SQLServer2005とSQLServer2008の間でパーティション化されたテーブルの内部表現が変更された結果、ほとんどの場合(特に並列実行が含まれる場合)、クエリプランとパフォーマンスが向上しました。残念ながら、同じ変更により、SQL Server 2005でうまく機能していたものが、SQLServer2008以降では突然うまく機能しなくなったことがあります。この投稿では、SQLServer2005クエリオプティマイザーが後のバージョンと比較して優れた実行プランを作成した1つの例を紹介します。
サンプルテーブルとデータ
この投稿の例では、次のパーティションテーブルとデータを使用しています。
CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES
(
10000, 20000, 30000, 40000, 50000,
60000, 70000, 80000, 90000, 100000,
110000, 120000, 130000, 140000, 150000
);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
GO
CREATE TABLE dbo.T4
(
RowID integer IDENTITY NOT NULL,
SomeData integer NOT NULL,
CONSTRAINT PK_T4
PRIMARY KEY CLUSTERED (RowID)
ON PS (RowID)
);
INSERT dbo.T4 WITH (TABLOCKX)
(SomeData)
SELECT
ABS(CHECKSUM(NEWID()))
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
CREATE NONCLUSTERED INDEX nc1
ON dbo.T4 (SomeData)
ON PS (RowID); パーティション化されたデータレイアウト
このテーブルには、パーティション化されたクラスター化インデックスがあります。この場合、クラスタリングキーはパーティショニングキーとしても機能します(ただし、これは一般的に必須ではありません)。パーティション化すると、クエリプロセッサが単一のエンティティとしてユーザーに提示する個別の物理ストレージユニット(行セット)が生成されます。
次の図は、テーブルの最初の3つのパーティションを示しています(クリックして拡大):
非クラスター化インデックスは同じ方法でパーティション化されます(「整列」されます):

非クラスター化インデックスの各パーティションは、RowID値の範囲をカバーします。各パーティション内で、データはSomeDataによって順序付けられます(ただし、RowID値は一般的に順序付けられません)。
MIN/MAX問題
MINはかなりよく知られています およびMAX 集約は、パーティション化されたテーブルでは適切に最適化されません(集約される列がパーティション化列でもある場合を除く)。この制限(SQL Server 2014 CTP 1にはまだ存在します)は、何年にもわたって何度も書かれてきました。私のお気に入りの報道は、ItzikBen-Ganによるこの記事にあります。この問題を簡単に説明するために、次のクエリを検討してください。
SELECT MIN(SomeData) FROM dbo.T4;
SQLServer2008以降の実行プランは次のとおりです。

このプランはインデックスから150,000行すべてを読み取り、Stream Aggregateが最小値を計算します(代わりに最大値を要求した場合、実行プランは基本的に同じです)。 SQL Server 2005の実行プランは少し異なります(これ以上はありません):
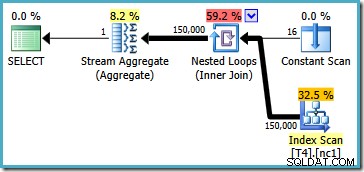
このプランは、一度にパーティションを完全にスキャンするパーティション番号(コンスタントスキャンにリストされている)を繰り返し処理します。 150,000行すべてが、最終的にStreamAggregateによって読み取られて処理されます。
パーティション化されたテーブルとインデックスの図を振り返り、データセットでクエリをより効率的に処理する方法を考えてください。非クラスター化インデックスは、集計の計算時に悪用される可能性のある順序でSomeData値が含まれているため、クエリを解決するのに適しているようです。
