データベース管理システムは、情報の宝庫です。データベースが適切に管理され、目的を達成できるように、データベース管理システムの設計を試みます。
この記事では、大規模なデータベースシステムの設計と管理について説明します。データベーステクノロジー、ストレージ、データ配信、サーバーアセット、アーキテクチャパターンなど、複数の構成を使用します。
できれば、Telcoドメイン、eコマースプラットフォーム、保険ドメイン、銀行システム、ヘルスケア、エネルギーシステムなどで大規模なデータベースを探す必要があります。適切なデータベーステクノロジーを選択する前に、いくつかのパラメーターを念頭に置く必要があります。つまり、トラフィック、TPS(1秒あたりのトランザクション数)、1日あたりの推定ストレージ、HA、DRです。
データベースを構築する際には、データベースを代替で変更することが非常に問題になることが多いため、いくつかのパラメーターに注意を払う必要があります。今から考えてみましょう。
データベーステクノロジー
データベース技術が主な要因です。適切なデータベース管理システムを選択すると、ビジネスを効率的かつ簡単に実行できるようになります。
多くの機能を備えたさまざまなデータベーステクノロジがあります。ただし、オープンソースデータベーステクノロジを使用している間は、事前定義されたソリューションの一部の明示的な機能にアクセスできない場合があります。 Microsoft SQL Server、Oracleなどのエンタープライズデータベーステクノロジがそれらを提供します。
多くのエンタープライズデータベーステクノロジーは、HA(高可用性)、DR(ディザスタリカバリ)、ミラーリング、データレプリケーション、セカンダリ読み取りレプリカ、およびかなり便利ですぐに構成可能なビジネスソリューションを実装しています。それらはオープンソースデータベースに存在する場合と存在しない場合があります。
多くの理由があります。たとえば、上記の要素が必要なときに機能しないために、既存のアーキテクチャが乱されていることに気付くことがあります。
ストレージ
ストレージは、ビジネスソリューションのパフォーマンスに大きく影響します。ビジネスソリューションには、一定量のIOPSを備えた一流のストレージまたはSSDが必要です。しかし、そうですか?オンプレミスまたはクラウドでは、ストレージのサイズとタイプによってインフラストラクチャのコストが決まります。
ストレージのパフォーマンスを検討する際には、データの種類とデータ処理の動作に注意を払う必要があります。ユーザーのデータとその処理に応じて、ストレージの選択を選択する必要があります。ユーザーが複数のデータベースを使用する場合は、データ型とデータ処理動作について、さまざまなデータベースに対してSANよりもストレージの選択肢を提供する必要があります。
データベースエンジニアは、ユーザーがプレミアムストレージをまったく必要としない場合に、IOPS計算に必要なさまざまなデータベースをより適切に振り返ります。
データ配布
最近のデータベーステクノロジー(SQLまたはNoSQL)のほとんどは、パーティショニングまたはシャーディング機能を提供します。
- パーティションは、パーティションキーに基づいてファイルシステム内のデータを再配布します。
- シャーディングはデータベースノード間で情報を分散し、データは同じまたは異なるマシンに保存されます。
基本的に、各データベースサービスまたはデータベーステーブルは、データのパーティショニング/シャーディング機能を必要としません。これらは、より大きなサイズのオブジェクトを保持するデータベースにのみ適用する必要があります。これにより、パフォーマンスが向上します。
サーバーアセット
マシンが異なれば、必要なメモリとCPUのタイプとサイズも異なります。メモリ、プロセッサなどのハードウェアレベルの資産を考慮する必要があります。たとえば、大規模なデータベースや複数のデータベースを処理する必要があるマシンでは、より多くのメモリとCPUが必要になります。したがって、メモリとプロセッサの品質は重要です。さまざまなCPUキャッシュを備えた、市場で入手可能なさまざまなタイプのプロセッサを処理します。
多くの場合、私たちは気づいていないかもしれない問題に遭遇します。ハードウェアのCPUキャッシュの使用率と役割には注意を払いませんでした。ただし、大規模なデータベースシステムでハードウェア要件を選択して満たすためには非常に重要です。
アーキテクチャパターン
データベース設計では、アーキテクチャパターンは常に模範的な役割を果たします。以前は、データベースシステムは非常にモノリシックな方法で設計されていました。現在、マイクロサービスベースまたはハイブリッド(モノリシック+マイクロ)を使用しています。
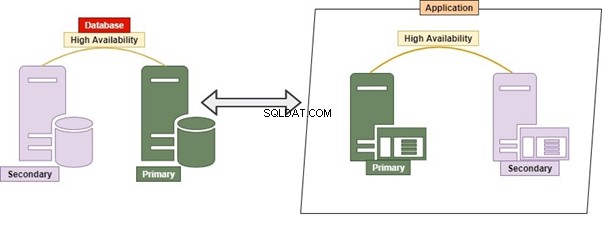
パフォーマンス、拡張性、およびゼロダウンタイムは、アーキテクチャパターンとデータベース設計に大きく依存します。各アプリケーションは個別のデータベースを持つことができ、すべてのデータベースは互いに緩く結合される可能性があります。アプリケーションまたはデータベースがダウンした場合でも、製品の別の部分が中断されることはありません。すべてのマイクロサービスは独立しており、疎結合になります。
