ハッシュインデックスはデータベースの不可欠な部分です。データベースを使用したことがある場合は、データベースが実際に動作しているのを、気付かないうちに見たことがある可能性があります。
ハッシュインデックスは、ディスク上にあるレコードへのポインタではなく値を格納するため、他のタイプのインデックスとは動作が異なります。これにより、検索とインデックスへの挿入が高速になります。そのため、ハッシュインデックスは主キーまたは一意の識別子としてよく使用されます。
ハッシュインデックスについて
ハッシュインデックスは、データ管理で最も一般的に使用されるインデックスタイプです。通常、主キーや電子メールアドレスなどの一意の値を含む列に作成されます。ハッシュインデックスを使用する主な利点は、パフォーマンスが速いことです。
これらのインデックスの背後にある概念は、これまで聞いたことがない人にとって理解できるように洗練されている可能性があります。ただし、データベースの動作を理解する必要がある場合は、ハッシュインデックスを理解することが重要です。データベースとその速度に関連する一般的な問題を解決するために必要です。
良いニュースは、少しの忍耐と携帯電話の電源を切ることで、ハッシュインデックスを確実にマスターできることです!それでは、よく見てみましょう。
すばやく簡単
ハッシュインデックスは、データベースクエリを高速化するために使用できるデータ構造です。これは、入力レコードをバケットの配列に変換することによって機能します。各バケットには、テーブル内の他のすべてのバケットと同じ数のレコードがあります。したがって、特定の列にいくつの異なる値がある場合でも、すべての行は常に1つのバケットにマップされます。
ハッシュインデックスを使用すると、テーブルに格納されているデータをすばやく検索できます。これらは、値からインデックスキーを作成し、結果のハッシュに基づいてインデックスキーを見つけることで機能します。すべてのレコードを調べるのではなく、キーを比較するだけでよいため、類似した値または重複する入力が多数ある場合に便利です。
これは迅速でも簡単でもありませんでしたか?ハッシュインデックスがどのように機能し、なぜそれらが非常に強力であるかを理解するには、ハッシュの意味を理解する必要があります。
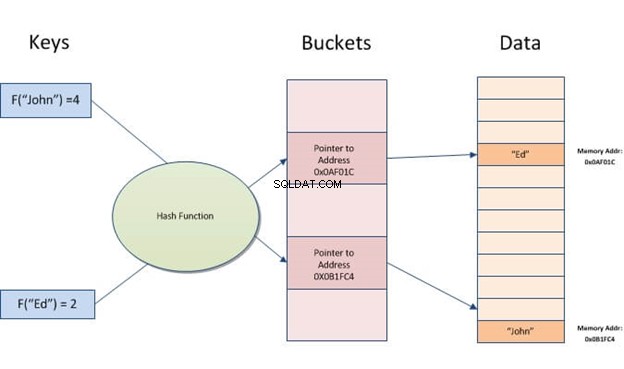
ハッシュ 情報の一部(文字列)を取得し、後ですばやくアクセスできるようにアドレスまたはポインタに変換します。
ハッシュの考え方は、データに少数が割り当てられるというものです。データを検索するときに、実際に大量にふるいにかける必要はありません。代わりに、その1つの番号を調べてください。最も簡単な例は、数十ページを自分で読むのではなく、テキスト内で探している単語をCtrl+Fで押すことです。
ハッシュインデックスとは何ですか?
ハッシュインデックスは、検索プロセスを高速化する方法です。従来のインデックスでは、クエリが成功することを確認するためにすべての行をスキャンする必要があります。しかし、ハッシュインデックスの場合、これは当てはまりません!
