この投稿には「文字列が添付されています:正当な理由があります。文字列を処理するデータ型であるSQLVARCHARについて詳しく見ていきます。
また、これは「あなたの目だけのために」です。文字列がないと、ブログの投稿、Webページ、ゲームの説明、ブックマークされたレシピなど、私たちの目が読んで楽しむことができないためです。私たちは毎日何億もの弦を扱っています。したがって、開発者として、あなたと私は、この種のデータを効率的に保存およびアクセスできるようにする責任があります。
これを念頭に置いて、ストレージとパフォーマンスにとって最も重要なことについて説明します。このデータタイプの推奨事項と禁止事項を入力してください。
しかしその前は、VARCHARはSQLの文字列タイプの1つにすぎません。何が違うのですか?
SQLのVARCHARとは何ですか? (例付き)
VARCHARは、さまざまなサイズの文字列または文字のデータ型です。文字、数字、記号を一緒に保存できます。 SQL Server 2019以降、UTF-8をサポートする照合を使用する場合は、Unicode文字の全範囲を使用できます。
VARCHAR [(n)]を使用して、VARCHAR列または変数を宣言できます。ここで、 n 文字列サイズをバイト単位で表します。 nの値の範囲 1から8000です。これは大量の文字データです。さらに、最大2GBの巨大な文字列が必要な場合は、VARCHAR(MAX)を使用して宣言できます。それはあなたの日記の秘密と私的なもののリストのために十分な大きさです!ただし、サイズなしで宣言することもでき、その場合はデフォルトで1になります。
例を挙げましょう。
DECLARE @actor VARCHAR(20) = 'Robert Downey Jr.';
DECLARE @movieCharacter VARCHAR(10) = 'Iron Man';
DECLARE @movie VARCHAR = 'Avengers';
SELECT @actor, @movieCharacter, @movie
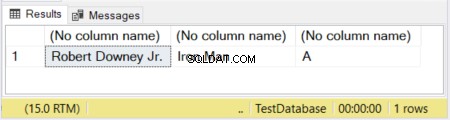
図1では、最初の2列にサイズが定義されています。 3番目の列はサイズなしで残されています。したがって、サイズが宣言されていないVARCHARはデフォルトで1文字であるため、「アベンジャーズ」という単語は切り捨てられます。
それでは、何か大きなことを試してみましょう。ただし、このクエリの実行には時間がかかることに注意してください。私のラップトップでは23秒です。
-- This will take a while
DECLARE @giganticString VARCHAR(MAX);
SET @giganticString = REPLICATE(CAST('kage bunshin no jutsu' AS VARCHAR(MAX)),100000000)
SELECT DATALENGTH(@giganticString)
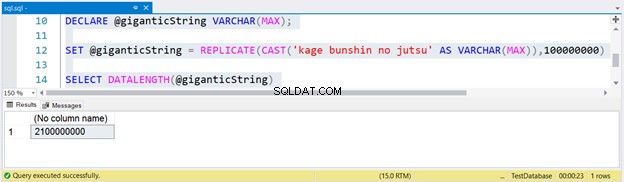
巨大な弦を生成するために、影文神の術を1億回複製しました。 REPLICATE内のCASTに注意してください。文字列式をVARCHAR(MAX)にキャストしない場合、結果は最大8000文字に切り捨てられます。
しかし、SQL VARCHARは他の文字列データ型とどのように比較されますか?