マイクロサービス
次の図は、すべてのアプリケーションが、同時に緩く結合されているデータベースの助けを借りて、どのように展開および通信しているのかを説明しています。 T-SQLでデータを操作できます。情報はさまざまなアプリケーションによって収集または蓄積され、クライアントはデータにアクセスできるようになります。スケーリングされたアプリケーションの数とその統合データベースの図を参照してください。
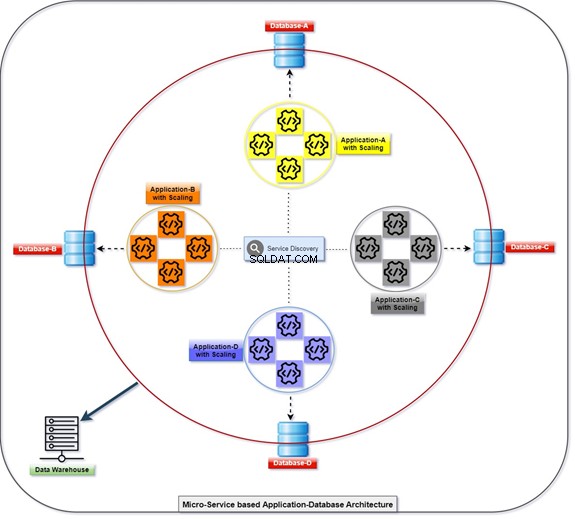
モノリシック
どのRDBMSを使用する必要がありますか? Oracle、Microsoft SQL Server、Postgres、MySQL、MongoDB、またはその他のデータベースである可能性があります。単一サーバーの単一または複数のデータベースで管理されるすべてのテーブルまたはオブジェクトを処理する従来の方法は、モノリシックと呼ばれます。
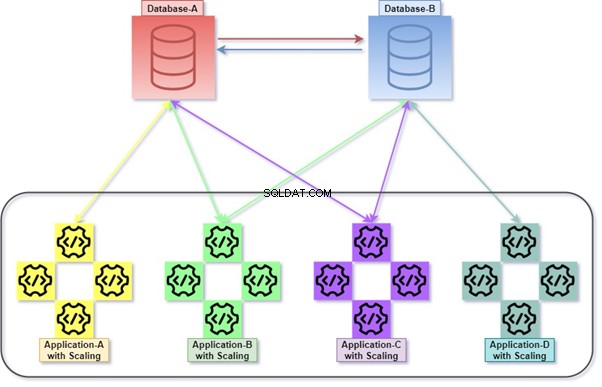
ハイブリッド
ハイブリッドは、モノリシックサービスとマイクロサービスの順列です。これは、多数のアプリケーション、多数のデータベース、およびデータベースサーバーを許可するため、非常に一般的な方法です。多数のデータベースとデータベースサーバーを相互に緊密に結合できます。
たとえば、同じデータベースサーバーまたは異なるデータベースサーバー内の2つ以上のデータベースに属するテーブル間でJOINを使用してクエリを実行します。別のデータベースサーバーでのデータの取得/操作に使用されるリモートクエリ。
すべてはSQLServerアーキテクチャに関するものです。ただし、同じデータベース内の異なるテーブル間、または同じサーバーまたは異なるサーバー上に存在する可能性のある異なるデータベース間でのデータ操作について話します。
ハイブリッドアーキテクチャまたはモノリシックアーキテクチャのいずれかで、同じデータベースまたは異なるデータベース内のさまざまなテーブル間でJOINを使用します。テーブルの分散はデータベースサービス(Dbas)間で行われる可能性があるため、コアのマイクロサービス標準に従うと非常に複雑になります。
Microsoft SQL Server、Oracleなどのエンタープライズデータベーステクノロジでは、ユーザーはリンクサーバー結合を使用して分散データベースのテーブルをクエリできます。ただし、すべてのオープンソースデータベーステクノロジで使用できるわけではありません。これは、リモートデータベースサービスが利用できない場合に機能しない可能性があるタイトカップリングアプローチとして知られています。
それでは、緩い結合にすることについて説明しましょう。リモートデータベース間でデータ操作が必要なのはなぜですか?
リモートデータベース間でデータ操作が必要なのはなぜですか?
システムがマイクロサービスまたはハイブリッドサービスを使用して設計されている場合、ユーザーは複数のデータベースサービスからデータを取得する必要があります。プロセス全体は、アプリケーションによって操作されるデータ量を処理できるバックエンドから見られます。
リアルタイムのクロスデータベースクエリを見ると、メタデータテーブルではなく、常にマスターエンティティテーブルを結合します。マスターテーブルはメタデータテーブルより大きくなりません。レポートの目的で、私たちは常にデータウェアハウスを使用してすべての情報をまとめます。しかし、それは製品ごとに管理および保守するのは簡単ではありません。エンタープライズソリューションを設計すれば、倉庫を購入する余裕があります。しかし、中小規模の製品にはそれを買う余裕はありません。
たとえば、さまざまなデータベースにある複数のテーブルのデータを含むレポートが必要です。さまざまなマイクロサービスを使用してデータを照合し、それをマージしてレポートを作成するため、実行するのは簡単な作業ではありません。したがって、必要なデータを同期する必要があります。
標準ソリューションとして使用できるもの2つのデータベース間で緩く結合されたテーブルデータの同期を行うには?
テーブルレプリケーションは、複数のデータベース間の単純なデータ同期に使用する必要があります。この例は、SQLServerによって提供されるシンプレックスデータ同期のトランザクションレプリケーションとデュプレックスデータ同期のマージレプリケーションです。
複数のデータベース間でデータを同期できる有料のサードパーティおよびオープンソースソリューションがいくつかあります。 SQL Serverトランザクションレプリケーションのようなメッセージキューを使用した疎結合ソリューションでさえ、ユーザーが独自に開発できます。
結論
DBAは独自の方法でデータベースを設計します。データベースを設計し、データベース管理システムを選択する際には、多くの側面を念頭に置く必要があります。データベース設計、特に大規模なデータベースの最も重要な要素を紹介しました。次の資料にご期待ください!