はじめに
最近、トランザクションを深刻な速度で処理するSQLServerデータベースの1つで興味深いパフォーマンスの問題が発生しました。これらのトランザクションをキャプチャするために使用されるトランザクションテーブルは、ホットテーブルになりました。その結果、問題はアプリケーション層に現れました。トランザクションの投稿を求めるセッションが断続的にタイムアウトしました。
これは、セッションが通常、テーブルを「保持」し、データベースに一連の誤ったロックを引き起こすために発生しました。
一般的なデータベース管理者の最初の反応は、プライマリブロッキングセッションを特定し、それを安全に終了することです。これは通常、SELECTステートメントまたはアイドルセッションであったため、安全でした。
問題を解決する他の試みもありました:
- テーブルを削除します。これにより、クエリでテーブル全体をスキャンする必要がある場合でも、良好なパフォーマンスが得られると期待されていました。
- READ COMMITTED SNAPSHOT分離レベルを有効にして、セッションのブロックの影響を軽減します。
この記事では、シナリオの単純化されたバージョンを再作成し、それを使用して、適切に実行された場合に、単純なインデックス作成がこのような状況にどのように対処できるかを示します。
2つの関連テーブル
リスト1とリスト2をご覧ください。これらは、検討中のシナリオに関係するテーブルの簡略化されたバージョンを示しています。
-- Listing 1: Create TranLog Table
use DB2
go
create table TranLog (
TranID INT IDENTITY(1,1)
,CustomerID char(4)
,ProductCount INT
,TotalPrice Money
,TranTime Timestamp
)
-- Listing 2: Create TranDetails Table
use DB2
go
create table TranDetails (
TranDetailsID INT IDENTITY(1,1)
,TranID INT
,ProductCode uniqueidentifier
,UnitCost Money
,ProductCount INT
,TotalPrice Money
)
リスト3は、4行を TranDetailsに挿入するトリガーを示しています。 TranLogに挿入されたすべての行のテーブル テーブル。
-- Listing 3: Create Trigger
CREATE TRIGGER dbo.GenerateDetails
ON dbo.TranLog
AFTER INSERT
AS
BEGIN
-- SET NOCOUNT ON added to prevent extra result sets from
-- interfering with SELECT statements.
SET NOCOUNT ON;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
END
GO
クエリに参加
大きなテーブルでサポートされているトランザクションテーブルを見つけるのが一般的です。目的は、はるかに古いトランザクションを保持すること、または最初の表に要約されているレコードの詳細を保存することです。これを注文と考えてください およびorderdetails SQLServerサンプルデータベースで一般的なテーブル。この例では、 TranLogを検討しています。 およびTranDetails テーブル。
