PIVOTステートメントはテーブルの行を列に変換するために使用され、UNPIVOT演算子は列を行に変換し直します。 PIVOTステートメントを逆にすることは、元のデータセットを取得するために、すでにPIVOTEDされたデータセットにUNPIVOT演算子を適用するプロセスを指します。
この記事では、これら3つの概念をさまざまな例で学習します。
PIVOTオペレーター
前述のように、PIVOTオペレーターは、テーブルの行を列に変換します。たとえば、次のようなテーブルがある場合:

3番目の列でピボットすると、結果は次のようになります。
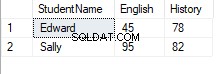
元の表では、コース列に2つの固有の値(英語と履歴)がありました。ピボットテーブルでは、これらの一意の値が列に変換されています。新しい各列のスコア値は変更されていないことがわかります。たとえば、元のテーブルでは、ピボットテーブルの値とは異なり、学生のサリーは英語で95点を獲得していました。
ライブデータベースを調整する前に、安全なバックアップを作成してください。
SQLServerでPIVOT演算子を使用するこの例を見てみましょう。
CREATE DATABASE School
GO
USE School
GO
CREATE TABLE Students
(
Id INT PRIMARY KEY IDENTITY,
StudentName VARCHAR (50),
Course VARCHAR (50),
Score INT
)
GO
INSERT INTO Students VALUES ('Sally', 'English', 95 )
INSERT INTO Students VALUES ('Sally', 'History', 82)
INSERT INTO Students VALUES ('Edward', 'English', 45)
INSERT INTO Students VALUES ('Edward', 'History', 78) 上記のスクリプトは、Schoolデータベースを作成します。データベースに、Id、StudentName、Course、Scoreなどの4つの列を持つStudentsテーブルを作成します。最後に、4つのダミーレコードをStudentsテーブルに追加します。
ここで、SELECTステートメントを使用してすべてのレコードを取得すると、次のように表示されます。
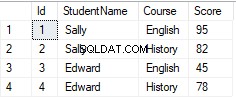
この表を[コース]列でPIVOTしましょう。これを行うには、次のスクリプトを実行します。
SELECT * FROM (SELECT StudentName, Score, Course FROM Students ) AS StudentTable PIVOT( SUM(Score) FOR Course IN ([English],[History]) ) AS SchoolPivot
スクリプトで何が起こっているか見てみましょう。最初の行では、SELECTステートメントを使用して、ピボットテーブルに追加する列を定義します。最初の2つの列はStudentNameとScoreです。これらの2つの列のデータは、Studentsテーブルから直接取得されます。 3番目の列はコースです。テーブルをCourse列でPIVOTしたいので、Course列は、Course列のPIVOT演算子で指定された値に等しい列数に分割されます。
PIVOT演算子の構文は単純です。まず、ピボットされた列に値を表示する列に集計関数を適用する必要があります。この例では、ピボットされた列(英語と履歴)にスコアを表示します。最後に、FORステートメントを使用して、ピボット列とその中の一意の値を指定します。結果は次のようになります:
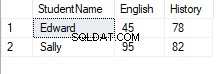
UNPIVOTオペレーター
UNPIVOT演算子は、テーブルの列を行に変換するために使用されます。たとえば、次のようなテーブルがある場合:

UNPIVOT演算子は、次の結果を返します。
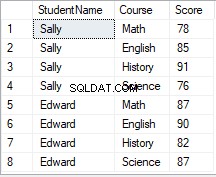
元のテーブルの列は、ピボットされていないテーブルの行に変換されています。そのデータを使用して、SQLでUNPIVOT演算子がどのように機能するかを見てみましょう。
これを行うには、次のスクリプトを実行します。
CREATE DATABASE School2
GO
USE School2
GO
CREATE TABLE Students
(
Id INT PRIMARY KEY IDENTITY,
StudentName VARCHAR (50),
Math INT,
English INT,
History INT,
Science INT
)
GO
INSERT INTO Students VALUES ('Sally', 78, 85, 91, 76 )
INSERT INTO Students VALUES ('Edward', 87, 90, 82, 87) School2データベースのStudentsテーブルからデータを選択すると、次の結果が表示されます。

