はじめに
インデックスは、必要な結果セットを完全に満たす(カバーインデックス)か、クエリエンジンを必要なデータセットの正確な場所に簡単に誘導するルックアップとして機能することにより、クエリのパフォーマンスを向上させることは、データベースサークルの一般的な知識です。ただし、経験豊富なDBAが知っているように、ワークロードの性質を理解せずに、OLTP環境でインデックスを作成することに熱心になりすぎないようにする必要があります。 SQL Server 2019インスタンスでクエリストアを使用すると(クエリストアはSQL Server 2016で導入されました)、挿入に対するインデックスの効果を示すのは非常に簡単です。
インデックスなしで挿入
まず、WideWorldImportersサンプルデータベースを復元してから、Salesのコピーを作成します。リスト1のスクリプトを使用した請求書テーブル。サンプルデータベースでは、クエリストアがすでに読み取り/書き込みモードで有効になっていることに注意してください。
-- Listing 1 Make a Copy Of Invoices SELECT * INTO [SALES].[INVOICES1] FROM [SALES].[INVOICES] WHERE 1=2;
作成したばかりのテーブルにはインデックスがまったくないことに注意してください。私たちが持っているのはテーブル構造だけです。完了したら、リスト2に示すように、親からのデータを使用して新しいテーブルに挿入を実行します。