通常の状況では、トランザクションは時間の経過とともにこれら2つのテーブルにデータを入力します。レポートまたは単純なクエリに関しては、クエリはこれら2つのテーブルに対して結合を実行します。この結合は、テーブル間の共通の列を利用します。
まず、リスト4のクエリを使用してテーブルにデータを入力します。
-- Listing 4: Insert Rows in TranLog
use DB2
go
insert into TranLog values ('CU01', 5, '50.45', DEFAULT);
insert into TranLog values ('CU02', 7, '42.35', DEFAULT);
insert into TranLog values ('CU03', 15, '39.55', DEFAULT);
insert into TranLog values ('CU04', 9, '33.50', DEFAULT);
insert into TranLog values ('CU05', 2, '105.45', DEFAULT);
go 1000
use DB2
go
select * from TranLog;
select * from TranDetails;
このサンプルでは、結合で使用される一般的な列は TranIDです。 列:
-- Listing 5 Join Query
-- 5a
select * from TranLog a join TranDetails b
on a.TranID=b.TranID where a.CustomerID='CU03';
-- 5b
select * from TranLog a join TranDetails b
on a.TranID=b.TranID where a.TranID=30;
結合を使用してTranLogからレコードを取得する2つの簡単なサンプルクエリを確認できます。 およびTranDetails 。
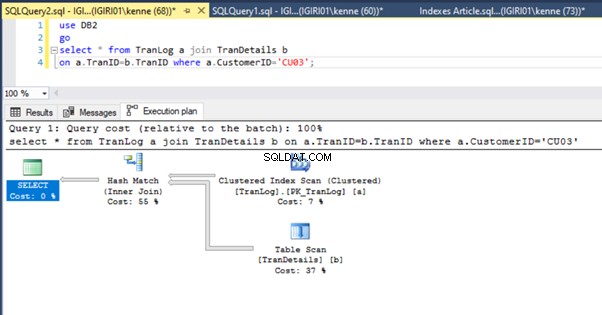
リスト5のクエリを実行する場合、どちらの場合も、両方のテーブルで全表スキャンを実行する必要があります(図1および2を参照)。各クエリの主要な部分は、物理的な操作です。どちらも内部結合です。ただし、リスト5aはハッシュマッチを使用しています リスト5bはネストされたループを使用しています。 加入。注:リスト5aは4000行を返し、リスト4bは4行を返します。
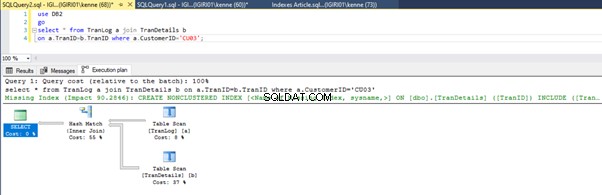
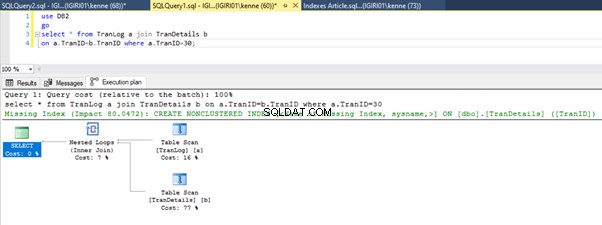
3つのパフォーマンスチューニングステップ
最初に行う最適化は、 TranID にインデックス(正確には主キー)を導入することです。 TranLogの列 テーブル:
-- Listing 6: Create Primary Key
alter table TranLog add constraint PK_TranLog primary key clustered (TranID);
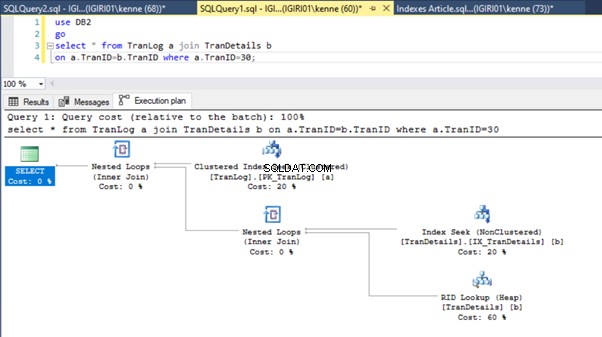