さて、インデックスがパーティション化されているという事実は少し複雑です:各パーティション インデックスのはSomeData列で並べ替えられますが、特定のから最小値を単純に読み取ることはできません。 クエリ全体に対する正しい答えを得るためにパーティションを作成します。
問題の本質が理解されると、人間は、効率的な戦略は、各パーティションでSomeDataの単一の最小値を見つけることであることがわかります。 インデックスの値を取得し、パーティションごとの結果から最小値を取得します。
これは基本的に、Itzikが彼の記事で提示している回避策です。クエリを書き直して、パーティションごとの集計を計算します(APPLYを使用) 構文)そして、それらのパーティションごとの結果を再度集計します。そのアプローチを使用して、書き直されたMIN クエリはこの実行プランを生成します(正確な構文についてはItzikの記事を参照してください):
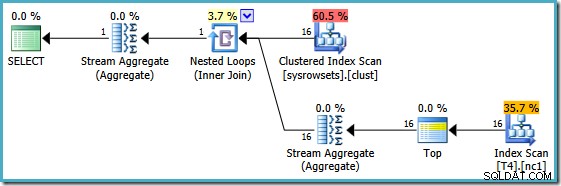
このプランは、システムテーブルからパーティション番号を読み取り、各パーティションのSomeDataの最小値を取得します。最終的なStreamAggregateは、パーティションごとの結果の最小値を計算するだけです。
このプランの重要な機能は、単一行を読み取ることです。 各パーティションから(各パーティション内のインデックスのソート順を利用)。テーブル内の150,000行すべてを処理するオプティマイザーの計画よりもはるかに効率的です。
単一のパーティション内のMINとMAX
次に、次のクエリを検討して、単一のパーティション内に含まれているRowID値の範囲について、SomeData列の最小値を見つけます。 :
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 18000;
オプティマイザでMINに問題があることがわかりました およびMAX 複数のパーティションにまたがっていますが、これらの制限は単一のパーティションクエリには適用されないと予想されます。
単一のパーティションは、RowID値10,000および20,000で囲まれたパーティションです(パーティション化関数の定義に戻って参照してください)。パーティショニング関数はRANGE RIGHTとして定義されました したがって、10,000境界値はパーティション#2に属し、20,000境界値はパーティション#3に属します。したがって、新しいクエリで指定されたRowID値の範囲は、パーティション2のみに含まれます。
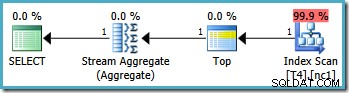
このクエリのグラフィカルな実行プランは、2005以降のすべてのSQLServerバージョンで同じように見えます。
計画分析
オプティマイザーは、WHEREで指定されたRowID範囲を取得しました 節を作成し、それをパーティション関数定義と比較して、非クラスター化インデックスのパーティション2のみにアクセスする必要があることを確認しました。インデックススキャンのSQLServer2005プランのプロパティは、単一パーティションアクセスを明確に示しています。
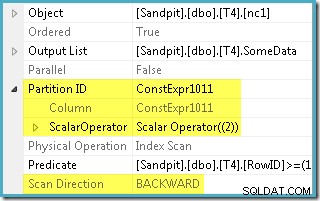
他の強調表示されたプロパティはスキャン方向です。スキャンの順序は、クエリが最小または最大のSomeData値を探しているかどうかによって異なります。非クラスター化インデックスは、SomeData値の昇順で(パーティションごとに、覚えておいてください)順序付けられるため、インデックススキャンの方向はFORWARDです。 クエリが最小値を要求する場合、およびBACKWARD 最大値が必要な場合(上のスクリーンショットはMAXから取得したものです クエリプラン)。
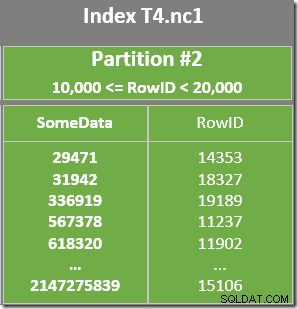
インデックススキャンには、パーティション2からスキャンされたRowID値がWHEREと一致することを確認するための述語も残っています。 節述語。オプティマイザーは、RowID値が非クラスター化インデックスを介してかなりランダムに分散されていると想定しているため、WHEREに一致する最初の行を見つけることを想定しています。 節の述語は非常に迅速です。パーティション化されたデータレイアウト図は、RowID値が実際にインデックス内で非常にランダムに分散されていることを示しています(SomeData列が覚えている順序で並べられています):