SQLでのCHARとVARCHARの違い
VARCHARと比較すると、CHARは固定長文字データ型です。 CHAR変数にどの程度小さい値または大きい値を設定しても、最終的なサイズは変数のサイズになります。以下の比較を確認してください。
DECLARE @tvSeriesTitle1 VARCHAR(20) = 'The Mandalorian';
DECLARE @tvSeriesTitle2 CHAR(20) = 'The Mandalorian';
SELECT DATALENGTH(@tvSeriesTitle1) AS VarcharValue,
DATALENGTH(@tvSeriesTitle2) AS CharValue
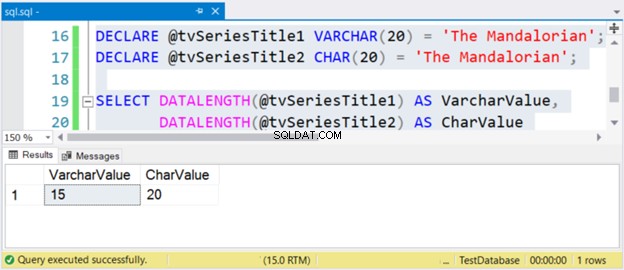
文字列「マンダロリアン」のサイズは15文字です。つまり、 VarcharValue 列はそれを正しく反映しています。ただし、 CharValue 20のサイズを保持します–右側に5つのスペースが埋め込まれます。
SQLVARCHARとNVARCHAR
これらのデータ型を比較するとき、2つの基本的なことが思い浮かびます。
まず、バイト単位のサイズです。 NVARCHARの各文字は、VARCHARの2倍のサイズです。 NVARCHAR(n)は1から4000までのみです。
次に、保存できる文字。 NVARCHARは、韓国語、日本語、アラビア語などの多言語文字を格納できます。データベースに韓国語のK-Pop歌詞を格納する場合は、このデータ型がオプションの1つです。
例を見てみましょう。 K-popグループ세븐틴または英語のSeventeenを使用します。
DECLARE @kpopGroupKorean NVARCHAR(5) = N'세븐틴';
SELECT @kpopGroupKorean AS KPopGroup,
DATALENGTH(@kpopGroupKorean) AS SizeInBytes,
LEN(@kpopGroupKorean) AS [NoOfChars]
上記のコードは、文字列値、バイト単位のサイズ、および文字数を出力します。これらが非Unicode文字の場合、文字数はバイト単位のサイズと同じです。しかし、そうではありません。下の図4を確認してください。
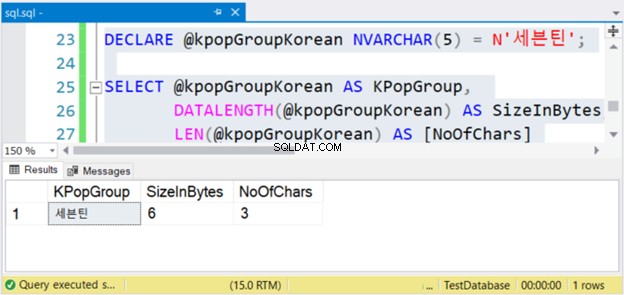
見る? NVARCHARが3文字の場合、バイト単位のサイズは2倍になります。ただし、VARCHARではありません。英語の文字を使用する場合も同様です。
