グループ化は、データの整理と整理に役立つ重要な機能です。これを行うには多くの方法があり、最も効果的な方法の1つはSQLGROUPBY句です。
SQL GROUP BYを使用して、結果の行を集計関数でグループに分割できます。 。レコードの合計、平均、カウントは簡単に聞こえます。
しかし、あなたはそれを正しくやっていますか?
「正しい」は主観的である可能性があります。重大なエラーが発生せず、正しい出力で実行されている場合は、問題ないと見なされます。ただし、それも迅速である必要があります。
この記事では、速度も考慮されます。すべてのポイントで論理読み取りと実行プランを使用した多くのクエリ分析が表示されます。
始めましょう。
1。早期にフィルタリング
WHEREとHAVINGをいつ使用するかについて混乱している場合は、これが最適です。提供する条件によっては、どちらも同じ結果になる可能性があるためです。
しかし、それらは異なります。
HAVINGは、SQLGROUPBY句の列を使用してグループをフィルタリングします。 WHEREは、グループ化と集計が行われる前に行をフィルタリングします。したがって、HAVING句を使用してフィルタリングすると、すべてに対してグループ化が行われます。 行が返されました。
そしてそれは悪いことです。
なんで?簡単に言えば、遅いです。これを2つのクエリで証明しましょう。以下のコードを確認してください。 SQL Server Management Studioで実行する前に、まずCtrl-Mを押してください。
SET STATISTICS IO ON
GO
-- using WHERE
SELECT
MONTH(soh.OrderDate) AS OrderMonth
,YEAR(soh.OrderDate) AS OrderYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.Name, YEAR(soh.OrderDate), MONTH(soh.OrderDate)
ORDER BY Product, OrderYear, OrderMonth;
-- using HAVING
SELECT
MONTH(soh.OrderDate) AS OrderMonth
,YEAR(soh.OrderDate) AS OrderYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
GROUP BY p.Name, YEAR(soh.OrderDate), MONTH(soh.OrderDate)
