モデルクラスに基づいて一般的なSQLステートメントを生成するライブラリでは、クエリSELECTのカスタマイズが許可される場合と許可されない場合があります。 リスト。生成された列またはビューがここでの答えになります。
トリガーと結果
関数と手順はデータベース設計者とユーザーの間で十分に論争がありますが、本当に トリガーで離陸します。トリガーは、別のアクションの前、後、または代わりに実行される自動アクション(通常はプロシージャ(SQLiteでは単一のステートメントのみを許可))を定義します。
開始アクションは通常、テーブルへの挿入、更新、または削除であり、トリガープロシージャは通常、各レコードまたはステートメント全体のいずれかに対して実行するように設定できます。 SQL Serverでは、主に、より詳細なセキュリティ対策を実施する方法として、更新可能なビューでトリガーを使用することもできます。そして、PostgreSQL、およびOracleはすべて、何らかの形式のイベントまたは
トリガーの一般的な低リスクの使用法は、無効なデータが保存されるのを防ぐ非常に強力な制約としてです。すべての主要なリレーショナルデータベースでは、主キーと外部キー、およびUNIQUEのみ 制約は、候補レコード外の情報を評価できます。たとえば、1か月に2つのロットしか作成できないことをテーブル定義で宣言することはできません。また、最も単純なデータベースとコードのソリューションは、カウントしてから設定するアプローチと同様の競合状態に対して脆弱です。 lot_number その上。テーブル全体または他のテーブルを含む他の制約を適用するには、
CREATE FUNCTION enforce_monthly_lot_limit () RETURNS TRIGGERAS $$DECLARE current_count BIGINT;BEGIN SELECT count(*) INTO current_count FROM lots WHERE date_trunc('month', created_at) = date_trunc('month', NEW.created_at); IF current_count >= 2 THEN RAISE EXCEPTION 'Two lots already created this month'; END IF; RETURN NEW;END;$$LANGUAGE plpgsql;CREATE TRIGGER monthly_lot_limitBEFORE INSERT ON lotsFOR EACH ROWEXECUTE PROCEDURE enforce_monthly_lot_limit();
lotsへのレコードの挿入 それ自体が、ordersへの挿入によって開始されるトリガーの最終操作である可能性があります 、lotsへの書き込みを許可された人間のユーザーやアプリケーションのバックエンドはありません 直接。またはitemsとして ロットに追加されると、そこでトリガーがcurrent_quantityの更新を処理する可能性があります 、target_quantityに到達したら、他のプロセスを開始します 。
トリガーと関数は、それらの定義者のアクセスレベルで実行できます(PostgreSQLでは、SECURITY DEFINER 関数のLANGUAGEの横にある宣言 )。これにより、制限のあるユーザーがより広範囲のプロセスを開始できるようになり、それらのプロセスの検証とテストがさらに重要になります。
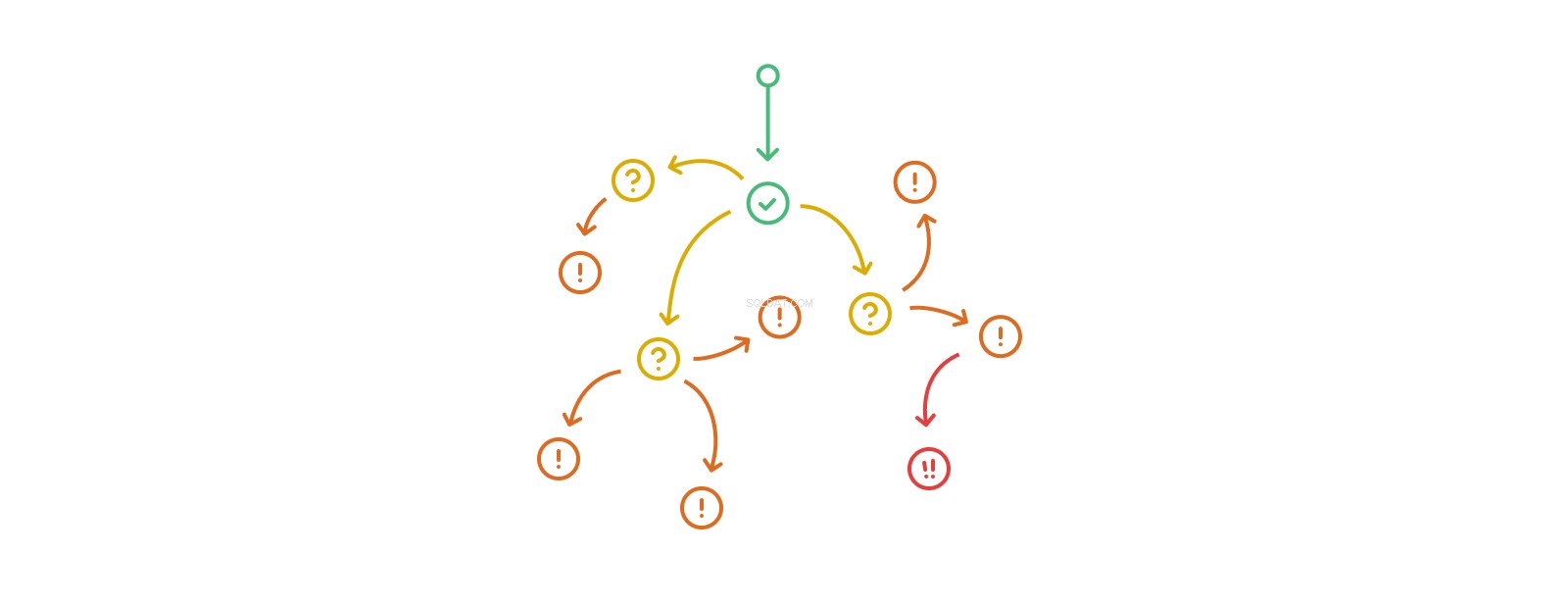
トリガー-アクション-トリガー-アクションの呼び出しスタックは任意に長くなる可能性がありますが、同じテーブルまたはレコードをそのようなフローで複数回変更するという形での真の再帰は、一部のプラットフォームでは違法であり、より一般的にはほとんどすべての状況で悪い考えです。トリガーネスティングは、その範囲と効果を理解する能力を急速に上回ります。ネストされたトリガーを多用するデータベースは、複雑な領域から複雑な領域へと移行し始め、分析、デバッグ、および予測が困難または不可能になります。
実用的なプログラマビリティ
データベース内の計算は、より高速で簡潔に表現されるだけでなく、あいまいさを排除し、標準を設定します。上記の例では、データベースユーザーが自分でロット番号を計算する必要がないことや、誤って処理できるよりも多くのロットを作成することを心配する必要がありません。特にアプリケーション開発者は、データベースを「ダムストレージ」と見なし、構造と永続性のみを提供するように訓練されていることが多いため、データベースの外部で何ができるかを不器用に表現していることに気付くことがあります。 SQLでより効果的に。
プログラマビリティは、リレーショナルデータベースの不当に見過ごされている機能です。それを回避する理由は他にもありますが、関数、プロシージャ、トリガーはすべて、データモデルが組み込まれているシステムに課す複雑さを制限するための強力なツールです。