はじめに
アプリケーションのパフォーマンス、信頼性、およびスケーリングの要件に一致させるために必要なデータベースインフラストラクチャの種類を把握することは、困難な作業になる可能性があります。データベーストポロジに対して行う選択は、アプリケーションスタック全体がさまざまなタイプの使用にどのように応答するか、およびどのような障害シナリオを説明できるかに影響を与える可能性があります。このため、選択肢を理解し、目標に沿った情報に基づいた決定を下すことが重要です。
すべてのインフラストラクチャのニーズを処理する単一のデータベースから、より複雑なシステムに移行するには、さまざまな方法があります。これに加えて、考慮すべき多くのトレードオフがあります。
このガイドでは、リレーショナルデータベースインフラストラクチャの最も一般的なパターンのいくつかと、それらがさまざまな使用パターンにどのように対応するかを紹介します。各構成が提供する利点と、説明する必要のあるいくつかの欠点について説明します。また、さまざまな決定が全体的な運用の複雑さに与える影響についても説明します。完了したら、現在のニーズに最適なデザインと、ニーズの変化に応じて実験したいオプションについて、より適切な決定を下せるようになります。
垂直方向のスケーリング
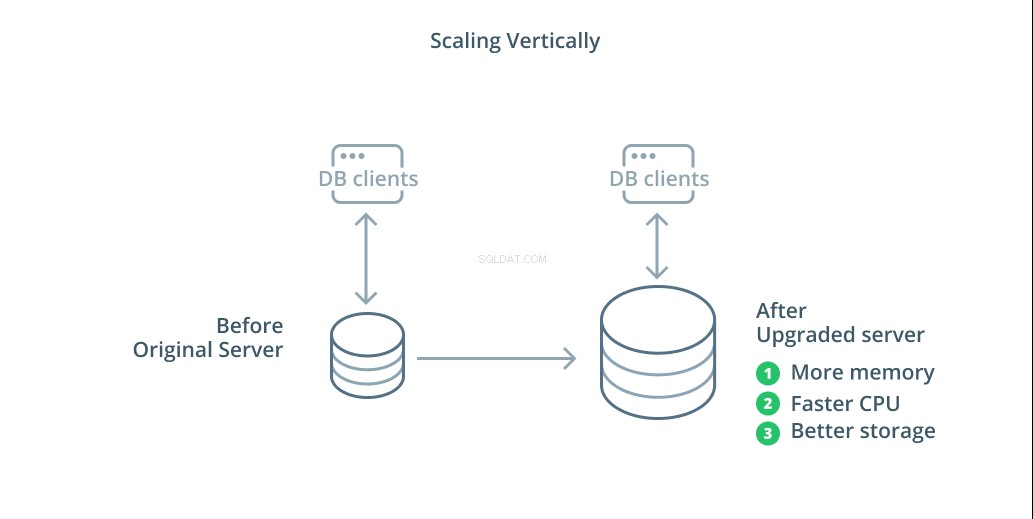
データベースシステムをスケーリングする最も簡単な方法は、垂直スケーリングです。 垂直方向のスケーリング 、スケールアップとも呼ばれます は、データベースを管理するサーバーに容量を追加することを意味します。処理能力、メモリ割り当て、またはストレージ容量を増やすことで、システム全体の複雑さを増すことなく、データベースシステムが処理できるパフォーマンスとボリュームを増やすことができます。
原則として、データベースのスケールアップは、インフラストラクチャトポロジに影響を与えることなくデータベースの機能を向上させるため、最初の良いステップです。大容量のマシンは、同期されるまでレプリケーションフォロワーとして構成でき、その後フェイルオーバーをトリガーして新しいプライマリサーバーにすることができるため、スケールアップも通常はかなり簡単です。