しかし、NCHARはどうですか? NCHARは、Unicode文字のCHARに相当します。
UTF-8をサポートするSQLServerVARCHAR
照合情報を変更することにより、サーバーレベル、データベースレベル、またはテーブル列レベルでUTF-8をサポートするVARCHARが可能になります。使用する照合はUTF-8をサポートする必要があります。
SQLサーバーの照合
図5は、サーバーの照合を示すSQL ServerManagementStudioのウィンドウを示しています。
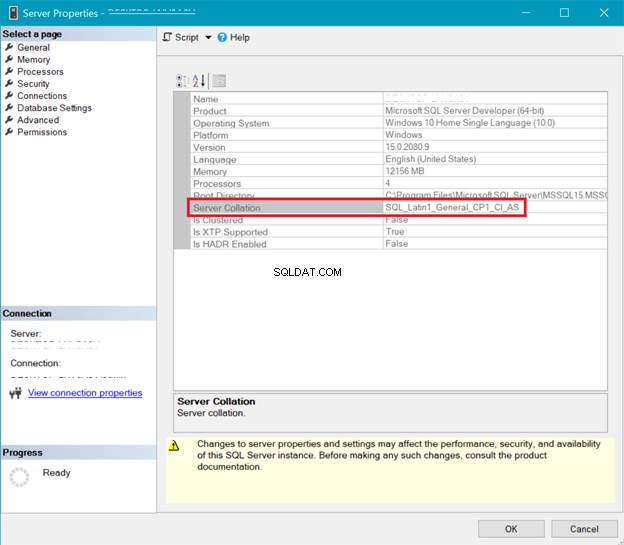
一方、図6は、 AdventureWorksの照合を示しています。 データベース。
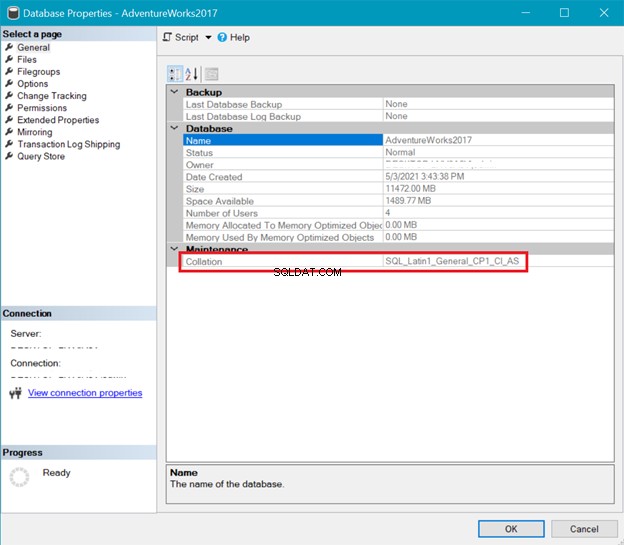
上記のサーバーとデータベースの照合は、UTF-8がサポートされていないことを示しています。照合文字列には、UTF-8をサポートするために_UTF8が含まれている必要があります。ただし、テーブルの列レベルでUTF-8サポートを引き続き使用できます。例を参照してください。
CREATE TABLE SeventeenMemberList
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
KoreanName VARCHAR(20) COLLATE Latin1_General_100_BIN2_UTF8 NOT NULL,
EnglishName VARCHAR(20) NOT NULL
)
上記のコードにはLatin1_General_100_BIN2_UTF8があります KoreanNameの照合 桁。 NVARCHARではなくVARCHARですが、この列は韓国語の文字を受け入れます。いくつかのレコードを挿入してから表示してみましょう。
INSERT INTO SeventeenMemberList
(KoreanName, EnglishName)
VALUES
(N'에스쿱스','S.Coups')
,(N'원우','Wonwoo')
,(N'민규','Mingyu')
,(N'버논','Vernon')
,(N'우지','Woozi')
,(N'정한','Jeonghan')
,(N'조슈아','Joshua')
,(N'도겸','DK')
,(N'승관','Seungkwan')
,(N'호시','Hoshi')
,(N'준','Jun')
,(N'디에잇','The8')
,(N'디노','Dino')
