クエリチューニングの重要な部分は、オプティマイザがさまざまなクエリ構造(フィルタリング、結合、グループ化、集約など)を処理するために使用できるアルゴリズムと、それらのスケーリング方法を理解することです。この知識は、適切なインデックスの作成など、クエリに最適な物理環境を準備するのに役立ちます。また、オプティマイザーが1つのアルゴリズムから別のアルゴリズムに切り替える必要があるしきい値に精通していることに基づいて、特定の状況下で計画に表示されると予想されるアルゴリズムを直感的に把握するのにも役立ちます。次に、パフォーマンスの悪いクエリを調整するときに、たとえばカーディナリティの見積もりが不正確であるためにオプティマイザが最適ではない選択を行った可能性のあるクエリプラン内の領域をより簡単に特定し、それらを修正するためのアクションを実行できます。
クエリチューニングのもう1つの重要な部分は、わかりやすいツールを使用するときにオプティマイザが使用できるアルゴリズムを超えて、箱から出して考えることです。クリエイティブに。最適な物理環境を調整したにもかかわらず、パフォーマンスが悪いクエリがあるとします。使用したクエリ構成の場合、オプティマイザで使用できるアルゴリズムはx、y、zであり、オプティマイザはその状況下で可能な限り最良のものを選択しました。それでも、クエリのパフォーマンスは良くありません。はるかに優れたパフォーマンスのクエリを生成できるアルゴリズムを使用した理論的な計画を想像できますか?あなたがそれを想像できるなら、おそらくタスクのためのあまり明白でないクエリ構造で、いくつかのクエリの書き直しでそれを達成することができるでしょう。
このシリーズの記事では、データのグループ化と集約に焦点を当てています。グループ化されたクエリを使用するときにオプティマイザが使用できるアルゴリズムを確認することから始めます。次に、既存のアルゴリズムのいずれもうまく機能しないシナリオについて説明し、優れたパフォーマンスとスケーリングをもたらすクエリの書き換えを示します。
クエリの最適化に関する質問に答えてくれた、地球上で最も賢い人々とSQLServer開発者の交差点のメンバーであるCraigFreedman、Vassilis Papadimos、JoeSackに感謝します。
サンプルデータには、PerformanceV3というデータベースを使用します。ここから、データベースを作成してデータを取り込むためのスクリプトをダウンロードできます。 1,000,000行が入力されているdbo.Ordersというテーブルを使用します。このテーブルには、不要で私の例に干渉する可能性のあるインデックスがいくつかあるため、次のコードを実行して、これらの不要なインデックスを削除します。
DROP INDEX idx_nc_sid_od_cid ON dbo.Orders; DROP INDEX idx_unc_od_oid_i_cid_eid ON dbo.Orders;
このテーブルに残っている2つのインデックスは、orderdate列のidx_cl_odと呼ばれるクラスター化インデックスと、orderid列のPK_Ordersと呼ばれる非クラスター化一意インデックスであり、主キー制約を適用します。
EXEC sys.sp_helpindex 'dbo.Orders';
index_name index_description index_keys ----------- ----------------------------------------------------- ----------- idx_cl_od clustered located on PRIMARY orderdate PK_Orders nonclustered, unique, primary key located on PRIMARY orderid>
既存のアルゴリズム