ただし、1台のマシンに合理的に割り当てることができるリソースの量が制限されるため、スケールアップには制限があります。また、問題が発生したときに引き継ぐようにレプリケーションフォロワーが構成されていない場合は、単一障害点を表します。これらの懸念は、他のスケーリングオプションのいくつかによって対処されます。
コマンドクエリ責任分離(CQRS)および読み取り専用レプリカ
データベースインフラストラクチャをスケールアウトするもう1つの主要な方法は、スケールアウトすることです。 スケールアウト つまり、単一のサーバーの容量を増やす代わりに、特定のニーズに対応するための専用サーバーの数を増やすことになります。したがって、インフラストラクチャにマシンを追加することで容量を追加します。
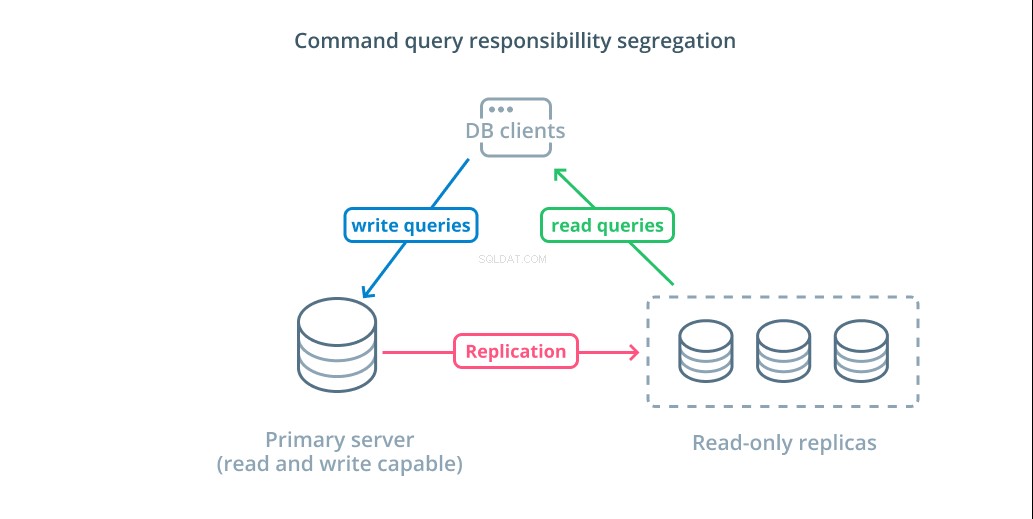
コマンドクエリの責任の分離 (CQRS)は、データを変更するクエリ(書き込みクエリ)と変更しないクエリ(読み取りクエリ)を分離するロジックを追加することを説明するために使用される用語です。これにより、これらのさまざまなカテゴリのリクエストをさまざまなホストにルーティングして、負荷を分散させることができます。
この設計を利用するための最も基本的なインフラストラクチャは、読み取りおよび書き込みクエリを受け入れることができるプライマリサーバーと、読み取りクエリを受け入れることができるプライマリサーバーに続く1つ以上のレプリカサーバーを組み合わせたものです。この設計は、読み取り操作が任意のデータベースサーバーで処理できるため、読み取りが多いアプリケーションの使用パターンに適しています。
さらに、このシステムは、サーバーのいずれかがダウンしてもシステムが機能するため、アーキテクチャにある程度の冗長性を提供します。フォロワーがダウンした場合、読み取り要求を他のサーバーにルーティングできます。プライマリサーバーがダウンした場合、レプリカフォロワーの1つを昇格させて書き込みクエリを受け入れることができます。