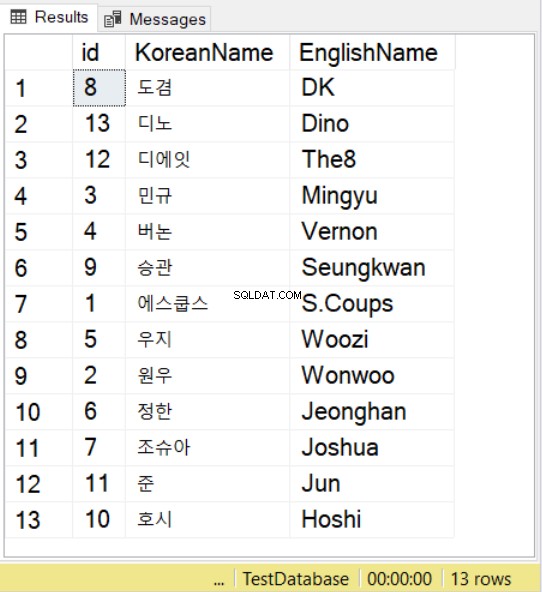
SELECT * FROM SeventeenMemberList
ORDER BY KoreanName
COLLATE Latin1_General_100_BIN2_UTF8
私たちは、韓国語と英語の対応物を使用して、SeventeenK-popグループの名前を使用しています。韓国語の文字の場合でも、値の前に Nを付ける必要があることに注意してください。 、NVARCHAR値で行うのと同じように。
次に、SELECTをORDER BYとともに使用する場合、照合も使用できます。上記の例でこれを観察できます。これは、指定された照合の並べ替えルールに従います。
UTF-8サポート付きのVARCHARのストレージ
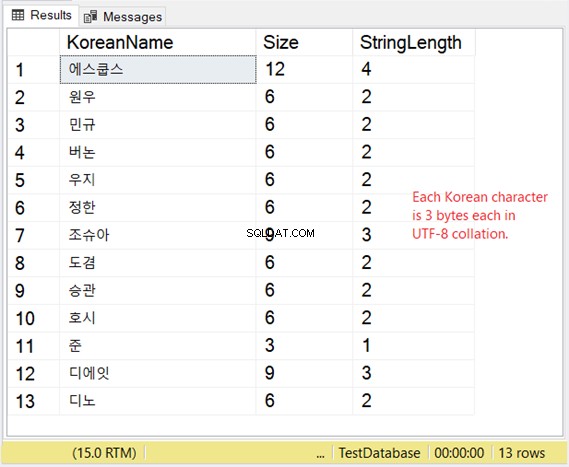
しかし、これらのキャラクターの保管はどうですか? 1文字あたり2バイトを期待している場合は、驚きに満ちています。図8を確認してください。
したがって、ストレージが非常に重要な場合は、UTF-8サポートでVARCHARを使用するときに以下の表を検討してください。
| キャラクター | バイト単位のサイズ |
| ASCII 0 – 127 | 1 |
| ラテン語ベースのスクリプト、およびギリシャ語、キリル文字、コプティック文字、アルメニア語、ヘブライ語、アラビア語、シリア語、ターナ語、およびN’Ko | 2 |
| 中国語、韓国語、日本語などの東アジアのスクリプト | 3 |
| 010000〜10FFFFの範囲の文字 | 4 |
韓国の例は東アジアのスクリプトなので、1文字あたり3バイトです。
VARCHARの説明と他の文字列タイプとの比較が完了したので、次は「すべきこと」と「すべきでないこと」について説明します。
SQLServerでのVARCHARの使用に関する注意事項
1。サイズを指定
サイズを指定しないと何がうまくいかない可能性がありますか?
文字列の切り捨て
サイズを指定するのが面倒になると、文字列の切り捨てが発生します。すでにこの例を見ました。
ストレージとパフォーマンスへの影響
もう1つの考慮事項は、ストレージとパフォーマンスです。データに適切なサイズを設定するだけで、それ以上は設定できません。しかし、どうやって知ることができますか?将来の切り捨てを回避するために、最大サイズに設定することもできます。つまり、VARCHAR(8000)またはVARCHAR(MAX)です。また、2バイトはそのまま保存されます。 2GBでも同じです。重要ですか?