図3と図4は、SQL Serverが両方のクエリでこのインデックスを利用し、リスト5aのスキャンとリスト5bのシークを実行していることを示しています。
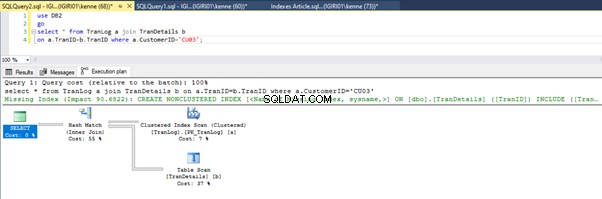
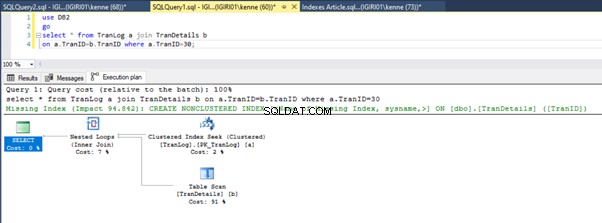
リスト5bにインデックスシークがあります。これは、WHERE句の述語–TranIDに含まれる列が原因で発生します。 インデックスを適用したのはその列です。
次に、 TranIDに外部キーを導入します TranDetailsの列 表(リスト7)。
-- Listing 7: Create Foreign Key
alter table TranDetails add constraint FK_TranDetails foreign key (TranID) references TranLog (TranID);
これは、実行プランではあまり変わりません。状況は、図3および4で前に示したものと実質的に同じです。
次に、外部キー列にインデックスを導入します:
-- Listing 8: Create Index on Foreign Key
create index IX_TranDetails on TranDetails (TranID);
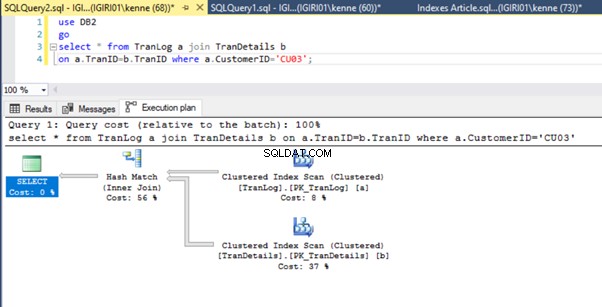
このアクションにより、リスト5bの実行プランが大幅に変更されます(図6を参照)。より多くのインデックスが発生しようとしていることがわかります。また、図6のRIDルックアップにも注目してください。
ヒープでのRIDルックアップは、通常、主キーがない場合に発生します。ヒープは主キーのないテーブルです。
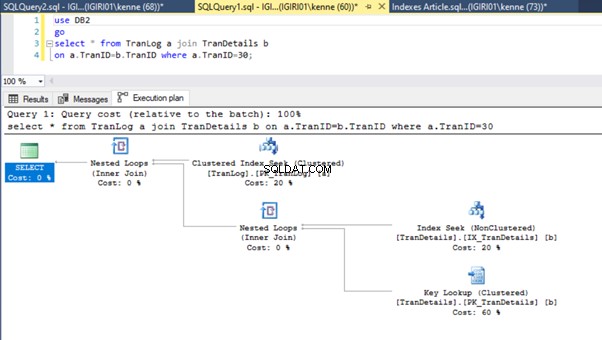
最後に、 TranDetailsに主キーを追加します テーブル。これにより、リスト5aと5bのテーブルスキャンとRIDヒープルックアップがそれぞれ削除されます(図7と8を参照)。
-- Listing 9: Create Primary Key on TranDetailsID
alter table TranDetails add constraint PK_TranDetails primary key clustered (TranDetailsID);
結論
インデックスによって導入されたパフォーマンスの向上は、初心者のDBAでもよく知られています。ただし、クエリがインデックスをどのように使用するかを詳しく調べる必要があることを指摘しておきます。
さらに、トランザクションログの間に結合クエリがある特定の場合にソリューションを確立するというアイデアがあります。 テーブルとトランザクションの詳細 テーブル。
一般に、キーを使用してそのようなテーブル間の関係を強制し、主キー列と外部キー列にインデックスを導入することは理にかなっています。
このような設計を使用するアプリケーションを開発する場合、開発者は設計段階で必要なインデックスと関係を念頭に置く必要があります。 SQL Serverスペシャリスト向けの最新のツールを使用すると、これらの要件をはるかに簡単に満たすことができます。専用のクエリプロファイラーツールを使用して、クエリをプロファイリングできます。これは、DBAの作業を簡素化するためにDevartによって開発されたSQLServer用の多機能プロフェッショナルソリューションdbForgeStudioの一部です。