マルチプライマリレプリケーション
読み取り専用レプリカでCQRSを使用すると、より多くの読み取り要求に対応できますが、インフラストラクチャの書き込みパフォーマンスに大きな影響を与えることはありません。アーキテクチャが処理できる書き込みの数を増やすには、マルチプライマリレプリケーション設計を採用できるかどうかを検討する必要があります。
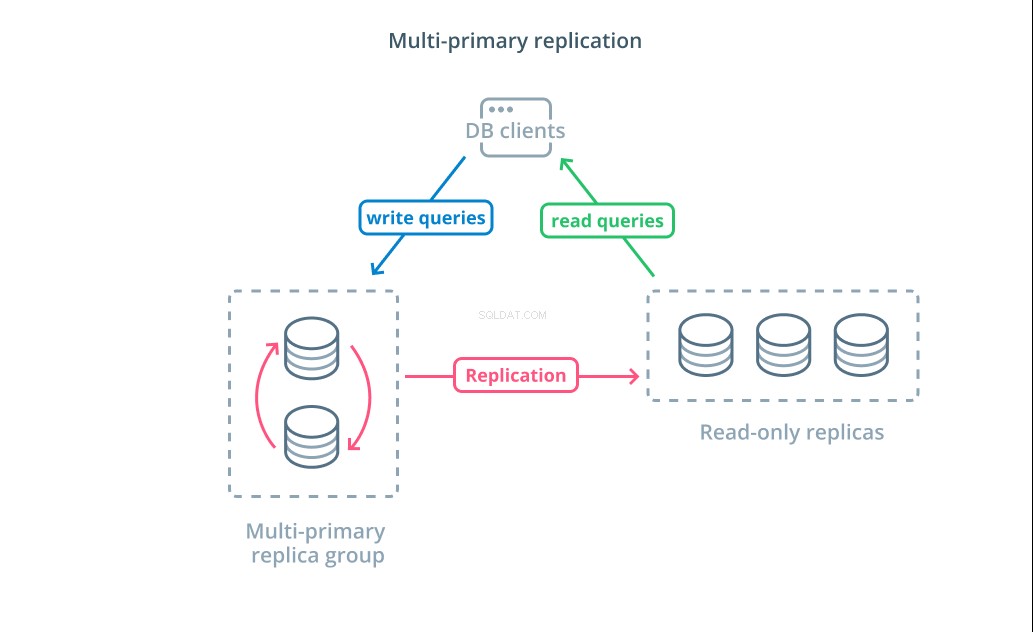
マルチプライマリレプリケーション は、複数のサーバーが書き込み要求を受け入れることができるレプリケーションの形式です。一部のシステムは、任意のサーバーが書き込み要求を処理できるように構成されていますが、他のシステムは、プライマリサーバーのコアグループが多数の読み取り専用フォロワーで書き込みを処理するように設計されています。実装に関係なく、マルチプライマリレプリケーションは書き込みクエリを担当するサーバーの数を増やします。
この設計は最初は理想的に聞こえますが、これが広く採用されるパターンになるのを妨げるいくつかの大きな課題があります。複数のサーバーが書き込み要求を処理できますが、サーバー間で変更を複製し、データ変更の競合を解決するために調整する必要があります。これにより、競合がネゴシエートされるために応答時間が長くなるか、データに一貫性がなくなる可能性があります。
各システムは、これらの課題を処理するために独自のアプローチを選択します。これはCAP定理のデモンストレーションです。 —分散システムにおける一貫性、可用性、およびパーティション許容度の間の相互作用を説明するステートメント—実行中。一部のシステムは、可用性を維持するための弱い整合性保証を提供しますが、他のデータベースは、書き込み時にピアがトランザクションを調整できない場合、変更を受け入れることを拒否します。さまざまな実装を決定する際には、ニーズに最適なアプローチを選択することが重要な要素です。
読み取りクエリキャッシュ
