2つのクエリを結合または結合するために使用される演算子は、SET演算子に他なりません。 SET演算子に分類される演算子は次のとおりです。
- UNIONオペレーター。
- UNION ALL’オペレーター。
- INTERSECTオペレーター。
- マイナス演算子。
SET演算子を使用して操作するために従うべきルールは次のとおりです。
- 列の数と列の順序は同じである必要があります。
- データ型は互換性がある必要があります。
例を使って各SET演算子を理解しましょう。
与えられたレコードと一緒に次の表を検討してください。
表1:従業員
| EMPLOYEEID | FIRST_NAME | LAST_NAME | 給与 | CITY | 部門 | MANAGERID | WORKING_HOURS | 性別 |
| 1001 | VAIBHAVI | MISHRA | 65000 | PUNE | ORACLE | 1 | 12 | F |
| 1002 | VAIBHAV | シャルマ | 60000 | NOIDA | ORACLE | 1 | 9 | M |
| 1003 | NIKHIL | VANI | 50000 | ジャイプール | FMW | 2 | 10 | M |
| 2001 | PRACHI | シャルマ | 55500 | チャンディーガル | ORACLE | 1 | 10 | F |
| 2002 | BHAVESH | JAIN | 65500 | PUNE | FMW | 2 | 12 | M |
| 2003 | ルチカ | JAIN | 50000 | ムンバイ | テスト | 4 | 9 | F |
| 3001 | PRANOTI | SHENDE | 55500 | PUNE | JAVA | 3 | 9 | F |
| 3002 | ANUJA | 場所 | 50500 | ジャイプール | FMW | 2 | 9 | F |
| 3003 | DEEPAM | ジャウハリ | 58500 | ムンバイ | JAVA | 3 | 12 | M |
| 4001 | RAJESH | GOUD | 60500 | ムンバイ | テスト | 4 | 10 | M |
表2:従業員。
| EMPLOYEEID | FIRST_NAME | LAST_NAME | 給与 | CITY | 部門 | MANAGERID | WORKING_HOURS | 性別 |
| 1001 | Vaibhav | シャルマ | 65000 | PUNE | ORACLE | 1 | 12 | M |
| 1002 | ニキル | ヴァニ | 60000 | NOIDA | ORACLE | 1 | 9 | M |
| 1003 | Vaibhavi | ミシュラ | 50000 | ジャイプール | FMW | 2 | 10 | F |
| 2001 | ルチカ | Jain | 55500 | チャンディーガル | ORACLE | 1 | 10 | F |
| 2002 | プラチ | シャルマ | 65500 | PUNE | FMW | 2 | 12 | F |
| 2003 | Bhavesh | Jain | 50000 | ムンバイ | テスト | 4 | 9 | M |
| 3001 | Deepam | ジャウハリ | 55500 | PUNE | JAVA | 3 | 9 | M |
| 3002 | ANUJA | 場所 | 50500 | ジャイプール | FMW | 2 | 9 | F |
| 3003 | プラノティ | シェンデ | 58500 | ムンバイ | JAVA | 3 | 12 | F |
| 4001 | RAJESH | GOUD | 60500 | ムンバイ | テスト | 4 | 10 | M |