このテーブルにUNPIVOT演算子を適用するには、次のクエリを実行します。
SELECT StudentName, Course, Score FROM Students UNPIVOT ( Score FOR Course in (Math, English, History, Science) ) AS SchoolUnpivot
UNPIVOT演算子の構文は、PIVOT演算子の構文と似ています。 SELECTステートメントで、出力テーブルに追加する列を指定する必要があります。 UNPIVOTステートメントでは、次の2つの列を指定します。
- 最初の列には、ピボットされた列の行の値(この場合はスコア)が含まれます。
- 2番目の列には、ピボットされた列の名前(数学、英語、歴史、科学)が含まれています。
出力テーブルは次のようになります:
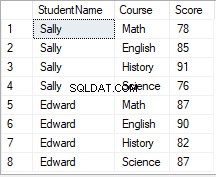
PIVOTの逆転
ピボット演算子を元に戻すとは、元のテーブルに戻すために、ピボットテーブルにUNPIVOT演算子を適用するプロセスを指します。
非集計ピボットテーブルの反転
ピボットテーブルに集計データが含まれていない場合にのみ、PIVOT演算子を元に戻すことができます。
この記事のPIVOTセクションで使用した表を見てみましょう。
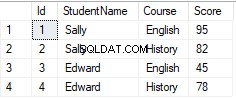
繰り返される行がないことがわかります。つまり、各学生のコースごとに1つのレコードしかないということです。たとえば、サリーは英語コースでのスコアの記録が1つしかありません。
上記の表にPIVOT演算子を適用すると、次の結果が得られました。
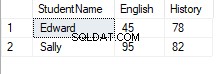
次に、この結果にUNPIVOT演算子を適用して、元のテーブルに戻ることができるかどうかを確認します。これを行うには、次のスクリプトを実行します。
注:
このクエリは、PIVOTオペレーターセクションで作成したSchoolデータベースで実行できます。
SELECT StudentName, Course, Score FROM (SELECT * FROM (SELECT StudentName, Score, Course FROM Students ) AS StudentTable PIVOT( SUM(Score) FOR Course IN ([English],[History]) ) AS SchoolPivot) PivotedResults UNPIVOT ( Score FOR Course in (English, History) ) AS Schoolunpivot
ここでは、サブクエリを使用して、ピボットされたデータにUNPIVOT演算子を適用します。内部クエリはPIVOT演算子を使用し、外部クエリはUNPIVOT演算子を使用します。出力には、元のStudentsテーブルが表示されます。
集約されたピボットテーブルの反転
先ほど、集合体データを含まないPIVOT演算子のみを元に戻すことができると述べました。集約されたデータを含むPIVOTステートメントを逆にしてみましょう。
この記事の最初のセクションで作成したSchoolデータベースのStudentsテーブルに別のレコードを追加します。これを行うには、次のクエリを実行します。
INSERT INTO Students VALUES ('Edward', 'History', 78) ここで、Studentsテーブルからすべてのレコードを選択すると、次の出力が得られます。
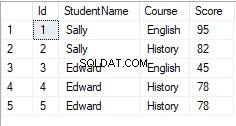
エドワードの歴史上のスコアの記録が重複していることがわかります。
次に、PIVOT演算子をこのテーブルに適用します。
SELECT Id, StudentName, English, History FROM Students PIVOT ( SUM (Score) FOR Course in (English, History) ) AS Schoolpivot
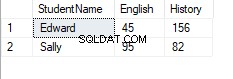
出力から、PIVOT演算子のSUM関数が、Edwardが受講した履歴コースに2つのスコアを追加したことがわかります。このテーブルのピボットを逆にしようとすると(つまり、UNPIVOT演算子を適用しようとすると)、元のテーブルを受け取ることはできません。元の5つのレコードの代わりに4つのレコードを返します。学生のエドワードの[履歴]列には、個々の結果ではなく、集計された結果が含まれます。
これを確認するには、次のスクリプトを実行します。
SELECT StudentName, Course, Score FROM (SELECT * FROM (SELECT StudentName, Score, Course FROM Students ) AS StudentTable PIVOT( SUM(Score) FOR Course IN ([English],[History]) ) AS SchoolPivot) PivotedResults UNPIVOT ( Score FOR Course in (English, History) ) AS Schoolunpivot
出力テーブルは次のようになります:
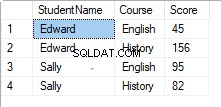
参照:
- Microsoft:PIVOTとUNPIVOTの使用
- Codingsight:SQLでのPIVOTの使用
- YouTube:リバースPIVOTビデオ