-- Listing 2 Populate Invoices1 -- TRUNCATE TABLE [SALES].[INVOICES1] INSERT INTO [SALES].[INVOICES1] SELECT * FROM [SALES].[INVOICES]; GO 100
この操作中に、クエリストアはクエリの実行プランをキャプチャします。図1は、内部で何が起こっているかを簡単に示しています。左から右に読むと、SQLServerがプランID563を使用して挿入を実行していることがわかります。 –ソーステーブルの主キーでインデックススキャンを実行してデータをフェッチし、次に宛先テーブルでテーブル挿入を実行します。 (左から右に読む)。この場合、コストの大部分がテーブルインサートにあることに注意してください– 99% クエリコストの。
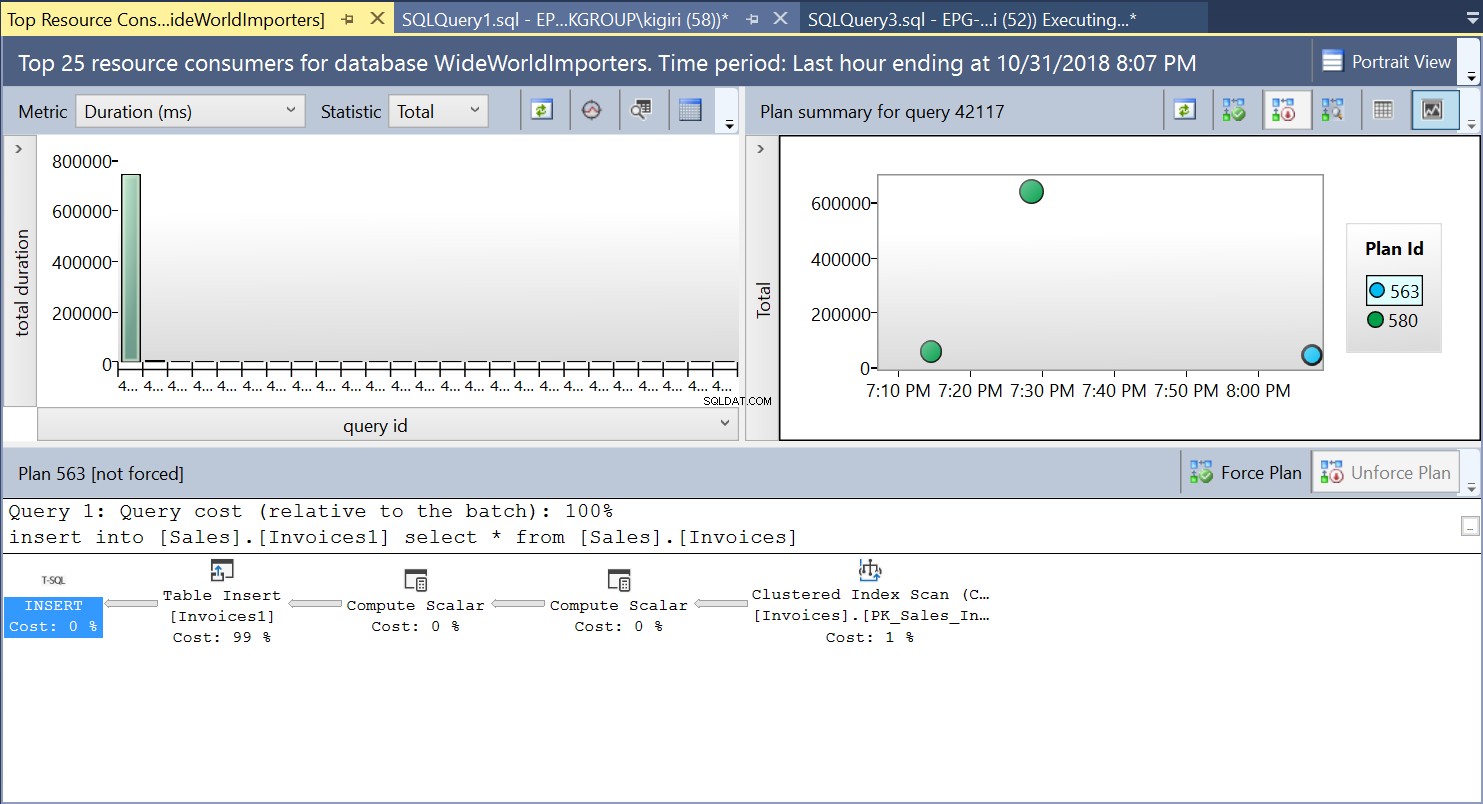
図1実行計画563
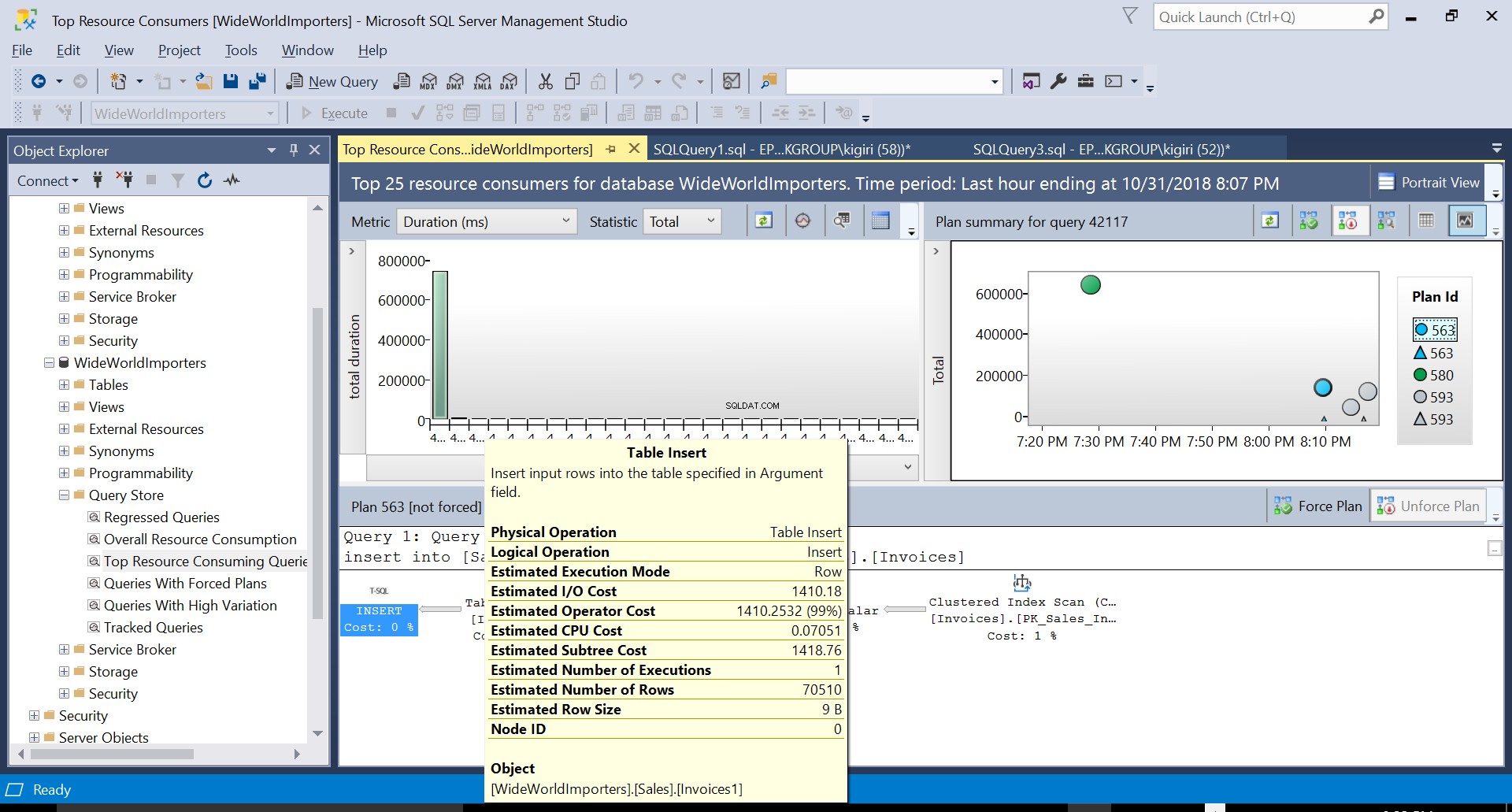
図2宛先へのテーブル挿入
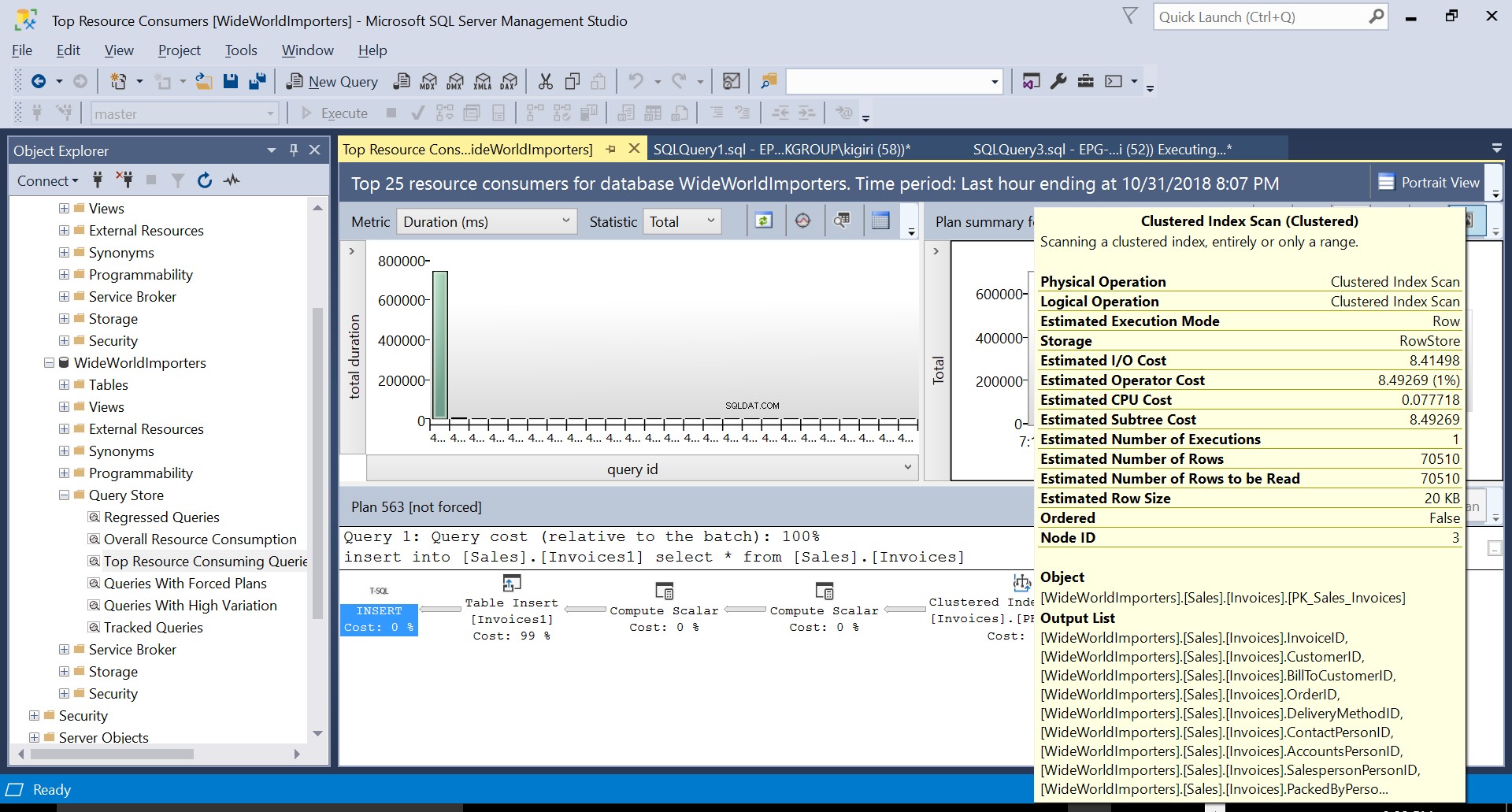
図3ソーステーブルでのクラスター化インデックススキャン
インデックス付きで挿入