HAVING YEAR(soh.OrderDate) = 2012
ORDER BY Product, OrderYear, OrderMonth;
SET STATISTICS IO OFF
GO
分析
上記の2つのSELECTステートメントは、同じ行を返します。 2012年の月ごとの返品注文はどちらも正しいです。しかし、最初のSELECTには136ミリ秒かかりました。私のラップトップで実行するのに、別のラップトップは764msかかりました。!
なぜですか?
図1で最初に論理読み取りを確認してみましょう。STATISTICSIOはこれらの結果を返しました。次に、フォーマットされた出力用にStatisticsParser.comに貼り付けました。
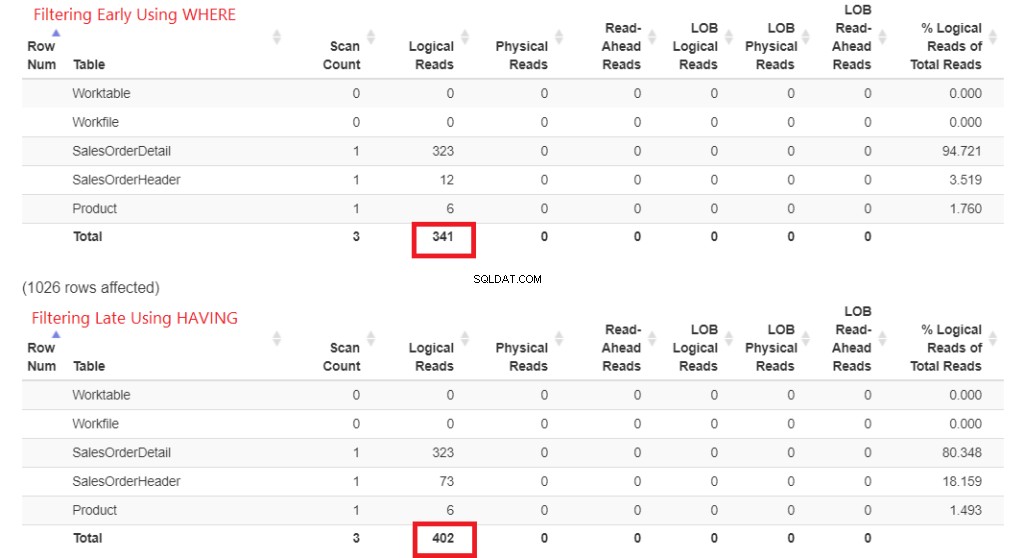
図1 。 WHEREを使用した早期のフィルタリングと、HAVINGを使用した後期のフィルタリングの論理的な読み取り。
それぞれの論理読み取りの合計を見てください。これらの数値を理解するために、より論理的な読み取りが行われるほど、クエリは遅くなります。したがって、HAVINGの使用は遅く、WHEREで早期にフィルタリングする方が速いことがわかります。
もちろん、これはHAVINGが役に立たないという意味ではありません。 1つの例外は、 HAVING SUM(sod.Linetotal)> 100000のような集計でHAVINGを使用する場合です。 。 WHERE句とHAVING句を1つのクエリに組み合わせることができます。
図2の実行計画を参照してください。
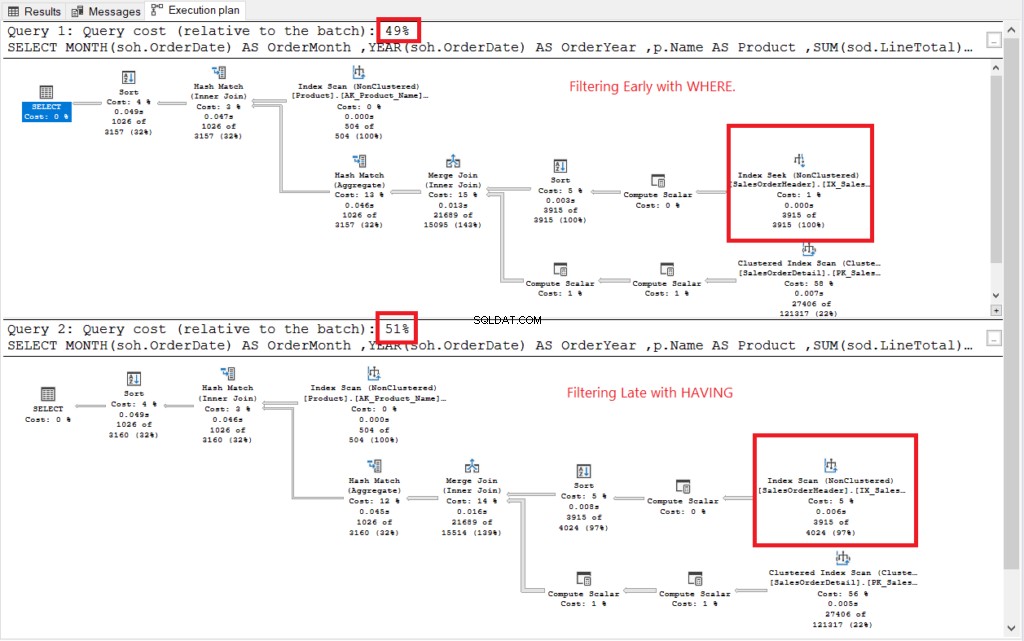
図2 。 早期フィルタリングと遅延フィルタリングの実行計画。
赤で囲まれたものを除いて、両方の実行計画は類似しているように見えました。初期のフィルタリングではインデックスシーク演算子を使用し、別のフィルタリングではインデックススキャンを使用しました。シークは、大きなテーブルでのスキャンよりも高速です。
いいえ te: 早期にフィルタリングする方が、遅くフィルタリングするよりもコストが低くなります。つまり、最終的には行を早期にフィルタリングすることでパフォーマンスを向上させることができます。
2。最初にグループ化し、後で参加する
後で必要なテーブルのいくつかを結合することで、パフォーマンスを向上させることもできます。
毎月の商品販売をしたいとします。また、製品名、番号、およびサブカテゴリをすべて同じクエリで取得する必要があります。これらの列は別のテーブルにあります。また、実行を成功させるには、これらすべてをGROUPBY句に追加する必要があります。これがコードです。