表3:マネージャー。
| Managerid | manager_name | manager_department |
| 1 | Snehdeep Kaur | ORACLE |
| 2 | Kirti Kirtane | FMW |
| 3 | Abhishek Manish | JAVA |
| 4 | アヌパムミシュラ | テスト |
表4:マネージャー1。
| Managerid | manager_name | manager_department |
| 1 | 石田アグラワル | ORACLE |
| 2 | Kirti Kirtane | FMW |
| 3 | Abhishek Manish | JAVA |
| 4 | Paul Oakip | テスト |
UNIONオペレーター
UNION演算子は、2つ以上のSELECTステートメントをマージまたは結合するために使用される最初の演算子です。列の数と列の順序が同じである場合に限ります。
重複した行は、UNION操作の実行後に取得された結果では考慮されません。
UNION演算の構文は次のとおりです。
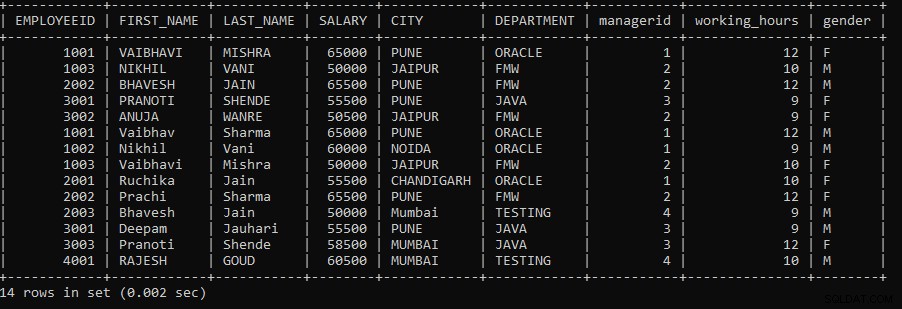
SELECT * FROM TABLE_NAME1 UNION SELECT * FROM TABLE_NAME2;例1: クエリを実行して、EmployeesテーブルとEmployeeテーブルの間でUNION操作を実行します。
SELECT * FROM EMPLOYEES UNION SELECT * FROM EMPLOYEE;上記のクエリでは、2つのSELECTクエリを使用しました。最初のSELECTクエリは従業員からデータを取得し、2番目のSELECTクエリは従業員データからデータを取得し、UNION操作は両方のSELECTクエリで実行されます。
UNION操作は、両方のテーブル間で重複する行を破棄します。次の出力は次のように表示されます。
重複レコードを除いて、両方のテーブルレコードが表示されます。
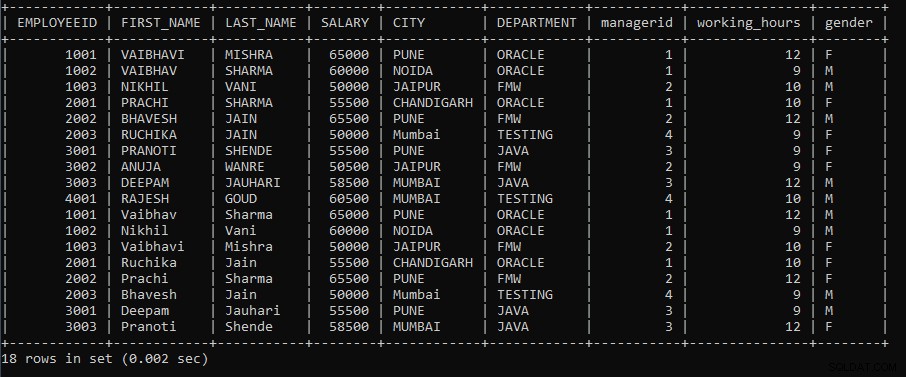
例2: クエリを実行して、EmployeesテーブルとEmployeeテーブルの間でUNION操作を実行します。ただし、ムンバイ市に属する従業員テーブルからの従業員のレコードのみを表示し、従業員テーブルからは、従業員の給与が50000より大きく60000未満の従業員のレコードのみを表示します。
SELECT * FROM EMPLOYEES WHERE CITY = 'MUMBAI' UNION SELECT * FROM EMPLOYEE WHERE SALARY > 50000 AND SALARY < 60000;上記のクエリでは、2つのSELECTクエリを使用しました。最初のSELECTクエリは、従業員がムンバイ市に属するレコードのみをEmployeesテーブルからフェッチします。そして、2番目のSELECTクエリでUNION操作を実行すると、従業員の給与が50000より大きく60000未満のレコードのみがemployeeテーブルからフェッチされます。 UNION操作は、両方のテーブル間で重複する行を破棄します。
次の出力は次のように表示されます。
重複レコードを除いて、両方のテーブルレコードが表示されます。
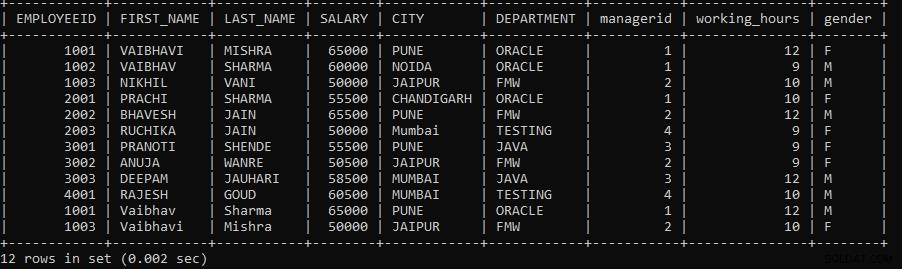
例3: クエリを実行して、EmployeesテーブルとEmployeeテーブルの間でUNION操作を実行します。従業員の都市が「プネ」と「ジャイプール」に属する従業員テーブルのレコードのみが必要です。
