SQL Serverでのテーブルのパーティション分割は、基本的に、複数の物理テーブル(行セット)を単一のテーブルのように見せるための方法です。この抽象化は、クエリプロセッサによって完全に実行されます。これは、ユーザーにとって物事を単純化する設計ですが、クエリオプティマイザの複雑な要求を引き起こします。この投稿では、SQLServer2008以降のオプティマイザーの機能を超える2つの例を紹介します。
列の順序に関する事項に参加する
この最初の例は、ONのテキストの順序がどのようになっているのかを示しています。 句の条件は、パーティションテーブルを結合するときに生成されるクエリプランに影響を与える可能性があります。まず、パーティショニングスキーム、パーティショニング関数、および2つのテーブルが必要です。
CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES
(
10000, 20000, 30000, 40000, 50000,
60000, 70000, 80000, 90000, 100000,
110000, 120000, 130000, 140000, 150000
);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
GO
CREATE TABLE dbo.T1
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL,
CONSTRAINT PK_T1
PRIMARY KEY CLUSTERED (c1, c2, c3)
ON PS (c1)
);
CREATE TABLE dbo.T2
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL,
CONSTRAINT PK_T2
PRIMARY KEY CLUSTERED (c1, c2, c3)
ON PS (c1)
); 次に、両方のテーブルに150,000行をロードします。データはそれほど重要ではありません。この例では、1〜150,000のすべての整数値を含む標準のNumbersテーブルをデータソースとして使用しています。両方のテーブルに同じデータがロードされます。
INSERT dbo.T1 WITH (TABLOCKX)
(c1, c2, c3)
SELECT
N.n * 1,
N.n * 2,
N.n * 3
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
INSERT dbo.T2 WITH (TABLOCKX)
(c1, c2, c3)
SELECT
N.n * 1,
N.n * 2,
N.n * 3
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
テストクエリは、これら2つのテーブルの単純な内部結合を実行します。繰り返しになりますが、クエリは重要ではなく、特に現実的であることが意図されていません。パーティション化されたテーブルを結合するときに奇妙な効果を示すために使用されます。クエリの最初の形式は、ONを使用します c3、c2、c1の列の順序で記述された句:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
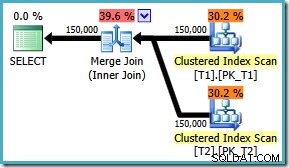
AND t1.c1 = t2.c1; このクエリ用に作成された実行プラン(SQL Server 2008以降)は、並列ハッシュ結合を特徴としており、推定コストは 2.6953 です。 :
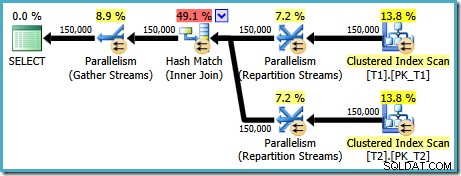
これは少し予想外です。両方のテーブルには、(c1、c2、c3)の順序でクラスター化インデックスがあり、c1でパーティション化されているため、インデックスの順序を利用してマージ結合が期待されます。 ONを書いてみましょう 代わりに(c1、c2、c3)の順序の句:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c1 = t2.c1
AND t1.c2 = t2.c2
AND t1.c3 = t2.c3; 実行プランは、予想されるマージ結合を使用するようになり、推定コストは 1.64119 ( 2.6953から減少 )。オプティマイザは、並列実行を使用する価値がないと判断します。
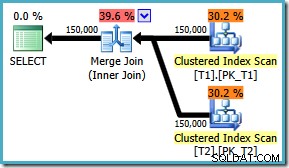
マージ結合プランの方が明らかに効率的であることに注意して、元のONのマージ結合を強制することができます。 クエリヒントを使用した句の順序:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
AND t1.c1 = t2.c1
OPTION (MERGE JOIN); 結果のプランは、要求に応じてマージ結合を使用しますが、両方の入力のソートも備えており、並列処理の使用に戻ります。このプランの推定コストはなんと8.71063 :
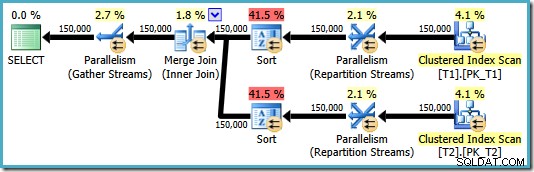
両方の並べ替え演算子には同じプロパティがあります:
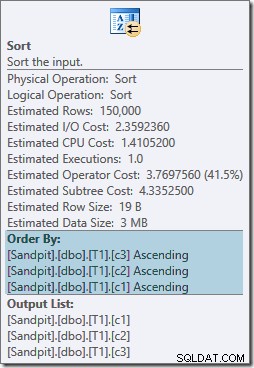
オプティマイザーは、マージ結合には、ONの厳密な記述順序でソートされた入力が必要であると考えています。 句、結果として明示的な並べ替えを導入します。オプティマイザーは、マージ結合では入力を同じ方法でソートする必要があることを認識していますが、列の順序は重要ではないことも認識しています。マージ結合(c1、c2、c3)は、入力が(c2、c1、c3)またはその他の組み合わせでソートされている場合と同様に、入力が(c3、c2、c1)でソートされている場合にも同様に満足します。
