Sparkは、カリフォルニア大学バークレー校のAMPLab内のプロジェクトとして2009年に誕生しました。具体的には、AMPLabでも作成されたMesosのコンセプトを証明する必要性から生まれました。 Sparkは、Mesosホワイトペーパー「Mesos:データセンターでのきめ細かいリソース共有のためのプラットフォーム」で最初に議論されました。特にBenjaminHindmanとMateiZahariaによって書かれました。
これは、大規模データの複雑な分析を実行するための高速で便利なソリューションとして登場しました。 Sparkは、MapReduceモデルの多くの欠点に対処するビッグデータの新しい処理フレームワークとして進化しました。大規模なデータ分析をサポートしており、データは、リアルタイム、画像、テキスト、グラフなどのさまざまな形式のバッチ処理など、さまざまなソースからのものである可能性があります。 Apache Sparkコアに加えて、ビッグデータ分析に役立つライブラリのセットも提供します。
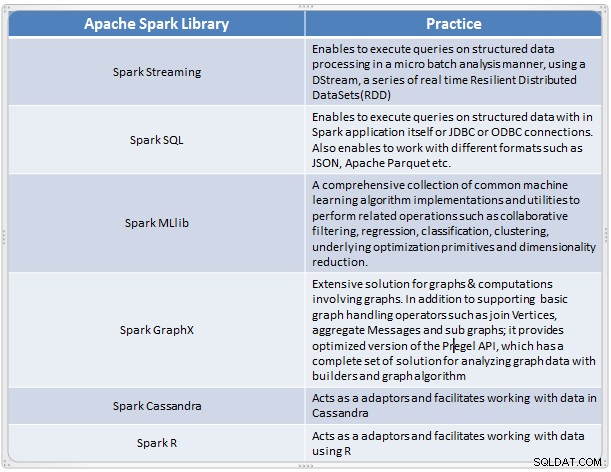
Sparkコンポーネントの概要
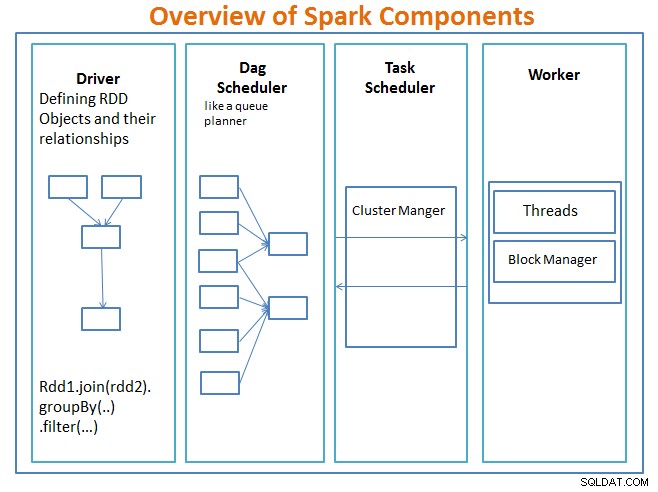
ドライバー main関数を含み、復元力のある分散データセット(RDD)とその変換を定義するコードです。 RDDは、Sparkプログラムで使用される主要なデータ構造です。
RDDの並列操作は、DAGスケジューラに送信されます。 、コードを最適化し、アプリケーションのデータ処理ステップを表す効率的なDAGに到達します。
結果のDAGはクラスタマネージャに送信されます。 クラスタマネージャは、ワーカー、割り当てられたスレッド、およびデータブロックの場所に関する情報を持ち、特定の処理タスクをワーカーに割り当てる責任があります。また、作業者が失敗した場合のペイバックも処理します。クラスターマネージャーは、YARN、Mesos、Sparkのクラスターマネージャーです。
ワーカー 管理する作業単位とデータを受け取り、ワーカーはDAG全体の知識がなくても特定のタスクを実行し、その結果はドライバーアプリケーションに返送されます。
Sparkは、他のビッグデータツールと同様に、強力で機能があり、さまざまなデータの課題に取り組むのに最適です。 Sparkは、他のビッグデータテクノロジーと同様に、必ずしもすべてのデータ処理タスクに最適な選択ではありません。
パート2では、復元力のある分散データセット、共有変数、SparkContext、変換、アクションなどのSparkの概念の基本について説明します。 、およびSparkを使用する利点と例およびSparkをいつ使用するか。
参照:
Acodemy&Hadoopアプリケーションアーキテクチャで1日でSparkを学ぶ。