SQL Serverは、データを集約するための2つの主要なアルゴリズムであるStreamAggregateとHashAggregateをサポートしています。グループ化されたクエリでは、Stream Aggregateアルゴリズムでは、データをグループ化された列で並べ替える必要があるため、2つのケースを区別する必要があります。 1つは、事前に注文されたStream Aggregateです。たとえば、データがインデックスから事前に注文されて取得される場合です。もう1つは、事前に順序付けされていないStream Aggregateで、入力を明示的に並べ替えるために追加の手順が必要です。これらの2つのケースは非常に異なるスケーリングであるため、2つの異なるアルゴリズムと見なす方がよいでしょう。
Hash Aggregateアルゴリズムは、グループとその集計をハッシュテーブルに編成します。入力を注文する必要はありません。
十分なデータがあれば、オプティマイザーは作業の並列化を検討し、ローカルグローバルアグリゲートと呼ばれるものを適用します。このような場合、入力は複数のスレッドに分割され、各スレッドは前述のアルゴリズムの1つを適用して、行のサブセットをローカルに集約します。次に、グローバルアグリゲートは、前述のアルゴリズムの1つを使用して、ローカルアグリゲートの結果を集約します。
この記事では、事前に注文されたStreamAggregateアルゴリズムとそのスケーリングに焦点を当てます。このシリーズの今後のパートでは、他のアルゴリズムについて説明し、オプティマイザーが切り替えるしきい値と、クエリの書き換えを検討する必要がある場合について説明します。
事前注文されたストリームアグリゲート
空でないグループ化セット(グループ化する式のセット)を使用したグループ化されたクエリの場合、Stream Aggregateアルゴリズムでは、グループ化セットを形成する式によって入力行を並べ替える必要があります。アルゴリズムがグループの最初の行を処理するとき、中間の集計値を保持しているメンバーを関連する値(たとえば、MAX集計の最初の行の値)で初期化します。グループ内の最初以外の行を処理する場合、中間集計値と新しい行の値(たとえば、中間集計値と新しい値の間の最大値)を含む計算の結果をそのメンバーに割り当てます。グループ化セットのメンバーのいずれかがその値を変更するか、入力が消費されるとすぐに、現在の集計値が最後のグループの最終結果と見なされます。
Stream Aggregateアルゴリズムが必要とするようにデータを順序付けする1つの方法は、インデックスから事前に順序付けされたデータを取得することです。グループ化セットの列をキーとして、それらの間の任意の順序でインデックスを定義する必要があります。また、インデックスをカバーする必要があります。たとえば、次のクエリ(クエリ1と呼びます)について考えてみます。
SELECT shipperid, MAX(orderdate) AS maxorderid FROM dbo.Orders GROUP BY shipperid;
このクエリをサポートするための最適な行ストアインデックスは、shipperidを先頭のキー列として定義し、orderdateをインクルード列または2番目のキー列として定義したものです。
CREATE INDEX idx_sid_od ON dbo.Orders(shipperid, orderdate);
このインデックスを設定すると、図1に示す推定計画が得られます(SentryOneプランエクスプローラーを使用)。

図1:クエリ1の計画
インデックススキャン演算子には、インデックスキーで順序付けられた行を配信する必要があることを示すOrdered:Trueプロパティがあることに注意してください。次に、Stream Aggregateオペレーターは、必要に応じて順序付けられた行を取り込みます。オペレーターのコストの計算方法については、その前に、最初に簡単な序文を…
ご存知かもしれませんが、SQL Serverがクエリを最適化すると、複数の候補プランが評価され、最終的に推定コストが最も低いプランが選択されます。推定計画コストは、すべてのオペレーターの推定コストの合計です。同様に、各オペレーターの推定コストは、推定I/Oコストと推定CPUコストの合計です。コスト単位はそれ自体では無意味です。その関連性は、オプティマイザーが候補プラン間で行う比較にあります。つまり、原価計算式は、候補プラン間で、コストが最も低いものが(うまくいけば)より早く終了するものを表すことを目標に設計されました。正確に行うには非常に複雑な作業です!
