最近、DISTINCTとGROUPBYについて投稿しました。これは、GROUPBYが一般的にDISTINCTよりも優れたオプションであることを示した比較でした。別のサイトにありますが、すぐにsqlperformance.comに戻ってください。
その投稿で示したクエリ比較の1つは、サブクエリのGROUP BYとDISTINCTの間でした。これは、Salesテーブルのすべての行の製品名を取得する必要があるため、DISTINCTの方がはるかに遅いことを示しています。異なるProductIDごとだけではありません。これはクエリプランから非常に明白です。最初のクエリでは、結合の結果ではなく、1つのテーブルのデータのみをAggregateが操作していることがわかります。ああ、両方のクエリで同じ266行が返されます。
select od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
group by od.ProductID;
select distinct od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od;

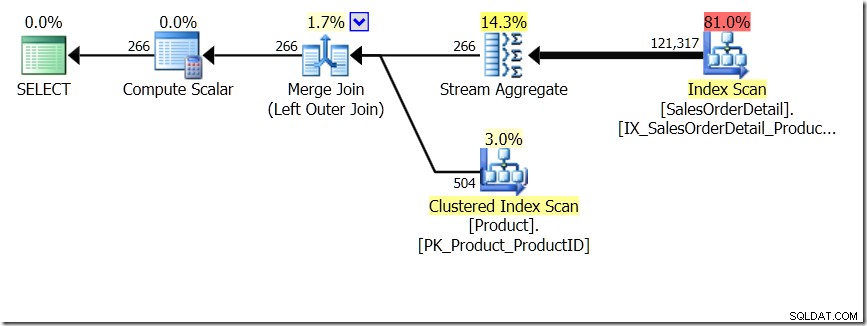
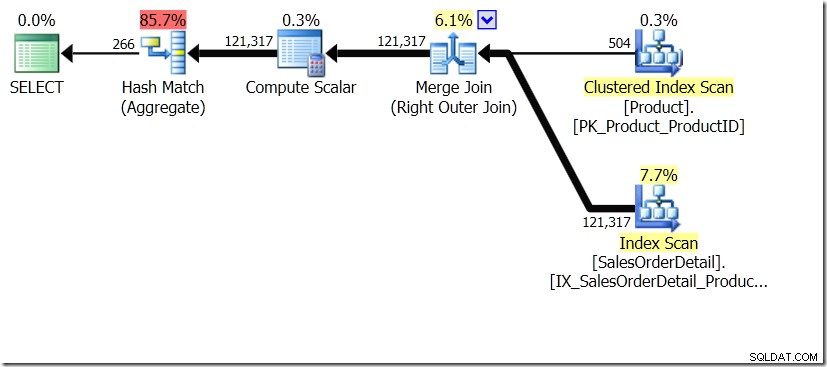
さて、GROUP BY vDISTINCTに関するAaronの投稿を参照するツイートのAdamMachanic(@adammachanic)を含めて、2つのクエリは本質的に異なり、1つは実際に結果の異なる組み合わせのセットを要求していることが指摘されています。渡された個別の値に対してサブクエリを実行するのではなく、サブクエリを実行します。これが計画に見られるものであり、パフォーマンスが大きく異なる理由です。
重要なのは、結果は同じになると私たち全員が想定するということです。
しかし、それは仮定であり、良いものではありません。
クエリオプティマイザが別の計画を考え出したことを少し想像します。これにはヒントを使用しましたが、ご存知のとおり、クエリオプティマイザーは、さまざまな理由でさまざまな形のプランを作成することを選択できます。
select od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
group by od.ProductID
option (loop join);
select distinct od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
option (loop join);
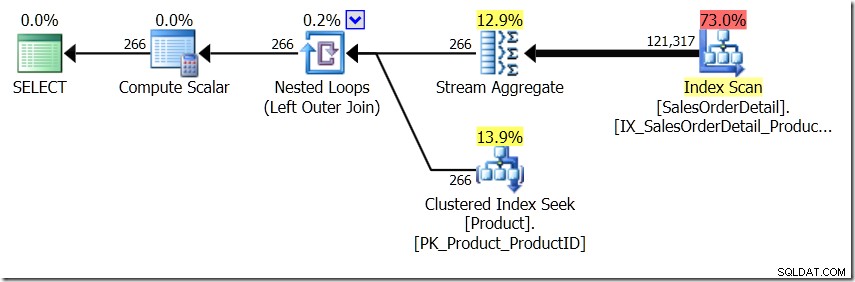
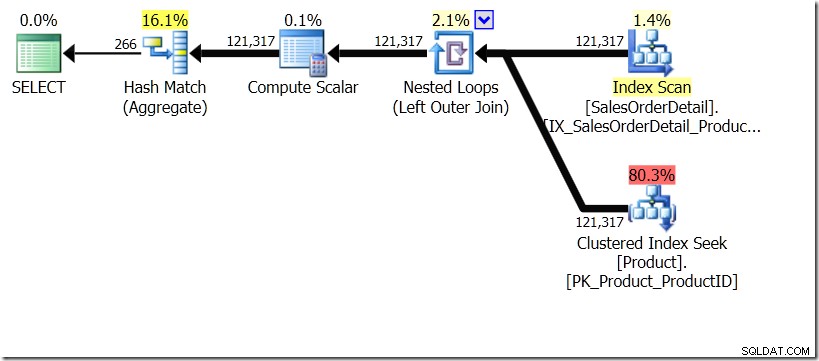
この状況では、関心のある異なるProductIDごとに1つずつ、製品テーブルに266シークを実行するか、121,317シークを実行します。したがって、特定のProductIDについて考えている場合、最初の名前から1つの名前を取得することがわかります。また、100回要求する必要がある場合でも、そのProductIDに対して単一の名前を取得すると想定しています。同じ結果が返されると想定しています。
しかし、そうでない場合はどうなりますか?