SELECT* FROM EMPLOYEES WHERE CITY IN ('PUNE', 'JAIPUR') UNION SELECT * FROM EMPLOYEE;上記のクエリでは、2つのSELECTクエリを使用しました。最初のSELECTクエリは、従業員が「Pune」および「Jaipur」都市に属するレコードをEmployeesテーブルからフェッチします。 UNION操作は、テーブルemployeeからの2番目のSELECTクエリから取得されたレコードを使用して実行されます。
UNION操作は、両方のテーブル間で重複する行を破棄します。次の出力は次のように表示されます。
ご覧のとおり、最初の5つのレコードは、プネまたはジャイプール市に属する従業員です。残りのレコードは、2番目のSELECTクエリであるemployeeテーブルからのものです。
重複レコードを除いて、両方のテーブルレコードが表示されます。
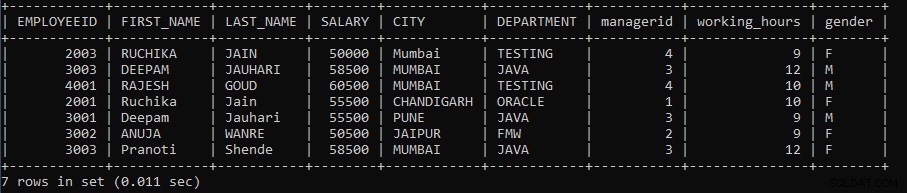
例4: クエリを実行して、EmployeesテーブルとEmployeeテーブルの間でUNION操作を実行します。従業員の名がVで始まるEmployeeテーブルのレコードのみが必要です。
SELECT * FROM EMPLOYEES UNION SELECT * FROM EMPLOYEE WHERE FIRST_NAME LIKE 'V%';上記のクエリでは、2つのSELECTクエリを使用しました。最初のSELECTクエリは、Employeesテーブルからすべてのレコードをフェッチします。 UNION操作は、名が「V」で始まるテーブルemployeeからの2番目のSELECTクエリから取得されたレコードを使用して実行されます。
UNION操作は、両方のテーブル間で重複する行を破棄します。次の出力は次のように表示されます。
最初の10件の結果はEmployeesテーブルからのものであり、残りはEmployeeテーブルからのものであり、その従業員の名は「V」で始まります。
例5: クエリを実行して、ManagerテーブルとManager1テーブルの間でUNION操作を実行します。
SELECT * FROM MANAGER UNION SELECT * FROM MANAGER1;上記のクエリでは、2つのSELECTクエリを使用しました。最初のSELECTクエリはManagerからデータを取得し、2番目のSELECTクエリはmanager1データからデータを取得し、UNION操作は両方のSELECTクエリで実行されます。
UNION操作は、両方のテーブル間で重複する行を破棄します。次の出力は次のように表示されます。
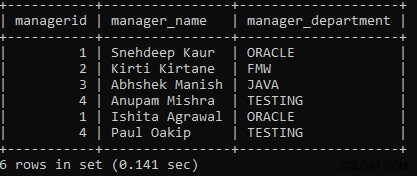
重複レコードを除いて、両方のテーブルレコードが表示されます。
UNIONALLオペレーター
UNION ALL演算子は、両方のクエリからのすべてのデータを結合します。 UNION演算子では、結果で重複レコードは考慮されませんでしたが、UNION ALLは、UNIONALL操作の実行後に取得された結果で重複レコードと見なされました。
UNIONALL操作の構文は次のとおりです。
SELECT * FROM TABLE_NAME1 UNION ALL SELECT * FROM TABLE_NAME2;例1: クエリを実行して、EmployeesテーブルとEmployeeテーブルの間でUNIONALL操作を実行します。
SELECT * FROM EMPLOYEES UNION ALL SELECT * FROM EMPLOYEE;上記のクエリでは、2つのSELECTクエリを使用しました。最初のSELECTクエリは従業員からデータをフェッチし、2番目のSELECTクエリによってフェッチされたデータを使用してUNIONALL操作を実行します。
次の出力は次のように表示されます。