SET STATISTICS IO ON
GO
SELECT
p.Name AS Product
,p.ProductNumber
,ps.Name AS ProductSubcategory
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER JOIN Production.Product p ON sod.ProductID = p.ProductID
INNER JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.name, p.ProductNumber, ps.Name
ORDER BY Product
SET STATISTICS IO OFF
GO
これは正常に実行されます。しかし、より良い、より速い方法があります。これにより、GROUP BY句に製品名、番号、サブカテゴリの3つの列を追加する必要はありません。ただし、これにはもう少しキーストロークが必要になります。
SET STATISTICS IO ON
GO
;WITH Orders2012 AS
(
SELECT
sod.ProductID
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY sod.ProductID
)
SELECT
P.Name AS Product
,P.ProductNumber
,ps.Name AS ProductSubcategory
,o.ProductSales
FROM Orders2012 o
INNER JOIN Production.Product p ON o.ProductID = p.ProductID
INNER JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID
ORDER BY Product;
SET STATISTICS IO OFF
GO
分析
なぜこれが速いのですか? 製品への参加 およびProductSubcategory 後で行われます。どちらもGROUPBY句には含まれていません。 STATISTICSIOの数字でこれを証明しましょう。図4を参照してください。
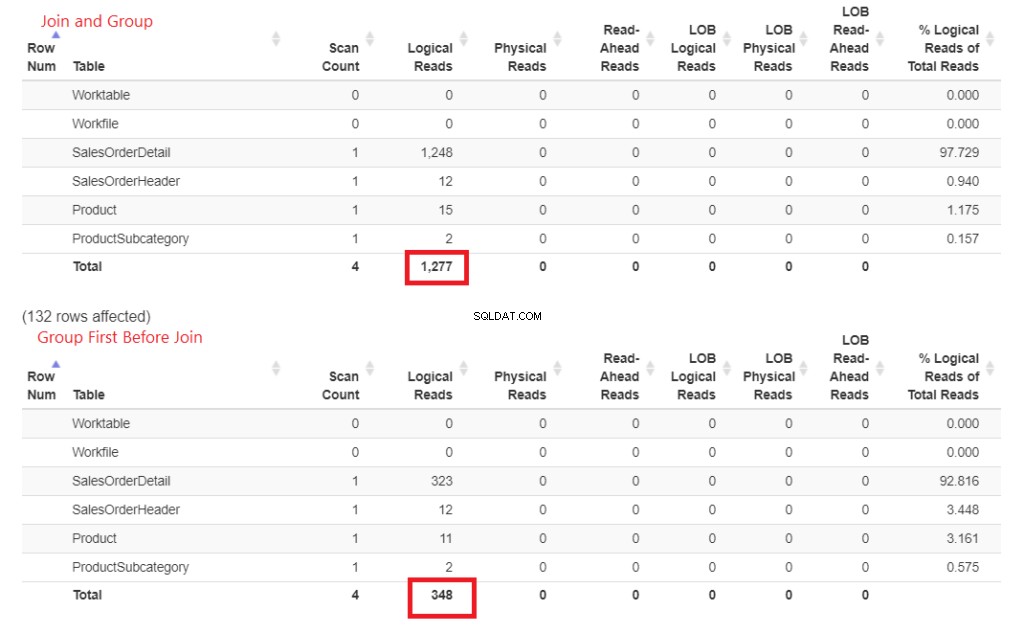
図3 。 早期に参加してからグループ化すると、後で参加するよりも多くの論理読み取りが消費されました。