これに答えると、SQLServerがデータを格納する方法の概念にたどり着きます。例とイラストでこれを詳細に説明している別の記事があります。
つまり、データは8KBページに保存されます。データの行がこのサイズを超えると、SQLServerはそれをROW_OVERFLOW_DATAと呼ばれる別のページアロケーションユニットに移動します。
元のページアロケーションユニットに適合する可能性のある2バイトのVARCHARデータがあるとします。 8000バイトを超える文字列を格納すると、データは行オーバーフローページに移動されます。次に、もう一度縮小して小さいサイズにすると、元のページに戻ります。前後の動きは、多くのI/Oとパフォーマンスのボトルネックを引き起こします。 1ページではなく2ページからこれを取得するには、追加のI/Oも必要です。
もう1つの理由は、インデックス作成です。 VARCHAR(MAX)は、インデックスキーとしての大きなNOです。その間、VARCHAR(8000)は最大インデックスキーサイズを超えます。これは、非クラスター化インデックスの場合は1700バイト、クラスター化インデックスの場合は900バイトです。
データ変換の影響
ただし、もう1つの考慮事項があります。それはデータ変換です。以下のコードのようなサイズのないCASTで試してみてください。
SELECT
SYSDATETIMEOFFSET() AS DateTimeInput
,CAST(SYSDATETIMEOFFSET() AS VARCHAR) AS ConvertedDateTime
,DATALENGTH(CAST(SYSDATETIMEOFFSET() AS VARCHAR)) AS ConvertedLength
このコードは、タイムゾーン情報を含む日付/時刻をVARCHARに変換します。
したがって、CASTまたはCONVERT中にサイズを指定するのが面倒な場合、結果は30文字のみに制限されます。
NVARCHARをUTF-8をサポートするVARCHARに変換するのはどうですか?これについては後で詳しく説明しますので、読み続けてください。
2。文字列サイズが大幅に異なる場合はVARCHARを使用する
AdventureWorksの名前 データベースのサイズはさまざまです。最短の名前の1つはMinSuで、最長の名前はOsarumwenseUwaifiokunAgbonileです。スペースを含めて6〜31文字です。これらの名前を2つのテーブルにインポートして、VARCHARとCHARを比較してみましょう。
-- Table using VARCHAR
CREATE TABLE VarcharAsIndexKey
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
varcharName VARCHAR(50) NOT NULL
)
GO
CREATE INDEX IX_VarcharAsIndexKey_varcharName ON VarcharAsIndexKey(varcharName)
GO
-- Table using CHAR
CREATE TABLE CharAsIndexKey
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
charName CHAR(50) NOT NULL
)
GO
CREATE INDEX IX_CharAsIndexKey_charName ON CharAsIndexKey(charName)
GO
INSERT INTO VarcharAsIndexKey (varcharName)
SELECT DISTINCT
LastName + ', ' + FirstName + ' ' + ISNULL(MiddleName,'')
FROM AdventureWorks.Person.Person
INSERT INTO CharAsIndexKey (charName)
SELECT DISTINCT
LastName + ', ' + FirstName + ' ' + ISNULL(MiddleName,'')
FROM AdventureWorks.Person.Person
GO
2つのうちどちらが良いですか?以下のコードを使用し、STATISTICS IOの出力を調べて、論理読み取りを確認しましょう。
SET NOCOUNT ON
SET STATISTICS IO ON
SELECT id, varcharName
FROM VarcharAsIndexKey
SELECT id, charName
FROM CharAsIndexKey
SET STATISTICS IO OFF
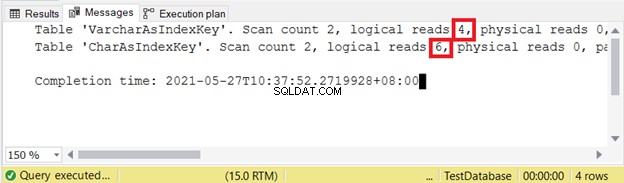
論理読み取り:
論理的な読み取りは少ないほど良いです。ここで、CHAR列はVARCHARの対応する列の2倍以上を使用しました。したがって、この例ではVARCHARが優先されます。
3。値のサイズが異なる場合は、CHARではなくVARCHARをインデックスキーとして使用する
インデックスキーとして使用するとどうなりましたか? CHARはVARCHARよりもうまくいくでしょうか?前のセクションと同じデータを使用して、この質問に答えましょう。
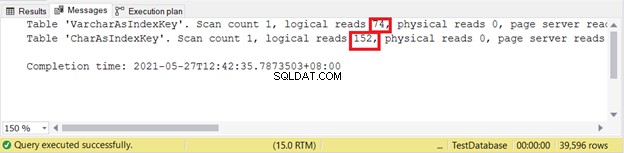
いくつかのデータをクエリし、論理読み取りを確認します。この例では、フィルターはインデックスキーを使用します。
SET NOCOUNT ON
SET STATISTICS IO ON
SELECT varcharName FROM VarcharAsIndexKey
WHERE varcharName = 'Sai, Adriana A'
OR varcharName = 'Rogers, Caitlin D'
SELECT charName FROM CharAsIndexKey
WHERE charName = 'Sai, Adriana A'
OR charName = 'Rogers, Caitlin D'
SET STATISTICS IO OFF
論理読み取り:
したがって、キーのサイズが異なる場合、VARCHARインデックスキーはCHARインデックスキーよりも優れています。しかし、インデックスエントリを変更するINSERTとUPDATEはどうですか?