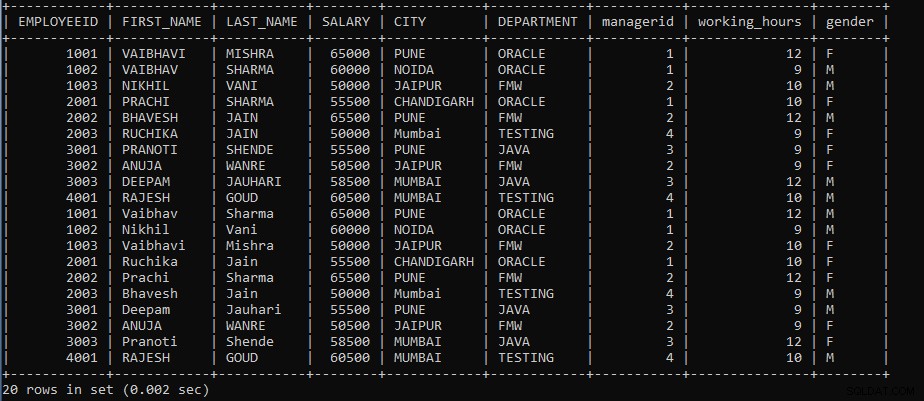
UNION ALL操作を実行すると、すべてのレコードがEmployeesテーブルとEmployeeテーブルの両方から表示され、重複するレコードも表示されます。
例2: クエリを実行して、EmployeesテーブルとEmployeeテーブルの間でUNIONALL操作を実行します。ただし、ムンバイ市に属する従業員テーブルからの従業員のレコードのみを表示します。従業員テーブルから、従業員の給与が60500で、市が「ムンバイ」である従業員のレコードのみ。
SELECT * FROM EMPLOYEES WHERE CITY = 'MUMBAI' UNION ALL SELECT * FROM EMPLOYEE WHERE SALARY = 60500 AND CITY = 'MUMBAI';上記のクエリでは、2つのSELECTクエリを使用しました。最初のSELECTクエリは、従業員がムンバイ市に属するレコードのみをEmployeesテーブルからフェッチします。そして、2番目のSELECTクエリでUNION ALL操作を実行すると、従業員の給与が60500で、市が「ムンバイ」であるレコードのみが従業員テーブルからフェッチされます。
次の出力は次のように表示されます。

UNION ALL操作を実行する際の重複レコードを含め、両方のテーブルレコードが表示されます。
例3: クエリを実行して、EmployeesテーブルとEmployeeテーブルの間でUNION操作を実行します。従業員の都市が「プネ」、「ムンバイ」、「ジャイプール」に属するEmployeesテーブルのレコードのみが必要です。
SELECT* FROM EMPLOYEES WHERE CITY IN ('PUNE', 'MUMBAI', 'JAIPUR') UNION ALL SELECT * FROM EMPLOYEE;上記のクエリでは、2つのSELECTクエリを使用しました。最初のSELECTクエリは、従業員が「プネ」、「ムンバイ」、および「ジャイプール」の都市に属するレコードをEmployeesテーブルからフェッチします。 UNION ALL操作は、テーブルemployeeからの2番目のSELECTクエリから取得されたレコードを使用して実行されます。
次の出力は次のように表示されます。
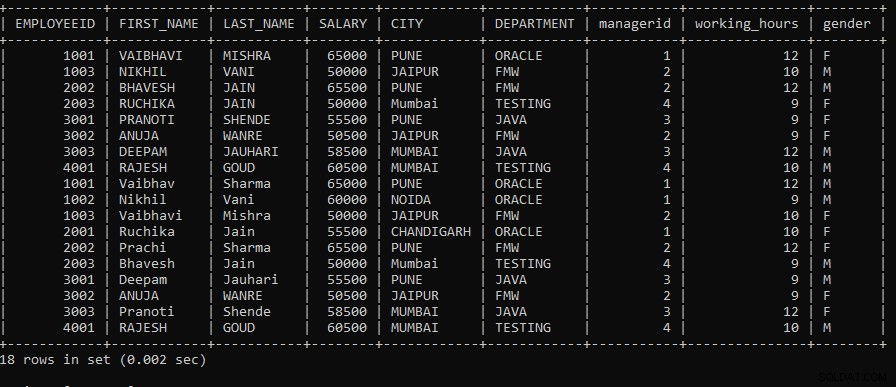
UNION ALL操作を実行する際の重複レコードを含め、両方のテーブルレコードが表示されます。
例4: クエリを実行して、ManagerテーブルとManager1テーブルの間でUNIONALL操作を実行します。
SELECT * FROM MANAGER UNION ALL SELECT * FROM MANAGER1;上記のクエリでは、2つのSELECTクエリを使用しました。最初のSELECTクエリはManagerからデータをフェッチし、2番目のSELECTクエリによってフェッチされたデータを使用してUNIONALL操作を実行します。
次の出力は次のように表示されます。
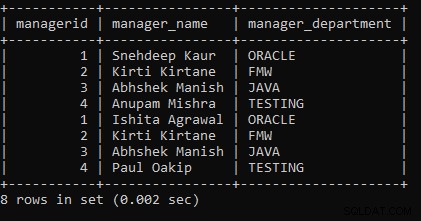
すべてのレコードは、テーブルManagerとManager1の両方から表示されます。 UNION ALL操作を実行すると、重複するレコードが表示されます。
INTERSECT演算子
交差演算子は、2つ以上のSELECTステートメントを組み合わせるために使用されますが、SELECTステートメントと同様のデータのみを表示します。
INTERSECT操作の構文は次のとおりです。
SELECT * FROM TABLE_NAME1 INTERSECT SELECT * FROM TABLE_NAME2;例1: クエリを実行して、EmployeesテーブルとEmployeeテーブルの間でINTERSECT操作を実行します。