原価計算式がアルゴリズムのパフォーマンスとスケーリングに実際に影響する要因を適切に考慮すればするほど、それらはより正確になり、正確なカーディナリティ推定が与えられると、オプティマイザーは最適な計画を選択する可能性が高くなります。いずれにせよ、オプティマイザーが1つのアルゴリズムと別のアルゴリズムを選択する理由を理解したい場合は、2つの主要なことを理解する必要があります。1つはアルゴリズムの動作と拡張方法であり、もう1つはSQLServerのコストモデルです。
次に、図1の計画に戻ります。コストの計算方法を理解してみましょう。ポリシーとして、Microsoftは使用する内部原価計算式を明らかにしません。私は子供の頃、物事を分解することに魅了されていました。時計、ラジオ、カセットテープ(そう、私はそんなに年をとっています)、あなたはそれに名前を付けます。どうやって作られたのか知りたかった。同様に、コストを合理的に正確に予測できれば、アルゴリズムをよく理解していることを意味するので、数式をリバースエンジニアリングすることに価値があります。その過程で、たくさんのことを学ぶことができます。
クエリは1,000,000行を取り込みます。この行数でも、I / OコストはCPUコストに比べて無視できるように思われるため、無視しても安全です。
CPUコストについては、どの要因がどのように影響するかを試してみてください。理論的には、入力行の数、グループの数、グループ化セットのカーディナリティ、データ型、グループ化セットのメンバーのサイズなど、いくつかの要因が考えられます。したがって、これらの要因のいずれかの効果を測定するために、測定する要因のみが異なる2つのクエリの推定コストを比較する必要があります。たとえば、行数がコストに与える影響を測定するには、入力行数が異なる2つのクエリを作成しますが、他のすべての側面(グループ数、グループ化セットのカーディナリティなど)は同じです。また、オプティマイザは推定数に基づいてコストを計算するため、実際の数ではなく推定数が望ましい数であることを確認することが重要です。
このような比較を行うときは、推定数を完全に制御できる手法を用意することをお勧めします。たとえば、入力行の推定数を制御する簡単な方法は、TOPクエリに基づくテーブル式をクエリし、外部クエリに集計関数を適用することです。 TOP演算子を使用しているために、オプティマイザーが行の目標を適用し、それによって元のコストが調整されることが懸念される場合、これは、TOP演算子の下のプランに表示される演算子にのみ適用されます。右)、上(左)ではありません。 Stream Aggregateオペレーターは、フィルター処理された行を取り込むため、プランのTopオペレーターの上に自然に表示されます。
出力グループの推定数を制御する場合は、グループ化式
Stream Aggregateアルゴリズムとシリアルプランを確実に取得するには、クエリヒントOPTION(ORDER GROUP、MAXDOP 1)を使用してこれを強制できます。
また、リバースエンジニアリングされた式で考慮できるように、オペレーターに初期費用があるかどうかを把握する必要があります。
入力行の数がオペレーターの推定CPUコストにどのように影響するかを理解することから始めましょう。明らかに、この要素はオペレーターのコストに関連しているはずです。また、1行あたりのコストは一定であると予想されます。入力行の推定数のみが異なる比較用のクエリをいくつか示します(それぞれクエリ2とクエリ3と呼びます)。
SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1); SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1);
図2は、これらのクエリの推定計画の関連部分を示しています。

図2:クエリ2とクエリ3の計画>
行あたりのコストが一定であると仮定すると、オペレーターのコストの差をオペレーターの入力カーディナリティの差で割ったものとして計算できます。
CPU cost per row = (0.125 - 0.065) / (200000 - 100000) = 0.0000006