次に、リスト3のDDLを使用して、宛先テーブルにインデックスを作成します。宛先テーブルを切り捨てた後、リスト2のステートメントを繰り返すと、わずかに異なる実行プランが表示されます(図4に示すプランID 593)。テーブルインサートは引き続き表示されますが、貢献度は 58%のみです。 クエリのコストに。ソートとインデックス挿入の導入により、実行のダイナミクスは少し歪んでいます。基本的に何が起こっているのかというと、SQL Serverは、新しいレコードがテーブルに導入されるときに、対応する行をインデックスに導入する必要があるということです。
-- LISTING 3 Create Index on Destination Table CREATE NONCLUSTERED INDEX [IX_Sales_Invoices_ConfirmedDeliveryTime] ON [Sales].[Invoices1] ( [ConfirmedDeliveryTime] ASC ) INCLUDE ( [ConfirmedReceivedBy]) WITH (PAD_INDEX = OFF , STATISTICS_NORECOMPUTE = OFF , SORT_IN_TEMPDB = OFF , DROP_EXISTING = OFF , ONLINE = OFF , ALLOW_ROW_LOCKS = ON , ALLOW_PAGE_LOCKS = ON) ON [USERDATA] GO
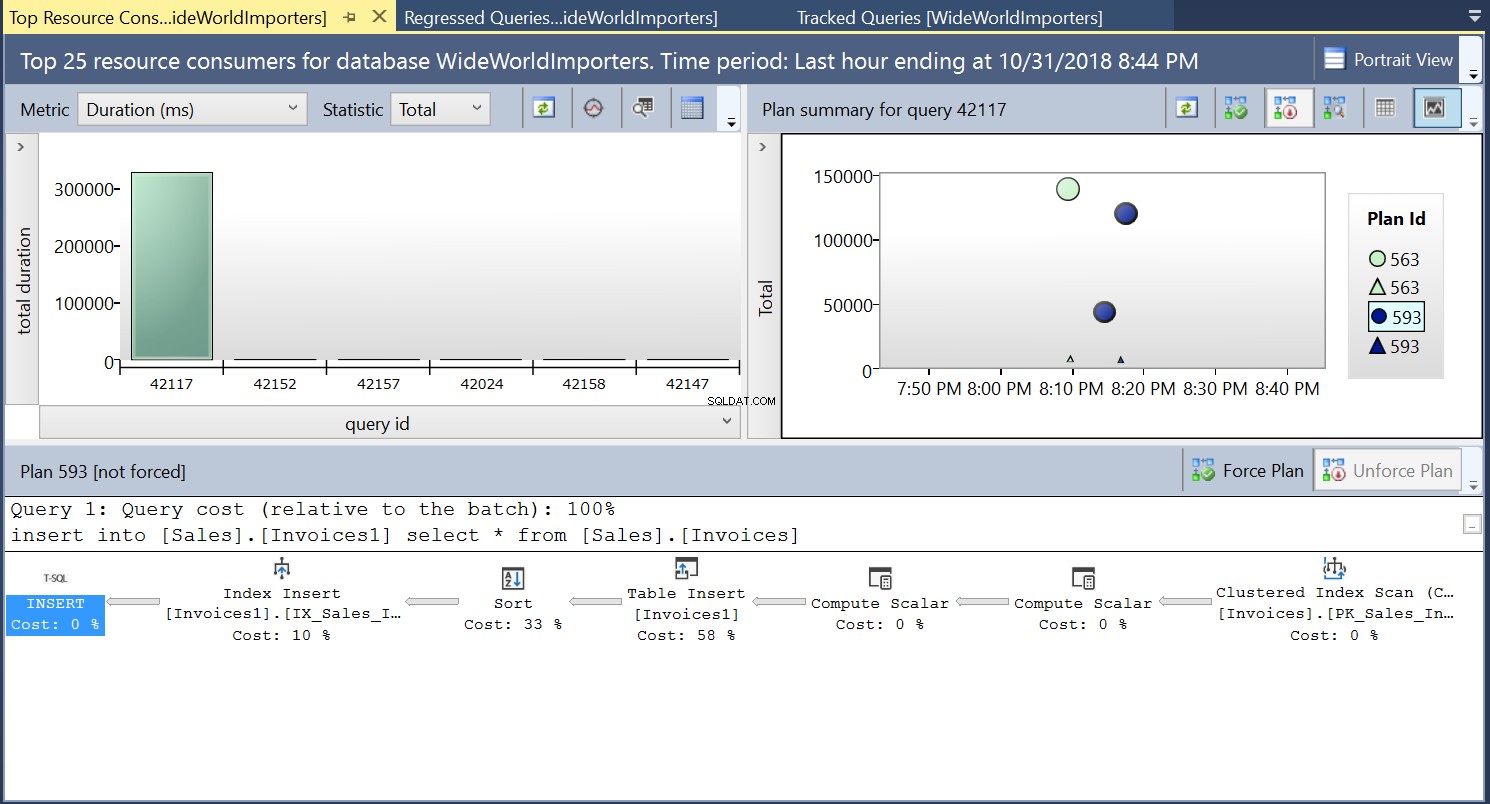