読み取り専用レプリカを使用することは、読み取り要求に応答できる使用可能なデータベースを増やす方法ですが、複雑な読み取り操作の基本的なクエリパフォーマンスを向上させることはありません。結果が前のルックアップと同じであっても、サーバーの1つは、要求が行われるたびに読み取り操作を実行することが期待されます。
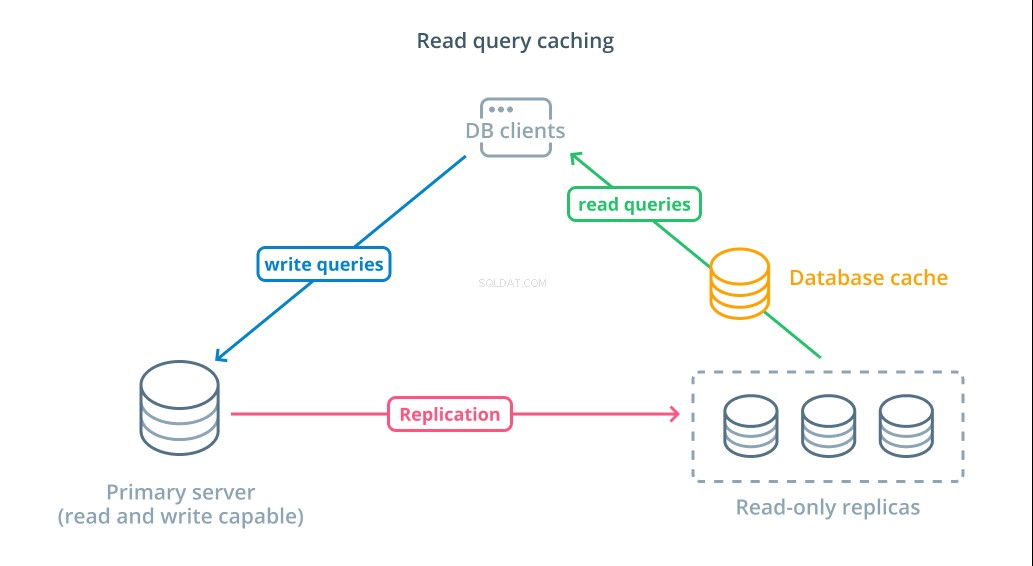
応答時間を短縮するには、読み取りクエリキャッシュ レイヤーを導入することができます。データベースクライアントとデータベース自体の間にキャッシュを追加すると、一般的な要求のクエリ時間を大幅に短縮できます。アプリケーションは、キャッシュからの読み取り結果を要求し、利用可能な場合はほぼ即座にそれらを受信できます。結果がキャッシュに見つからない場合は、データベース自体から取得され、次回のためにキャッシュに追加されます。
このようにキャッシュを構成することは、要求が行われるたびにデータが変更される可能性が低いシナリオでは非常に効率的です。これは、複数のテーブルを参照し、複雑な結合操作を含む高価な読み取りクエリに特に役立ちます。これらの結果は一度実行してから、将来のクエリのために保存できます。
データがより急速に変化している場合、読み取りキャッシュはそれほど役に立たない可能性があります。構成された動作に応じて、キャッシュはこれらの状況で古いデータを返すリスクがあり、変更されたときに古いデータをキャッシュから排除するために、慎重なキャッシュ無効化戦略を実装する必要があります。
データシャーディング
これまで説明してきた設計では、書き込み要求に応答するかどうかに基づいてデータベースコンポーネントをセグメント化してきました。ただし、責任を分割する別の方法は、実際のデータセットを複数の部分に分割することです。
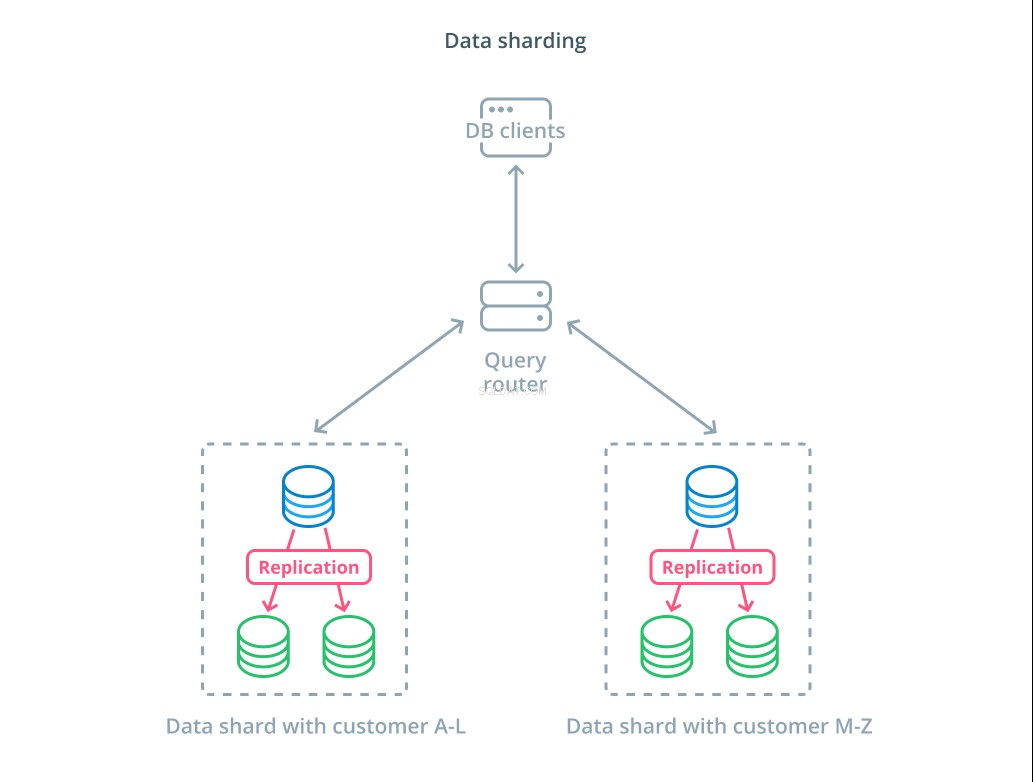
シャーディング 論理データセットをより小さなサブセットに分割して、それらの管理を異なるマシンに分散するプロセスです。各データベースサーバーはデータの一部のみを処理し、どのマシンがどのデータの一部を担当しているかを理解するルーティングメカニズムが導入されています。