挿入と更新を使用する場合
2つのケースをテストしてから、通常どおりに論理読み取りを確認しましょう。
SET STATISTICS IO ON
INSERT INTO VarcharAsIndexKey (varcharName)
VALUES ('Ruffalo, Mark'), ('Johansson, Scarlett')
INSERT INTO CharAsIndexKey (charName)
VALUES ('Ruffalo, Mark'), ('Johansson, Scarlett')
SET STATISTICS IO OFF
論理読み取り:
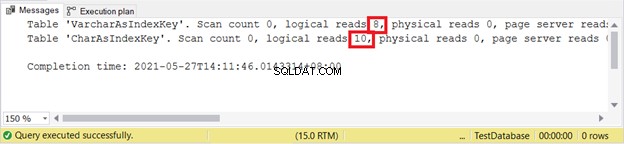
レコードを挿入するときは、VARCHARの方が優れています。 UPDATEはどうですか?
SET STATISTICS IO ON
UPDATE VarcharAsIndexKey
SET varcharName = 'Hulk'
WHERE varcharName = 'Ruffalo, Mark'
UPDATE CharAsIndexKey
SET charName = 'Hulk'
WHERE charName = 'Ruffalo, Mark'
SET STATISTICS IO OFF
論理読み取り:
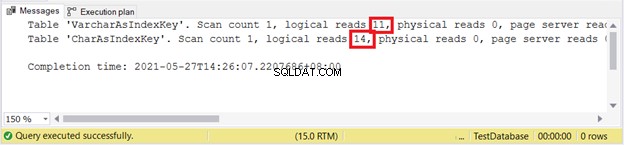
VARCHARが再び勝ったようです。
小さいかもしれませんが、最終的にはテストに勝ちます。反対のことを証明するより大きなテストケースがありますか?
4。多言語データのUTF-8サポート(SQL Server 2019以降)を使用したVARCHARを検討してください
テーブルにUnicode文字と非Unicode文字が混在している場合は、NVARCHARよりもUTF-8をサポートするVARCHARを検討できます。ほとんどの文字がASCII0〜127の範囲内にある場合、NVARCHARと比較してスペースを節約できます。
私が何を意味するのかを理解するために、比較してみましょう。
NVARCHAR TO VARCHAR WITH UTF-8 SUPPORT
データベースをSQLServer2019に既に移行しましたか?文字列データをUTF-8照合に移行することを計画していますか?アイデアを出すために、日本語と日本語以外の文字の混合値の例を示します。
CREATE TABLE NVarcharToVarcharUTF8
(
NVarcharValue NVARCHAR(20) NOT NULL,
VarcharUTF8 VARCHAR(45) COLLATE Latin1_General_100_BIN2_UTF8 NOT NULL
)
GO
INSERT INTO NVarcharToVarcharUTF8
(NVarcharValue, VarcharUTF8)
VALUES
(N'NARUTO-ナルト- 疾風伝',N'NARUTO-ナルト- 疾風伝'); -- NARUTO Shippûden
SELECT
NVarcharValue
,LEN(NVarcharValue) AS nvarcharNoOfChars
,DATALENGTH(NVarcharValue) AS nvarcharSizeInBytes
,VarcharUTF8
,LEN(VarcharUTF8) AS varcharNoOfChars
,DATALENGTH(VarcharUTF8) AS varcharSizeInBytes
FROM NVarcharToVarcharUTF8
データが設定されたので、2つの値のサイズをバイト単位で調べます。

サプライズ! NVARCHARの場合、サイズは30バイトです。これは2文字の15倍です。ただし、UTF-8をサポートするVARCHARに変換すると、サイズはわずか27バイトになります。なぜ27?これがどのように計算されるかを確認してください。