クエリプランのTop演算子は、インデックススキャンを単一の行に制限します(スキャン方向に応じて、インデックスの下限または上限のいずれかから)。インデックススキャンはクエリプランで問題になる可能性がありますが、Top演算子を使用すると、ここで効率的なオプションになります。スキャンで生成できる行は1つだけで、その後停止します。上位と順序付きのインデックススキャンの組み合わせは、WHEREにも一致するインデックスの最高値または最低値へのシークを効果的に実行します 節の述語。 NULLを確実にするために、StreamAggregateもプランに表示されます インデックススキャンによって行が返されない場合に生成されます。スカラーMIN およびMAX 集計は、NULLを返すように定義されています 入力が空のセットの場合。
全体として、これは非常に効率的な戦略であり、計画の推定コストはわずか 0.0032921 です。 結果としてユニット。これまでのところ良いです。
境界値問題
次の例では、RowID範囲の上限を変更します。
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 20000;
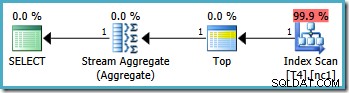
クエリが除外していることに注意してください 「未満」演算子を使用した20,000の値。パーティション関数はRANGE RIGHTとして定義されているため、20,000の値はパーティション3(パーティション2ではない)に属していることを思い出してください。 。 SQL Server 2005 オプティマイザーはこの状況を正しく処理し、 0.0032878の推定コストで最適な単一パーティションクエリプランを生成します :
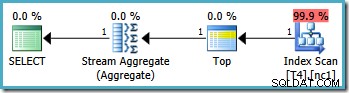
ただし、同じクエリを使用すると、SQL Server2008以降で異なるプランが生成されます。 (SQL Server 2014 CTP 1を含む):
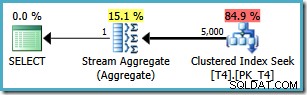
これで、クラスター化されたインデックスシークができました(目的のインデックススキャンとトップ演算子の組み合わせの代わりに)。 WHEREに一致する5,000行すべて 句は、この新しい実行プランのStreamAggregateを介して処理されます。この計画の推定費用は0.0199319 ユニット–6回以上 SQLServer2005プランのコスト。
原因
SQL Server 2008(およびそれ以降)のオプティマイザーは、間隔が参照するときに内部ロジックを正しく取得しませんが、ただし除外します 、別のパーティションに属する境界値。オプティマイザーは、複数のパーティションがアクセスされると誤って判断し、MINに単一パーティションの最適化を使用できないと結論付けます。 およびMAX 骨材。
回避策
1つのオプションは、> =および<=演算子を使用してクエリを書き直し、別のパーティションから境界値を参照しないようにすることです(除外する場合でも!):
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID <= 19999;
これにより、単一のパーティションに触れる最適な計画が作成されます。
残念ながら、この方法で正しい境界値を指定できるとは限りません(パーティショニング列のタイプによって異なります)。その一例は、ハーフオープン間隔を使用するのが最適な日付と時刻のタイプです。この回避策に対するもう1つの反対意見は、より主観的なものです。分割関数は範囲から1つの境界を除外するため、ハーフオープン間隔構文も使用してクエリを作成するのが最も自然なようです。
2番目の回避策は、パーティション番号を明示的に指定することです(そして、ハーフオープン間隔を保持します):
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 20000 AND $PARTITION.PF(RowID) = 2;
これにより、最適なプランが作成されますが、追加の述語が必要になり、ユーザーがパーティション番号を決定する必要があります。
もちろん、2008年以降のオプティマイザーがSQLServer2005と同じ最適な計画を作成したほうがよいでしょう。完璧な世界では、より包括的なソリューションでマルチパーティションのケースにも対応できるため、Itzikが説明している回避策も不要になります。