これは分離レベルのもののように聞こえるので、Productテーブルに到達したときにNOLOCKを使用しましょう。そして、(別のウィンドウで)スクリプトを実行して、[名前]列のテキストを変更してみましょう。クエリの間にいくつかの変更を加えようと、何度も繰り返します。
update Production.Product set Name = cast(newid() as varchar(36)); go 1000
今、私の結果は異なります。計画は同じですが(2番目のクエリでHash Aggregateから出てくる行の数を除いて)、私の結果は異なります。
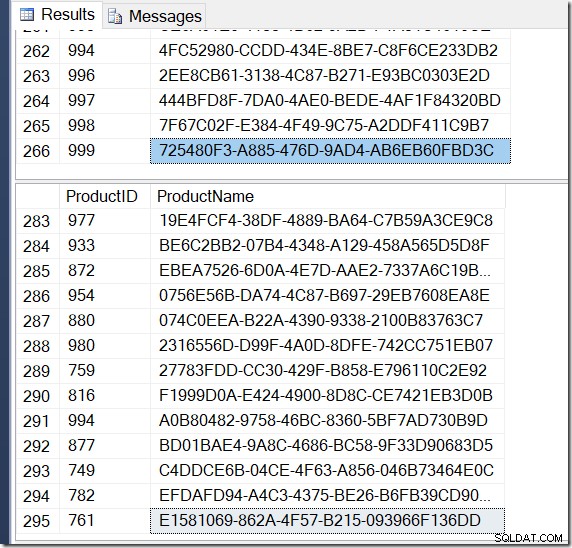
案の定、同じProductIDに対して異なるName値が検出されるため、DISTINCTの行が増えています。そして、私は必ずしも295行を持っているわけではありません。別の方法で実行すると、273、300、またはおそらく121,317になる可能性があります。
複数のName値を示し、何が起こっているかを確認するProductIDの例を見つけるのは難しくありません。

明らかに、結果にこれらの行が表示されないようにするには、DISTINCTを使用しないか、より厳密な分離レベルを使用する必要があります。
この例ではNOLOCKの使用について説明しましたが、その必要はありませんでした。この状況は、多くのSQLServerシステムのデフォルトの分離レベルであるREADCOMMITTEDでも発生します。
ご覧のとおり、この状況を回避し、読み取られた各行のロックを保持するには、REPEATABLEREAD分離レベルが必要です。そうしないと、私たちが見たように、別のスレッドがデータを変更する可能性があります。
しかし…クエリのデッドロックを回避できなかったため、結果が修正されたことを示すことはできません。
それでは、他のクエリの問題が少ないことを確認して、条件を変更しましょう。テーブル全体を一度に更新するのではなく(とにかく現実の世界でははるかに少ない可能性があります)、一度に1行だけ更新しましょう。
declare @id int = 1; declare @maxid int = (select count(*) from Production.Product); while (@id < @maxid) begin with p as (select *, row_number() over (order by ProductID) as rn from Production.Product) update p set Name = cast(newid() as varchar(36)) where rn = @id; set @id += 1; end go 100
これで、READCOMMITTEDやREADUNCOMMITTEDなど、より低い分離レベルでも問題を示すことができます(ただし、クエリ中に行を更新する可能性があるため、初めて266を取得した場合は、クエリを複数回実行する必要があります。が少なくなります)。これで、REPEATABLE READで修正されることを示すことができます(クエリを何度実行しても)。
REPEATABLE READは、缶に書かれていることを実行します。トランザクション内の行を読み取ると、読み取りを繰り返して同じ結果を取得できるようにロックされます。分離レベルが低いと、データを変更しようとするまで、これらのロックは解除されません。クエリプランで読み取りを繰り返す必要がない場合(GROUP BYプランの形状の場合のように)、REPEATABLEREADは必要ありません。
間違いなく、REPEATABLE READやSERIALIZABLEなど、常により高い分離レベルを使用する必要がありますが、それはすべて、システムに必要なものを理解することです。これらのレベルは不要なロックを引き起こす可能性があり、SNAPSHOT分離レベルには、価格も伴うバージョン管理が必要です。私にとって、それはトレードオフだと思います。データの変更によって影響を受ける可能性のあるクエリを要求している場合は、しばらくの間、分離レベルを上げる必要があるかもしれません。
理想的には、読み取ったばかりのデータを更新せず、クエリ中に再度読み取る必要がある可能性があるため、REPEATABLEREADは必要ありません。しかし、何が起こり得るかを理解することは間違いなく価値があり、これはDISTINCTとGROUPBYが同じではない可能性がある場合の一種のシナリオであることを認識する必要があります。
@rob_farley