それらの論理的な読み取りを参照してください?違いは大きく、勝者は明らかです。
2つのクエリの実行プランを比較して、上記の数値の背後にある理由を確認しましょう。まず、グループ化されたときにすべてのテーブルが結合されたクエリの実行プランについては、図4を参照してください。
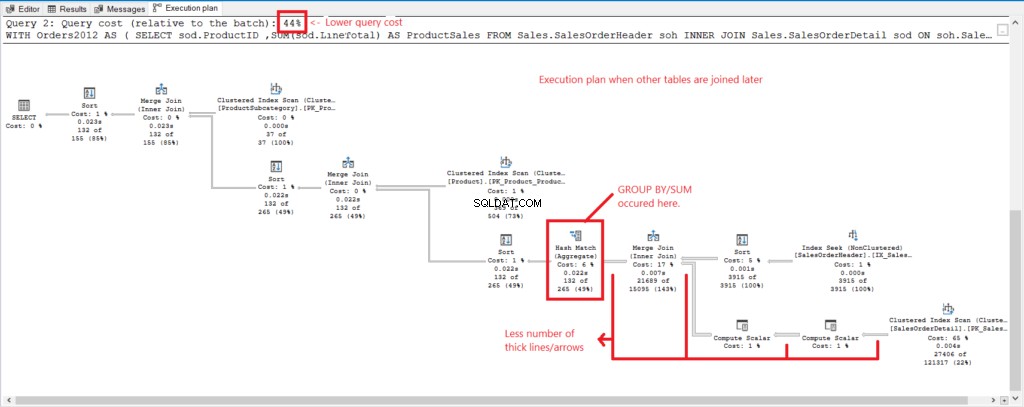
図4 。 すべてのテーブルが結合されたときの実行プラン。
そして、次の所見があります:
- GROUP BYとSUMは、すべてのテーブルを結合した後、プロセスの後半で実行されました。
- 多くの太い線と矢印–これは1,277の論理読み取りを説明しています。
- 2つのクエリを組み合わせると、クエリコストの100%になります。ただし、このクエリのプランでは、クエリのコストが高くなります(56%)。
さて、これが最初にグループ化して製品に参加したときの実行計画です。 およびProductSubcategory 後でテーブル。図5を確認してください。
図5 。 グループが最初に実行され、後で参加する実行計画。
また、図5には次のような所見があります。
- GROUPBYとSUMは早期に終了しました。
- 太い線と矢印の数が少ない–これは348の論理読み取りのみを説明しています。
- クエリコストの削減(44%)。
3。インデックス付きの列をグループ化する
SQL GROUP BYが列に対して実行される場合は常に、その列にインデックスが必要です。列をインデックスでグループ化すると、実行速度が向上します。前のクエリを変更して、注文日の代わりに出荷日を使用してみましょう。出荷日列には、 SalesOrderHeaderにインデックスがありません 。
SET STATISTICS IO ON
GO
SELECT
MONTH(soh.ShipDate) AS ShipMonth
,YEAR(soh.ShipDate) AS ShipYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
WHERE soh.ShipDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.Name, YEAR(soh.ShipDate), MONTH(soh.ShipDate)
ORDER BY Product, ShipYear, ShipMonth;
SET STATISTICS IO OFF
GO