SELECT * FROM EMPLOYEES INTERSECT SELECT * FROM EMPLOYEE;上記のクエリでは、2つのSELECTクエリを使用しました。最初のSELECTクエリは従業員からデータをフェッチし、2番目のSELECTクエリによってフェッチされたデータを使用してINTERSECT操作を実行し、従業員テーブルからデータを取得します。
次の出力は次のように表示されます。

EmployeesテーブルとEmployeeテーブルの間でINTERSECT操作を実行したため、両方のテーブルから類似したレコードのみが表示されます。
例2: クエリを実行して、ManagerテーブルとManager1テーブルの間でINTERSECT操作を実行します。
SELECT * FROM MANAGER INTERSECT SELECT * FROM MANAGER1;上記のクエリでは、2つのSELECTクエリを使用しました。最初のSELECTクエリはManagerからデータをフェッチし、2番目のSELECTクエリによってフェッチされたデータを使用してINTERSECT操作を実行し、Manager1テーブルからデータを取得します。
次の出力は次のように表示されます。
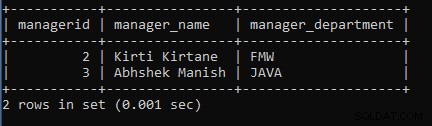
ManagerテーブルとManager1テーブルの間でINTERSECT操作を実行したため、両方のテーブルから類似したレコードのみが表示されます。
マイナス演算子
MINUS演算子は、最初のクエリに存在するが、重複のない残りのクエリには存在しない行を返すために使用されます。
MINUS演算の構文は次のとおりです。
SELECT * FROM TABLE_NAME1 EXCEPT SELECT * FROM TABLE_NAME2;注: MINUSキーワードは、ORACLEデータベースでのみサポートされています。他のデータベースにEXCEPTキーワードを使用して、同様の操作を実行できます。
例1: クエリを実行して、EmployeesテーブルとEmployeeテーブルの間でMINUS演算を実行します。
SELECT * FROM EMPLOYEES EXCEPT SELECT * FROM EMPLOYEE;上記のクエリでは、2つのSELECTクエリを使用しました。最初のSELECTクエリは従業員からデータをフェッチし、2番目のSELECTクエリによってフェッチされたデータを使用してMINUS操作を実行し、従業員テーブルからデータを取得します。
次の出力は次のように表示されます。
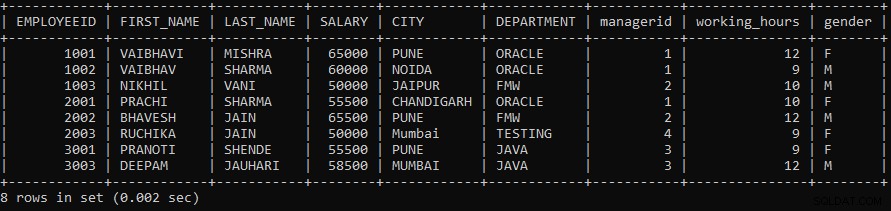
EmployeesテーブルとEmployeeテーブルの間でMINUS演算を実行したため、一致しないレコードのみが両方のテーブルから表示されます。
例2: クエリを実行して、ManagerテーブルとManager1テーブルの間でマイナス演算を実行します。
SELECT * FROM MANAGER EXCEPT SELECT * FROM MANAGER1;上記のクエリでは、2つのSELECTクエリを使用しました。最初のSELECTクエリはManagerからデータをフェッチし、2番目のSELECTクエリによってフェッチされたデータを使用してMINUS操作を実行し、Manager1テーブルからデータを取得します。
次の出力は次のように表示されます。
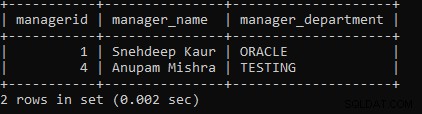
ManagerテーブルとManager1テーブルの間でMINUS操作を実行したため、一致しないレコードのみが両方のテーブルから表示されます。