図4実行計画593
もっと深く見る
両方の計画の詳細を調べて、これらの新しい要因がステートメントの実行時間をどのようにエスカレートするかを確認できます。プラン593は、ステートメントの平均期間に300ミリ秒程度を追加します。実稼働環境での負荷の高い作業では、この違いが大きくなる可能性があります。
どちらの場合も(宛先テーブルにインデックスがある場合と宛先テーブルにインデックスがない場合)、挿入ステートメントを1回だけ実行するときにSTATISTICS IOをオンにすると、インデックス付きのテーブルに行を挿入するときに論理IOに関してより多くの作業が行われることも示されます。
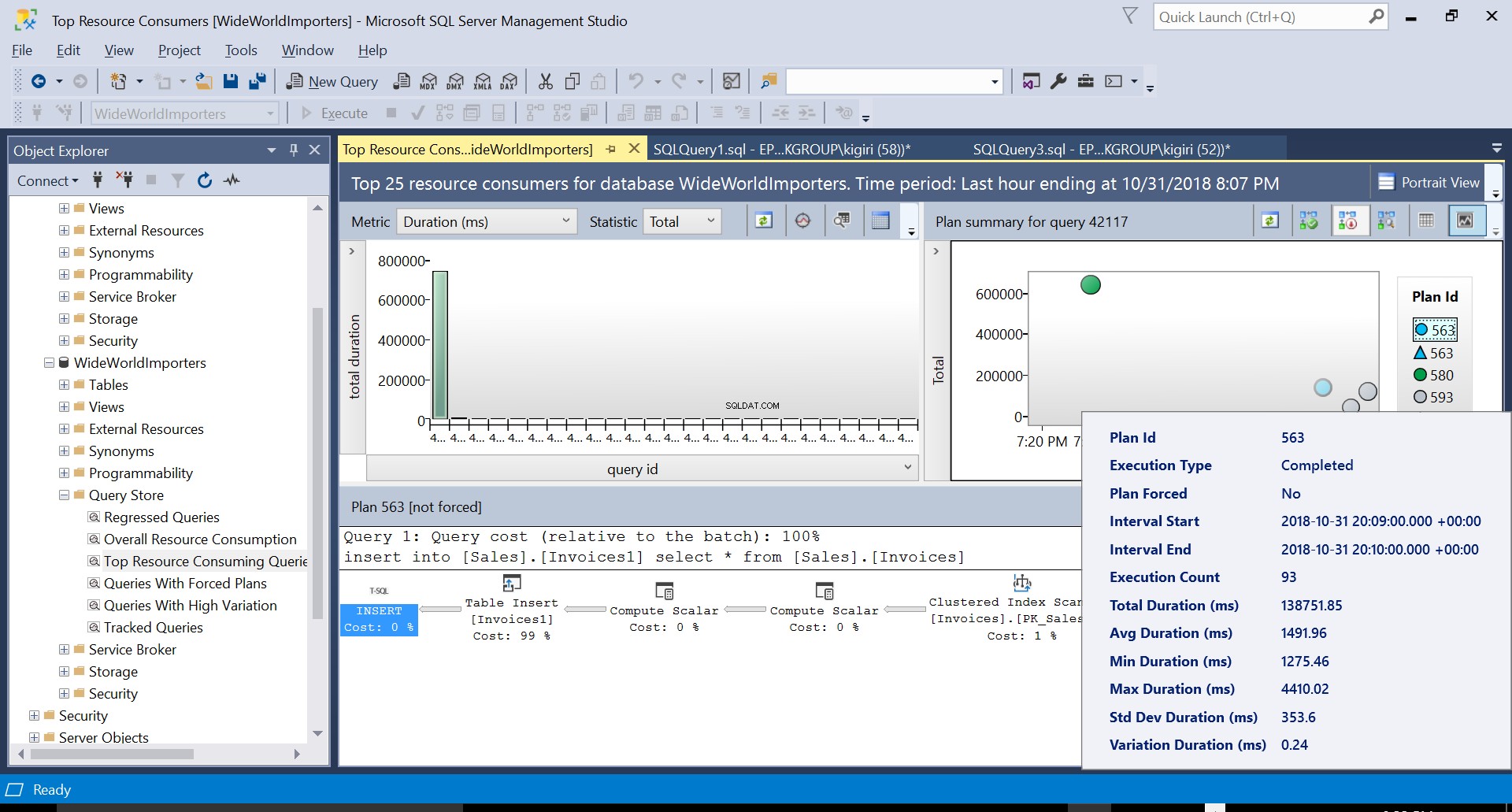
図5実行計画563の詳細
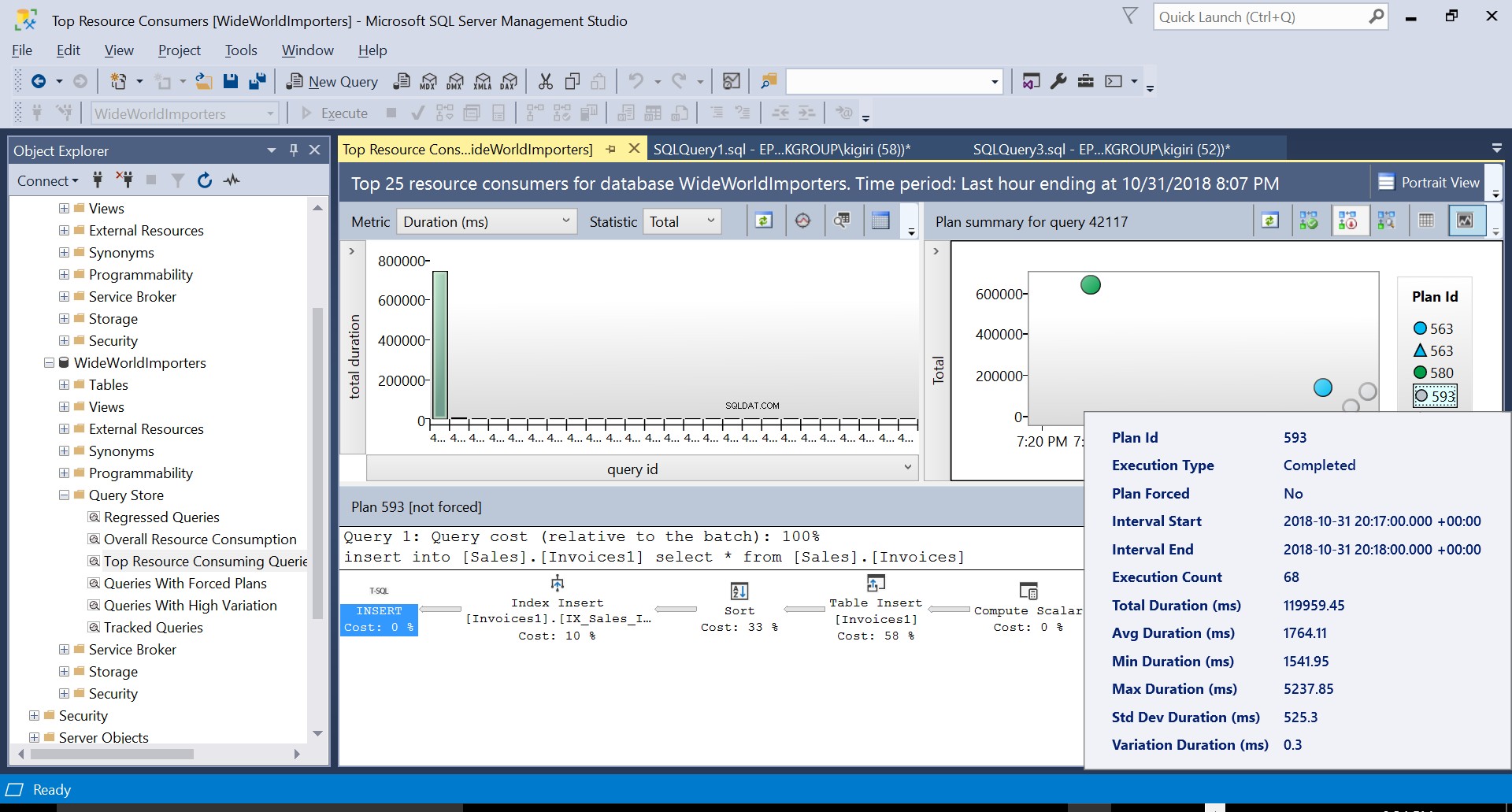
図4実行計画593の詳細
インデックスなし:STATISTICS IOがオンになっている出力:
表「請求書1」。スキャンカウント0、論理読み取り78372 、物理読み取り0、先読み読み取り0、lob論理読み取り0、lob物理読み取り0、lob先読み読み取り0。
表「請求書」。スキャンカウント1、論理読み取り11400、 物理読み取り0、先読み読み取り0、lob論理読み取り0、lob物理読み取り0、lob先読み読み取り0。
(70510行が影響を受けます)
インデックス:STATISTICS IOをオンにした出力:
表「請求書1」。スキャンカウント0、論理読み取り81119 、物理読み取り0、先読み読み取り0、lob論理読み取り0、lob物理読み取り0、lob先読み読み取り0。
表「作業台」。 スキャンカウント0、論理読み取り0、物理読み取り0、先読み読み取り0、lob論理読み取り0、lob物理読み取り0、lob先読み読み取り0。
表「請求書」。スキャンカウント1、論理読み取り11400 、物理読み取り0、先読み読み取り0、lob論理読み取り0、lob物理読み取り0、lob先読み読み取り0。
(70510行が影響を受けます)
追加情報
Microsoftおよびその他のソースは、インデックスの実稼働環境を調べ、次のような状況を特定するためのスクリプトを提供しています。
- 冗長インデックス –重複するインデックス
- 欠落しているインデックス –ワークロードに基づいてパフォーマンスを向上させる可能性のあるインデックス
- ヒープ –クラスター化インデックスのないテーブル
- インデックスが過剰なテーブル –列よりもインデックスが多いテーブル
- インデックスの使用法 –インデックスのシーク、スキャン、ルックアップの数
項目2、3、および5は、読み取りに関するパフォーマンスへの影響に関連していますが、項目1および4は、書き込みに関するパフォーマンスへの影響に関連しています。リスト4と5は、これらの公開されているクエリの2つの例です。