Ctrl-Mを押してから、SSMSで上記のクエリを実行します。次に、 ShipDateに非クラスター化インデックスを作成します 桁。論理読み取りと実行プランに注意してください。最後に、別のクエリタブで上記のクエリを再実行します。論理読み取りと実行計画の違いに注意してください。
これが図6の論理読み取りの比較です。
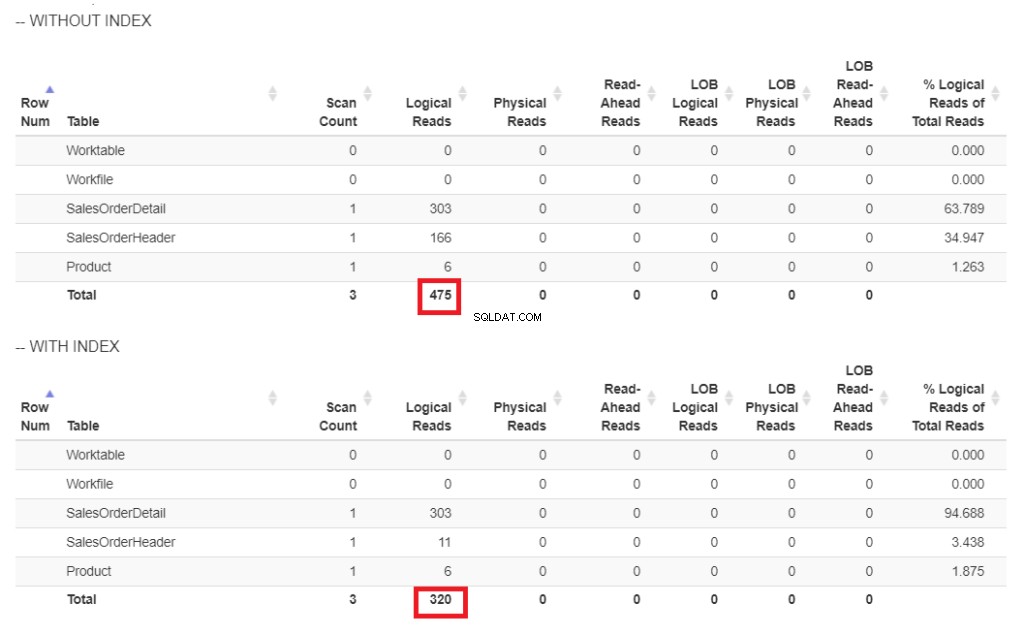
図6 。 ShipDateにインデックスがある場合とない場合のクエリ例の論理的な読み取り。
図6では、 ShipDateにインデックスがない場合のクエリの論理読み取りが高くなっています。 。
次に、 ShipDateにインデックスがない場合の実行プランを作成しましょう。 図7に存在します。
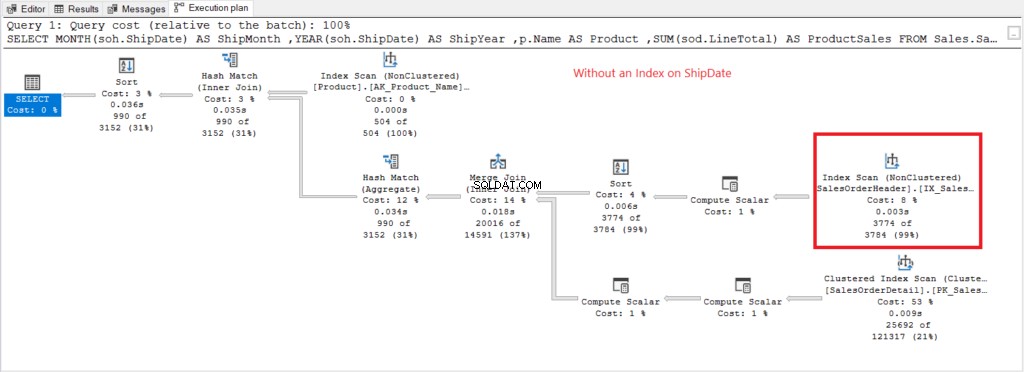
図7 。 ShipDateでインデックスなしでGROUPBYを使用する場合の実行プラン。
インデックススキャン 図7の計画で使用されている演算子は、より高い論理読み取り(475)を説明しています。 ShipDateにインデックスを付けた後の実行プランは次のとおりです。 列。
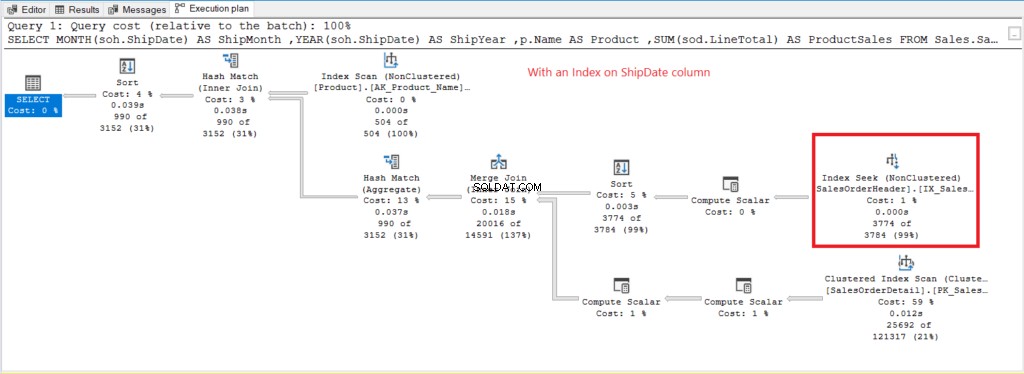
図8 。 インデックスに登録されたShipDateでGROUPBYを使用する場合の実行プラン。
ShipDate のインデックスを作成した後、インデックススキャンの代わりにインデックスシークが使用されます。 桁。これは、図6の下位の論理読み取りを説明しています。
したがって、GROUP BYを使用するときのパフォーマンスを向上させるには、グループ化に使用した列にインデックスを付けることを検討してください。
SQLGROUPBYの使用に関するポイント
SQLGROUPBYは使いやすいです。ただし、レポートのデータを要約するだけでなく、次のステップに進む必要があります。ここでもポイントがあります:
- 早期にフィルタリング 。 HAVING句の代わりにWHERE句を使用して、要約する必要のない行を削除します。
- 最初にグループ化し、後で参加する 。グループ化する列とは別に、追加する必要のある列がある場合があります。それらをGROUPBY句に含める代わりに、クエリをCTEで分割し、後で他のテーブルを結合します。
- インデックス付きの列でGROUPBYを使用する 。この基本的なことは、データベースがカタツムリと同じくらい速い場合に役立つかもしれません。
これが結果のグループ化でゲームをレベルアップするのに役立つことを願っています。
この投稿が気に入ったら、お気に入りのソーシャルメディアプラットフォームで共有してください。