取得した数が実際に一定で正しいことを確認するために、他の数の入力行を使用したクエリで推定コストを予測してみることができます。たとえば、入力行が500,000の場合の予測コストは次のとおりです。
Cost for 500K input rows = <cost for 100K input rows> + 400000 * 0.0000006 = 0.065 + 0.24 = 0.305
次のクエリを使用して、予測が正確かどうかを確認します(クエリ4と呼びます)。
SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1);
このクエリの計画の関連部分を図3に示します。
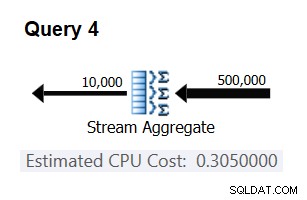
図3:クエリ4の計画
ビンゴ。当然、複数の追加の入力カーディナリティを確認することをお勧めします。私がチェックしたすべてのもので、0.0000006の入力行あたりの一定のコストがあるという仮説は正しかった。
次に、グループの推定数がオペレーターのCPUコストにどのように影響するかを調べてみましょう。各グループを処理するにはCPUの作業が必要になると予想されます。また、グループごとに一定であると予想するのも妥当です。この論文をテストし、グループあたりのコストを計算するには、結果グループの数のみが異なる次の2つのクエリを使用できます(それぞれクエリ5とクエリ6と呼びます)。
SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1); SELECT orderid % 20000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 20000 OPTION(ORDER GROUP, MAXDOP 1);
推定されたクエリプランの関連部分を図4に示します。
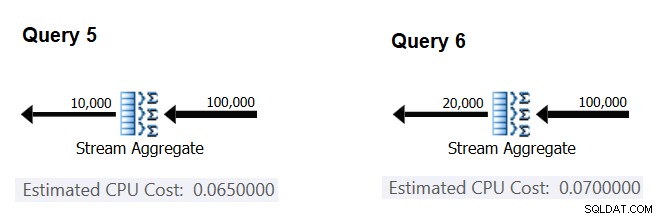
図4:クエリ5とクエリ6の計画>
入力行ごとの固定費を計算する方法と同様に、出力グループごとの固定費は、オペレーターのコストの差をオペレーターの出力カーディナリティの差で割ったものとして計算できます。
CPU cost per group = (0.07 - 0.065) / (20000 - 10000) = 0.0000005
また、前に示したように、他の数の出力グループでコストを予測し、予測された数をオプティマイザーによって生成された数と比較することで、結果を検証できます。私が試したグループの数はすべて、予測されたコストは正確でした。
同様の手法を使用して、他の要因がオペレーターのコストに影響を与えるかどうかを確認できます。私のテストでは、グループ化セットのカーディナリティ(グループ化する式の数)、グループ化された式のデータ型とサイズは、推定コストに影響を与えないことが示されています。
残っているのは、オペレーターに想定される意味のある初期費用があるかどうかを確認することです。存在する場合、オペレーターのCPUコストを計算するための完全な(うまくいけば)式は次のようになります。
Operator CPU cost = <startup cost> + <#input rows> * 0.0000006 + <#output groups> * 0.0000005
したがって、残りの部分から起動コストを導き出すことができます:
Startup cost =- (<#input rows> * 0.0000006 + <#output groups> * 0.0000005)
この目的のために、この記事の任意のクエリプランを使用できます。たとえば、図4で前述したクエリ5の計画の数値を使用すると、次のようになります。
Startup cost = 0.065 - (100000 * 0.0000006 + 10000 * 0.0000005) = 0
表示されるように、Stream Aggregateオペレーターには、CPU関連の起動コストがないか、コスト測定の精度で表示されないほど低いです。