-- LISTING 4 Check Redundant Indexes
;WITH INDEXCOLUMNS AS(
SELECT DISTINCT
SCHEMA_NAME (O.SCHEMA_ID) AS 'SCHEMANAME'
, OBJECT_NAME(O.OBJECT_ID) AS TABLENAME
,I.NAME AS INDEXNAME, O.OBJECT_ID,I.INDEX_ID,I.TYPE
,(SELECT CASE KEY_ORDINAL WHEN 0 THEN NULL ELSE '['+COL_NAME(K.OBJECT_ID,COLUMN_ID) +']' END AS [DATA()]
FROM SYS.INDEX_COLUMNS AS K WHERE K.OBJECT_ID = I.OBJECT_ID AND K.INDEX_ID = I.INDEX_ID
ORDER BY KEY_ORDINAL, COLUMN_ID FOR XML PATH('')) AS COLS
FROM SYS.INDEXES AS I INNER JOIN SYS.OBJECTS O ON I.OBJECT_ID =O.OBJECT_ID
INNER JOIN SYS.INDEX_COLUMNS IC ON IC.OBJECT_ID =I.OBJECT_ID AND IC.INDEX_ID =I.INDEX_ID
INNER JOIN SYS.COLUMNS C ON C.OBJECT_ID = IC.OBJECT_ID AND C.COLUMN_ID = IC.COLUMN_ID
WHERE I.OBJECT_ID IN (SELECT OBJECT_ID FROM SYS.OBJECTS WHERE TYPE ='U') AND I.INDEX_ID <>0 AND I.TYPE <>3 AND I.TYPE <>6
GROUP BY O.SCHEMA_ID,O.OBJECT_ID,I.OBJECT_ID,I.NAME,I.INDEX_ID,I.TYPE
)
SELECT
IC1.SCHEMANAME,IC1.TABLENAME,IC1.INDEXNAME,IC1.COLS AS INDEXCOLS,IC2.INDEXNAME AS REDUNDANTINDEXNAME, IC2.COLS AS REDUNDANTINDEXCOLS
FROM INDEXCOLUMNS IC1
JOIN INDEXCOLUMNS IC2 ON IC1.OBJECT_ID = IC2.OBJECT_ID
AND IC1.INDEX_ID <> IC2.INDEX_ID
AND IC1.COLS <> IC2.COLS
AND IC2.COLS LIKE REPLACE(IC1.COLS,'[','[[]') + ' %'
ORDER BY 1,2,3,5;
-- LISTING 5 Check Indexes Usage