残念ながら、パーティショニングが含まれる場合、クエリオプティマイザではこの推論が壊れます。これはオプティマイザーのバグです これはSQLServer2008 R2以降で修正されていますが、トレースフラグは 4199 修正を有効にするには:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
AND t1.c1 = t2.c1
OPTION (QUERYTRACEON 4199);
通常、このトレースフラグはDBCC TRACEONを使用して有効にします。 または、QUERYTRACEONのため、スタートアップオプションとして ヒントは、4199で使用するために文書化されていません。トレースフラグは、SQL Server 2008 R2、SQL Server 2012、およびSQL Server2014CTP1で必要です。
とにかく、フラグが有効になっている場合でも、クエリはONに関係なく最適なマージ結合を生成するようになりました。 句の順序:
SQLServer2008の修正はありません 、回避策はONを書くことです 「正しい」順序の句! SQL Server 2008でこのようなクエリが発生した場合は、マージ結合を強制し、並べ替えを調べて、クエリのONを記述する「正しい」方法を決定してください。 条項。
この問題はSQLServer2005では発生しません。これは、そのリリースがAPPLYを使用してパーティション化されたクエリを実装したためです。 モデル:

SQL Server 2005のクエリプランは、処理するパーティション番号を含むメモリ内のテーブル(定数スキャン)を使用して、一度に各テーブルから1つのパーティションを結合します。各パーティションは、結合の内側で個別にマージ結合されます。2005オプティマイザーは、ONを確認できるほど賢いです。 句の列の順序は重要ではありません。
この最新の計画は、併置されたマージ結合の例です。 、SQLServer2005からSQLServer2008の新しいパーティショニング実装に移行したときに失われた機能。併置されたマージ結合を復元するためのConnectに関する提案は、修正されないため終了しました。
Group By Order Matters
私が見たい2番目の特徴は、同様のテーマに従いますが、GROUP BYの列の順序に関連しています。 ONではなく句 内部結合の節。デモンストレーション用の新しいテーブルが必要になります:
CREATE TABLE dbo.T3
(
RowID integer IDENTITY NOT NULL,
UserID integer NOT NULL,
SessionID integer NOT NULL,
LocationID integer NOT NULL,
CONSTRAINT PK_T3
PRIMARY KEY CLUSTERED (RowID)
ON PS (RowID)
);
INSERT dbo.T3 WITH (TABLOCKX)
(UserID, SessionID, LocationID)
SELECT
ABS(CHECKSUM(NEWID())) % 50,
ABS(CHECKSUM(NEWID())) % 30,
ABS(CHECKSUM(NEWID())) % 10
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000; テーブルには、整列された非クラスター化インデックスがあります。「整列」とは、クラスター化されたインデックス(またはヒープ)と同じ方法でパーティション化されていることを意味します。
CREATE NONCLUSTERED INDEX nc1 ON dbo.T3 (UserID, SessionID, LocationID) ON PS (RowID);
テストクエリは、3つの非クラスター化インデックス列にまたがるデータをグループ化し、各グループのカウントを返します。
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 GROUP BY LocationID, UserID, SessionID;
クエリプランは非クラスター化インデックスをスキャンし、ハッシュ一致集計を使用して各グループの行をカウントします。
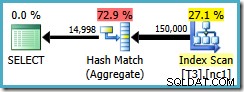
HashAggregateには2つの問題があります。
- これはブロッキング演算子です。すべての行が集約されるまで、行はクライアントに返されません。
- ハッシュテーブルを保持するには、メモリの付与が必要です。
多くの実際のシナリオでは、ここでStream Aggregateを使用することをお勧めします。これは、そのオペレーターがグループごとにブロックするだけであり、メモリの付与を必要としないためです。このオプションを使用すると、クライアントアプリケーションはより早くデータの受信を開始し、メモリが付与されるのを待つ必要がなくなり、SQLServerはそのメモリを他の目的に使用できます。
OPTION (ORDER GROUP)を追加することで、クエリオプティマイザにこのクエリにStreamAggregateを使用するように要求できます。 クエリヒント。これにより、次の実行プランが作成されます。

並べ替え演算子は完全にブロックされており、メモリの付与も必要であるため、この計画は単にハッシュ集計を使用するよりも悪いようです。しかし、なぜそのようなものが必要なのですか?プロパティは、行がGROUP BYで指定された順序で並べ替えられていることを示しています 条項:
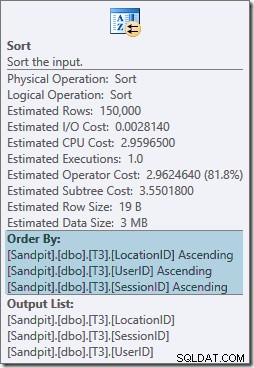
この種は期待される インデックスのパーティション整列(SQL Server 2008以降)は、パーティション番号がインデックスの先頭の列として追加されることを意味するためです。事実上、非クラスター化インデックスキーは(パーティション、ユーザー、セッション、場所)パーティション化のためです。インデックス内の行は引き続きユーザー、セッション、場所で並べ替えられますが、各パーティション内でのみ並べ替えられます。