通常、シャーディングは、データセット全体を一度に操作する必要がないか、一般的でないシナリオで実行されます。データセットは、シャーディングキーと呼ばれる特定のキーの各レコードの値に基づいてセグメント化されます。 。たとえば、顧客の場所に基づいてデータを手動でシャーディングできます。また、ハッシュアルゴリズムを使用して自動的にシャーディングし、どのノードがどのキーを処理するかを決定することもできます。これにより、シャードキースペースが不均一に分散されている場合に、システムが不均衡な分散を回避できます。
シャーディングはデータシステムにかなりの複雑さをもたらし、すべてのシナリオに適しているわけではありません。複数のシャードと相互作用する操作は、各メンバーから結果を取得するため、パフォーマンスが大幅に低下します。これは、集約クエリの場合、または特定のシャードキーが事前にわからない場合に発生する可能性があります。さらに、シャードの不均等な割り当ては、データセット全体の分散を再調整することによって修正する必要がある非効率性とボトルネックを引き起こす可能性もあります。
分散型機能データ管理
多くの場合、データセットの値を複数のセグメントに分割するよりも、さまざまな機能目的でさまざまなデータベースを使用する方が理にかなっています。たとえば、アカウントサービスと製品サービスがある場合、それぞれの懸念事項に一致する専用のデータベースがあると、さまざまなコンポーネントを個別に拡張するのに役立ちます。
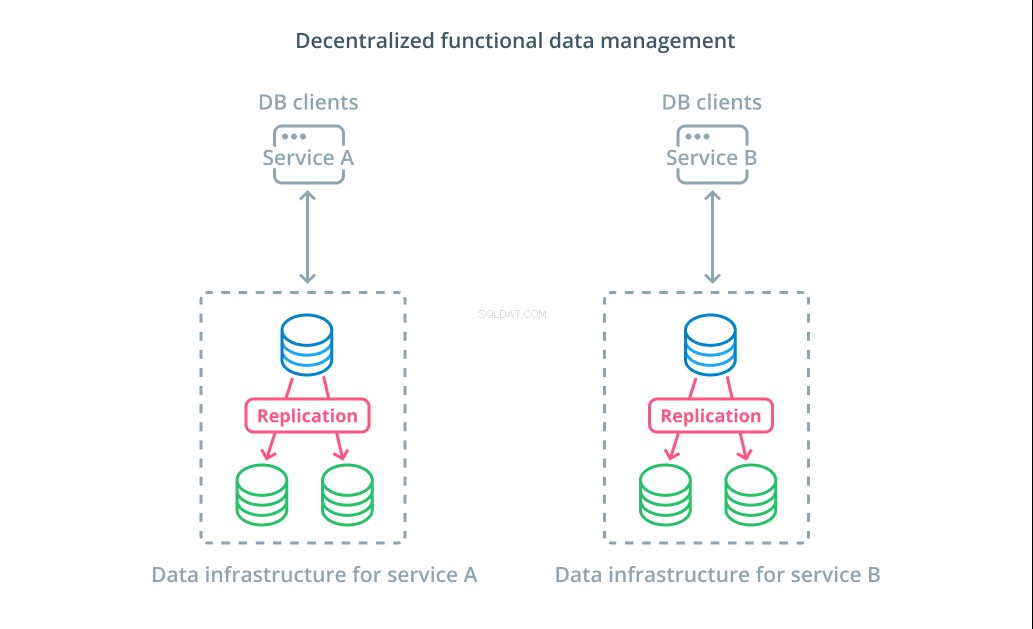
機能データ管理を使用すると、データベースインフラストラクチャを分割し、クライアントのニーズに応じて各部分を管理できます。各機能部分は、最も意味のある戦略を使用してスケーリングできます。これにより、データベーススキーマを設計し、組織全体にサービスを提供する必要がなく、特定のユースケースのパターンに最適な場所にデプロイできます。