SELECT O.NAME AS TABLE_NAME
, I.NAME AS INDEX_NAME
, S.USER_SEEKS
, S.USER_SCANS
, S.USER_LOOKUPS
, S.USER_UPDATES
FROM SYS.DM_DB_INDEX_USAGE_STATS S
INNER JOIN SYS.INDEXES I
ON I.INDEX_ID=S.INDEX_ID
AND S.OBJECT_ID = I.OBJECT_ID
INNER JOIN SYS.OBJECTS O
ON S.OBJECT_ID = O.OBJECT_ID
INNER JOIN SYS.SCHEMAS C
ON O.SCHEMA_ID = C.SCHEMA_ID;
結論
クエリストアを使用して、インデックスを使用した追加のワークロードがサンプルの挿入ステートメントの実行プランに導入される可能性があることを示しました。本番環境では、特にOLTPワークロード向けのデータベースでは、過剰で冗長なインデックスがパフォーマンスに悪影響を与える可能性があります。利用可能なスクリプトとツールを使用してインデックスを調べ、それらが実際にパフォーマンスを向上させているのか、それとも低下させているのかを判断することが重要です。
便利なツール:
dbForge Index Manager – SQLインデックスのステータスを分析し、インデックスの断片化に関する問題を修正するための便利なSSMSアドイン。