したがって、9文字はそれぞれ1バイトです。 NVARCHARでは、英語の文字も2バイトであるため、これは興味深いことです。残りの日本語文字はそれぞれ3バイトです。
これがすべて日本語の場合、15文字の文字列は45バイトになり、 VarcharUTF8の最大サイズも消費します。 桁。 NVarcharValueのサイズに注意してください 列がVarcharUTF8未満です 。
NVARCHARから変換する場合、サイズを等しくすることはできません。そうしないと、データが収まらない可能性があります。前の表1を参照できます。
NVARCHARをUTF-8をサポートするVARCHARに変換する際のサイズへの影響を考慮してください。
SQLServerでVARCHARを使用しないでください
1。文字列サイズが固定されていてnull許容でない場合は、代わりにCHARを使用してください。
固定サイズの文字列が必要な場合の一般的な経験則は、CHARを使用することです。右パッドのスペースが必要なデータ要件がある場合は、これに従います。それ以外の場合は、VARCHARを使用します。区切り文字のない固定長の文字列をクライアントのテキストファイルにダンプする必要がある場合、いくつかのユースケースがありました。
さらに、CHAR列は、列がnull許容でない場合にのみ使用します。なんで? NULLの場合のCHAR列のバイト単位のサイズは、定義された列のサイズと等しいためです。ただし、NULLのサイズが1の場合、定義されたサイズがいくらであってもVARCHAR。以下のコードを実行して、自分の目で確かめてください。
DECLARE @charValue CHAR(50) = NULL;
DECLARE @varcharValue VARCHAR(1000) = NULL;
SELECT
DATALENGTH(ISNULL(@charvalue,0)) AS CharSize
,DATALENGTH(ISNULL(@varcharvalue,0)) AS VarcharSize
2。 n の場合はVARCHAR(n)を使用しないでください 8000バイトを超えます。代わりにVARCHAR(MAX)を使用してください。
8000バイトを超える文字列はありますか?これは、VARCHAR(MAX)を使用するときです。ただし、名前やアドレスなどの最も一般的な形式のデータの場合、VARCHAR(MAX)は過剰であり、パフォーマンスに影響を与えます。私の個人的な経験では、VARCHAR(MAX)を使用したという要件を覚えていません。
3。 SQLServer2017以下で多言語文字を使用する場合。代わりにNVARCHARを使用してください。
SQL Server 2017以下を引き続き使用している場合、これは明らかな選択です。
VARCHARデータ型は、非常に多くの面で役立ちました。 SQL Server 7以降、それは私にとって重要でした。それでも、私たちはまだ悪い選択をすることがあります。この投稿では、SQL VARCHARが定義され、例を使用して他の文字列データ型と比較されます。繰り返しになりますが、データベースを高速化するための推奨事項と禁止事項は次のとおりです。
すべきこと:
- サイズを指定しますn オプションの場合でも、VARCHAR [(n)]で。
- 文字列のサイズが大幅に異なる場合に使用します。
- VARCHAR列をCHARではなくインデックスキーと見なします。
- 現在SQLServer2019を使用している場合は、UTF-8をサポートする多言語文字列のVARCHARを検討してください。
禁止事項:
- 文字列サイズが固定されていてnull許容でない場合は、VARCHARを使用しないでください。
- 文字列サイズが8000バイトを超える場合は、VARCHAR(n)を使用しないでください。
- SQL Server 2017以前を使用する場合は、多言語データにVARCHARを使用しないでください。
他に追加するものはありますか?コメントセクションでお知らせください。これが開発者の友達に役立つと思われる場合は、お気に入りのソーシャルメディアプラットフォームで共有してください。