多くの組織にとって、この戦略には、実際のシステムの特性を超える重要な利点があります。データ管理を分散化することで、小規模なチームが他の関係者と変更を調整することなく、独自のデータを所有できるようになります。これは、マイクロサービス指向のアプリケーションアーキテクチャによって促進される関心の分離に焦点を合わせています。
サーバーレスデータベース
評価しなければならないさまざまなトレードオフと、適切なスケーリングのために管理することが期待されるインフラストラクチャの量は、多くの人にとって圧倒される可能性があります。この複雑さを軽減するための1つのオプションは、インフラストラクチャを管理し、拡張するデータベースサービスを利用することです。
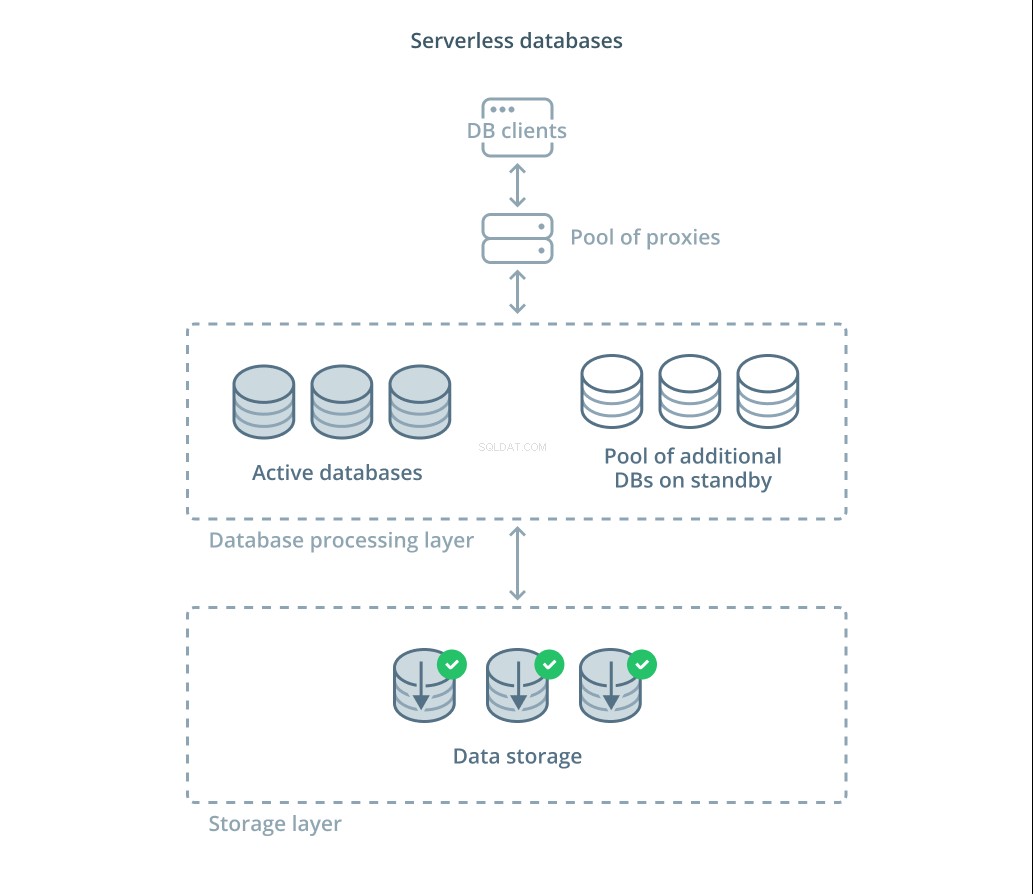
サーバーレスデータベース は、データストレージをデータ処理から切り離して、需要の変化に応じてリソースを簡単に拡張できるサービスのカテゴリです。
データストレージレイヤーは、システムによって管理される実際のデータを維持する責任があります。このレイヤーの前に、データセットに対する実際のクエリ処理を処理するために、スケーラブルなデータベース処理ユニットの層が展開されます。常にアクティブなユニットの数は現在の使用量に直接関係しているため、需要のピーク時に割り当てられるリソースが増え、物事が静まると処理ユニットはスタンバイに戻ります。
クエリは、アクティブノードにリクエストを転送する方法と追加のリソースをリクエストするタイミングを知っているルーティングプロキシを介してデータベースプロセッサに転送されます。
サーバーレスデータベースには、自動スケーリング機能を実装する従来のデータベースサービスと同じプロパティが多数あります。どちらも需要に基づいて容量を割り当てることができます。ただし、サーバーレスデータベースを使用すると、ストレージコストを処理コストから分離でき、不要な場合は処理をゼロまでスケールダウンできます。さらに、サーバーレスソリューションは、従来のサービスで提供される自動スケーリングと比較して、需要を満たすためにはるかに迅速にスケールアップできる傾向があります。