結論として、StreamAggregateオペレーターコストのリバースエンジニアリング式は次のとおりです。
I/O cost: negligible CPU cost: <#input rows> * 0.0000006 + <#output groups> * 0.0000005
図5は、行数とグループ数の両方に関するStreamAggregateオペレーターのコストのスケーリングを示しています。
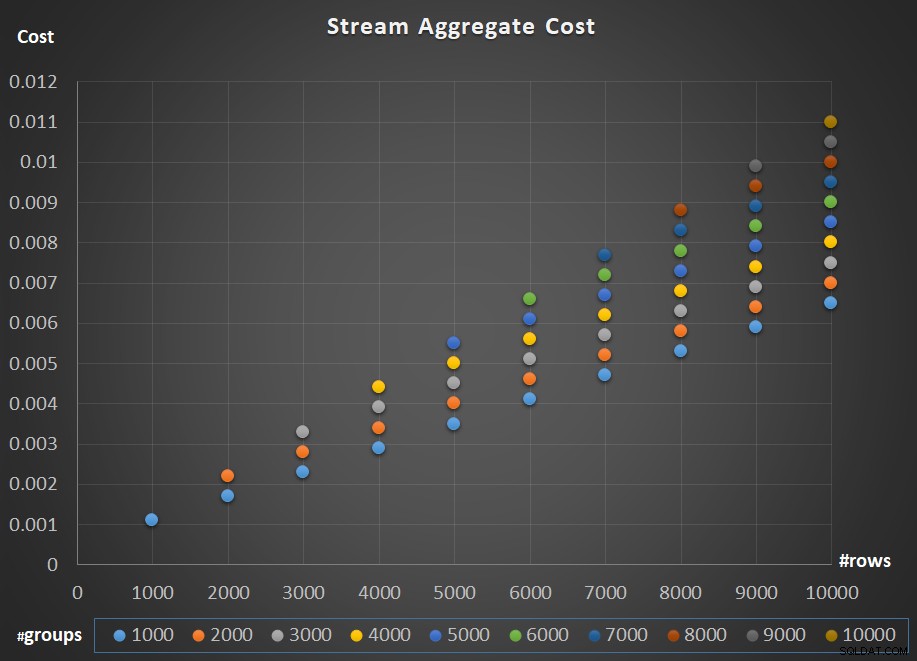
図5:StreamAggregateアルゴリズムのスケーリングチャート
オペレーターのスケーリングについては、線形です。グループの数が行の数に比例する傾向がある場合、行とグループの両方の数が増加するのと同じ係数で、オペレーター全体のコストが増加します。つまり、入力行と入力グループの両方の数を2倍にすると、オペレーター全体のコストが2倍になります。理由を理解するために、オペレーターのコストを次のように表すと仮定します。
r * 0.0000006 + g * 0.0000005
行数とグループ数の両方を同じ係数pだけ増やすと、次のようになります。
pr * 0.0000006 + pg * 0.0000005 = p * (r * 0.0000006 + g * 0.0000005)
したがって、指定された数の行とグループに対して、Stream AggregateオペレーターのコストがCである場合、行とグループの両方の数を同じ係数pだけ増やすと、オペレーターのコストはpCになります。図5のチャートで例を特定して、これを確認できるかどうかを確認してください。
入力行の数が増えてもグループの数がかなり安定している場合でも、線形スケーリングが得られます。グループの数に関連するコストを定数と見なすだけです。つまり、特定の行数とグループに対して、演算子のコストがC =G(グループ数に関連するコスト)+ R(行数に関連するコスト)である場合、行数だけを1倍に増やします。 pはG+pRになります。このような場合、当然、オペレーター全体のコストはpC未満です。つまり、行数を2倍にすると、オペレーター全体のコストは2倍未満になります。
実際には、多くの場合、データをグループ化すると、入力行の数は出力グループの数よりも大幅に多くなります。この事実は、行ごとに割り当てられたコストとグループごとのコストがほぼ同じであるという事実と相まって、グループの数に起因するオペレーターのコストの部分は無視できるようになります。例として、図1で前述したクエリ1の計画を参照してください。このような場合、オペレーターのコストは、入力行の数に対して単純に線形にスケーリングするものと考えるのが安全です。
特別な場合
Stream Aggregateオペレーターが、データをまったくソートする必要がない特殊なケースがあります。考えてみれば、Stream Aggregateアルゴリズムには、プレゼンテーションの目的でデータを並べ替える必要がある場合(クエリに外部プレゼンテーションのORDER BY句がある場合など)と比較して、入力からの順序付けの要件が緩和されています。 Stream Aggregateアルゴリズムでは、同じグループのすべての行を一緒に並べ替える必要があります。入力セット{5、1、5、2、1、2}を取ります。プレゼンテーションの順序付けの目的で、このセットは次のように順序付けする必要があります:1、1、2、2、5、5。集約の目的で、データが次の順序で配置されている場合、StreamAggregateアルゴリズムは引き続き適切に機能します。 5、1、1、2、2。これを念頭に置いて、スカラー集計(集計関数を使用し、GROUP BY句を使用しないクエリ)を計算する場合、または空のグループ化セットでデータをグループ化する場合、グループは1つしかありません。 。入力行の順序に関係なく、StreamAggregateアルゴリズムを適用できます。 Hash Aggregateアルゴリズムは、入力としてグループ化セットの式に基づいてデータをハッシュします。スカラー集計と空のグループ化セットの両方で、ハッシュする入力はありません。したがって、スカラー集計と空のグループ化セットに適用された集計の両方で、オプティマイザーは、データを事前に並べ替える必要なしに、常にStreamAggregateアルゴリズムを使用します。現在(SQL Server 2017 CU4の時点で)バッチモードはハッシュ集計アルゴリズムでのみ使用できるため、少なくとも行実行モードの場合はそうです。これを示すために、次の2つのクエリを使用します(クエリ7とクエリ8と呼びます)。