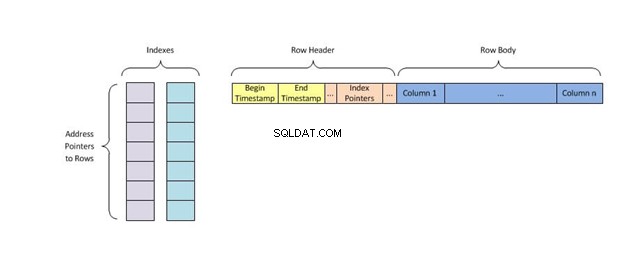
インデックスの各キーには、テーブルデータの1行のみが含まれ、ハッシュと呼ばれるインデックスアルゴリズムを使用します。 これにより、メモリ内の一意の場所が割り当てられ、探しているものを見つける前に、値が重複している他のすべてのキーが削除されます。
ハッシュインデックスは、データベース内のデータを整理するための多くの方法の1つです。それらは、入力を受け取り、それをディスクに保存するためのキーとして使用することによって機能します。これらのキー、またはハッシュ値 、文字列の長さから入力の文字まで、何でもかまいません。
ハッシュインデックスは、特定の属性を持つ特定の入力をクエリするときに最も一般的に使用されます。たとえば、10cmを超えるすべてのA文字を検索している可能性があります。ハッシュインデックス関数を作成することで、すばやく実行できます。
ハッシュインデックスはPostgreSQLデータベースシステムの一部です。このシステムは、速度とパフォーマンスを向上させるために開発されました。ハッシュインデックスは、BツリーやGiSTなどの他のインデックスタイプと組み合わせて使用できます。
ハッシュインデックスは、キーをバケットと呼ばれる小さなチャンクに分割して保存します。各バケットには整数のID番号が割り当てられ、ハッシュテーブルでキーの場所を検索するときにすばやく取得できます。バケットはディスクに順番に保存されるため、バケットに含まれるデータにすばやくアクセスできます。
より技術的な説明はこのページにあります(マウスを右クリックして「英語に翻訳」を選択してください)。
利点
ハッシュインデックスを使用する主な利点は、キー値でレコードを取得するときに高速アクセスが可能になることです。これは、等式条件を持つクエリに役立つことがよくあります。また、ハッシュベンチマークを使用しても、多くのストレージスペースは必要ありません。したがって、これは効果的なツールですが、欠点がないわけではありません。
短所
ハッシュインデックスは比較的新しいインデックス構造であり、パフォーマンスに大きなメリットをもたらす可能性があります。それらは、二分探索木(BST)の拡張と考えることができます。
ハッシュインデックスは、ハッシュ値に基づいてデータをバケットに格納することで機能します。これにより、データを高速かつ効率的に取得できます。それらは正常であることが保証されています。
ただし、重複するキーをバケット内に保存することはできません。したがって、常にいくらかのオーバーヘッドがあります。しかし、これまでのところ、ハッシュインデックスを使用することの長所は短所を上回っています。
すべてがもう少し深く機能するのですか?
デモを見てみましょうaviasales ハッシュインデックスがどのように機能するかをより深く理解するためのデータベース。
demo=# create index on flights using hash(flight_no);
WARNING: hash indexes are not WAL-logged and their use is discouraged
CREATE INDEX
demo=# explain (costs off) select * from flights where flight_no = 'PG0001';
QUERY PLAN
----------------------------------------------------
Bitmap Heap Scan on flights
Recheck Cond: (flight_no = 'PG0001'::bpchar)
-> Bitmap Index Scan on flights_flight_no_idx
Index Cond: (flight_no = 'PG0001'::bpchar)
(4 rows)
ここでは、データをセットにコンパイルすることでハッシュインデックスを実装する方法を確認できます。
これは簡単な例ですが、制限はコードインフラストラクチャが少ないことに伴うことに注意してください。クラッシュ後にWALログアクセスが不足しているか、インデックス(インデックス?)を回復できない可能性があります。さらに、インデックスがレプリケーションに参加しない可能性があります。これは、PostgreSQLが古くなっていることが原因です。ただし、Pythonの場合と同様に、間違いを防ぐことができる警告が表示されます。
十分に興味を持っている場合は、これらのインデックスの内部を詳しく調べることができます。そのために、ページ検査を作成しています 拡張インスタンス。
demo=# create extension pageinspect;
CREATE EXTENSION
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',0));
hash_page_type
----------------
metapage
(1 row)
demo=# select ntuples, maxbucket from hash_metapage_info(get_raw_page('flights_flight_no_idx',0));
ntuples | maxbucket
---------+-----------
33121 | 127
(1 row)
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',1));
hash_page_type
----------------
bucket
(1 row)
demo=# select live_items, dead_items from hash_page_stats(get_raw_page('flights_flight_no_idx',1));
live_items | dead_items
------------+------------
407 | 0
(1 row)
コードを完全に検査したい場合は、READMEから始めてください。
概要
ハッシュインデックスは、大規模なデータベースで情報を検索するプロセスを高速化するデータ構造です。これらは、データを小さなチャンクに分割してから並べ替えることで機能します。したがって、何かを検索すると、はるかに速く見つけることができます。
もっと調べたい場合は、DYORのリソースがあります。また、このページの「ハッシュ」という単語をCtrl+Fで押すよりも早く公開される新しい記事にも注目してください。これがお役に立てば幸いです!