クエリを単一のパーティションに制限する場合、オプティマイザはインデックスを使用して、ソートせずにStreamAggregateにフィードできるようにする必要があります。説明が必要な場合、単一のパーティションを指定すると、クエリプランで非クラスター化インデックススキャンから他のすべてのパーティションを削除できるため、(ユーザー、セッション、場所)順に並べられた行のストリームが生成されます。
$PARTITIONを使用して、このパーティションの削除を明示的に実現できます。 機能:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 WHERE $PARTITION.PF(RowID) = 1 GROUP BY LocationID, UserID, SessionID;
残念ながら、このクエリは依然としてハッシュ集計を使用しており、推定計画コストは 0.287878 です。 :
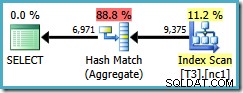
スキャンは1つのパーティションを超えていますが、(ユーザー、セッション、場所)の順序は、オプティマイザーがStreamAggregateを使用するのに役立ちませんでした。 GROUP BYのため、(ユーザー、セッション、場所)の順序が役に立たないことに異議を唱えるかもしれません。 句は(場所、ユーザー、セッション)ですが、グループ化操作ではキーの順序は重要ではありません。
ORDER BYを追加しましょう ポイントを証明するためのインデックスキーの順序での句:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 WHERE $PARTITION.PF(RowID) = 1 GROUP BY LocationID, UserID, SessionID ORDER BY UserID, SessionID, LocationID;
ORDER BYに注意してください GROUP BYですが、句は非クラスター化インデックスキーの順序と一致します 節はしません。このクエリの実行プランは次のとおりです。
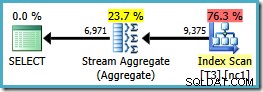
これで、私たちが求めていたStream Aggregateができました。推定計画コストは、 0.0423925 です。 ( 0.287878と比較して Hash Aggregateプランの場合–ほぼ7倍)
ここでStreamAggregateを実現する別の方法は、GROUP BYを並べ替えることです。 非クラスター化インデックスキーと一致する列:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1 GROUP BY UserID, SessionID, LocationID;
このクエリは、まったく同じコストで、すぐ上に示したものと同じStreamAggregateプランを生成します。 GROUP BYに対するこの感度 列の順序は、SQLServer2008以降のパーティションテーブルクエリに固有です。
ここでの問題の根本的な原因は、マージ結合を含む前のケースと同様であることに気付くかもしれません。マージ結合とストリーム集約はどちらも、結合キーまたは集約キーでソートされた入力を必要としますが、どちらもこれらのキーの順序を気にしません。 (x、y、z)でのマージ結合は、(y、z、x)または(z、y、x)で順序付けられた行を受け取るのと同じように満足でき、StreamAggregateについても同じことが言えます。
このオプティマイザーの制限は、DISTINCTにも適用されます。 同じ状況で。次のクエリは、推定コストが 0.286539のハッシュ集計プランになります。 :
SELECT DISTINCT LocationID, UserID, SessionID FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1;
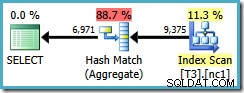
DISTINCTを書くと 非クラスター化インデックスキーの順序の列…
SELECT DISTINCT UserID, SessionID, LocationID FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1;
…0.041455のコストでStreamAggregateプランが提供されます :

要約すると、これはSQL Server 2008以降(SQL Server 2014 CTP 1を含む)のクエリオプティマイザーの制限であり、トレースフラグ4199を使用しても解決されません マージ結合の例の場合と同様です。この問題は、GROUP BYを持つパーティション化されたテーブルでのみ発生します またはDISTINCT 単一のパーティションが処理される、整列されたパーティション索引を使用する3つ以上の列。
マージ結合の例と同様に、これはSQLServer2005の動作からの後退ステップを表しています。 SQL Server 2005は、APPLYを使用して、パーティションインデックスに暗黙の先行キーを追加しませんでした 代わりにテクニック。 SQL Server 2005では、$PARTITIONを使用してここに表示されるすべてのクエリ 単一のパーティションを指定すると、クエリプランでパーティションの削除が実行され、クエリテキストの並べ替えなしでStreamAggregatesが使用されます。
SQL Server 2008でのパーティションテーブル処理の変更により、主にパーティションの効率的な並列処理に関連するいくつかの重要な領域のパフォーマンスが向上しました。残念ながら、これらの変更には副作用がありましたが、それ以降のリリースではすべて解決されていません。