SELECT COUNT(*) AS numrows FROM dbo.Orders; SELECT COUNT(*) AS numrows FROM dbo.Orders GROUP BY ();
これらのクエリの計画を図6に示します。
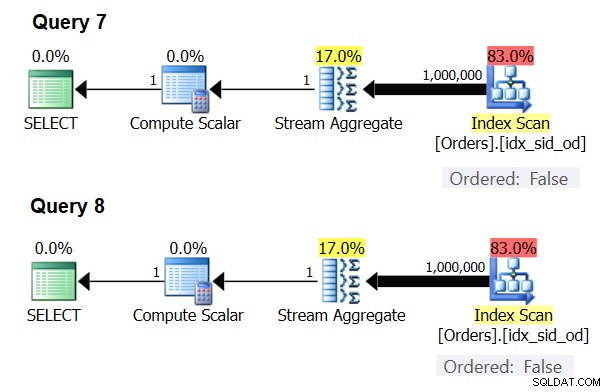
図6:クエリ7とクエリ8の計画>
どちらの場合も、ハッシュ集計アルゴリズムを強制してみてください。
SELECT COUNT(*) AS numrows FROM dbo.Orders OPTION(HASH GROUP); SELECT COUNT(*) AS numrows FROM dbo.Orders GROUP BY () OPTION(HASH GROUP);
オプティマイザは要求を無視し、図6に示すのと同じ計画を作成します。
クイッククイズ:スカラー集計と空のグループ化セットに適用された集計の違いは何ですか?
回答:入力セットが空の場合、スカラー集計は1行の結果を返しますが、グループ化セットが空のクエリの集計は空の結果セットを返します。試してみてください:
SELECT COUNT(*) AS numrows FROM dbo.Orders WHERE 1 = 2;
numrows ----------- 0 (1 row affected)
SELECT COUNT(*) AS numrows FROM dbo.Orders WHERE 1 = 2 GROUP BY ();
numrows ----------- (0 rows affected)
完了したら、クリーンアップのために次のコードを実行します。
DROP INDEX idx_sid_od ON dbo.Orders;
まとめと課題
Stream Aggregateアルゴリズムのコスト計算式をリバースエンジニアリングすることは、子供の遊びです。事前に注文されたStreamAggregateアルゴリズムのコスト計算式は、これを理解する方法を説明する記事全体ではなく、@ numrows * 0.0000006 + @numgroups*0.0000005であると言ったかもしれません。ただし、ポイントは、リバースエンジニアリングのプロセスと原則を説明してから、より複雑なアルゴリズムと、あるアルゴリズムが他のアルゴリズムよりも最適になるしきい値に移ることでした。魚のようなものを与えるのではなく、釣り方を教えます。さまざまなアルゴリズムの原価計算式をリバースエンジニアリングしようとしているときに、私は多くのことを学び、考えもしなかったことを発見しました。
あなたのスキルをテストする準備はできましたか?あなたの使命は、それを受け入れることを選択した場合、StreamAggregateオペレーターをリバースエンジニアリングするよりも一段難しいものです。シリアルソート演算子の原価計算式をリバースエンジニアリングします。入力データが事前に並べ替えられていない空でないグループ化セットを使用してクエリに適用されるStreamAggregateアルゴリズムでは、明示的な並べ替えが必要になるため、これは私たちの調査にとって重要です。このような場合、集計操作のコストとスケーリングは、Sort演算子とStreamAggregate演算子を組み合わせたコストとスケーリングによって異なります。
ソート演算子のコストを予測することにうまく近づいた場合、署名の「リバースエンジニア」に追加する権利を獲得したように感じることができます。そこには多くのソフトウェアエンジニアがいます。でも確かにリバースエンジニアはあまり見かけません!数式を小さい数と大きい数の両方でテストしてください。見つけたものに驚かれるかもしれません。