サーバーレスデータベースは一部の人には適しているかもしれませんが、特効薬ではありません。データベースプロセッサがあった場合 ゼロにスケールダウンすると、コールドスタートのために処理が再び遅れる可能性があります。さらに、サーバーレスデータベーススタック内のさまざまなコンポーネント間の接続を介したチャーンにより、遅延が増える可能性があります。
サーバーレスデータベースプラットフォームも、運用の観点から難しい場合があります。展開とデータベースの変更は、推論と監視がより困難になる可能性があります。データベースシステムの動的な状態のために、ローカル開発環境も本番環境と大幅に異なる場合があります。そして最後に、他のクラウドサービスと同様に、サーバーレスデータベースを使用すると、ベンダーロックインの危険にさらされる可能性があります。サーバーレスプラットフォームを中心に設計する場合は、これらのトレードオフを覚えておくことが重要です。
結論
アプリケーション要件がより深刻になるにつれて、データベースインフラストラクチャを設計、展開、および管理する方法は多数あります。各ソリューションには長所と制限があり、環境に適したものを見つけようとするときに理解することが重要です。
データベースインフラストラクチャがデータの可用性、パフォーマンス、および整合性にどのように影響するかを知ることで、必要な保証を提供しないコストのかかるミスや実装を回避できます。上記の設計のいずれかが要件を満たしていない場合は、さまざまなアプローチの要素のいくつかを組み合わせて、追加の利点を得ることができる場合があります。
上記の一般的なパターンについて詳しく知りたい場合は、以下のリソースを確認してください。
- スケールアップとスケールアウト
- コマンドクエリの責任の分離
- マルチプライマリレプリケーション
- 読み取りクエリのキャッシュ
- データシャーディング
- 分散型データ管理
- サーバーレスデータベース